JavaScript浅析javaScript和HTML与unicode字符集的关系
Posted David Wu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaScript浅析javaScript和HTML与unicode字符集的关系相关的知识,希望对你有一定的参考价值。
目录结构:
javascript和html支持的字符集
JavaScript是支持unicode的。
现代的浏览器在网页中都支持ASCII字符集、ISO字符集、数学符号、希腊字母、其他符号。HTML5默认使用UTF-8。读者可以点击这儿查看ASCII、unicode和utf-8的关系。
javaScript和HTML如何表现unicode字符集
HTML页面使用的是网页文档对象,它是通过转义字符串来表现unicode字符集,语法规则为:“第一部分是一个&符号,英文叫ampersand;第二部分是实体(Entity)名字或者是#加上实体(Entity)编号;第三部分是一个分号。”比如:字符“&”可以在HTML中表示为"&"、" &"或是"&"点击这儿查看详情。
javaScript使用的是浏览器系统对象,是十六进制的。它同HTML表现unicode字符集不一样,他有自己的转义字符,javaScript的转义字符表:
| Unicode 字符值 | 转义序列 | 含义 | 类别 |
|---|---|---|---|
| \\u0008 | \\b | Backspace | |
| \\u0009 | \\t | Tab | 空白 |
| \\u000A | \\n | 换行符(换行) | 行结束符 |
| \\u000B | \\v | 垂直制表符 | 空白 |
| \\u000C | \\f | 换页 | 空白 |
| \\u000D | \\r | 回车 | 行结束符 |
| \\u0020 | 空格 | 空白 | |
| \\u0022 | \\" | 双引号 (") | |
| \\u0027 | \\\' | 单引号 (\') | |
| \\u005C | \\\\ | 反斜杠 (\\) | |
| \\u00A0 | 不间断空格 | 空白 | |
| \\u2028 | 行分隔符 | 行结束符 | |
| \\u2029 | 段落分隔符 | 行结束符 | |
| \\uFEFF | 字节顺序标记 | 空白 |
读者可以打开电脑自带的字符映射表,在里面可以找到unicode代码,比如:
在宋体栏目一行中的unicode转到中输入字符串“FE6A”,就会自动跳到百分号,并且在最下面显示“U+FE6A”。
读者可以在html中写出如下测试代码:
<!DOCTYPE html>
<html>
<head>
<title>test.html</title>
<meta name="content-type" content="text/html; charset=UTF-8">
</head>
<body>
<script>
document.write("\\ufe6a﹪");
alert("\\ufe6a");
</script>
<p>\\ufe6a
<p>﹪
</body>
</html>
读者可在浏览器上看到如下效果:

在document文档中的“\\ufe6a"和“﹪”都正常显示出来了,这里读者需要注意,前者是javaScript认得到的,所以会被javaScript转化,后者是HTML中的转义字符,因此会原封不动的发给HTML文档,由HTML来转换。上面的代码中有一个alert警告框,它都是支持unicode字符集的,如果在里面写上HTML的转义字符串的话,由于alert的内容不是发送到HTML文档对象中,因此转义字符串将不会被转化。
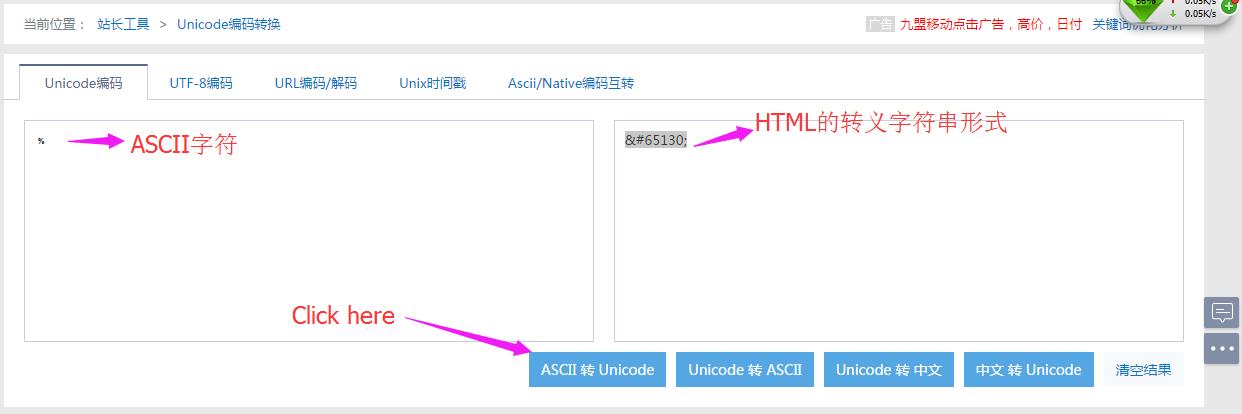
介绍了javaScript和html表现unicode的差别,如果需要某个符号的unicode代码或是html的转义字符串代码挨着挨着在字符映射表中或是字符集中查找太麻烦了,这时候可以使用在线Unicode编码转换。在使用在线Unicode编码转换的时候,ASCII字符转Unicode字符默认是HTML的转义字符串形式,这也说明HTML的转义字符串也是Unicode编码的一部分,这时候读者可以通过“中文转Unicode”来实现十六进制。
参考文章
http://www.runoob.com/charsets/ref-html-utf8.html
本文为博主原创作品,如需转载请注明出处
以上是关于JavaScript浅析javaScript和HTML与unicode字符集的关系的主要内容,如果未能解决你的问题,请参考以下文章