Hadoop之深入HDFS原理<一>
Posted 月疯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之深入HDFS原理<一>相关的知识,希望对你有一定的参考价值。
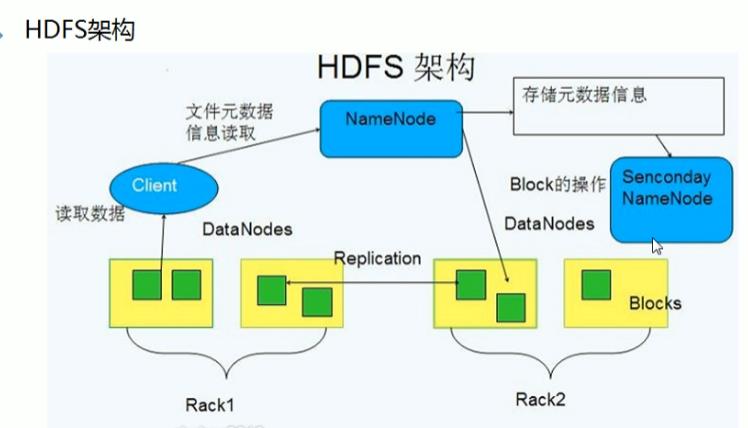
1、HDFS原理
1、三大组件(NameNode、DataNode、SecondaryNameNode)
2、NameNode
a、作用:存储元数据(文件名、创建时间、大小、权限、文件与block块映射关系)
b、数据存储目录:dfs.namenode.name.dir
3、DataNode
a、作用:存储真是的数据信息
b、数据存储目录:dfs.datanode.data.dir
c、block块:默认128M,通过dffs.blockzize设置
d、副本策略:1、默认3个副本,通过dfs.replication配置
2、存放形式
I、如果客户端在集群中,第一个副本放到客户端机器上;否则第一个副本随即挑选一个不忙的机器
ii、第二个副本放到和第一个副本不同的机架上的一个服务器上
iii、第三个副本放到和第二个副本相同机架不同服务器上
iiii、如果还有更多副本,就随即存放
4、SecondaryNameNode
a、作用:减轻NameNode压力,将edits编辑日志文件和fsimage镜像文件进行合并

NameNode补充:
数据存储在hdfs-site.xml的dfs.namenode.name.dir属性配置中
1、fsimage:镜像文件,存储某段时间内存元数据信息和文件与Block块的映射关系(NameNode第一映射关系)
2、edits:编辑日志文件
3、seen_txid:操作事物id
4、VERSION:存储命名空间ID、集群ID等信息
多次格式化namenode的问题原因解释
hdfs格式化会改变VERSION文件中的clusterID,首次格式化datanode和namenode会产生相同的clusterID;如果重新执行格式化,namenode的clusterID改变,就会与datanade的cclusterID不一致,如果重新启动或读写hdfs就会挂掉。
解释镜像文件:
镜像是一种文件存储形式,是冗余的一种类型,一个磁盘上的数据在另一个磁盘上存在一个完全相同的副本即为镜像,常见的镜像文件格式有ISO、BIN、IMG、TAO、DAO、CIF、FCD。
DataNode和NameNode之间通讯:

NameNode和secondaryNameNode通讯机制:

SecondaryNameNode(SNN)执行流程
SNN周期性地向NN发送请求,NN申城一个新的edits文件
NN将edits文件和fsimage文件发送给SNN
SNN将fsimage文件加载到内存,合并edits文件,生成新的fsimage.ckpt文件
SNN将新的faimage.ckpt文件发给NN
NN用新的fsimage.ckpt代替旧的fsimage文件,重命名edits.new为edits文件
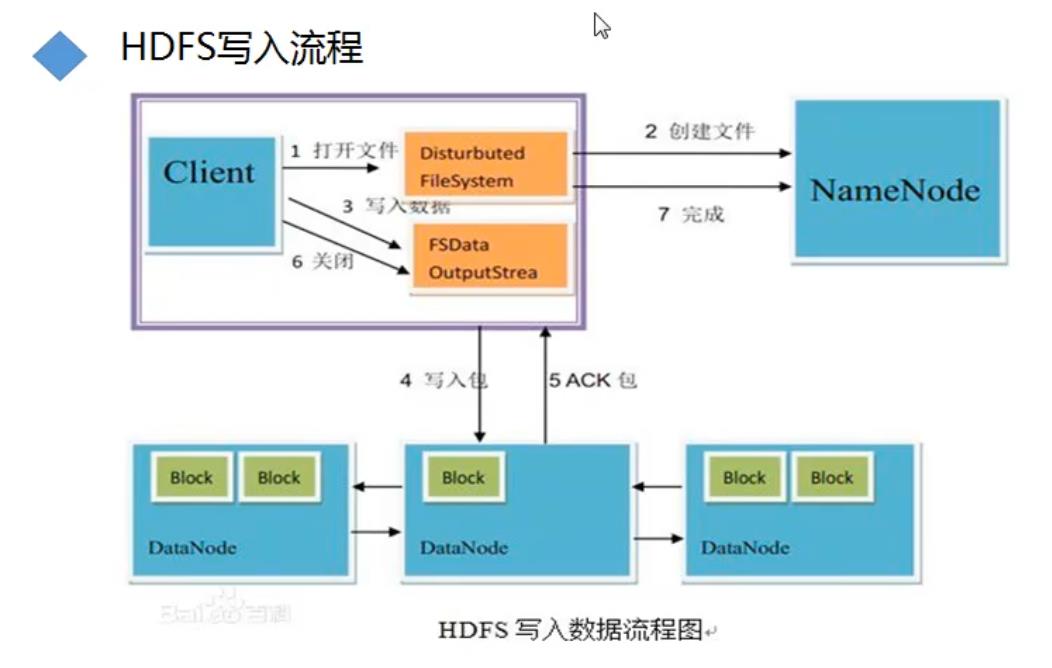
HDFS的写流程:

HDFS的读流程:

HDFS读取流程:
1、client客户端向远程NN发送RPC请求
2、NN查找文件对应的block块及存放的DN地址,返回给Client端
3、Client端以pipeline的方式从DN中读取各个block块数据
4、Client端读取block块后,使用校验和验证,判断block是否损坏。如果损坏,读取另外DN上的数据;如果没有损坏,通知NN,继续下一个block块读取
安全模式:
含义:客户端只能进行查看,不能进行写入、删除操作
作用:NN启动后进入安全模式,检查数据块和DN的完整性,
达到下面三个条件就退出安全模式



以上是关于Hadoop之深入HDFS原理<一>的主要内容,如果未能解决你的问题,请参考以下文章