论文泛读 YOLO v3:An Incremental Improvement
Posted 风信子的猫Redamancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读 YOLO v3:An Incremental Improvement相关的知识,希望对你有一定的参考价值。
【论文泛读】 YOLO v3:An Incremental Improvement
文章目录
论文链接: YOLOv3: An Incremental Improvement
YOLOv3是YOLO (You Only Look Once)系列目标检测算法中的第三版,相比之前的算法,尤其是针对小目标,精度有显著提升。作者在2018年写下这篇技术报告,为什么说是技术报告而不是论文呢。其实整篇文章中,用了很多通俗的语言,不是非常的正式的口吻,所以更像是一种技术报告而不是一个论文,但是还是特别值得我们去学习的,毕竟经典永流传。
摘要 Abstract
我们对 YOLO 做了一些更新!通过一些小的设计更改使其变得更好,我们也训练了这个非常好的新网络。虽然它比上个版本 YOLOv2 的体量稍微大了一些,但是精准度更高了,并且它的速度仍然很快,所以不用担心。在输入 320 × 320 的图片后,YOLOv3 能在 22 毫秒内完成处理,并取得 28.2 mAP 的检测精准度,它的精准度和 SSD 相当,但是速度要快 3 倍。当我们用旧的 .5 IOU mAP 检测指标时,YOLOv3 的精准度也是相当好的。在 Titan X 环境下,YOLOv3 在 51 毫秒内实现了 57.9 AP50 的精准度,和 RetinaNet 在 198 毫秒内的 57.5 AP50 相当,但是 YOLOv3 速度要快 3.8 倍。和以前一样,所有代码均在 https://pjreddie.com/yolo/
介绍 Introduction
这一段介绍用了很通俗的语言,比如作者一开始说,有时候可能一整年的时间都是在打电话,整天刷着 Twitter了,还在 GAN 上花了点时间,结果发现自己还有一些时间,就想着更新一下 YOLO了。
有趣的是,作者提出,之所以写这篇技术报告的原因就是,他们有一篇论文要截稿了,但是还缺一篇关于YOLO 更新的文章作为引用来源,所以就写了这篇技术报告。
并且由于技术报告和论文是不同的,首先不需要写引言,可以偷懒哈哈。所以作者用这篇技术报告告诉我们YOLOv3的更新情况,并且展示更新方法和一些失败的尝试,最后就是对这次更新意义的总结。
更新改进 The Deal
对于 YOLOv3 的更新情况做一个简单的介绍:
很多时候就借鉴别人的好想法,并且作者训练了一个新的比其他更好的分类网络,为了方便理解,从头开始介绍整个系统。
Bounding Box Prediction
在 YOLO9000 之后,我们的系统使用维度聚类(dimension cluster)固定 anchor boxes 来选定边界框。神经网络为每个边界框预测 4 个坐标, t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th。如果目标 cell 距离图像左上角的边距是$ (c_x, c_y)$ ,且对应的边界框的高和宽为$ p_w, p_h $,那么网络的预测值是:
b
x
=
σ
(
t
x
)
+
c
x
b
y
=
σ
(
t
y
)
+
x
y
b
w
=
p
w
e
t
w
b
h
=
p
h
e
t
h
P
r
(
o
b
j
e
c
t
)
∗
I
O
U
(
b
.
o
b
j
e
c
t
)
=
σ
(
t
o
)
\\begin{aligned} b_x &= σ(t_x) + c_x\\\\ b_y &= σ(t_y) + x_y \\\\ b_w &= p_we^{t^w} \\\\ b_h &= p_he^{t^h} \\\\ Pr(object)*IOU(b.object) &= σ(t_o) \\end{aligned}
bxbybwbhPr(object)∗IOU(b.object)=σ(tx)+cx=σ(ty)+xy=pwetw=pheth=σ(to)
这里很好玩,作者说他在这篇技术报告中明目张胆的抄袭了自己YOLOv2论文的图,并且在下面引用。

在yolov3中,有个比较不同的地方,它对所有的anchor都预测了一个置信度,但是只有与GT的IOU最大的预测框来负责拟合,并且他的置信度为1。并且我们会忽略掉一些不是IOU不是最大的,并且大于我们设置的threshold的anchor。
假设我们的threshold为0.5
预测框分三种
正例
P
o
s
i
t
i
v
e
I
O
U
最
大
负例
N
e
g
a
t
i
v
e
I
O
U
<
0.5
忽略
I
g
n
o
r
e
I
O
U
>
0.5
但
并
非
最
大
\\begin{aligned} \\text{预测框分三种}\\\\ \\text{正例 } Positive \\text{ } IOU最大\\\\ \\text{负例 } Negative \\text{ } IOU<0.5\\\\ \\text{忽略 } Ignore \\text{ } IOU>0.5但并非最大\\\\ \\end{aligned}
预测框分三种正例 Positive IOU最大负例 Negative IOU<0.5忽略 Ignore IOU>0.5但并非最大
对每一个GT,yolov3都仅仅分配一个Anchor预测框。所以这样会有一个好处,对不预测GT的Anchor来说,不计算其定位和分类损失函数,仅计算置信度,只有正样本才会对分类和定位产生贡献,负样本只会对置信度学习产生贡献。
Class Prediction
这里对我们多分类进行了改进,之前的时候,我们都是用softmax,但是YOLOv3用独立的逻辑回归来分类。并且在训练过程,二分类交叉熵损失函数。这样可以每个预测框的每个类别逐一用逻辑回归输出概率,结果可以有多个类别输出高概率。
这个选择有助于我们把 YOLOv3 用于更复杂的领域,如公开图像数据集。这个数据集包含了大量重叠的标签(如女性和人)。如果我们用 softmax,它会强加一个假设,使每个框只包含一个类别,但通常情况并非如此。多标签的分类方法能够更好地模拟数据。
Predictions Across Scales
这里就到YOLOv3一个特别好的创新点,YOLOv3使用多尺度的目标检测。这个想法借鉴了FPN(feature pyramid networks),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体。
作者在网络模型中加入了一些卷积层,最后预测出一个三维张量编码:边界框、框中目标和分类预测。在 COCO 数据集实验中,我们的神经网络分别为每种尺寸各预测了 3 个边界框,所以得到的张量是 N × N × [3∗(4+1+80)],其中包含 4 个边界框偏移值(不是偏移量,还需要乘一个比例因子)、1 个目标预测以及 80 种分类预测。

从前面的 2 层中获取特征图(feature map),并将其上采样 2 倍。我们还从更早的网络图层中获取特征图,并使用 concatenation 将其与我们的上采样特征进行合并。这种方法使我们能够从早期特征映射中的上采样特征和更细粒度的信息中获得更有意义的语义信息。然后,我们添加几个卷积层来处理这个组合的特征图,并最终预测出一个相似的、大小是原先两倍的张量。

最后与YOLOv2一样,采用了k-means聚类来去确定边界框的先验。在实验中,我们选择了 9 个聚类和 3 个尺寸,然后在不同尺寸的边界框上均匀分割聚类。在 COCO 数据集上,这 9 个聚类分别是:(10×13)、(16×30)、(33×23)、(30×61)、(62×45)、(59×119)、(116×90)、(156×198)、(373×326) 。每个尺度三个Anchor。
我们可以看到,进过我们的模型以后,我们可以得到三个尺度,分别是13x13,26x26,52x52,中间是进行上采样和拼接的操作。在论文中,我们得到的是8x8,16x16,32x32,这里可以很容易看出来,尺度越大的,就越适合去预测小物体,尺度越大的就越适合预测大物体。所以我们会预测出三个预测框。
Feature Extractor
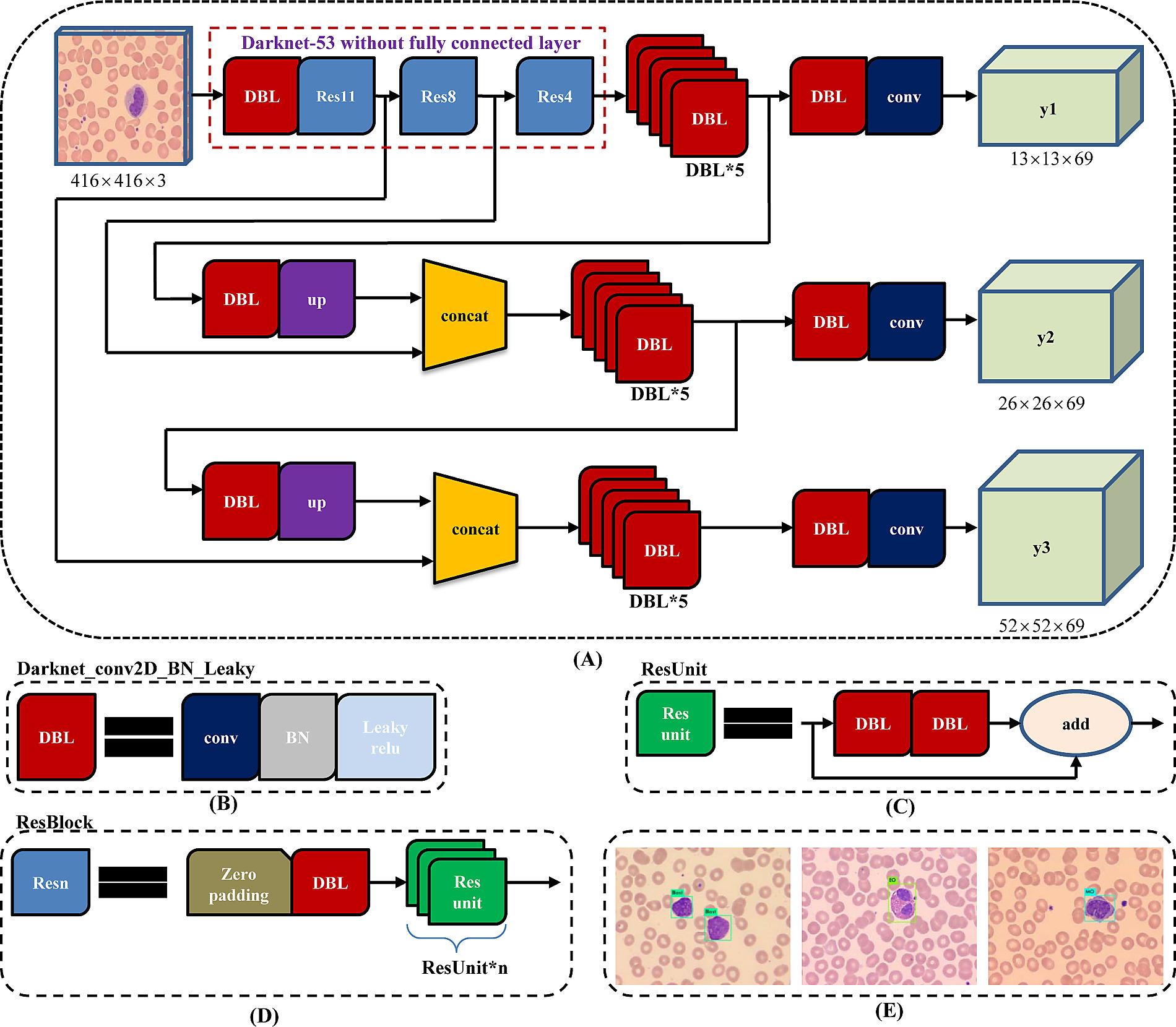
在YOLOv3中,作者用了一个新模型,结合了YOLOv2的Darknet-19和当时比较新奇时髦的残差网络。并且多用了连续的3x3和1x1的卷积,所以这个模型也比较大,它有53层卷积,所以被称为Darknet-53。
还有一个比较好的点是,论文的模型中,最后一层用了全局平均池化,所以能够更好的对我们的目标检测进行预测。
下面给出模型的结构,在论文中,并没有给出三个尺度的采样与拼接等,我找了个新的图,不过是类似的。

其后,作者对模型进行了一个比较,比较时间和模型的每秒的浮点运算量,凸显出Darkent-53的优点。

每个网络都使用相同的设置进行训练,输入 256 × 256 的图片,并进行单精度测试。运行环境为 Titan X。我们得出的结论是 Darknet-53 在精度上可以与最先进的分类器ResNet-152相媲美,同时它的浮点运算更少,速度也更快。和 ResNet-101 相比,Darknet-53 的速度是前者的 1.5 倍;而 ResNet-152 和它性能相似,但用时却是它的 2 倍以上。
Darknet-53 也可以实现每秒最高的测量浮点运算。这意味着网络结构可以更好地利用 GPU,使其预测效率更高,速度更快。这主要是因为 ResNets 的层数太多,效率不高。
Training
最后的训练中,作者只是输入完整的图像,并没有做其他处理。实验过程中涉及的多尺寸训练、大量数据增强和批量标准化等操作均符合标准。模型训练和测试的框架是 Darknet 神经网络。
YOLOv3 Loss
这里给出一下YOLOv3的损失函数的图

我们做的怎么样 How We Do
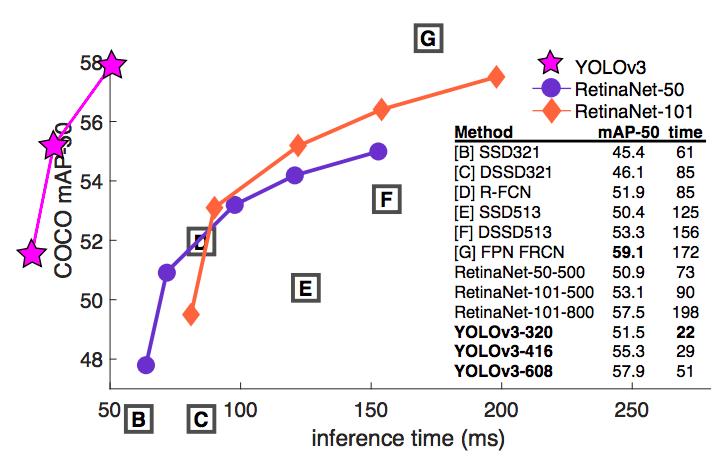
YOLOv3表现出了不错的性能,我们可以从下面的表可以看的出来,对于 COCOs 数据集那些奇怪的 mAP 评价指标,它的表现与与 SSD 平分秋色,但速度提高了 3 倍。尽管如此,它仍然比像 RetinaNet 这样的模型要差不少。

在实验过程中,发现了一个很神奇的事情,当作者用以前的评价指标,IOU=0.5 时的 mAP(表中的 AP50)来评价 YOLOv3 时,我们发现它真的很强。它几乎与 RetinaNet 媲美,且远远高于 SSD。这表明它是一个非常强大的检测器,擅长为检测目标生成合适的边界框。但是,随着 IOU 阈值的增加,YOLOv3 性能显著下降,这时候 YOLOv3 预测的边界框就不能做到完美对齐了。
在过去,YOLO 一直被用于小型对象检测。但现在我们可以看到其中的演变趋势,随着多尺寸预测功能的上线,YOLOv3 将具备更高 APS 性能。但它目前在中等尺寸或大尺寸物体上的检测表现还相对较差,仍需进一步的完善。
下图是根据mAP50画的图,而且这个图很搞笑,作者直接用别人论文的图了,还把自己的话在外面,突出结果哈哈,真不错。

失败的尝试 Things We Tried That Didn’t Work
作者在研究 YOLOv3 的时候尝试了很多东西,以下是一些失败案例。
Anchor box x,y offset predictions
我们尝试了常规的 Anchor box 预测方法,比如使用线性激活来将坐标 x,y 的偏移预测为边界框宽度或高度的倍数。但我们发现,这种做法降低了模型的稳定性而且效果不佳。
Linear x,y predictions instead of logistic
我们尝试使用线性激活来直接预测 x,y 的偏移,而不是使用逻辑激活,这降低了 mAP 结果。
Focal loss
我们尝试使用 focal loss,但它使我们的 mAP 大概降低了 2 个点。这可能是因为它具有单独的对象预测和条件类别预测,YOLOv3 对于 focal loss 函数试图解决的问题已经具有相当的鲁棒性。因此,对于大多数例子而言,类别预测没有损失?或者其他什么原因?我们并不完全确定。
Focal Loss 可以解决 one-stage中 “正负样本不均衡,真正有用的负样本少”,但YOLOv3中IOU过高,导致正样本中会夹杂着负样本,而focal loss赋予了更大的权重,所以不好。
Dual IOU thresholds and truth assignment
在训练期间,Faster RCNN 用了两个 IOU 阈值,如果预测的边框与标注边框的重合度不低于 0.7 ,那判定它为正样本;如果在 [0.3~0.7] 之间,则忽略;如果低于 0.3 ,就判定它为负样本。我们也尝试了这种方法,但是效果并不好。
更新的意义 What This All Means
YOLOv3 是一个非常棒的检测器,它又准又快。虽然它在 COCO 数据集上,0.3 和 0.95 的新指标上的成绩并不好,但对于旧的检测指标 0.5 IOU,它还是非常不错的。
其实接着,作者在这篇技术报告中,就开始吐槽,凑字数了哈哈。
下面给出这段翻译:
所以,为什么我们要改变指标呢?最初的 COCO 论文中只有这样的一句含糊其辞的话:评估完成,就会生成评估指标结果。但是 Russakovsky 等人曾经有份报告,说人类很难区分 0.3 和 0.5 的 IOU:“训练人们用肉眼区别 IOU 值为 0.3 和 0.5 的边界框是一件非常困难的事”。既然人类都难以区分,那这个指标还重要吗?
也许有个更好的问题值得我们去探讨:“我们用它来做什么”,很多从事这方面研究的人都受雇于 Google 和 Facebook,我想至少我们知道如果这项技术发展的完善,那他们绝对不会把它用来收集你的个人信息然后卖给…等一下,你把事实说出来了!!哦哦。
另外军方在计算机视觉领域投入了大量资金,他们从来没有做过任何可怕的事情,比如用新技术杀死很多人…哦哦。
我有很多希望!我希望大多数人会把计算机视觉技术用于快乐、幸福的事情上,比如就统计国家公园里斑马的数量,或者追踪他们小区附近有多少只猫。但是计算机视觉技术的应用已经步入歧途了,作为研究人员,我们有责任思考自己的工作可能带给社会的危害,并考虑怎么减轻这种危害。我们非常珍惜这个世界。
最后,不要在 Twitter 上 @ 我,我已经不玩了。
其实蛮搞笑的,而且这个作者确实也很有责任心,在之后的YOLOv4中,他没有再研究这一部分,因为他认为他做的一些成果被用到了战争上,感觉有一部分是自己的责任,所以由于愧疚,就放弃了这个领域的研究,并且称要退出推特。(其实好像最近他活跃了起来,还是玩了)
其实在论文中还有一部分,可能大家看的时候都把这一部分忽略掉了,很少人会认真看这一部分。虽然这一部分不是很重要,但也有有趣的东西,我觉得是最有意思的一部分。
Rebuttal
虽然这一部分没什么用,但是我还是想讲一下哈哈。
首先作者说自己工作繁忙,然后直接开始喷Twitter的评论哈哈,以下是他提到的两个评论:
一个人认为没有创新型, 另一个人认为MSCOCO metrics不够说服力.
- 对第一个, 他希望作者能给个清晰的图,然后作者一顿嘲讽,最后还是贴了图。
- 对第二个作者说:“我做出接过来还必须得吹吹水你才能满意吗?” 这还没完, 作者直接对传统metrics表示不满.
第二个有点搞笑,毕竟作者所有的工作都是在那上面进行的,这样一问,难道自己砸自己的脚么哈哈,当然作者还是表达了对maP的不满,但是其实有点没办法,难道有更好的指标么。
作者提供了一个例子, 下例中两种情况都有高mAP, 但有一个表现显然比另一个差:

这里其实肯定是有问题的,作者说mAP和Precision相同,但是我们仔细一看,肯定是不同的。所以作者这里,肯定是有问题的,因为太多FP了,所以说最后的Precision是不可能相同的,但是recall是有可能相同的。
参考
以上是关于论文泛读 YOLO v3:An Incremental Improvement的主要内容,如果未能解决你的问题,请参考以下文章