语义SLAM论文Incremental Dense Semantic Stereo Fusion for Large-Scale Semantic Scene Reconstruction
Posted 振华OPPO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语义SLAM论文Incremental Dense Semantic Stereo Fusion for Large-Scale Semantic Scene Reconstruction相关的知识,希望对你有一定的参考价值。
2015 IEEE International Conference on Robotics and Automation (ICRA)
Washington State Convention Center
Seattle,Washington,May 26-30,2015
摘要
我们的场景理解能力,让我们能够感知周围环境的 3D 结构并直观地识别我们看到的物体,在很大程度上是我们认为理所当然的事情,但对于机器人来说,快速理解大场景的任务仍然极具挑战性.最近,基于 3D 重建和语义分割的场景理解方法变得流行,但现有方法要么无法扩展,要么在户外失败,要么仅提供稀疏重建,要么相当缓慢。
在本文中,我们建立在最近的基于散列的大规模融合技术和用于密集连接 CRF 的有效平均场推理算法的基础上,以展示我们所知的第一个可以执行密集、大规模、户外的系统(近)实时的场景语义重建。我们还提出了一种“语义融合”方法,使我们能够比以前的方法更有效地处理动态对象。我们展示了我们的方法在 KITTI 数据集上的有效性,并提供了定性和定量结果,显示了许多场景的高质量密集重建和标记。
一、介绍
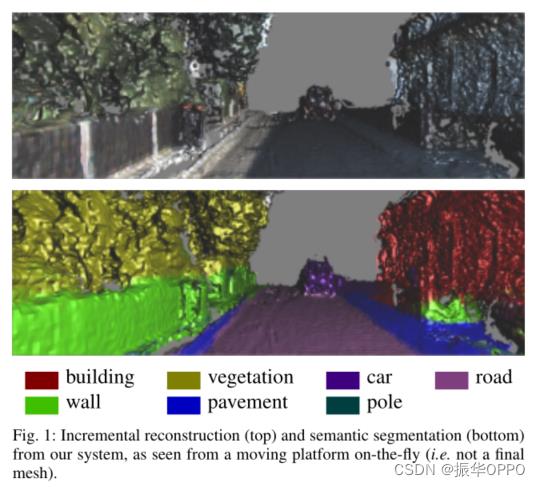
当我们环游世界时,例如从家里开车到工作地点时,我们会不断感知周围环境的 3D 结构并识别其中的物体。这些能力在我们的日常生活中为我们提供帮助,让我们即使在不熟悉的地方也能自由准确地移动。构建一个可以自动执行增量实时密集大规模重建和语义分割的系统,如图 1 所示,是各种应用的关键先决条件,包括机器人导航 [1]、[2]、语义映射[3]、[4]、可穿戴和/或辅助技术 [5]、[6] 和变化检测 [7]。然而,尽管有大量文献受到此类应用的启发 [3]、[4]、[8]-[12],但大多数现有方法都受到各种限制。离线重建方法可以在城市规模 [13] 及以上范围内取得令人印象深刻的结果,但不能在实时环境中使用。稀疏在线重建 [14]-[17] 在历史上比密集重建更受青睐,因为它们的计算量较低。密集方法的要求和获取足够输入的困难,但不保证稀疏地图包含感兴趣的对象(例如交通信号灯、标志)。由于内存要求,在规则体素网格上工作的密集重建 [18]-[20] 仅限于小体积。这已通过使用可扩展数据结构和在 GPU 和 CPU 内存之间流式传输数据的方法得到解决 [21]、[22],但它们使用仅在室内工作的类似 Kinect 的相机 [9]、[10]。在户外工作的方法通常需要大量时间来运行 [4]、[8]、[11]、[23],不能增量工作 [12] 或依赖 LIDAR 数据 [24]。现有系统也不能很好地处理移动物体。
理想情况下,我们认为一种方法应该:
- 能够以任何规模逐步构建任何室内或室外环境的密集语义 3D 地图;
- 以实时速率即时执行这两项任务;
- 能够处理移动的物体。
在本文中,我们提出了一种端到端系统,可以增量处理数据并执行实时密集立体重建和无界户外环境的语义分割。系统输出 pervoxel 概率分布而不是单个标签(软预测在机器人技术中是可取的,因为视觉输出通常作为输入馈送到其他子系统)。我们的系统还能够更有效地处理移动物体,与之前的方法相比,通过将对象类别的知识纳入重建过程。为了实现更快的测试时间,我们广泛使用现代 GPU 的计算能力。
我们的目标是逐步构建密集的大规模语义户外地图。我们强调我们方法的增量性质,因为许多方法采用表面致密化、纹理映射和色调消光等后处理技术来生成高质量或视觉上合理的网格。然而,在大多数机器人设置中,重要的是即时产生的实际输出(图 1)。这种考虑激励了我们的重建管道和整个系统。
我们系统的核心(图 2)是一种可扩展的融合方法 [22],它允许在几乎无界的场景中重建高质量的表面。它通过将标准公式 [18]-[20] 的固定密集 3D 体积表示替换为忽略目标环境中未占用空间的哈希表驱动对应物来实现这一点。此外,虽然标准公式受到可用 GPU 内存的限制,但 [22] 根据需要在设备和主机内存之间交换/流映射数据。这是可扩展密集重建的关键,据我们所知,迄今为止仅用于室内环境。
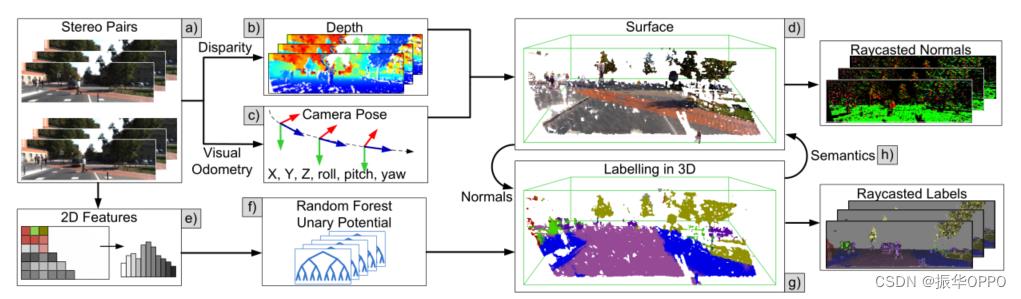
户外场景存在几个挑战:
- 类似 Kinect 的摄像头在户外效果较差,而 LIDAR 通常对于“可穿戴机器人”来说太大或产生过于稀疏的点云:因此我们更喜欢依赖立体,这适用于大型机器人和可穿戴眼镜/耳机;
- 因此,估计的深度[25]通常更嘈杂;
- 深度范围要大得多
- 动态移动的对象更常见,并且相机本身可能会在连续帧之间显着移动(例如,如果安装在汽车上等)。
所有这些都使得 ICP 相机姿态估计的数据关联(如 [20]、[22] 中使用的)更难,因此我们用更可靠的视觉里程计代替它 [16]。
我们的语义分割管道提取 2D 特征并基于随机森林分类器预测评估一元势。它将这些转移到 3D 体积中,我们在其中定义了一个密集连接的 CRF。体积 CRF 减少了计算负担,因为多个像素通常对应于相同的体素,并强制执行时间一致性,因为我们标记了实际的 3D 表面。为了有效地推断近似最大后边际 (MPM) 解决方案,我们提出了一种在线体积平均场推断技术,该技术在迭代中逐步细化体素的边缘,并设计了一个适合并行实现的体积滤波器。这允许我们在每一帧运行推理(单个平均场更新需要 2-6 毫秒),因此我们的动态能量景观变化缓慢,并且每个时间步只需要几次平均场更新迭代。我们使用我们的语义标签来加强融合步骤中的权重,从而使我们能够比以前的方法更有效地处理移动对象(参见§IV)。
我们系统的所有部分都在 GPU 上实现,除了视觉里程计和视差估计,但两者都很容易并行化,因此可以切换到 GPU。
二、相关工作
2.1 重建
最近,[26] 展示了仅使用单目相机的大规模半密集重建。早期的实时密集方法 [18]、[19] 能够从单目输入估计深度,但由于内存需求,它们使用常规体素网格将重建限制在小体积。 KinectFusion [20] 使用有源传感器直接感知深度,并随着时间的推移融合感知场景的噪声深度测量,以恢复高质量的表面,但也遇到了同样的可扩展性问题。此后,该缺点已通过使用体素层次结构 [21] 或体素块散列 [22] 的可扩展方法消除,以避免为可用空间存储不必要的数据,并将层次结构中的单个树或 GPU 和 CPU 之间的体素块流式传输到允许缩放到无限场景。散列方法具有支持体素块的恒定时间查找的优点,而即使在平衡的层次结构中查找也是块数量的对数。
2.2 语义分割
在该领域 [3]、[4]、[8]-[12]、[23]、[24] 已经提出了许多方法。表中提供了户外大规模重建的最相关论文和关键属性的摘要。
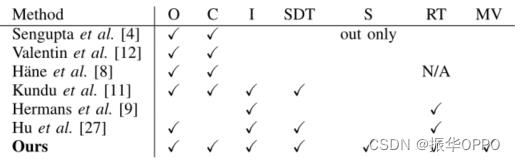
Hermans 等人,[9] 使用随机森林分类器和密集的 2D CRF,将生成的边缘转换为 3D 和求解 3D CRF 以改进预测。除了其他缺点(参见表一),CPU 实现需要启发式调度(跳帧等)以保持接近实时的帧速率。森古普塔等人。 [4] 提出了一种离线方法,该方法使用从 2D 到 3D 的标签传输,并以相反的顺序进行采样,这在计算上非常昂贵。它们支持从 RAM 流式传输(CPU 实现),但不会再次返回,即它们总是从头开始。同样,瓦伦丁等人。 [12] 在重建的网格上定义 CRF,从而加快推理速度。然而,他们的方法不是增量的,即他们需要先重建整个场景,然后对其进行标记。昆杜等人。 [11] 提出了一种离线方法(基于个人通信)将稀疏(单目)重建与 2D 语义标签集成到 CRF 模型中,以确定场景的结构和标签。虽然它们的结果在视觉上很吸引人,但在近距离观察时,它们确实显得略微体素化。其他方法 [8]、[18]、[19]、[23] 有类似的问题,而 Hu 等人。 [27] 依赖于激光雷达数据。与 [4]、[11]、[12]、[23] 相比,我们的方法提供了软预测。
三、大规模户外重建
我们的系统依赖于被动立体相机,因此我们需要估计要融合到每一帧重建中的深度数据。为了融合深度数据,我们还需要知道相机的当前位姿,因此我们在深度估计过程中并行运行相机位姿跟踪器。以下小节更详细地描述了我们重建系统的三个部分(深度估计、相机姿态估计和大规模融合)。
3.1 深度估计
为了估计每个立体对的深度,我们首先估计视差,然后使用等式 zi = bf /di 将其转换为深度,其中 zi 和 di(分别)是第 i 个像素的深度和视差,b 是立体相机基线,f 是相机的焦距。对于视差估计,我们使用 Geiger 等人的方法。 [25],它在一组可以稳健匹配的支持点上形成三角剖分。这减少了匹配的歧义,并允许通过对搜索空间的约束有效地利用差异,而无需任何全局优化。因此,该方法可以很容易地并行化。
3.2 相机位姿估计
为了估计相机姿态,我们使用基于 FOVIS 特征的视觉里程计方法 [16]。首先,使用高斯平滑滤波器构建了三级图像金字塔(每一级对应于尺度空间的一个八度)。然后,通过使用具有自适应选择阈值的 FAST 角点检测器来提取一组稀疏的局部特征,以检测足够数量的特征。特征提取步骤通常使用分桶“有偏差”,以确保特征在空间和尺度上均匀分布。
为了将特征匹配阶段限制在局部搜索窗口,估计图像平面的初始旋转以处理 3D 中的小运动。匹配阶段将提取的特征与描述符相关联,并使用相互一致性检查来匹配特征。通过在图中找到最大团或使用 RANSAC 来执行稳健估计,并在内点上估计最终变换。通过使用“关键帧”进一步提高了鲁棒性,这在相机视点没有显着变化时减少了漂移。这可以通过使用带有闭环的完整 SLAM 来进一步改进,但这超出了本文的范围。
3.3 大规模融合
传统上,基于 KinectFusion 的方法将深度融合到完整、密集的体积 3D 表示中,这严重限制了可以处理的重建大小。然而,在现实世界的场景中,这个体素块的很大一部分只包含空闲空间,不需要密集存储。通过将表示集中在场景的有用部分上,我们可以更有效地使用内存,从而可以重建更大的环境。这种洞察力已成为诸如 [22] 的基于散列的方法和 [21] 的八叉树技术等工作的催化剂。
我们采用基于散列的融合方法[22],它只为那些落在场景中感知表面一小段距离内的体素分配空间。这个空间被组织成小的体素块。与其他深度融合方法一样,密集区域使用近似截断符号距离函数 (TSDF) [28] 表示。对单个体素块的访问由散列表介导。给定一个已知的相机位姿(§III-B),我们使用以下融合管道:
a) 分配:我们确保为深度图像中可见的每个体素分配体素块。这是通过 (i) 将所有可见体素反向投影到体素块世界坐标来完成的; (ii) 在哈希表中查找每个唯一的体素块以确定它当前是否已分配,以及 (iii) 分配当前未分配的任何块。
b) 集成:我们使用 [28] 的传统滑动平均技术将当前深度和颜色帧集成到体积数据结构中。
c)主机-设备流式传输:虽然目前的 GPU 有几 GB 的设备内存,但通常不足以存储完整的大规模重建。为此,数据在设备和主机之间传输。我们只保留在截锥体中或附近的部分。为了实现这种方法,我们主动在设备和主机之间交换部分映射他们进出视野时的记忆。请注意,在当前实现中,我们可以处理的重建规模仍然受到主机 RAM 的限制。但是,使用 RAM 和磁盘存储之间的“交换进出”策略来实现几乎无限制的重建是很简单的。
d) Raycasting:在每一帧中,融合的深度图都是从当前相机位置渲染的。
四、语义融合
当场景中有移动物体时,标准融合步骤通常会失败,因为当我们融合来自移动物体的深度数据时,静态物体可能会被破坏。这种影响可以通过基于对象类别的实时权重 wtT,i 和 wtC,i 来减少:通过对标有移动对象类别(例如汽车、行人等)的体素使用更高的权重,我们可以加快处理速度在场景更可能快速变化的地方将新数据融合到我们的 TSDF 中,这使我们能够避免在短暂包含移动对象的地方留下不正确的表面(请注意,体素的权重随着我们在移动中融合而增加对象数据,并在对象再次离开体素后需要一些时间再次减少)。我们将原始方案的这种改编称为“语义融合”,并使用以下方法更新我们的测量结果。
这种方法暂时降低了受影响体素表面的平滑度,但它允许我们保持移动场景中的对象,并避免静态对象的损坏。图 6 显示了一个示例,展示了我们的语义融合方法能够处理动态移动对象的方式。

五、体积 CRF 和平均场推断
5.1 模型
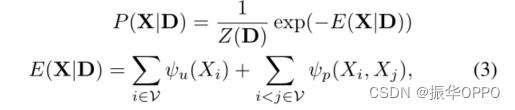
5.2 高效的平均场推断
多标签 CRF 推理最流行的方法之一是基于图形切割的α-扩展 [31],它找到了最大后验 (MAP) 解决方案。然而,graph-cuts 会导致缓慢的推理并且不容易并行化。鉴于上面定义的能量函数的形式,我们遵循基于平均场的优化方法,这是一种基于滤波器的变体,已被证明对于二维图像分割中的密集连接 CRF 非常有效 [32]、[33]。
接下来,我们讨论我们的在线体积平均场方法,它改编自我们上面描述的基于 2D 过滤的平均场方法。尽管这种在线平均场方法以前已应用于 2D [35],但我们相信这是它首次应用于 3D 设置。

5.3 基于体积滤波的平均场
平均场推断中最耗时的步骤是成对更新,其复杂度为 O(N 2)。现在我们将讨论如何将这种复杂性降低到 O(N),以采用高斯核的加权组合形式的成对势。我们的工作受到 [32]、[33] 的启发,他们表明可以通过应用交叉双边过滤技术来实现快速近似 MPM 推理。
5.4 在线平均场
给定无限的计算,一个人可能会运行多次更新迭代直到收敛。然而,在我们的在线系统中,我们假设下一帧对体积(以及对能量函数)的更新不是太激进,因此我们可以假设 Qi 分布可以从一帧时间传播到接下来,而不是在每一帧重新初始化(例如统一)。因此,即使每帧运行一次平均场更新迭代,我们也可以有效地将原本昂贵的推理操作分摊到多个帧上,并保持实时速度。

六、实验
我们证明了我们的方法对 3D 语义分割和重建的有效性。我们在 KITTI 数据集 [36] 上评估我们的系统,该数据集包含各种户外序列,包括城市、道路和校园。使用安装在车顶上的立体相机(基线 0.54m)以 1241×376 像素的分辨率捕获所有序列。该车还配备了 Velodyne HDL-64E 激光扫描仪 (LIDAR)。 KITTI 数据集非常具有挑战性,因为它包含许多移动物体,例如汽车、行人和自行车,以及光照条件的大量变化。
对于体素标记和重建,我们在静态和动态场景中展示了我们的结果。这使我们能够正确评估我们的方法处理运动的能力。对于静态场景,我们使用了 Sengupta 等人的数据集。 [4],由 45 个训练图像和 25 个测试图像组成,标记有以下类别:道路、建筑物、车辆、行人、人行道、树木、天空、标牌、柱子/柱子和墙/栅栏。对于动态场景,我们从包含许多移动对象的 KITTI 数据集中手动注释序列。我们将我们的体素标记方法实现的时间和准确性与两个基线 Ladick´y 等人 [30] 和 Sengupta 等人 [4]进行比较。为了评估我们的重建结果,我们将它们与使用 Geiger 等人的方法 [25] 生成的深度数据进行比较,使用来自 Velodyne 扫描仪的 LIDAR 数据作为基本事实。为了进行定性和定量评估,我们将体素标签和重建表面反向投影到相机的图像平面上,忽略距离相机超过 25 米的那些。
6.1. 定性 KITTI 结果
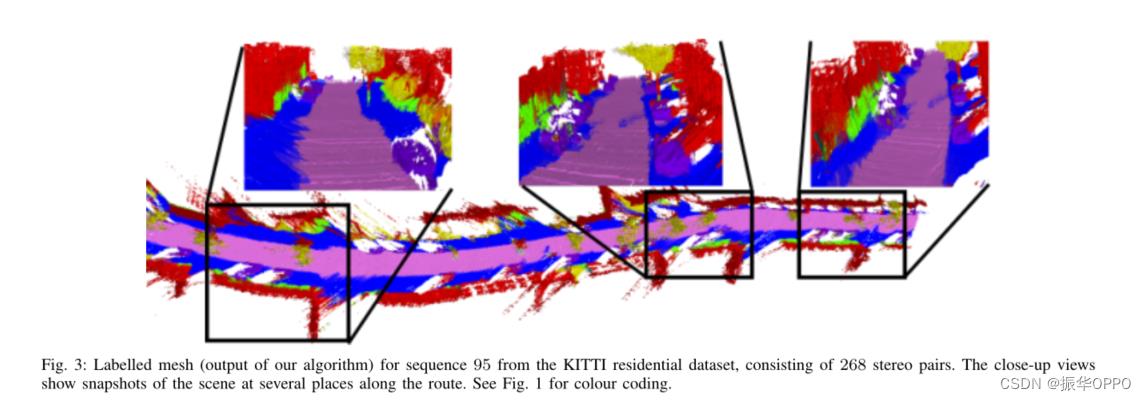
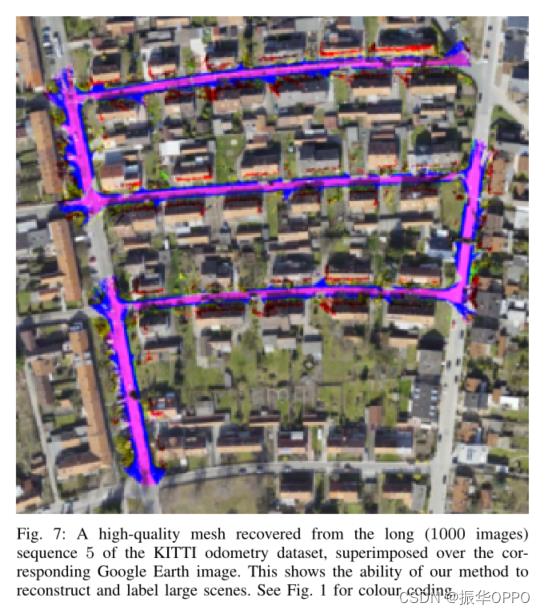
首先,我们展示了语义重建方法的一些定性结果。在图 5 中,我们强调了我们的方法不仅可以重建和标记包括道路、人行道和建筑物在内的整个户外场景,还可以准确地恢复灯柱和树木等薄物体。在图 6 中,我们展示了我们的语义融合方法在处理移动物体(在本例中为汽车)方面的优势。请特别注意,启用语义融合后,静态场景受到移动物体的破坏要比其他情况少得多。图 7 显示了从长 KITTI 序列(1000 张图像)中恢复的高质量网格,叠加在相应的 Google 地球图像上。这显示了我们的方法重建和标记大场景的能力。在图 8 中,我们展示了使用我们的方法生成的语义模型的特写视图,其中箭头表示图像位置及其在 3D 模型中的对应位置,颜色表示对象标签。这表明,即使我们的方法是一种增量方法,我们也能够为户外场景实现平滑的表面。
6.2. 定量 KITTI 结果
语义分割
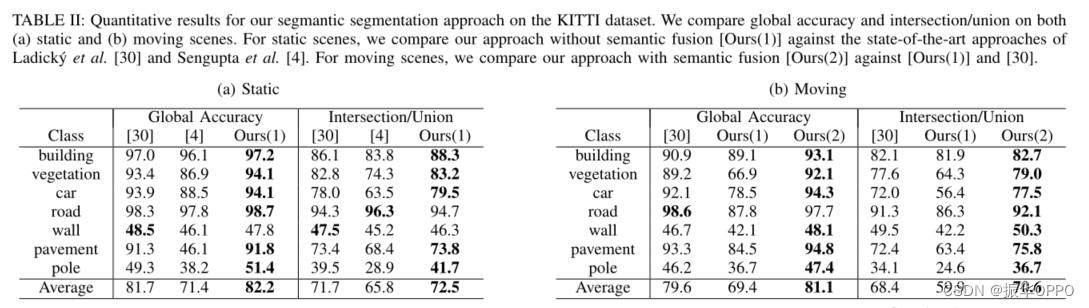
接下来,我们定量评估基于平均场的体积标记方法的速度和准确性。平均场更新大约需要 20 毫秒。虽然时间会随着函数的变化而变化,例如在可见体素的数量中,在我们执行的所有测试中,我们都观察到了实时性能。我们评估正确标记的体素的总体百分比(全局精度)和根据给定类的真/假阳性/阴性定义的交集/联合 (I/U) 分数,即 TP/(TP+FP+FN )。
静态场景的定量结果显示在表 II(a)中。与 Ladick´y 等人的 2D 方法[30]相比,我们实现了 0.49% 的全局准确度提高和 0.84% 的 I/U 分数提高。我们还显着改进了 Sengupta 等人的 3D 方法[4],实现全局精度提高 10.8%,I/U 提高 6.7%。更重要的是,我们的方法在全局精度和薄物体(例如杆)的 I/U 方面取得了令人鼓舞的改进。
在表 II(b),我们评估我们的标签在包含许多移动汽车的序列上的准确性。我们观察到,与 [30] 相比,我们的非语义融合方法将准确率降低了 10% 以上;然而,我们的语义融合方法将整体准确率提高了 1.5%。对于汽车,我们观察到全局准确度提高了 2.2%,I/U 提高了 5.5%。请注意,我们的语义融合方法显着提高了我们方法的全局准确性和 I/U,在这两种情况下都提高了 10% 以上。汽车的改进更为显着,突出了对包含移动物体的场景使用语义融合的重要性。
重建
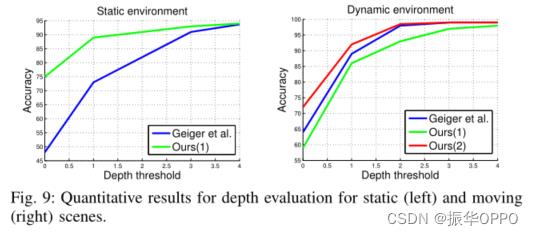
接下来,我们定量评估重建方法的效率和准确性。相机跟踪大约需要 20 毫秒,立体估计大约需要 40 毫秒(在我们的 12 个核心系统上),融合需要 14 毫秒。为了评估准确性,我们遵循 Sengupta 等人的方法 [4],他们测量投影到图像平面后与地面实况(在我们的例子中是 Velodyne 数据)的距离(在深度方面)小于固定阈值的像素数。
对于静态和动态场景,深度评估的定量结果总结在图 9 中。我们观察到,对于静态场景,当阈值分别为 1m 和 4m 时,我们的非语义融合方法本身达到了几乎 90% 和 95% 的准确率。因此,我们使用 Geiger 等人的方法 [25] 的立体声输出估计的初始深度提高了近 20%。然而,对于有很多移动物体的序列,非语义融合的表现并不好,与 Geiger 等人的方法相比,它导致准确率下降了近 5%。相比之下,我们的语义融合方法在准确性上实现了近 5% 的提高。
我们想强调的是,我们的语义重建管道的实时方面不包括特征评估时间。但是,可以在 GPU 上实现功能以提供实时性能,如 [37] 所示。
6.3. 其他定性结果
最后,我们展示了我们使用头戴式立体相机捕获的四个新的、具有挑战性的序列的额外定性结果。图 10 显示了通过运行我们的平均场推理程序获得的最终平滑语义重建。这些图像清楚地表明了我们设法在不同的冲突语义类别之间实现的清晰边界。例如,在第三列的序列中观察路面和道路之间极其精确的边界。补充视频中提供了更多结果。

七、结论
我们提出了一种稳健且准确的方法,用于从立体摄像机实时对室外环境进行增量密集大规模语义重建。我们算法的核心是用于 3D 重建的基于散列的融合方法和用于对象标记的体积平均场推断方法。通过同时执行重建和识别,我们捕捉到了这两个任务之间的协同作用。通过利用现代 GPU 的处理能力,我们可以以实时速率执行语义重建,即使在大规模环境中也是如此。我们已经证明了我们的系统对 KITTI 数据集上的高质量密集重建和场景标记的有效性。
我们的论文为进一步的工作提供了许多有趣的途径。我们想要探索的一个领域是针对 3D 重建执行特定于对象的形状先验。目前,类模型的特征生成和学习已经以离线方式完成。我们想在 GPU 上实现这些任务的在线方面。
以上是关于语义SLAM论文Incremental Dense Semantic Stereo Fusion for Large-Scale Semantic Scene Reconstruction的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读 YOLO v3:An Incremental Improvement
深度学习论文翻译解析:YOLOv3: An Incremental Improvement
经典文献阅读之--Multi-modal Semantic SLAM(多模态语义SLAM)
Semantic Monocular SLAM for Highly Dynamic Environments面向高动态环境的语义单目SLAM
[论文分享] Overcoming Catastrophic Forgetting in Incremental Few-Shot Learning by Finding Flat Minima