文献阅读:Universal Sentence Encoder
Posted Espresso Macchiato
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读:Universal Sentence Encoder相关的知识,希望对你有一定的参考价值。
文献链接:Universal Sentence Encoder
1. 文献内容简介
这篇文章算是考个古吧,前段时间看SNCSE(文献阅读:SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples)和SimCSE(文献阅读:SimCSE:Simple Contrastive Learning of Sentence Embeddings)的时候就突然想到了这篇古早文章,就拿来稍微复习了一下。
在这篇工作之前,大部分的工作基本都只在关注word embedding,而少有工作考察sentence embedding,对于sentence embedding的实现,大多数只是简单地使用word embedding的加权平均等简单操作,比如glove average之类的操作,不过事实上这类的工作感觉也很小众,毕竟直接在完整的end2end任务上面进行训练就行了,不需要单独考察sentence embedding这个问题。
而这篇文章算是比较最早的研究sentence embedding的工作之一了,目的就是为了可以将其进行更快地运用到下游的任务当中。
2. 主要方法考察
这篇文章的时间实在是比较早了,还是18年4月的时候,当时以bert为代表的利用大量无标注数据进行的self-supervised learning的范式还没有提出来,training更多还是基于标注数据下的supervised-training,在这种情况下任务大多都是end2end的,抽象sentence embedding意义不大,而且即使要做这个问题,数据量也不太够。
而这篇文章主要的研究点也就是突破了这个数据量的问题,它采用算是早期self-supervised training之前的预训练模型的范式,即使用transfer learning的方式最大程度地利用已有的标注数据,然后将共有层进行抽象的方式。
简单来说,就是同时training多个任务,然后把公共的部分裁出来作为最终的结果,而且google还是比较大气的,直接把这个结果扔到了tfhub上面给大家一起用了。
3. 实验结果梳理
在这篇文献当中,主要给出了两大实验结果,一是直接考察其在transfer learning当中的实验结果,具体如下图所示:
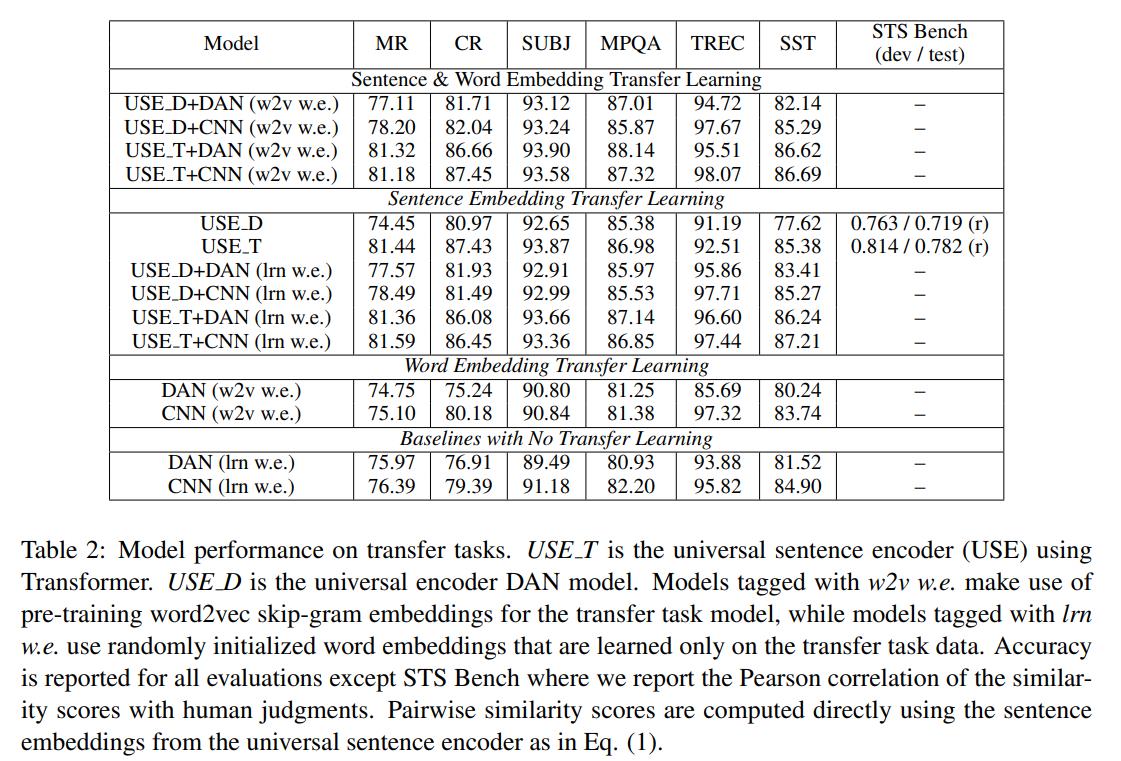
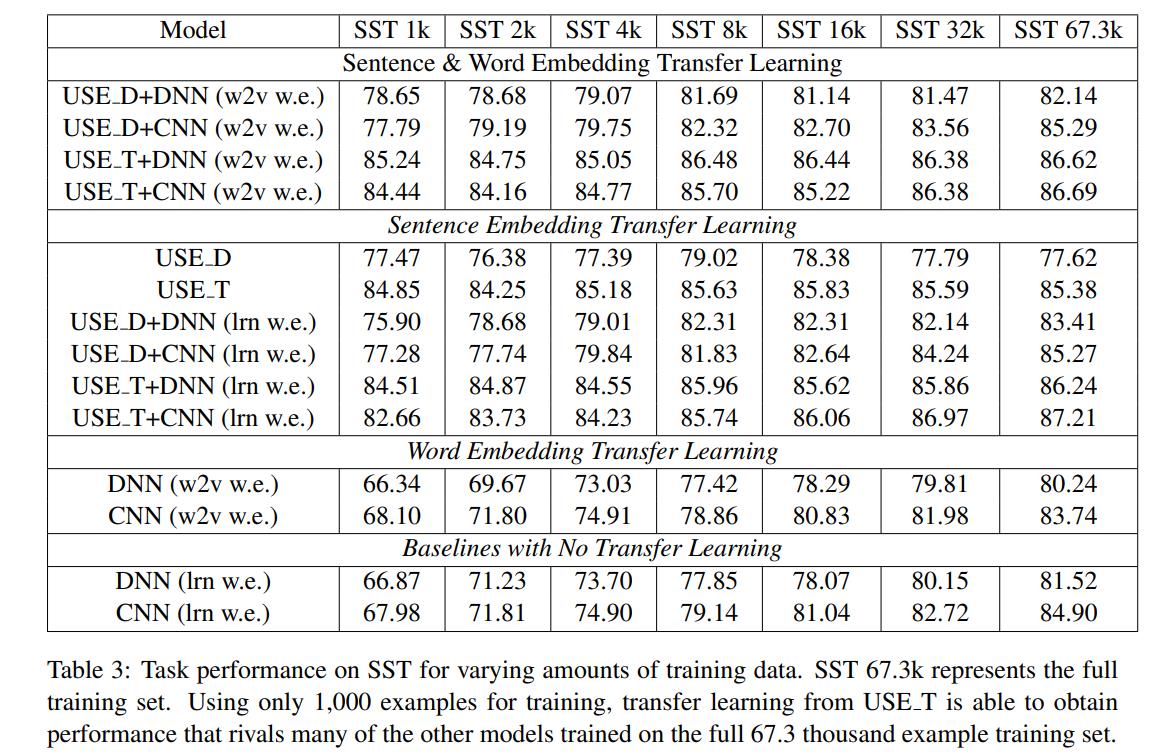
此外,为了证明学习得到的sentence embedding的有效性,文章将其作为参数载入然后在小数据量上进行训练,发现经过transfer learning得到的sentence embedding对应的模型效果在小数据量上就可以快速地达到一个较好的效果。
具体实验可以由下表显示:
4. 结论 & 思考
这篇文章多少有点早了,放到现在事实上已经多少有点累赘了。
这篇文章更多的思考还是集中在如何在标注数据有限的情况下尽可能地利用更多的标注数据,但是现在更多的NLP范式则是考虑如何更有效地利用大量的未标注数据,即通过自监督学习的方式从大量的未标注数据集当中学习其内隐的信息。
因此,这篇工作得到的模型效果事实上到了如今已经没有了什么实用价值,不过他的主要思路,即transfer learning的方式到现今依然还是可以有不少的借鉴意义的,google最新的一篇关于zero-shot learning的文章事实上就是借鉴了transfer learning的思路,对于缺乏数据的场景,不妨多从这个角度去考虑一下。
 《新程序员》:云原生和全面数字化实践
《新程序员》:云原生和全面数字化实践
 50位技术专家共同创作,文字、视频、音频交互阅读
50位技术专家共同创作,文字、视频、音频交互阅读
以上是关于文献阅读:Universal Sentence Encoder的主要内容,如果未能解决你的问题,请参考以下文章
文献阅读:SimCSE:Simple Contrastive Learning of Sentence Embeddings
文献阅读:SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples