文献阅读:SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples
Posted Espresso Macchiato
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读:SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples相关的知识,希望对你有一定的参考价值。
1. 内容简介
这篇文章算是SimCSE的一个进阶版本吧,关于SimCSE的介绍之前我已经写了一篇小博客(文献阅读:SimCSE:Simple Contrastive Learning of Sentence Embeddings)介绍了一下了,这篇文章感觉像是基于SimCSE之后的一个优化版本。
文章关注的问题依然是nlp当中sentence的embedding表征学习方面的工作,和SimCSE一样,它同样采用了对比学习的方式来优化效果,不过对于embedding的获取方法,与SimCSE的直接取用[CLS]标志的embedding不同,它采用了prompt learning的方式来获取文本的embedding。
此外,文中还特别针对了语义表达进行了优化。
文本表征的一个常见问题就是文本相似度很高,但是语义相反的情况,比如今天天气很好和今天天气不好。他们的语义是完全相反的,但是往往在NLP模型当中获得的两个句子的sentence embedding表达确实非常相似的,因为他们的token组成还有文本描述都是非常接近的,因此就会被模型混淆。
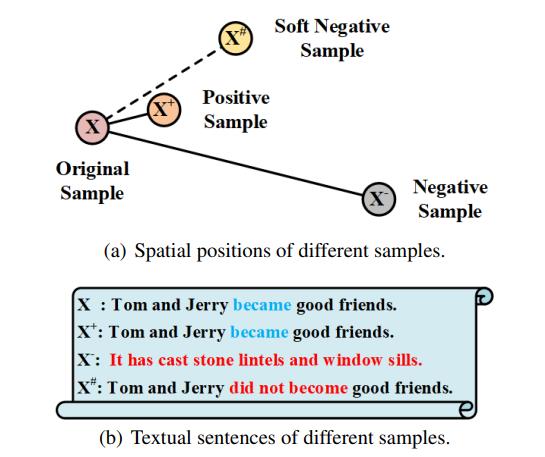
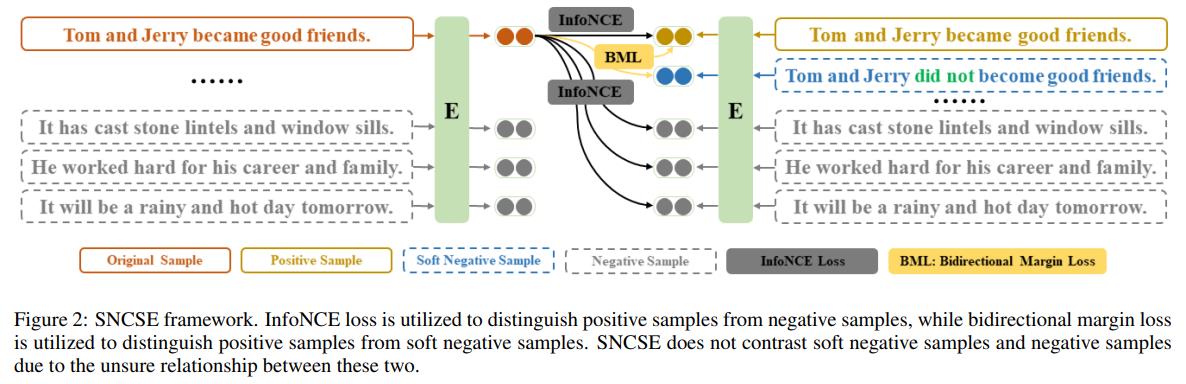
因此,文中提出了一种soft negative sample的方式来强制模型学习这种语义上的相反信息,然后增设了一个BML Loss来加强模型对这方面特征的学习,从而优化模型的效果。
整体的优化方案可以从下述图片当中获得比较直观的了解。
2. 方法实现
下面,我们来考察一下其具体的方法实现。
1. embedding的获取
首先,关于sentence的embedding获取方式,如前所述,与传统的bert通过[CLS]token来获取sentence embedding的方式略有不同,文中借鉴了prompt learning的方式,具体而言,对于任意的sentence
X
X
X,通过构造这样的文本:
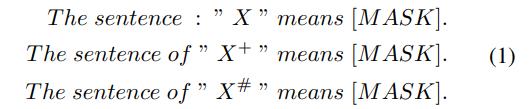
其中,3个[MASK]的embedding对应着三个句子的embedding,而
X
+
X^+
X+代表正例,事实上就是原始的文本输入,而
X
#
X^\\#
X# 代表soft negative sample。
不过坦率地说个人对于这里的prompt方法的必要性是多少有点存疑的,因为感觉基于bert的finetune,而且也没有给出其他的任务数据进行数据增强,那么获取sentence embedding的方式prompt learning和原始的[CLS]直接获取的方式应该是一样的,这里感觉有点强行蹭热度了,不过具体就不知道文中作者他们是不是有做相关的对比实验了,也可能纯粹是我想当然了……
2. soft negative样品的生成
而关于soft negative样品的生成方法,其实这个算是文中最核心的优化部分了。
正常来说,我们是无法获得这种soft negative样本的,文中事实上是采用了一种相对暴力的方式进行了实现。
具体而言,他其实是先调用了一个外部工具叫做spaCy的工具获取了文本的dependence parsing树结构,然后通过一些rule base的方式生成了与原文表达相近但是语义相反的文本。
所以某种意义上,个人觉得其实这也就是一种更好的数据增强的方式,个人觉得这部分内容才是这篇文章的精髓所在,可惜他没有给出具体的介绍,code大致扫了一下,似乎也没找到对应的部分……
3. loss函数的定义
最后,关于loss的定义,由于soft negative sample的存在,文中为其单独设置了一个loss来进行优化,即文中提到的BML(bidirectional margin loss)损失函数。
其具体的函数定义如下:
Δ
=
c
o
s
(
s
i
m
(
h
i
,
h
i
#
)
)
−
c
o
s
(
s
i
m
(
h
i
,
h
i
+
)
)
\\Delta = cos(sim(h_i, h_i^\\#)) - cos(sim(h_i, h_i^+))
Δ=cos(sim(hi,hi#))−cos(sim(hi,hi+))
L B M L = R e L U ( Δ + α ) + R e L U ( − Δ − β ) L_BML = ReLU(\\Delta + \\alpha) + ReLU(-\\Delta - \\beta) LBML=ReLU(Δ+α)+ReLU(−Δ−β)
而对于正常的负例,则使用普通的loss就行了,具体而言,就是:
L I n f o C S E = − l o g e c o s ( s i m ( h i , h i + ) ) / τ ∑ j e c o s ( s i m ( h i , h j + ) ) / τ L_InfoCSE = - log\\frace^cos(sim(h_i, h_i^+)) / \\tau\\sum_j e^cos(sim(h_i, h_j^+)) / \\tau LInfoCSE=−log∑jecos(sim(hi,hj+))/τecos(sim(hi,hi+))/τ
而整体的loss函数就定义为:
L S N C S E = L I n f o C S E + λ L B M L L_SNCSE = L_InfoCSE + \\lambda L_BML LSNCSE=LInfoCSE+λLBML
另外,出于对比实验的考虑,文中还给出了两个对比实验,分别就是将soft negative sample当成纯粹的正例以及纯粹的负例的情况进行考察,具体的两种Loss函数如下:
-
视为纯粹的正例
L P L = − l o g e c o s ( s i m ( h i , h i + ) ) / τ ∑ j e c o s ( s i m ( h i , h j + ) ) / τ − l o g e c o s ( s i m ( h i , h i # ) ) / τ ∑ j e c o s ( s i m ( h i , h j # ) ) / τ L_PL = - log\\frace^cos(sim(h_i, h_i^+)) / \\tau\\sum_j e^cos(sim(h_i, h_j^+)) / \\tau - log\\frace^cos(sim(h_i, h_i^\\#)) / \\tau\\sum_j e^cos(sim(h_i, h_j^\\#)) / \\tau LPL=−log∑jecos(sim(hi,hj+))/τecos(sim(hi,hi+))/τ−log∑jecos(sim(hi,hj#))/τecos(sim(hi,hi#))/τ
-
视为纯粹的负例
L N L = − l o g e c o s ( s i m ( h i , h i + ) ) / τ ∑ j e c o s ( s i m ( h i , h j + ) ) / τ + e c o s ( s i m ( h i , h i # ) ) / τ L_NL = - log\\frace^cos(sim(h_i, h_i^+)) / \\tau\\sum_j e^cos(sim(h_i, h_j^+)) / \\tau + e^cos(sim(h_i, h_i^\\#))/\\tau LNL=−log∑jecos(sim(hi,hj+))/τ+ecos(sim(hi,hi#))/τe以上是关于文献阅读:SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples的主要内容,如果未能解决你的问题,请参考以下文章