hadoop之MapReducer作业的提交执行过程
Posted 奔跑-起点
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop之MapReducer作业的提交执行过程相关的知识,希望对你有一定的参考价值。
debug信息
列出要切片的所有文件:[DeprecatedRawLocalFileStatuspath=file:/D:/a.txt; isDirectory=false; length=58; replication=1; blocksize=33554432; modification_time=1481531168562; access_time=0; owner=; group=; permission=rw-rw-rw-; isSymlink=false]
文件block信息[0,58,localhost]起始位置偏移量,长度,所在主机判断是不是可以切分
获取block块大小
计算切片大小,返回splitSize
执行切片逻辑:
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP)SPLIT_SLOP=1.1待切片大小/splitSize必须大于1.1倍的时候才进行切下一个
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));将切好的放入集合
[file:/D:/a.txt:0+58]返回切好的切片包括地址起始位置和长度
加入数组进行排序大的放在前边
返回数组大小,设置map的数量
writeConf(conf, submitJobFile);将job的信息写入描述文件.....
bbaiggey/mapred/local/localRunner/hadoop/job_local1171546085_0001/job_local1171546085_0001.xml----拷贝资源到运行目录
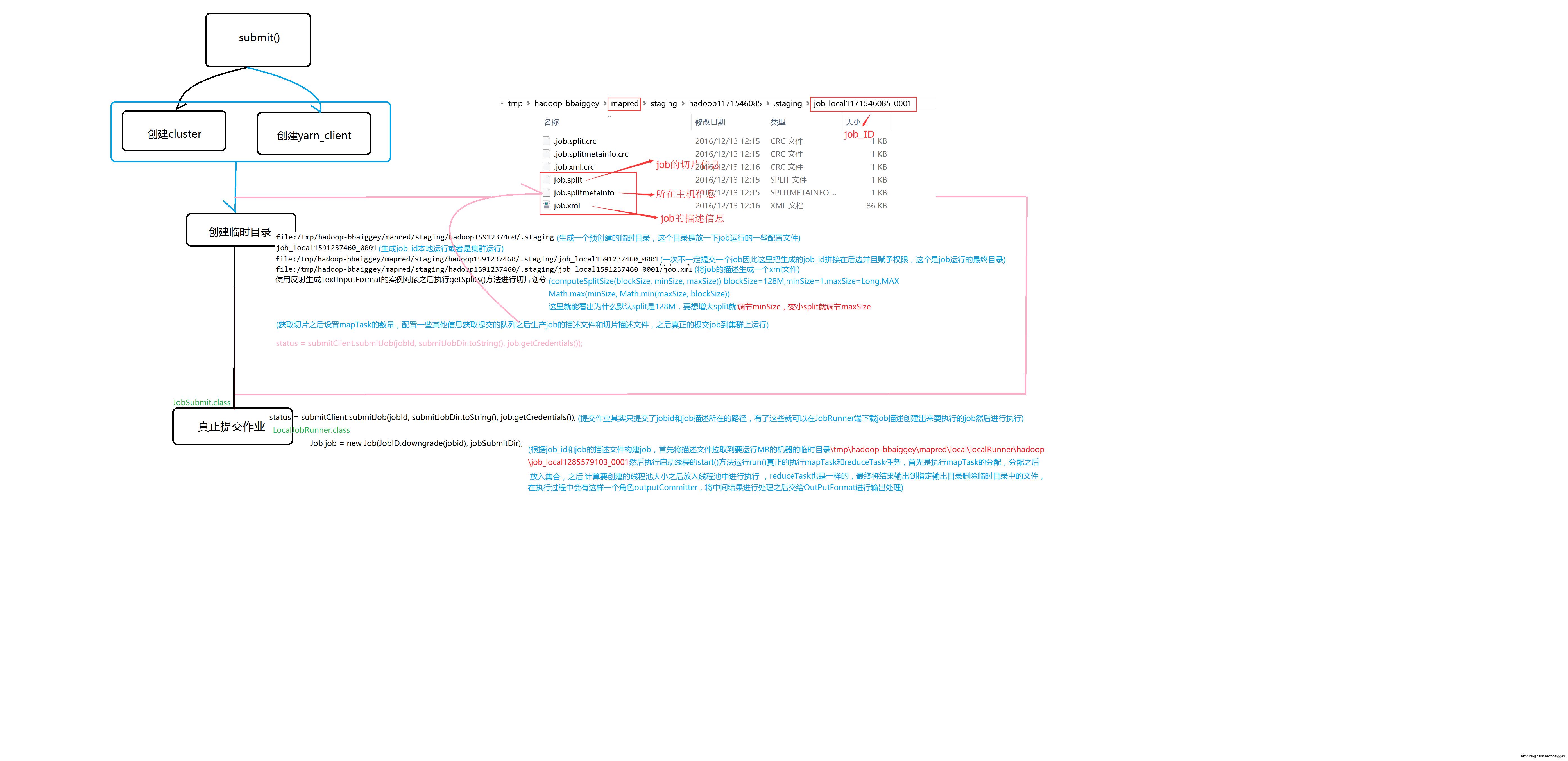
mapreduce.job.queuename
以上是关于hadoop之MapReducer作业的提交执行过程的主要内容,如果未能解决你的问题,请参考以下文章