自然语言处理(NLP)之近似训练法:负采样与层序Softmax
Posted 寅恪光潜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理(NLP)之近似训练法:负采样与层序Softmax相关的知识,希望对你有一定的参考价值。
我们在前面介绍的跳字模型与连续词袋模型有个缺陷就是在计算梯度时的开销随着词典增大会变得很大,因为每一步的梯度计算都包含词典大小数目的项的累加。
为了降低这种带来的高计算复杂度,介绍两种近似的处理方案:负采样和层序softmax
负采样(Negative Sampling)
我们回顾下跳字模型给定中心词 生成背景词
生成背景词 的条件概率:
的条件概率:

该条件概率相应的对数损失如下表示:

可以看到softmax运算考虑了背景词可能是词典V中的任一词,以上损失包含了词典大小数目的项的累加,复杂度大,于是出现新的方法来降低复杂度。
负采样修改了原来的目标函数,给定中心词的一个背景窗口,我们把背景词出现在该窗口当作一个事件,该事件的概率计算为:

其中的σ是sigmoid激活函数:
我们先考虑最大化文本序列中所有该事件的联合概率来训练词向量。具体来说,给定一个长度为T的文本序列,时间步t的词为 且背景窗口大小为m,最大化联合概率:
且背景窗口大小为m,最大化联合概率:

然后,这里的模型中包含的事件仅考虑了正样本,这导致当所有词向量相等且值为无穷大时,上述联合概率才被最大化为1,很明显,这样的词向量毫无意义。负采样通过采样并添加负类样本使目标函数更有意义。
设背景词出现在中心词的一个背景窗口为事件P,我们根据分布P(w)采样K个未出现在该背景窗口的词,即噪声词。设噪声词 (k=1,...,K)不出现在中心词的该背景窗口为事件
(k=1,...,K)不出现在中心词的该背景窗口为事件 。假设同时含有正类样本和负类样本的事件P,
。假设同时含有正类样本和负类样本的事件P, ,...,相互独立,负采样将以上需要最大化的仅考虑正类样本的联合概率改写为:
,...,相互独立,负采样将以上需要最大化的仅考虑正类样本的联合概率改写为:

其中条件概率被近似表示为:

设文本序列中时间步t的词在词典中的索引为 ,噪声词在词典中的索引为
,噪声词在词典中的索引为 ,有关以上条件概率的对数损失为:
,有关以上条件概率的对数损失为:



现在的训练中每步的梯度计算开销就不再跟词典大小有关,而跟K线性相关。所以当K较小时,负采样每步的梯度计算开销较小。
最后两步的推导,使用sigmoid激活函数验证下,是等价的
import numpy as np
np.log(sigmoid(-np.array([0.2,0.4,-0.8])))
np.log(1-sigmoid(np.array([0.2,0.4,-0.8])))
#array([-0.79813887, -0.91301525, -0.37110067])层序softmax
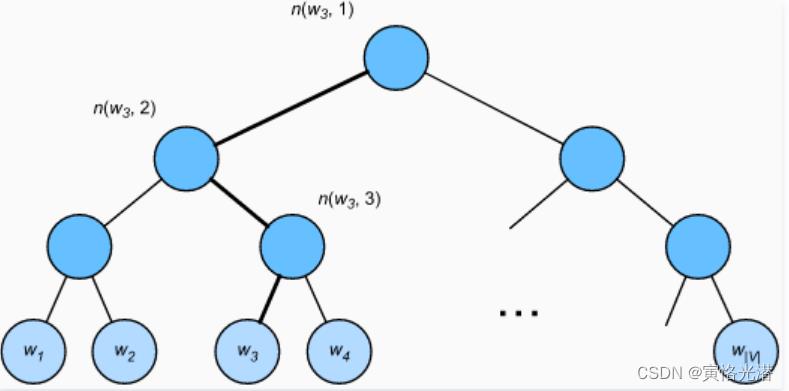
另一种近似训练法,就是层序softmax,使用的是二叉树这样的数据结构,树的每个叶节点代表词典V中的每个词
假设L(w)为从二叉树的根节点到词w的叶节点的路径(包括根节点和叶节点)上的结点数。设n(w,j)为该路径上第j个结点,并设该节点的背景词向量为 ,画图来看下:
,画图来看下:
层序softmax将跳字模型中的条件概率近似表示为:

其中leftChild(n)表示结点n是否是左子节点,如果是的话就是1,反之为-1
这里我们来计算下从给定词生成词 的条件概率(方向经过左->右->左),我们需要将的词向量
的条件概率(方向经过左->右->左),我们需要将的词向量 和根节点到路径上的非叶节点向量一一求内积。
和根节点到路径上的非叶节点向量一一求内积。
可以得到如下公式,注意方向就是正负的区别:

由于 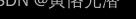 ,给定中心词生成词典V中任一词的条件概率之和为1这一条件也满足
,给定中心词生成词典V中任一词的条件概率之和为1这一条件也满足

此外,由于L()-1的数量级为O( ),当词典V很大时,层序softmax训练中每一步的梯度计算开销相较未使用近似训练时大幅降低。
),当词典V很大时,层序softmax训练中每一步的梯度计算开销相较未使用近似训练时大幅降低。
这两节主要就是公式的熟悉和推导,接下来就是实战了,感觉这个新的编辑器很好用,流畅和直观,赞一个
以上是关于自然语言处理(NLP)之近似训练法:负采样与层序Softmax的主要内容,如果未能解决你的问题,请参考以下文章
NLP⚠️学不会打我! 半小时学会基本操作 4⚠️词向量模型
NLP:自然语言处理技术领域的代表性算法概述(技术迭代路线图/发展时间路线)四大技术范式变迁概述(统计时代→大模型时代)四个时代的技术方法论探究(少数公司可承担的训练成本原因)之详细攻略