决策树算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树算法相关的知识,希望对你有一定的参考价值。
参考技术A 决策树算法的算法理论和应用场景算法理论:
我了解的决策树算法,主要有三种,最早期的ID3,再到后来的C4.5和CART这三种算法。
这三种算法的大致框架近似。
决策树的学习过程
1.特征选择
在训练数据中 众多X中选择一个特征作为当前节点分裂的标准。如何选择特征有着很多不同量化评估标准,从而衍生出不同的决策树算法。
2.决策树生成
根据选择的特征评估标准,从上至下递归生成子节点,直到数据集不可分或者最小节点满足阈值,此时决策树停止生长。
3.剪枝
决策树极其容易过拟合,一般需要通过剪枝,缩小树结构规模、缓解过拟合。剪枝技术有前剪枝和后剪枝两种。
有些算法用剪枝过程,有些没有,如ID3。
预剪枝:对每个结点划分前先进行估计,若当前结点的划分不能带来决策树的泛化性能的提升,则停止划分,并标记为叶结点。
后剪枝:现从训练集生成一棵完整的决策树,然后自底向上对非叶子结点进行考察,若该结点对应的子树用叶结点能带来决策树泛化性能的提升,则将该子树替换为叶结点。
但不管是预剪枝还是后剪枝都是用验证集的数据进行评估。
ID3算法是最早成型的决策树算法。ID3的算法核心是在决策树各个节点上应用信息增益准则来选择特征,递归构建决策树。缺点是,在选择分裂变量时容易选择分类多的特征,如ID值【值越多、分叉越多,子节点的不纯度就越小,信息增益就越大】。
ID3之所以无法 处理缺失值、无法处理连续值、不剪纸等情况,主要是当时的重点并不是这些。
C4.5算法与ID3近似,只是分裂标准从 信息增益 转变成 信息增益率。可以处理连续值,含剪枝,可以处理缺失值,这里的做法多是 概率权重。
CART:1.可以处理连续值 2.可以进行缺失值处理 3.支持剪枝 4.可以分类可以回归。
缺失值的处理是 作为一个单独的类别进行分类。
建立CART树
我们的算法从根节点开始,用训练集递归的建立CART树。
1) 对于当前节点的数据集为D,如果样本个数小于阈值或者没有特征,则返回决策子树,当前节点停止递归。
2) 计算样本集D的基尼系数, 如果基尼系数小于阈值 (说明已经很纯了!!不需要再分了!!),则返回决策树子树,当前节点停止递归。
3) 计算当前节点现有的各个特征的各个特征值对数据集D的基尼系数。
4) 在计算出来的各个特征的各个特征值对数据集D的基尼系数中,选择 基尼系数最小的特征A和对应的特征值a。根据这个最优特征和最优特征值,把数据集划分成两部分D1和D2,同时建立当前节点的左右节点,做节点的数据集D为D1,右节点的数据集D为D2。 (注:注意是二叉树,故这里的D1和D2是有集合关系的,D2=D-D1)
5) 对左右的子节点递归的调用1-4步,生成决策树。
CART采用的办法是后剪枝法,即先生成决策树,然后产生所有可能的剪枝后的CART树,然后使用交叉验证来检验各种剪枝的效果,选择泛化能力最好的剪枝策略。
应用场景
比如欺诈问题中,通过决策树算法简单分类,默认是CART的分类树,默认不剪枝。然后在出图后,自行选择合适的叶节点进行拒绝操作。
这个不剪枝是因为欺诈问题的特殊性,欺诈问题一般而言较少,如数据的万几水平,即正样本少,而整个欺诈问题需要解决的速度较快。此时只能根据业务要求,迅速针对已有的正样本情况,在控制准确率的前提下,尽可能提高召回率。这种情况下,可以使用决策树来简单应用,这个可以替代原本手工选择特征及特征阈值的情况。
实验四 决策树算法及应用
| 博客班级 | 计算机与信息学院AHPU-机器学习实验-计算机18级 |
|---|---|
| 作业要求 | 实验四 决策树算法及应用 |
| 作业目标 | (1)理解决策树算法原理,掌握决策树算法框架; |
| (2)理解决策树学习算法的特征选择、树的生成和树的剪枝; | |
| (3)能根据不同的数据类型,选择不同的决策树算法; | |
| (4)针对特定应用场景及数据,能应用决策树算法解决实际问题。 | |
| 学号 | <3180701116> |
一、【实验目的】
理解决策树算法原理,掌握决策树算法框架;
理解决策树学习算法的特征选择、树的生成和树的剪枝;
能根据不同的数据类型,选择不同的决策树算法;
针对特定应用场景及数据,能应用决策树算法解决实际问题。
二、【实验内容】
设计算法实现熵、经验条件熵、信息增益等方法。
实现ID3算法。
熟悉sklearn库中的决策树算法;
针对iris数据集,应用sklearn的决策树算法进行类别预测。
针对iris数据集,利用自编决策树算法进行类别预测。
三、【实验报告要求】
对照实验内容,撰写实验过程、算法及测试结果;
代码规范化:命名规则、注释;
分析核心算法的复杂度;
查阅文献,讨论ID3、5算法的应用场景;
查询文献,分析决策树剪枝策略。
四、实验内容及结果
实验代码及截图
1.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
from math import log
import pprint
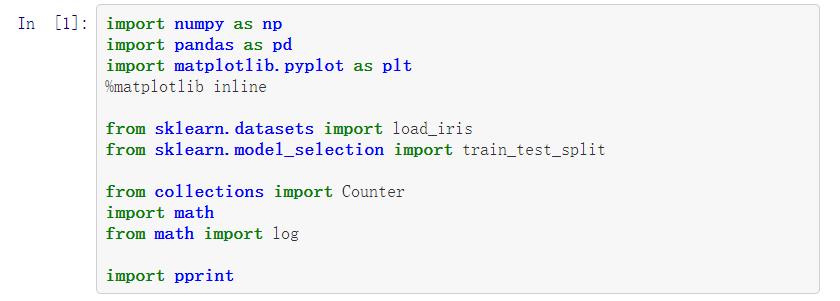
# 书上题目5.1
def create_data():
datasets = [[\'青年\', \'否\', \'否\', \'一般\', \'否\'],
[\'青年\', \'否\', \'否\', \'好\', \'否\'],
[\'青年\', \'是\', \'否\', \'好\', \'是\'],
[\'青年\', \'是\', \'是\', \'一般\', \'是\'],
[\'青年\', \'否\', \'否\', \'一般\', \'否\'],
[\'中年\', \'否\', \'否\', \'一般\', \'否\'],
[\'中年\', \'否\', \'否\', \'好\', \'否\'],
[\'中年\', \'是\', \'是\', \'好\', \'是\'],
[\'中年\', \'否\', \'是\', \'非常好\', \'是\'],
[\'中年\', \'否\', \'是\', \'非常好\', \'是\'],
[\'老年\', \'否\', \'是\', \'非常好\', \'是\'],
[\'老年\', \'否\', \'是\', \'好\', \'是\'],
[\'老年\', \'是\', \'否\', \'好\', \'是\'],
[\'老年\', \'是\', \'否\', \'非常好\', \'是\'],
[\'老年\', \'否\', \'否\', \'一般\', \'否\'],
]
labels = [u\'年龄\', u\'有工作\', u\'有自己的房子\', u\'信贷情况\', u\'类别\']
# 返回数据集和每个维度的名称
return datasets, labels

datasets, labels = create_data()

train_data = pd.DataFrame(datasets, columns=labels)

train_data
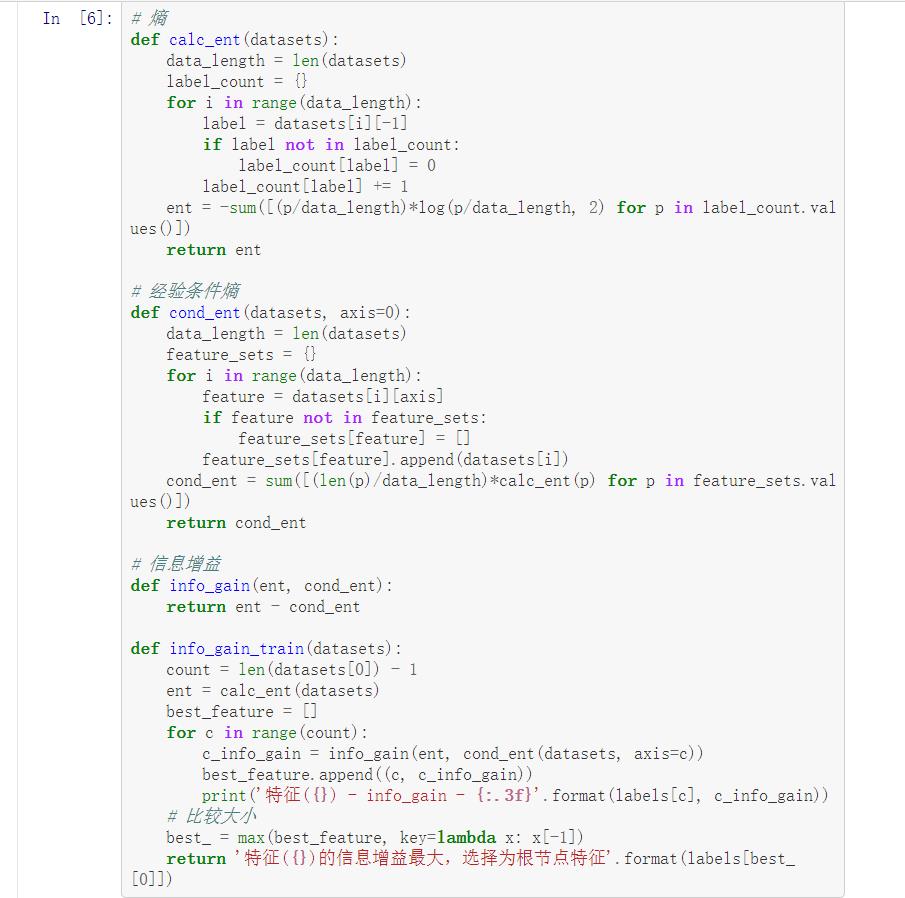
# 熵
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p/data_length)*log(p/data_length, 2) for p in label_count.values()])
return ent
# 经验条件熵
def cond_ent(datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p)/data_length)*calc_ent(p) for p in feature_sets.values()])
return cond_ent
# 信息增益
def info_gain(ent, cond_ent):
return ent - cond_ent
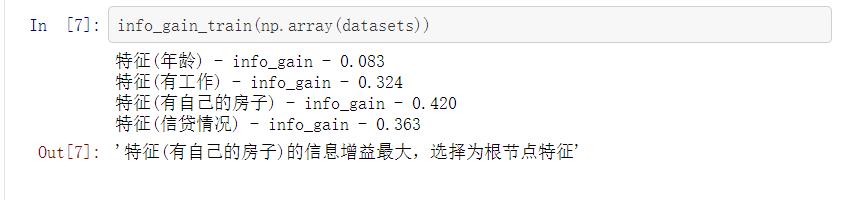
def info_gain_train(datasets):
count = len(datasets[0]) - 1
ent = calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = info_gain(ent, cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
print(\'特征({}) - info_gain - {:.3f}\'.format(labels[c], c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return \'特征({})的信息增益最大,选择为根节点特征\'.format(labels[best_[0]])
info_gain_train(np.array(datasets))
# 定义节点类 二叉树
class Node:
def __init__(self, root=True, label=None, feature_name=None, feature=None):
self.root = root
self.label = label
self.feature_name = feature_name
self.feature = feature
self.tree = {}
self.result = {\'label:\': self.label, \'feature\': self.feature, \'tree\': self.tree}
def __repr__(self):
return \'{}\'.format(self.result)
def add_node(self, val, node):
self.tree[val] = node
def predict(self, features):
if self.root is True:
return self.label
return self.tree[features[self.feature]].predict(features)
class DTree:
def __init__(self, epsilon=0.1):
self.epsilon = epsilon
self._tree = {}
# 熵
@staticmethod
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p/data_length)*log(p/data_length, 2) for p in label_count.values()])
return ent
# 经验条件熵
def cond_ent(self, datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p)/data_length)*self.calc_ent(p) for p in feature_sets.values()])
return cond_ent
# 信息增益
@staticmethod
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(self, datasets):
count = len(datasets[0]) - 1
ent = self.calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return best_
def train(self, train_data):
"""
input:数据集D(DataFrame格式),特征集A,阈值eta
output:决策树T
"""
_, y_train, features = train_data.iloc[:, :-1], train_data.iloc[:, -1], train_data.columns[:-1]
# 1,若D中实例属于同一类Ck,则T为单节点树,并将类Ck作为结点的类标记,返回T
if len(y_train.value_counts()) == 1:
return Node(root=True,
label=y_train.iloc[0])
# 2, 若A为空,则T为单节点树,将D中实例树最大的类Ck作为该节点的类标记,返回T
if len(features) == 0:
return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0])
# 3,计算最大信息增益 同5.1,Ag为信息增益最大的特征
max_feature, max_info_gain = self.info_gain_train(np.array(train_data))
max_feature_name = features[max_feature]
# 4,Ag的信息增益小于阈值eta,则置T为单节点树,并将D中是实例数最大的类Ck作为该节点的类标记,返回T
if max_info_gain < self.epsilon:
return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0])
# 5,构建Ag子集
node_tree = Node(root=False, feature_name=max_feature_name, feature=max_feature)
feature_list = train_data[max_feature_name].value_counts().index
for f in feature_list:
sub_train_df = train_data.loc[train_data[max_feature_name] == f].drop([max_feature_name], axis=1)
# 6, 递归生成树
sub_tree = self.train(sub_train_df)
node_tree.add_node(f, sub_tree)
# pprint.pprint(node_tree.tree)
return node_tree
def fit(self, train_data):
self._tree = self.train(train_data)
return self._tree
def predict(self, X_test):
return self._tree.predict(X_test)
datasets, labels = create_data()
data_df = pd.DataFrame(datasets, columns=labels)
dt = DTree()
tree = dt.fit(data_df)

tree

dt.predict([\'老年\', \'否\', \'否\', \'一般\'])

# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df[\'label\'] = iris.target
df.columns = [\'sepal length\', \'sepal width\', \'petal length\', \'petal width\', \'label\']
data = np.array(df.iloc[:100, [0, 1, -1]])
# print(data)
return data[:,:2], data[:,-1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)

from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz

clf = DecisionTreeClassifier()
clf.fit(X_train, y_train,)
clf.score(X_test, y_test)

tree_pic = export_graphviz(clf, out_file="mytree.pdf")
with open(\'mytree.pdf\') as f:
dot_graph = f.read()

graphviz.Source(dot_graph)
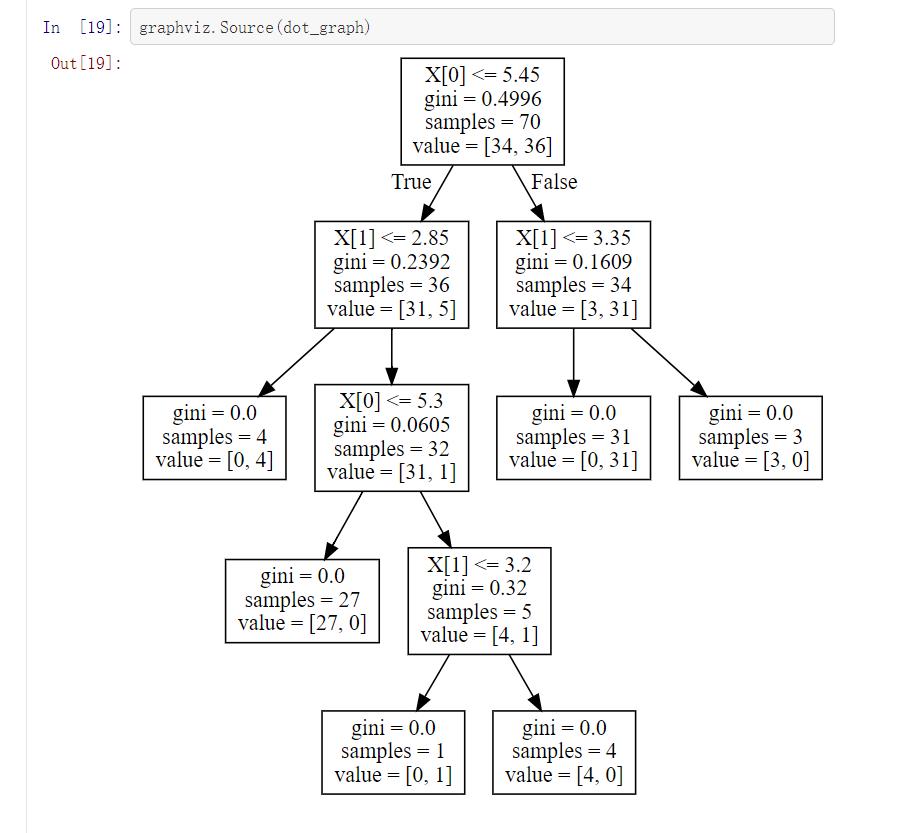
五、实验小结
本次实验是关于决策树的算法,其实决策树本质上是从训练数据集中归纳出一组分类规则。在判断一个决策树的性能好坏时,应该关注特征属性的本质和分类性能。决策树虽然也是一个良好的分类算法,但是它也面对一下问题:比如多度拟合,当数据中有噪声或训练样例的数量太少以至于不能产生目标函数的有代表性的采样时。
讨论ID3、C4.5算法的应用场景:
ID3算法应用场景:
它的基础理论清晰,算法比较简单,学习能力较强,适于处理大规模的学习问题,是数据挖掘和知识发现领域中的一个很好的范例,为后来各学者提出优化算法奠定了理论基础。ID3算法特别在机器学习、知识发现和数据挖掘等领域得到了极大发展。
C4.5算法应用场景:
C4.5算法具有条理清晰,能处理连续型属性,防止过拟合,准确率较高和适用范围广等优点,是一个很有实用价值的决策树算法,可以用来分类,也可以用来回归。C4.5算法在机器学习、知识发现、金融分析、遥感影像分类、生产制造、分子生物学和数据挖掘等领域得到广泛应用。
分析决策树剪枝策略:
剪枝的目的在于:缓解决策树的"过拟合",降低模型复杂度,提高模型整体的学习效率
(决策树生成学习局部的模型,而决策树剪枝学习整体的模型)
基本策略:
预剪枝:是指在决策树生成过程中,对每一个结点在划分前进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶子结点。
优点:降低了过拟合地风险,并显著减少了决策树地训练时间开销和测试时间开销。
缺点:有些分支地当前划分虽不能提升泛化性能、甚至可能导致泛化性能下降,但是在其基础上进行地后续划分却可能导致性能显著提高;
预剪枝基于\'贪心\'本质禁止这些分支展开,给预剪枝决策树带来了欠拟合的风险。
后剪枝:先从训练集生成一棵完整的决策树,然后自底向上地对非叶子结点进行考察,若将该结点对应地子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
优点:一般情况下后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。
缺点:自底向上的注意考察,时间开销较高。
以上是关于决策树算法的主要内容,如果未能解决你的问题,请参考以下文章