数据湖三大框架
Posted NC_NE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖三大框架相关的知识,希望对你有一定的参考价值。
一、数据湖框架
目前市面上流行的三大开源数据湖方案分别为:Delta Lake、Apache Iceberg和Apache Hudi
1、Delta Lake:DataBricks公司推出的一种数据湖方案,官网
2、Apache Iceberg:以类似于SQL的形式高性能的处理大型的开放式表,官网

3、Apache Hudi:Hadoop Upserts anD Incrementals,管理大型分析数据集在HDFS上的存储,官网
二、Delta Lake
2.1、简介
Delta Lake 是 DataBricks 公司开源的、用于构建湖仓架构的存储框架。能够支持 Spark,Flink,Hive,PrestoDB,Trino 等查询/计算引擎。作为一个开放格式的存储层,它在提供了批流一体的同时,为湖仓架构提供可靠的,安全的,高性能的保证。
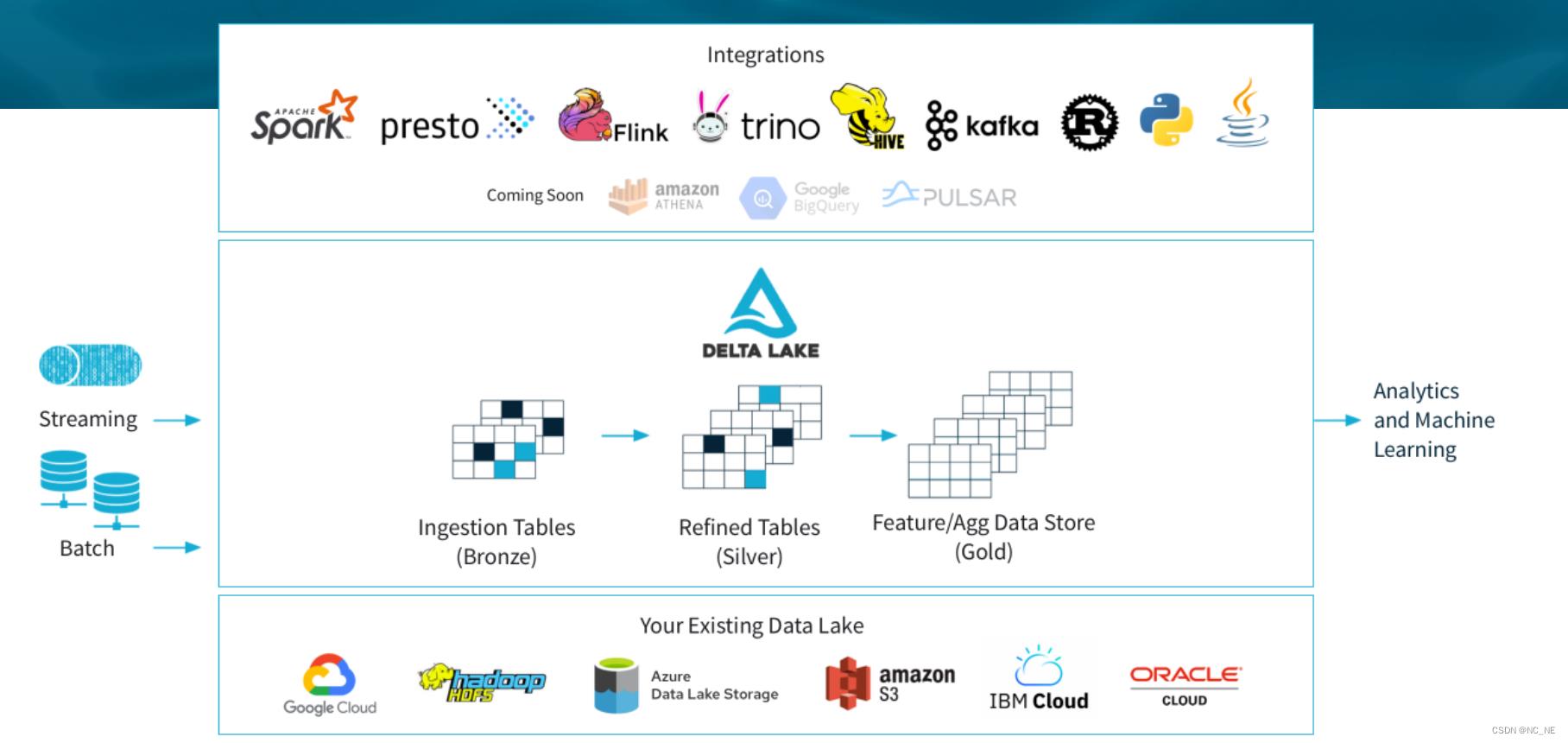
2.2、Delta Lake 关键特性
1、ACID事务:通过不同等级的隔离策略,Delta Lake 支持多个 pipeline 的并发读写;
2、数据版本管理:Delta Lake 通过 Snapshot 等来管理、审计数据及元数据的版本,并进而支持 time-travel 的方式查询历史版本数据或回溯到历史版本;
3、开源文件格式:Delta Lake 通过 parquet 格式来存储数据,以此来实现高性能的压缩等特性;
4、批流一体:Delta Lake 支持数据的批量和流式读写;
5、元数据演化:Delta Lake 允许用户合并 schema 或重写 schema,以适应不同时期数据结构的变更;
6、丰富的DML:Delta Lake 支持 Upsert,Delete 及 Merge 来适应不同场景下用户的使用需求,比如 CDC 场景;
三、Apache Iceberg
3.1、简介
Apache Iceberg 是Netflix 开发开源的,是一种用于大型分析表的高性能格式。Iceberg 为大数据带来了 SQL 表的可靠性和简单性,同时让 Spark、Trino、Flink、Presto 和 Hive 等引擎能够同时安全地使用相同的表。
3.2、Apache Iceberg特性
1、格式演变:支持添加,删除,更新或重命名,并且没有副作用
2、隐藏分区:可以防止导致错误提示或非常慢查询的用户错误
3、分区布局演变:可以随着数据量或查询模式的变化而更新表的布局
4、快照控制:可实现使用完全相同的表快照的可重复查询,或者使用户轻松检查更改
5、版本回滚:使用户可以通过将表重置为良好状态来快速纠正问题
6、快速扫描数据:无需使用分布式SQL引擎即可读取表或查找文件
7、数据修剪优化 :使用表元数据使用分区和列级统计信息修剪数据文件
8、支持事务 :序列化隔离,表更改是原子性的,读取操作永远不会看到部分更改或未提交的更改
9、高并发:高并发写入使用乐观并发,即使写入冲突,也会重试以确保兼容更新成功
四、Apache Hudi
4.1、简介
Hudi是Hadoop Updates and Incrementals的简写,它是由Uber开发并开源的Data Lakes解决方案。Hudi 用于管理的数据库层上构建具有增量数据管道的流式数据湖,同时针对湖引擎和常规批处理进行了优化。简言之,Hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。

4.2、Apache Hudi 特性
1、使用快速、可插入的索引进行更新、删除
2、增量查询,记录级别更改流
3、事务、回滚、并发控制
4、自动调整文件大小、数据集群、压缩、清理
5、用于可扩展存储访问的内置元数据跟踪
6、式摄取、内置 CDC 源和工具
7、支持 Spark、Presto、Trino、Hive 等的 SQL 读/写
8、向后兼容的模式演变和实施
以上是关于数据湖三大框架的主要内容,如果未能解决你的问题,请参考以下文章
数据湖09:开源框架DeltaLakeHudiIceberg深度对比