小度太弱了,干脆自己开发个对话机器人爬虫,数据库,面向对象,人工智能
Posted 程序员笑武
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小度太弱了,干脆自己开发个对话机器人爬虫,数据库,面向对象,人工智能相关的知识,希望对你有一定的参考价值。
背景

当我慢慢的开在高速公路上,宽敞的马路非常的拥挤!这时候我喜欢让百度导航的小度给我讲笑话,但她有点弱,每次只能讲一个。
百度号称要发力人工智能,成为国内人工智能的领军企业。但从小度的智商和理解能力上,我对此非常怀疑。
所以我们干脆用Python来开发一个可以讲笑话的机器人,可以自由定制功能,想讲几个笑话就讲几个笑话。
用到的技术
本文用到以下技术:
- 爬虫 - 抓取笑话
- 数据库 - 用sqlite保存笑话
- 面向对象 - 封装joke对象
- 模块 - 代码分模块放在多个文件中
- 语音识别 - 识别用户输入的语音,把笑话转换成语音
- GUI - 开发简单的用户界面
- 打包 - 把程序打包成可执行文件
主要流程

代码模块
为了代码结构清晰,方便维护,我们把代码放到了多个py文件中,每个文件各司其职。
本程序共包括一下几个代码模块:
- joke.py - 笑话对象,被多个模块共用
- joke_crawler.py - 笑话爬虫
- joke_db.py - 处理数据库相关,保存笑话,查询笑话等
- joke_ui.py - 用户界面模块
- joke_audio.py - 处理和语音相关的任务 和2个非代码结构:
- joke_audio - 存放语音文件的文件夹
- jokeDB.db - sqlite3数据库文件
现在开始写代码,请先创建一个文件夹,建议取名为myjoke。后面所有的代码都在这个文件夹中。
Joke对象
我们使用面向对象的编程思想,创建一个叫做Joke的类,来表示一个笑话。
用了Joke类,代码更清晰,数据传输也更方便。Joke类会被所有其他的模块用到。
创建一个名为joke.py的文件
代码如下:
class Joke:
'''
表示一个笑话。
其中title是笑话标题,detail是笑话内容
url是笑话的采集网址,通过url判定笑话是否重复,防止保存重复笑话
id是数据库生成的唯一标识符,刚刚采集下来的笑话是没有id的,所以id可以为空
'''
def __init__(self, title, detail, url, id=None):
self.title = title
self.detail = detail
self.url = url
self.id = id
def __str__(self):
'''
有了这个方法,print(joke)会把笑话打印成下面格式的字符串,否则只会打印对象的内存地址
'''
return f'id-title\\ndetail\\nurl'
这个类中只有两个魔术方法,一个是构造函数__init__,一个是__str__。
爬虫抓取笑话
分析网页结构
我们要抓取的网址是这个:http://xiaohua.zol.com.cn/detail1/1.html 我们要抓的数据点有三个:

在谷歌浏览器中,右键点击检查,就可以在下面看到网页的代码结构:
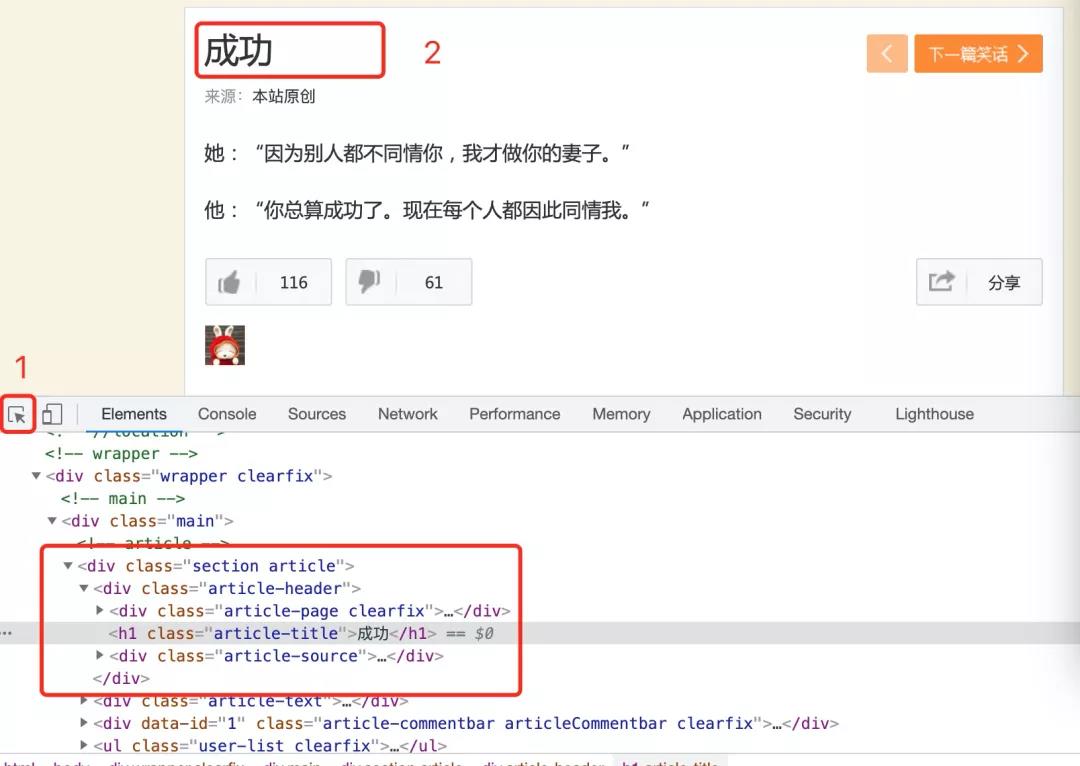
- 1.用鼠标点击1的按钮
- 2.然后把鼠标移到2的地方
- 3.就可以看到成功这两个字在网页中的结构。
通过分析这个结构,我们可以得出:成功这两个字是在一个h1结构内,这个h1的class是article-title,因为可以使用这个特征提取其中的内容(示例代码):
title = html.select_one('h1.article-title').getText()
用同样的方法可以分析出笑话内容和下一页URL的特征。
分析网页结构需要基本的HTML和CSS的知识,如果完全不懂,可以先直接模仿我的代码,然后再慢慢理解相关知识。
代码实现
现在来看完整的代码。
新建一个名为joke_crawler.py的文件。
import requests
import bs4
import time
import random
#先注释掉数据库相关的代码,后面需要反注释回来
#import joke_db
from joke import Joke
#起始URL
url = 'http://xiaohua.zol.com.cn/detail1/1.html'
#网站的域名地址,用来拼接完整地址
host = 'http://xiaohua.zol.com.cn'
def craw_joke(url):
'''
抓取指定的URL,返回一个Joke对象,和下一个要抓取的URL
如果抓取失败,返回None, None
必须设置User-Agent header,否则容易被封
'''
print(f'正在抓取:url')
headers =
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
html = requests.get(url, headers=headers).text
soup = bs4.BeautifulSoup(html, 'lxml')
try:
#分别使用css选择器提取title, detail和next_url
title = soup.select_one('h1.article-title').getText()
detail = soup.select_one('div.article-text').getText().strip()
next_url = soup.select_one('span.next > a')['href']
return Joke(title, detail, url), next_url
except Exception as e:
print('出错了:', e)
print(html)
return None, None
# 抓取笑话,以学习为目的,建议不要抓取太多,本例子只抓取了10个
count = 0
for i in range(0, 10):
joke, next_url = craw_joke(url)
if joke:
#先注释掉数据库相关的代码,后面需要反注释回来
#joke_db.save(joke)
print(joke)
url = host + next_url
print('歇一会儿再抓!')
time.sleep(random.randint(1, 5))
print('抓完收工!')
代码中已经添加了一些注释,有基础的应该可以看懂。
有两个点要注意:
1.在craw_joke函数中,必须添加User-Agent的header,否则会很快被封锁。
2.代码中注释掉了和数据库相关的代码,现在只是把笑话打印出来。写好了数据库模块,要把相关代码反注释回来。
3.抓取的中间有随机1到5秒的停顿,一个防止被封锁,二是出于文明礼貌,不要给服务器带来太大压力。
保存到sqlite数据库
抓来的笑话可以保存到文件中,但是用文件存储不方便检索,也不方便判断笑话是否重复等。
所以更好的方法是把笑话保存到数据库,这里选择sqlite做数据库。原因如下:
1.sqlite是文件数据库,不需要安装额外的数据库服务器
2.python默认支持sqlite数据库,不需要任何额外的安装和配置
但如果你想把世界上所有的笑话都抓下来,数据量很大,那建议使用更正式的数据库,比如mysql.
新建一个名为joke_db.py的文件
代码如下:
import sqlite3
from joke import Joke
def setup():
'''
创建数据库和创建表,如果已经存在了不会重复创建
'''
con = sqlite3.connect('jokeDB.db')
with con:
con.execute('''CREATE TABLE IF NOT EXISTS jokes
(id INTEGER PRIMARY KEY,
title varchar(256) NOT NULL,
detail varchar(1024) NOT NULL,
url varchar(1024) NOT NULL)''')
def save(joke):
'''
把笑话保存到数据库
根据url判断是否已经有这个笑话了,如果有了就不再保存
'''
con = sqlite3.connect('jokeDB.db')
with con:
cur = con.cursor()
cur.execute(
'SELECT * FROM jokes WHERE (url = ?)', [(joke.url)])
has_joke = cur.fetchone()
if has_joke:
print('重复了,不再插入')
else:
con.execute('INSERT INTO jokes(title, detail, url) VALUES (?,?,?)', (joke.title, joke.detail, joke.url))
print('笑话保存成功')
def get_jokes():
'''
返回所有的笑话列表
'''
print('loading jokes...')
con = sqlite3.connect('jokeDB.db')
jokes = []
with con:
for row in con.execute('SELECT * FROM jokes'):
joke = Joke(row[1], row[2], row[3], row[0])
jokes.append(joke)
return jokes
# 调用最上面的代码
setup()
# 测试代码,本模块被别的模块引入的时候,不会执行下面的代码
if __name__ == '__main__':
save(Joke('笑话Test', '笑话内容test', 'https://www.joke.com/1.html'))
save(Joke('笑话Test2', '笑话内容test', 'https://www.joke.com/2.html'))
print('========打印一下所有的笑话======')
for joke in get_jokes():
print(joke)
print()
代码已经添加了比较多的注释,请先看代码。这里额外的补充:
1.要使用sqlite,需要引入sqlite3模块
2.使用sqlite要先用connect()方法获得链接,然后调用execute()方法执行SQL语句。
运行上面的代码,就可以发现文件夹下多了一个名为jokeDB.db的文件,这是程序自动创建的数据库文件,笑话就保存在里面。下面里面只有两个测试的笑话:
> python joke_db.py
笑话保存成功
笑话保存成功
========打印一下所有的笑话======
loading jokes...
1-笑话Test
笑话内容test
https://www.joke.com/1.html
2-笑话Test2
笑话内容test
https://www.joke.com/2.html
这一部分需要一定的数据库知识,不过你也可以比这葫芦画瓢,先把功能做出来,再加强相关知识。
抓取笑话并保存到数据库
现在回到joke_crawler.py中,去掉关于joke_db的注释代码
第1处在文件开头:
#先注释掉数据库相关的代码,后面需要反注释回来
#import joke_db
第2处在文件的最下面:
for i in range(0, 10):
joke, next_url = craw_joke(url)
if joke:
#先注释掉数据库相关的代码,后面需要反注释回来
#joke_db.save(joke)
print(joke)
url = host + next_url
print('歇一会儿再抓!')
time.sleep(random.randint(1, 5))
print('抓完收工!')
去掉注释后,再次运行joke_crawler.py,就会把笑话保存在数据库中。
为了验证是否保存成功了,可以去运行joke_db.py,因为这个文件最后会打印出所有的笑话:
========打印一下所有的笑话======
loading jokes...
1-笑话Test
笑话内容test
https://www.joke.com/1.html
2-笑话Test2
笑话内容test
https://www.joke.com/2.html
3-成功
她:“因为别人都不同情你,我才做你的妻子。”他:“你总算成功了。现在每个人都因此同情我。”
http://xiaohua.zol.com.cn/detail1/1.html
4-结婚以后
女:“为什么从前你对我百依百顺,可结婚才三天,你就跟我吵了两天的架?”男:“因为我的忍耐是有限度的。”
http://xiaohua.zol.com.cn/detail1/2.html
5-我们的
燕尔新婚,新娘对新郎说:“今后咱们不兴说‘我的’了,要说‘我们的’。”新郎去洗澡,良久不出,新娘问:“你在干什么哪?”“亲爱的,我在刮我们的胡子呢。”
http://xiaohua.zol.com.cn/detail1/3.html
6-杞人忧天
妻子患了重病,医生宣告回天乏术。妻子即对丈夫说:“我现在希望你能够发誓。”“发什么誓。”“如果你再婚,不准把我的衣服给你的新妻子穿。”丈夫恍然大悟道:“这个我可以发誓。说实话,你根本不必操心,因为我再也不想找像你这样胖的太太了。”
http://xiaohua.zol.com.cn/detail1/5.html
7-理由充分
法官:“离婚理由是什么?”新娘:“他打呼噜。”法官:“结婚多长时间了?”新娘:“三天。”法官:“离婚理由充分,结婚三天还不是打呼噜的时候。”
http://xiaohua.zol.com.cn/detail1/6.html
8-聪明丈夫
某夫妇当街而过,一只鸽子飞过天空,一泡鸽粪不偏不倚正巧落在太太肩上,太太急了,忙叫丈夫拿纸。丈夫抬头,见鸽子不讲卫生,到处拉屎,却不知妻子叫他拿纸干嘛,说:“叫我有啥办法,追上前去给它擦屁股呀! ”
http://xiaohua.zol.com.cn/detail1/8.html
9-事故与灾难
一位夫人问她的丈夫:“亲爱的,你能告诉我‘事故’与‘灾难’这两个词之间有什么区别吗?”“这很简单。”丈夫认真地回答说,“譬如你失足落水,这就叫‘事故’;如果人家又把你当鱼钓上来,这就是‘灾难’了。”
http://xiaohua.zol.com.cn/detail1/13.html
10-吵架的结果
夫妻吵架了。当丈夫下班回到家里,他发现妻子不在家。只在桌上留了一个条子,上面写道:“午饭在《烹调大全》第215页;晚饭在317页。”
http://xiaohua.zol.com.cn/detail1/14.html
11-保险之险
太太不懂保险的道理,认为缴保险费是浪费,先生连忙解释说:“保险是为了你和孩子,万一我死了;你们也有个保障呀! ”太太反驳说:“要是你不死呢?”
http://xiaohua.zol.com.cn/detail1/16.html
12-补不足
妻:“我晓得,你与我结婚,是因为我有钱。”夫:“不是,是因为我没有钱。”
http://xiaohua.zol.com.cn/detail1/17.html
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

以上是关于小度太弱了,干脆自己开发个对话机器人爬虫,数据库,面向对象,人工智能的主要内容,如果未能解决你的问题,请参考以下文章
工作10年了,却被实习生代替,是实习生太牛了,还是我们太弱了?
测试工作8年了,却被应届生踩在头上,是应届生太牛了,还是我们太弱了?