遗传算法中种群规模和个体个数的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了遗传算法中种群规模和个体个数的区别相关的知识,希望对你有一定的参考价值。
参考技术A 种群规模就是个体总数,没有区别。遗传算法求解TSP问题
遗传算法是一种启发式搜索,属于进化算法的一种。它最初是人们根据自然界对物种的自然选择和遗传规律而设计的。它模拟自然界物种的自然选择、遗传和变异等,对一个种群的基因进行改良。
遗传算法需要设置交叉概率、变异概率和迭代次数等参数,且算法的收敛性受其参数设置影响较大。
遗传算法中把每一个候选解看做是一个个体,个体组成的集合看作是一个种群。遗传算法通过对每个解进行二进制编码把每个解转化为0-1字符串,其中每一个位叫做一个基因。不同基因的组合构成的个体的表现型也不同。它从一个初始种群开始,经过N次迭代最终求得近似最优解。在每次迭代的过程中,他首先计算初始种群内的每个个体的适应度,然后对初始种群使用选择算子,遗传算子,变异算子进行操作。每一个算子操作的过程都不是固定的,而是以一定的概率操作。这样确保了算法的搜索空间可以覆盖整个解空间,同时也能条出局部最优解。
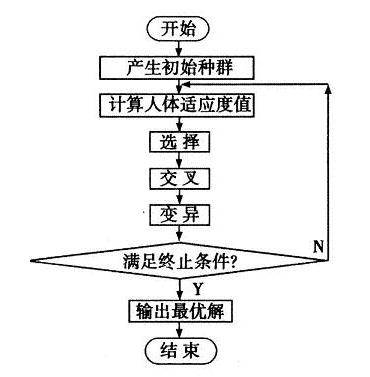
算法终止条件有两种,一种是在连续w次迭代之后当前最优解未发生变化就终止,其中w为根据经验设置的阈值,通常与问题规模有关;另一种是当算法迭代到一定的次数后终止。
TSP问题解的编码
编码是应用遗传算法时要解决的首要问题,也是设计遗传算法的一个关键步骤。编码方法除了决定个体的染色体排列形式之外,它还决定了个体从搜索空间的基因型变换到解空间的表现型时的解码方法。编码方法也影响到交叉算子、变异算子等遗传算子的运算方法。由此可见,编码方法在很大程度上决定了如何进行群体的遗传进化运算以及遗传进化运算的效率。
遗传算法编码的方式有多种,比如:二进制编码、浮点数编码和符号编码。针对不同的问题选择合适的编码方法有助于问题的求解。基于二进制的编码对TSP问题来说,我们无法保证执行完交叉变异变换后的解满足题意,故舍弃此方法。基于浮点数的编码方法通常用于求解连续函数的近似最优函数值,对于离散的TSP问题并不适合。在TSP问题中每一个解就是一个由城市序号组成的路径序列,在算法中也叫作种群中的个体。根据TSP问题的情况,我们选择符号编码的方法。举个例子:有4个城市,城市序号为:0,1,2,3。假设从0出发依次经过城市1,2,3最后回到城市0的路径最短。那么0-1-2-3-0就是这4个城市TSP问题的一个最优解,也叫作一个个体。路径序列中的单个城市序号,比如2,叫做个体的一个基因。通常最优解路径只有一条,但是路径序列不止一个,比如1-2-3-0-1,他们仅仅是起点不同。适应度计算
在自然界中,根据遗传学的观点,适应度越高的个体越有机会被选择,进而保留其基因。因此在遗传算法的设计过程必须对适应度具有正反馈的选择策略。在选择策略制定之前需要考虑衡量每个个体适应度的方法。根据TSP问题的目标,不难得出路径代价越小其适应度越高,同时适应度值必须为正值。因此取适应度为路径代价的倒数。
选择操作:轮盘赌+精英选择
INPUT:初始种群Popu[M]
OUTPUT:选择出种群NewPopu[M]
Begin
Sumfit=0.0;
For(k=0;k<Popu.Size();k++)
Sumfit+=Popu[k].fit;
End For
For(i=0,k=0;i<M-1;i++)
P=Random()%1000/1000.0;//随机产生一个概率
SumP=0;
For(j=0;j<Popu.Size();j++)
SumP=SumP+(Popu[j].fit)/Sumfit;
If(SumP>P)
Break;
End If
End For
NewPopu[k++]=Popu[j];
End For
Sort(Popu)//按适应度从大到小排序
NewPopu[k]=Popu[0];//精英放在最后
End
交叉策略
在生物的自然进化过程中,两个同源染色体通过交配而重组,形成新的染色体, 从而产生出新的个体或物种。交配重组是生物遗传和进化过程中的一个主要环节。模仿这个环节,在遗传算法中也使用交叉算子来产生新的个体。遗传算法中的所谓交叉运算,是指对两个相互配对的染色体按某种方式相互交换其部分基因,从而形成两个新的个体。对TSP问题来说,交叉运算不仅仅是互换两个个体的部分基因,同时还必须确保在互换基因后产生的新个体必须无重复的包含所有的城市。这是TSP交叉运算设计的一个难点和重点,同时并不是对每个个体都执行交叉操作,而是按照一定的交叉概率PC进行。
遗传算法中通常的交叉算法有单点交叉、多点交叉、均匀交叉和算术交叉。单点交叉又称为简单交叉,它是指在个体编码串中只随机设置一个交叉点,然后在该点相互交换两个配对个体的部分染色体。多点交叉指在个体编码串中随机设置多个交叉点,然后进行基因交换。多点交叉又称为广义交叉。常见的是双点交叉。指两个配对个体的每一个基因座上的基因都以相同的交叉概率进行交换,从而形成两个新的个体。均匀交叉实际上可归属于多点交叉的范围。由两个个体的线性组合而产生出两个新的个体,常用于求函数值的遗传算法中。
Cross (Popu[M])//交叉策略
INPUT:选择后的种群Popu[M]
OUTPUT:交叉后的种群NewPopu[M]
Begin
For(i=0;i<Popu.Size()-1;i++)//最后一个个体为种群内最优个体无条件保留
P=Random()%1000/1000.0;//随机产生一个概率
If(P<PC)//以概率PC交叉
j=Random()%(Popu.Size()-1)
Xcross(Popu[i],Popu[j])
Fit(Popu[i]);
Fit(Popu[j]);
If(Popu[i].fit>Popu[M-1].fit)Swap(Popu[i],Popu[M-1]);
If(Popu[j].fit>Popu[M-1].fit)Swap(Popu[j],Popu[M-1]);
EndIf
End For
End
整体来看,算法P的概率对前M-1个元素进行配对交叉。如果交叉后比当前最优值Popu[M-1]适应度高,则与当前最优进行交换。这样保证了种群内的最优个体(最后一个)总是能100%遗传给下一代。交叉过后重新计算其适应度,为变异操作做准备。其中Xcross()函数是随机生成两个交叉点,然后交换交叉点内部的元素。其他元素按照填充法,从第二个交叉点循环将剩余的元素添加到个体。变异后个体如果比当前最优值适应度高,则将当前最优与变异后个体交换。
以两个父代个体为例:(1 2 3 4 5 6 7 8)和(2 4 6 8 7 5 3 1),随机选择两个交叉的点,假如第一个点为位置3,第二个交叉点为位置5,那么在两个点之间的位置将进行交叉。在此实例中,第一个父代个体中3 4 5被选中,第二个父代个体中,6 8 7被选中。交换交叉区间内元素变为(1 2 6 8 7 6 7 8)和(2 4 3 4 5 5 3 1),然后从第二个交叉点开始,将原来相应的父代按照顺序进行填充子代1从第6个元素开始,如果选择的元素已经存在在该子代中,跳过该元素(6 7 8 跳过),选择下一个元素,这种过程反复进行,直到所有的城市都被选择一次。最终变换后的子代为(4 5 6 8 7 1 2 3)和(8 7 3 4 5 1 2 6)。
变异策略
交叉运算是产生新个体的主要方法,它决定了遗传算法的全局搜索能力;而变异运算只是产生新个体的辅助方法,但它也是必不可少的一个运算步骤,因为它决定了遗传算法的局部搜索能力。交叉算子与变异算子的相互配合,共同完成对搜索空间的全局搜索和局部搜索,从而使得遗传算法能够以良好的搜索性能完成最优化问题的寻优过程。
常见的变异操作主要有替换变异、交换变异、插入变异和简单倒位变异等。替换变异就是先从父代个体中选择一段基因,然后再随机在剩下的基因中随机选择一个位置,并插入选中的基因段。交换变异就是所及选择两个基因,然后交换两个基因的位置。插入变异属于替换变异的特殊情况,只选择一个基因插入而不是基因段。简单倒位变异是随机选择一段基因然后将其逆序。本文选择的是交换变异。对每个基因按照一定的概率进行变异选择,若选中,则随机从剩下的基因中选一个与其交换。
以上是关于遗传算法中种群规模和个体个数的区别的主要内容,如果未能解决你的问题,请参考以下文章