Sentence-BERT论文阅读笔记
Posted 梆子井欢喜坨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sentence-BERT论文阅读笔记相关的知识,希望对你有一定的参考价值。
目录
这次阅读笔记主要介绍SBERT的两篇相关论文,第一篇为2019年Nils Reimers团队首次提出SBERT的论文,第二篇为2020年Nils Reimers团队在SBERT上使用的数据增强策略的论文。
SBERT是目前实用性较好的Representation-based的文本匹配模型。SBERT采用了孪生网络的结构,可以输出定长的、保有语义信息的句向量,再通过余弦相似度、曼哈顿距离或欧式距离来计算其相似度。
 (思维导图内容来自李rumor:21个经典深度学习句间关系模型|代码&技巧)
(思维导图内容来自李rumor:21个经典深度学习句间关系模型|代码&技巧)
1. 第一篇论文《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》

1.1 论文基本信息
论文来源:
EMNLP-IJCNLP 2019
论文引用:
Reimers N , Gurevych I . Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
论文链接:
https://arxiv.org/abs/1908.10084
code:
https://www.sbert.net/index.html
摘要:
BERT(Devlin et al.,2018)和RoBERTa(Liu et al.,2019)在句子对打分任务(如语义-文本相似性(STS))上取得了最佳性能。然而,这需要将两个句子都输入到网络中,这会造成巨大的计算开销。例如,在10000个句子的集合中找到最相似的句子对需要使用BERT进行大约5000万次推理计算(~65小时)。BERT的构造使得它不适用于语义相似性搜索以及聚类等无监督任务。
在本文中,我们提出了Sentence-BERT(SBERT),这是对预训练BERT网络的一种修改,它使用孪生网络(siamese)和三重网络结构(triplet network)来推导语义上有意义的句子嵌入,可以使用余弦相似性进行比较。这减少了寻找最相似配对的工作量,从使用BERT/RoBERTa的65小时减少到使用SBERT的约5秒,同时保持了BERT的准确性。
我们评估了SBERT和SRoBERTa在普通STS任务和迁移学习任务中的表现,其表现优于其它最先进的句子嵌入方法。
1.2 动机
解决聚类和语义搜索的一种常用方法是将每个句子映射到向量空间,使得语义相似的句子的向量在向量空间中距离相近。
研究人员已经开始将单个句子输入到BERT中,并导出固定大小的句子嵌入。最常用的方法是平均BERT输出层(称为BERT embeddings)或使用第一个token([CLS]token)的输出。由于BERT本身的结构,这种方式得到的句子嵌入效果相当差,通常比使用GloVe词向量取平均得到的句子嵌入效果更差。
常规做法是将文本匹配转换成二分类任务。输入的两个文本拼接成一个序列(中间用特殊符号“SEP”分割),经过12层或24层Transformer模块编码后,将输出层的字向量取平均或者取“CLS”位置的特征作为句向量,经softmax完成最终分类。

从10,000条句子中找到最相似的一对句子,由于可能的组合众多,需要完成 n ( n − 1 ) / 2 = 49 , 995 , 000 n(n-1)/2 = 49,995,000 n(n−1)/2=49,995,000次推理。
在一块V100 GPU上使用BERT计算,将消耗65小时。
为了解决BERT输出的句子向量效果差\\句子组合输入计算耗时太长的问题,本文提出了SBERT,采用了孪生网络的结构,可以输出定长的、保有语义信息的句向量。再通过余弦距离、曼哈顿距离或欧式距离来计算其相似度。
由于结构具有鲜明的对称性,就像两个孪生兄弟,所以下图这种神经网络结构被研究人员称作“Siamese Network”,即孪生网络。
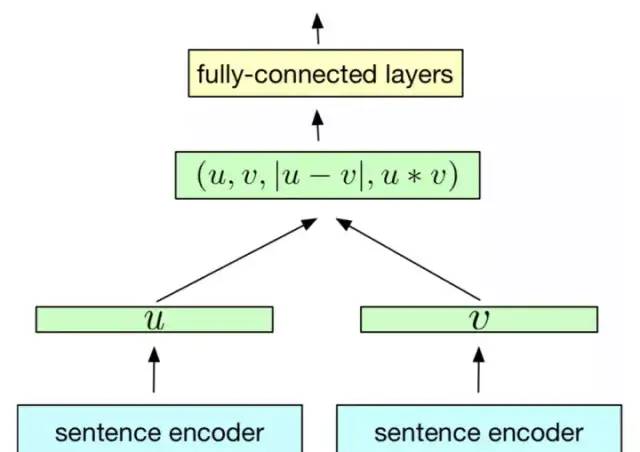
其中最能体现“孪生”的地方,在于网络具有相同的编码器(sentence encoder),即将文本转换为高维向量的部分。网络随后对两段文本的特征进行交互,最后完成分类/相似预测。“孪生网络”结构简单,训练稳定,是很多文本任务不错的baseline模型。
例如,现在我们有文本1和2,首先把它们分别输入 sentence encoder 进行特征提取和编码,将输入映射到新的空间得到特征向量u和v;最终通过u、v的拼接组合,经过下游网络来计算文本1和2的相似性。
整个过程有2个值得关注的点:
- 在训练和测试中,模型的编码器是权重共享的(“孪生”);编码器的选择非常广泛,传统的CNN、RNN和Attention、Transformer都可以
- 得到特征u、v后,可以直接使用cosine距离、欧式距离得到两个文本的相似度;不过更通用的做法是,基于u和v构建用于匹配两者关系的特征向量,然后用额外的模型学习通用的文本关系映射;毕竟我们的场景不一定只是衡量相似度,可能还有问答、蕴含等复杂任务
由于得到了句子的嵌入向量,对于前文提到的任务,只需要计算10000个句子的余弦相似度,再计算这10000个句子的词向量两两的余弦相似度。SBert仅需5秒就能完成!
使用预先训练好的BERT和RoBERTa网络,只对其进行微调,以产生有用的句子嵌入。这大大减少了所需的训练时间:SBERT可以在不到20分钟内调整,同时比类似的句子嵌入方法产生更好的结果。
1.3 模型
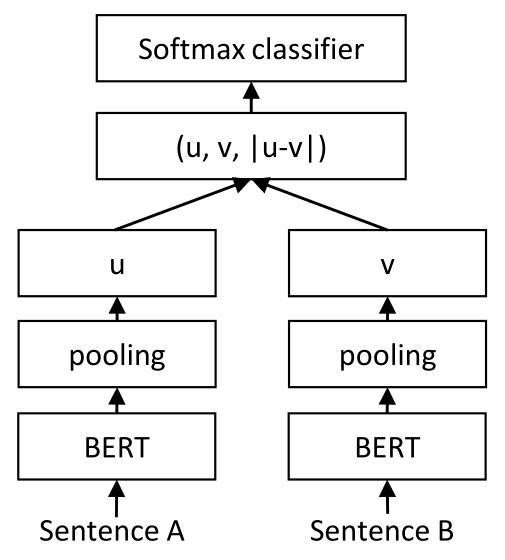
SBERT沿用了孪生网络的结构,文本Encoder部分用同一个BERT来处理。
SBERT在BERT/RoBERTa的输出中添加一个Pooling操作,以导出一个固定大小的句子嵌入。
常用的Pooling操作有:
- CLS-pooling:直接取[CLS]的Embedding
- mean-pooling:取每个Token的平均Embedding
- max-pooling:对得到的每个Embedding取max
为了微调BERT/RoBERTa,创建了孪生和三重网络以更新权重,从而使生成的句子嵌入具有语义意义,并且可以用余弦相似度进行比较。
同时使用了不同的目标函数进行训练。
-
使用分类目标函数
将u、v拼接,接入全连接网络,经softmax分类输出;损失函数用交叉熵。
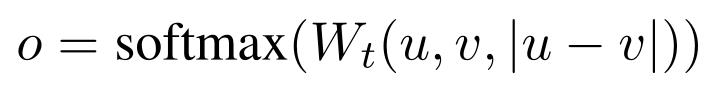
W
t
∈
R
3
n
×
k
W_t \\in R^3n \\times k
Wt∈R3n×k,
n
n
n为句子嵌入的维度,
k
k
k为分类的标签数目
-
回归目标函数
直接计算、输出余弦相似度;训练损失函数采用均方根误差(MSE, mean-squared-error)
-
Triplet Objective Function
论文中也给出了相应的损失函数

对于STS(Semantic Textual Similarity )任务,SOTA方法通常学习一个(复杂的)回归函数,将句子嵌入映射到相似性分数。然而,这些回归函数是成对工作的,并且由于组合数量爆炸( N 2 N^2 N2),如果句子集合达到一定大小,这些函数通常是不可伸缩的。
在测试阶段,SBERT直接使用余弦相似度来衡量两个句向量之间的相似度,极大提升了推理速度。

1.4. 实验
1.4.1 训练所用的数据集
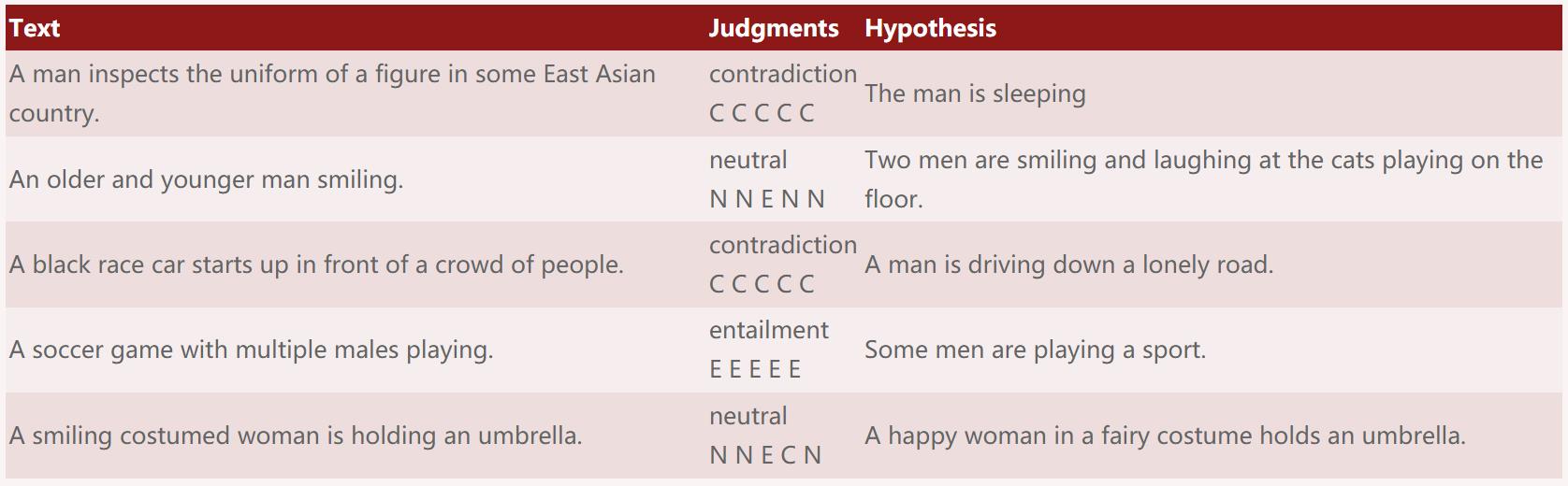
(1)SNLI语料库(1.0版)
https://nlp.stanford.edu/projects/snli/
是一个包含了57w条人工编写的英语句子对的集合,这些句子对经过手动标记以实现平衡分类,并带有蕴含,矛盾和中立(entailment, contradiction, and neutral.)标签,支持自然语言推理(NLI)的任务,也称为文本蕴含识别(textual entailment recognition)。
(2)Multi-Genre NLI
https://cims.nyu.edu/~sbowman/multinli/
Multi-Genre NLI是SNLI的升级版,格式一样,包含43w条英文句子对,不同之处是涵盖了口语和书面文本的一系列体裁,并支持独特的cross-genre transfer 评估
1.4.2 实验结果
测试数据:
-
STS12-STS16:SemEval 2012-2016
-
STSb: STSbenchmark
STS基准(STSb)(Cer等人,2017年)提供了一个流行的数据集,用于评估有监督的STS系统。数据包括8628个句子对,来自三个类别:标题、新闻和论坛。分为train(5749)、dev(1500)和test(1379)。
数据示例:
3.750 A dog is trying to get bacon off his back. A dog is trying to eat the bacon on its back. -
SICK-R: SICK relatedness dataset
无监督实验结果
通过计算句子嵌入的余弦相似度和测试数据给出的参考相似度标签之间的斯皮尔曼秩相关来评估模型。
斯皮尔曼等级相关系数(Spearman’s rank correlation coefficient)
它利用单调方程评价两个统计变量的相关性。若数据中没有重复值,且当两变量完全单调相关时,斯皮尔曼相关系数为 +1 或 −1 。
斯皮尔曼相关系数被定义成等级变量之间的皮尔逊相关系数。对于样本容量为n的样本,n个原始数据
X
i
,
Y
i
X_i,Y_i
Xi,Yi被转换成等级数据
x
i
,
y
i
x_i,y_i
xi,yi相关系数为
ρ
=
∑
i
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
∑
i
(
x
i
−
x
ˉ
)
2
∑
i
(
y
i
−
y
ˉ
)
2
\\Large \\rho =\\frac \\sum _i(x_i-\\bar x)(y_i-\\bar y)\\sqrt \\sum _i(x_i-\\bar x)^2\\sum _i(y_i-\\bar y)^2
ρ=∑i(xi−xˉ)2∑i(yi−yˉ)2∑i(xi−xˉ)(yi−yˉ)
等级数据 x i , y i x_i,y_i xi,yi是每个原始数据的降序位置的平均。
| 变量 | 降序位置(仅示意,不使用) | 降序位置的平均(使用) |
|---|---|---|
| 0.8 | 5 | 5 |
| 1.2 | 4 | 4 + 3 2 = 3.5 \\frac 4+3 2 = 3.5 24+3=3.5 |
| 1.2 | 3 | 4 + 3 2 = 3.5 \\frac 4+3 2 = 3.5 24+3=3.5 |
| 2.3 | 2 | 2 |
| 18 | 1 | 1 |
实际应用中,变量间的连结是无关紧要的,于是可以通过简单的步骤计算 ρ。
被观测的两个变量的等级的差值 d i = x i − y i d_i = x_i - y_i di=xi−yi,则 ρ = 1 − 6 ∑ d i 2 n ( n 2 − 1 ) \\Large \\rho =1-\\frac 6\\sum d_i^2n(n^2-1) ρ=1−n(n2−1)6∑di2
正的斯皮尔曼相关系数反应两个变量 X 和 Y 单调递增的趋势。
结果表明,直接使用BERT的输出会导致相当差的性能。平均BERT嵌入实现的平均相关性仅为54.81,并且使用[CLS]token输出仅实现29.19的平均相关性。两者都比计算平均Glove词向量的效果差。
使用本文所提出的孪生网络结构和微调机制显著提高了相关性,大大优于InferSent和USE。
SBERT的表现比USE差的唯一数据集是SICK-R。
有监督实验结果
进行两部分的实验,只在STSb数据集上训练和先在NLI数据集上训练,再在STSb数据集上训练。
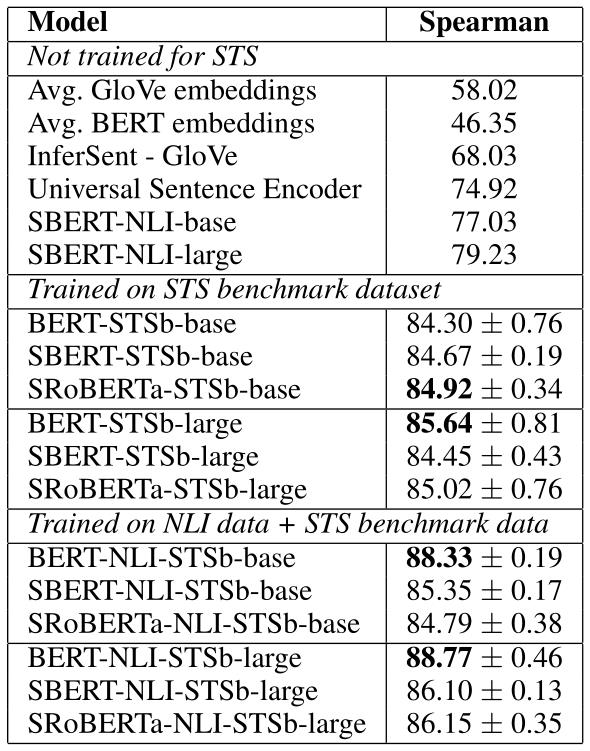
可以发现,更多的训练数据,带来了效果上的提升。同时,BERT和RoBERTa之间没有显著的性能差异。
1.4.3 消融实验
首先评估不同的池化策略,其次对于分类目标函数,评估不同的u,v向量拼接策略。
对于分类目标函数,我们基于SNLI和多NLI数据集训练SBERT。
对于回归目标函数,我们在STS基准数据集的训练集上进行训练。
使用余弦相似性和斯皮尔曼秩相关在STSb的dev set上评估。

当在NLI数据集上使用分类目标函数训练时,池化策略的影响非常小,u,v向量拼接方式的影响要更大一些。最重要的部分是element-
wise difference:
∣
u
−
v
∣
|u-v|
∣u−v∣,度量两个句子嵌入的维度之间的距离,确保相似对更接近,而不同对更远离。
1.5 小结
抛开具体任务,SBERT 可以帮助我们生成更好的句向量,在一些任务上可能产生更优结果。在推理阶段,SBert直接计算余弦相似度的方式,大大缩短了预测时间,在语义检索、信息搜索等任务中预计会有不错表现。
2. 第二篇论文:Augmented SBERT: Data augmentation method for improving bi-encoders for pairwise sentence scoring tasks

2.1 论文基本信息
论文来源:
arXiv
论文引用:
Thakur N, Reimers N, Daxenberger J, et al. Augmented sbert: Data augmentation method for improving bi-encoders for pairwise sentence scoring tasks[J]. arXiv preprint arXiv:2010.08240, 2020.
论文链接:
https://arxiv.org/abs/2010.08240
code:
https://www.sbert.net/index.html
摘要:
句子对评分有两种方法:一是Cross-encoders,对输入对执行full-attention;二是Bi-encoders,将每个输入独立地映射到密集向量空间。虽然Cross-encoders通常可以获得更高的性能,但对于许多实际使用场景来说,它们的速度太慢了。另一方面,Bi-encoders需要大量的训练数据和针对目标任务的微调,使模型达到具有竞争力的性能。本文提出了一种简单而有效的数据增强策略,称为增强SBERT,其中我们使用Cross-encoders来标记一组数据更多的输入对,以增强Bi-encoders的训练数据。我们展示了,在这个过程中,选择句子对是非常重要的,也是该方法成功的关键。我们在多个领域内任务和一个领域自适应任务上评估我们的方法。与Bi-encoders性能相比,增强SBERT在领域内任务和领域自适应任务上分别提高了6个百分点和37个百分点。
2.2 动机
通常Cross-encoders的性能指标更佳,但是运行效率不高,同时因为不能为可索引的输入生成独立的向量表示。相反,bi-encoders如SBERT,可以对每个句子进行独立编码,并将其映射到稠密向量空间,允许高效的索引和比较。
下面是一个对比试验,用经过微调的cross-encoder(BERT)和经过微调的bi-encoder(SBERT)做对比,两种模型使用不同规模的训练数据在STSb数据集上的测试分数对比。

可以发现,当训练数据不足的时候,性能的差距最为明显。因此,本文提出了一种数据增强的方法,称为Augmented SBERT(AugSBERT)
2.3 模型
2.3.1 Augmented SBERT
给定一个经过预训练、性能良好的cross-encoder,我们根据特定的采样策略(稍后讨论)对句子对进行采样,并使用cross-encoder标记这些句子对。我们将这些弱标记的示例称为silver数据集,它们将与gold训练数据集合并。然后,我们在这个扩展的训练数据集上训练bi-encoder。我们将此模型称为Augmented SBERT(AugSBERT)。

句子对采样策略:
使用cross-encoder标记的新句子对可以是新数据,也可以重复使用gold训练集中的单个句子并重新组合。在我们的领域内实验中,我们重复使用来自gold训练集的句子。
因为 n n n个句子就有 n × ( n − 1 ) / 2 n \\times (n-1)/2 n×(n−1)/2种可能的组合,选择正确的采样策略对性能提升是十分重要的。
-
Random Sampling(RS)
随机抽样,随机选择两个句子通常会抽出一对不相似的句子,会使silver数据集的标签分布极度的倾向负对。
-
Kernel Density Estimation (KDE)
目标是为silver数据集获得与golden训练集相似的标签分布。为此,我们对一大组随机抽样的对进行弱标记,然后只保留某些对。
对于分类任务,我们保留sliver数据集中的所有正对。随后,我们从剩余的负对中随机抽取一些,使得sliver数据集的分布(正/负)比例与golden数据集训练相同。
对于回归任务,我们使用核密度估计(KDE)来估计分数s的连续密度函数 F g o l d ( s ) F_gold(s) Fgold(s)和 F s l i v e r ( s ) F_sliver(s) Fsliver(s)。试图最小化分布间的K-L散度。
以概率 Q ( s ) Q(s) Q(s)保留得分为 s s s的样本。
