word2vec负采样中softmax的应用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了word2vec负采样中softmax的应用相关的知识,希望对你有一定的参考价值。
参考技术A word2vec可以说是整个embedding理论的基础,几乎所有的embedding方法,最终都会把序列用skip-gram或者是CBOW训练一把得到embedding。word2vec的原理并不复杂,精妙的思想在于如何减少输出层softmax的计算量,相关的基础文章王喆大神都列出来了,最近在阅读,经常会有一些让人眼前一亮的点,做一个简单的记录。
word2vec理论提出的文章中,Mikolov et al,写得并不是很好懂,好在有几篇explained,比如这篇: word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method ,另外一篇更详细一些,JinRong教授写的。
在计算输出矩阵时,激活函数是这样的:
(1)
进一步可以写成对数形式:
(2)
这里就有一个很尴尬的问题,当 ,也就是我们的字典(vocabulary)的size很大的时候,这个softmax算的就会非常慢。
解决这个问题官方是有两种方案,1)层次softmax;2)负采样。
关于这两种方法刘建平大神以及其他各种ml博主都有写,我也写不了他们那么好,就不用多说了。但是为了说下面的东西,简单说一说负采样。
其实负采样一言以蔽之,就是把公式(1)中分母的 干掉。引入了这样的思想:只考察两个词 和 ,怎么能描述他们的关系呢?还是用上面的余弦距离。当我们认为 的embedding,也就是 是直接从输入矩阵中拿到的,这时候要学习的就是 的表示 ,这时候论文中直接给出了一个softmax的表达:
(3)
光从这个公式上理解,还是可以接受的,当两个embedding接近的时候,余弦距离大, ,反之
这里就有两个问题,感觉如果搞清楚这两点,负采样基本上就捋顺了:
回答了这两个问题,其实接下去的事情就比较简单,或者说通畅。我们直接把公式(3)的softmax激活写成一个通用的激活形式 ,最后的损失函数就可以写成:
题外话可以说说softmax和lr的关系,设想这样的一个简单的逻辑回归问题,用线性函数拟合对数几率的废话不多说,公式如下:
(4)
但是当我们把它当成是一个多分类问题的时候,写成softmax的样子,可以有:
把下面的公式稍微变化一下就写成:
也就是说,当softmax是一个二分类问题的时候,其实没有必要训练两组参数,本质上就是一个逻辑回归问题,优化过程中,我们只关注 而不是这两组参数分别是多少。事实上,我们确实也无法求出他们准确的值来,或者说他们可以任意的数,因为在求偏导的时候 恒成立,迭代中只会优化它俩的差值。
word2vec (CBOW分层softmax负采样)
本文介绍
- wordvec的概念
- 语言模型训练的两种模型CBOW+skip gram
- word2vec 优化的两种方法:层次softmax+负采样
- gensim word2vec默认用的模型和方法
未经许可,不要转载。
机器学习的输入都是数字,而NLP都是文字; 为了让机器学习应用在NLP上,需要把文字转换为数字,把文字嵌入到数学空间。
1. 词表示:
- 词的独热表示:onehot (词之间是孤立的)
- onehot:
- 思想:假设词表大小为N, 则每个单字表示为N维向量; 每个单字只有1位为1,其他为0;茫茫0海中一个1
- 缺点:词之间是孤立的;维度太大
- onehot:
- 词的分布式表示:(能描述词之间的语义关系)
- 基于矩阵的分布式表示
- 基于聚类的分布式表示
- 基于神经网络的分布表示,词嵌入 word embedding
- 将01表示改为浮点数表述;降维
- word2vec是用神经网络训练语言模型(NNLM)过程中得到的参数.
- 其他概念
- 语言模型: 就是一段文字成为句子的概率; 经常用的ngram, n=2或3
2. NNLM 神经网络语言模型
用神经网络训练语言模型,常见有两种; 用上下文预测term(CBOW), 用term预测上下文(skip-gram),结构一般是简单三层网络,一个输入层、一个隐含层、一个输出层。
2.1 CBOW 连续词袋模型
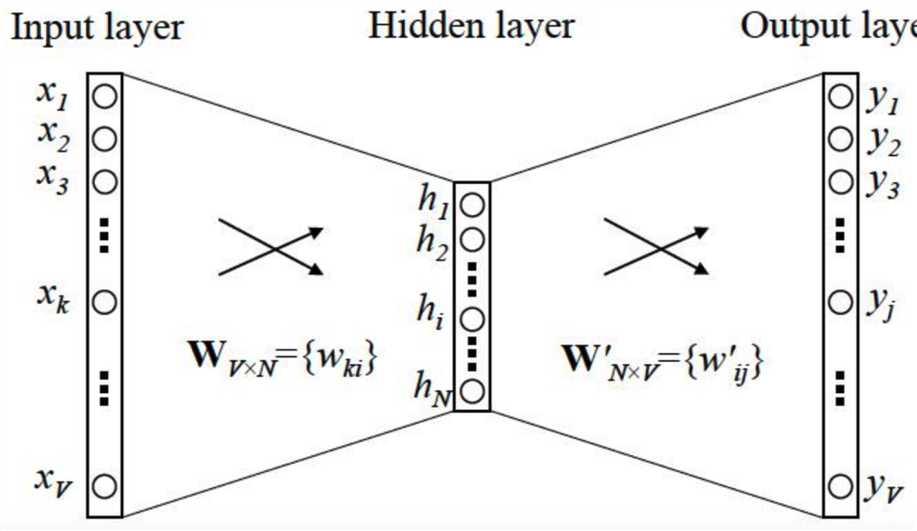
- 变量:词表大小V, 要嵌入到N维空间中,C/2是窗口大小,即上下文取几个term(不算当前term);- N一般取50~300
- 步骤:参考自 https://www.zhihu.com/question/44832436
- input layer:窗口内的C个词的onehot表示
- input layer -> hidden layer:(V维表示降到N维表示)
- 通过权重矩阵\\(W_V\\times N\\) ,将 \\(V \\times C\\)映射为 $N \\times C $
- hidden layer + 激活函数:C个词表示为1个词
- word2vec中激活函数,用了简单取平均;
- hidden layer -> output layer:1个N维词还原到高维V维中;
- 通过权重矩阵\\(W_N\\times V^'\\) ,将 \\(N \\times 1\\)映射为 \\(V\\times 1\\)
- output layer + softmax 激活函数,将值归一化到0~1之间 y
- 用BP+梯度下降优化cost function y和真实y之间的距离,迭代优化参数 \\(W、W^'\\)
- 收敛result:y是V维向量,每个元素取值0~1, 将最大元素值,还原为onehot编码,就是最终结果了。
2.2 skip-gram 语言模型
思路同CBOW, 只是输入是1个词,输出是C个词;
一般用BP训练得到参数,预测用一次前向传播;
3. word2vec用的优化方法
word2vec结合了CBOW, skip-gram的方法 训练得到参数\\(W\\), 但在计算中做了很多优化;
可以看到,NNLM计算中,两个问题导致计算量大;
- 词表维度大;
- softmax计算量大;
下面介绍两种优化方法;
3.1 hierarchical softmax 层次softmax
/?hī(?)?r?rkik?l/
huffman: 带权路径长度最短为目标,可以用log(V)长度的编码表示
带权路径长度WPL:
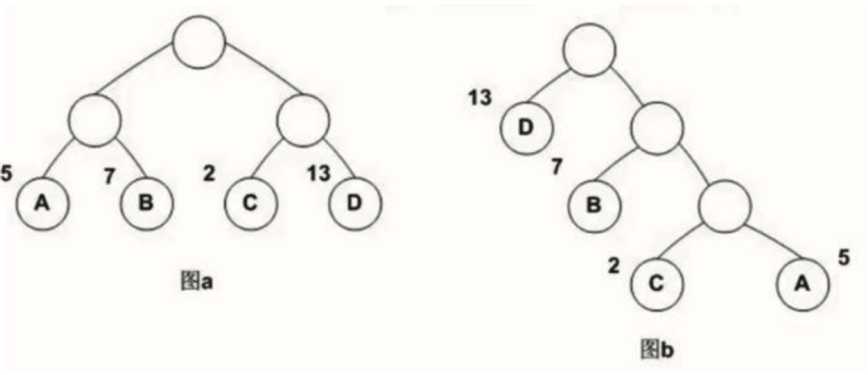
- 图a: 5 * 2 + 7 * 2 + 2 * 2 +13 * 2 = 54
- 图b:5 * 3 + 2 * 3 + 7 * 2 + 13 * 1 = 48 (huffman, 带权路径长度较小)
- 参考自: https://zhuanlan.zhihu.com/p/56139075
层次softmax
softmax需要对每个词语都计算输出概率,并进行归一化,计算量很大;
进行softmax的目的是多分类,那么是否可以转成多个二分类问题呢, 如SVM思想? 从而引入了层次softmax示意图
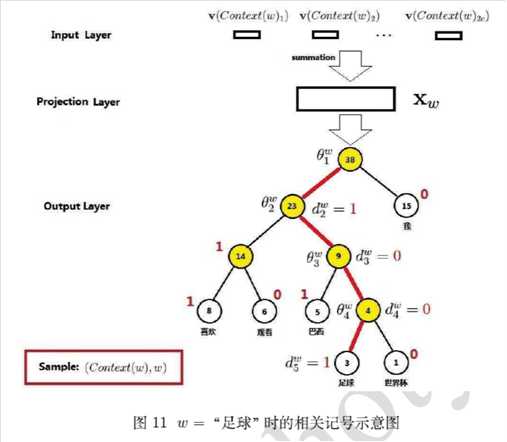
- 为什么有效?
- 1)用huffman编码做词表示
- 2)把N分类变成了log(N)个2分类。 如要预测的term(足球)的编码长度为4,则可以把预测为‘足球‘,转换为4次二分类问题,在每个二分类上用二元逻辑回归的方法(sigmoid);
- 3)逻辑回归的二分类中,sigmoid函数导数有很好的性质,\\(\\sigma^'(x) = \\sigma(x)(1-\\sigma(x))\\)
- 4)采用随机梯度上升求解二分类,每计算一个样本更新一次误差函数
- 参考自:http://flyrie.top/2018/10/31/Word2vec_Hierarchical_Softmax/
gensim的word2vec 默认已经不采用分层softmax了, 因为$log_2 1000=10 $也挺大的;如果huffman的根是生僻字,则分类次数更多;
3.2 高频词抽样+负采样
为了解决NNLM中softmax过程的计算性能问题,通常有几种优化技巧:
- 将常见的单词组合(word pairs)或者词组作为单个“words”来处理
- 对高频次单词进行抽样来减少训练样本的个数
- 对优化目标采用“negative sampling”方法,这样每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担
参考自:https://www.jianshu.com/p/56554a63410f
3.2.1 对高频词抽样
主要思想是少训练没有区分度的高频term;
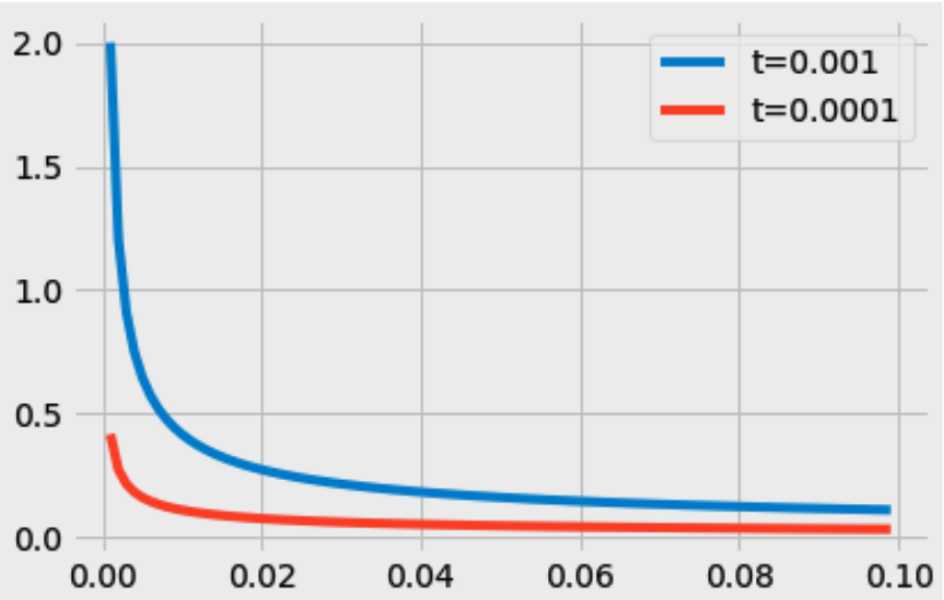
对于我们在训练原始文本中遇到的每一个单词,它们都有一定概率被我们从文本中删掉,而这个被删除的概率与单词的频率有关。词频越高(stopword),抽样越少;
- 抽样率 \\(P(w_i) = (\\sqrt\\fracZ(w_i)t+1)\\times \\fractZ(w_i) = \\sqrt\\fractZ(w_i) + \\fractZ(w_i)\\) ,其中
- \\(Z(w_i)\\)是词在语料中的出现概率,反比关系,越高频词抽的越少;
- \\(t\\)是设定的阈值,正比关系,\\(t\\)越大,不同频率单词的采样概率差异越大; gensim word2vec中默认值是0.001
- 抽样率直观理解
import numpy as np import matplotlib.pyplot as plt x = np.array(range(1, 100)) / 1000.0 t1 = 0.001 t2 = 0.0001 y1 = np.power(t1/x, 0.5) + t1/x y2 = np.power(t2/x, 0.5) + t2/x plt.plot(x, y1, '-', label='t=0.001') plt.plot(x, y2, '-', label='t=0.0001') plt.legend()3.2.2 负采样 Negative sampling
- 问题:在NNLM中对于每个样本w, 都要更新一次hidden->output的参数阵\\(W^'_N\\times V\\),计算量很大;比如词表大小V=10000, N=300, 那么权重矩阵有300万个参数;
- 思想:如果每次只更新目标词(正例 positive word)和少数几个负例(negative words), 那么计算量会显著减少; 比如如果我们每次只更新M=1+5个,则更新了6*300=1800, 1800/300万=0.06%; 计算量减少了3个数量级。
- negative words如何选择:根据词表中出现的概率,出现概率越高,被选作负样本的概率越高;
- \\(P(w_i) = \\fracf(w_i)^3/4\\sum_j=0^vf(w_j)^3/4\\), 其中\\(f(w_j)\\)是出现的概率,3/4是经验值,比线性关系更弱化了些;
4. gensim word2vec默认参数(CBOW+负采样)
默认用了CBOW模型,采用高频词抽样+负采样进行优化;
from gensim.models import Word2Vec
word2vec.Word2Vec(sentences=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, iter=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000, compute_loss=False, callbacks=(), max_final_vocab=None)- 上下文窗口大小:window=5
- 忽略低频次term:min_count=5
- 语言模型是用CBOW还是skip-gram?sg=0 是CBOW
- 优化方法是用层次softmax还是负采样:hs=0 是负采样
- 负采样样本数: negative=5 (一般设为5-20)
- 负采样采样概率的平滑指数:ns_exponent=0.75
- 高频词抽样的阈值 sample=0.001
以上是关于word2vec负采样中softmax的应用的主要内容,如果未能解决你的问题,请参考以下文章