基础网络爬虫(Web crawler)相关技术浅析
Posted Starzkg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基础网络爬虫(Web crawler)相关技术浅析相关的知识,希望对你有一定的参考价值。
文章目录
前言
万维网上有着无数的网页,包含着海量的信息,无孔不入、森罗万象。但很多时候,无论出于数据分析或产品需求,我们需要从某些网站,提取出我们感兴趣、有价值的内容,但是纵然是进化到21世纪的人类,依然只有两只手,一双眼,不可能去每一个网页去点去看,然后再复制粘贴。所以我们需要一种能自动获取网页内容并可以按照指定规则提取相应内容的程序,这就是爬虫。
基本概念
网络爬虫(Web crawler),是一种“自动化浏览网络”的程序,或者说是一种网络机器人。它们被广泛用于互联网搜索引擎或其他类似网站,
以获取或更新这些网站的内容和检索方式。
目前,网络上已经有很多开源的爬虫软件,像Larbin(c++语言实现,只负责网页抓取,不负责解析和存储),Nutch(开源Java 实现的搜索引擎),Heritrix(java开发的单实例的爬虫)。
按照系统结构和实现技术,爬虫可以分为通用网络爬虫,聚焦网络爬虫,增量式网络爬虫和深层网络爬虫。像百度,谷歌就是一种大型复杂的网络通用网络爬虫,通用网络爬虫大多提供基于关键字的收索,难以支持根据语义信息提出的查询,因此,聚焦网络爬虫应运而生。聚焦爬虫将目标定位为抓取某特定主题内容,为面向主题的用户查询准备数据资源。相比之下,增量网络爬虫难度更大,它需要进一步爬取更新的新产生的网页数据,而不重新下载未发生变化的网页。web页面可以分为表层网页和深层网页,通用网络爬虫通常是爬取表层网页,而需要登录或注册的网页就需要深层网络爬虫。常常,爬虫技术是多种技术的交替使用。
Robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots ExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取.
根据协议,网站管理员可以在网站域名的根目录下放一个robots.txt 文本文件,里面可以指定不同的网络爬虫能访问的页面和禁止访问的页面,指定的页面由正则表达式表示。网络爬虫在采集这个网站之前,首先获取到这个文件,然后解析到其中的规则,然后根据规则来采集网站的数据。
基本原理
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
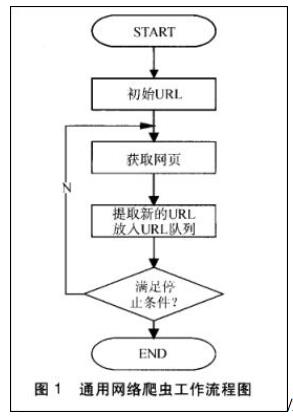
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;所以一个完整的爬虫一般会包含如下四个模块:
- 网络请求模块
- 流程控制模块
- 内容提取模块
- 数据存储模块
现状概况
爬虫软件
八爪鱼:https://www.bazhuayu.com/
跨语言
Selenium
官网:https://www.selenium.dev/
Selenium是一个自动化测试工具,对各种浏览器都能很好地支持,包括Chrome、Firefox这些主流浏览器。使用它就可以模拟浏览器进行各种各样的操作,包括爬取一些网页内容。
Python
Python是编写爬虫程序的常用工具。Python中有多个模块使得爬虫编写非常简单,常用的模块有:urllib、requests、re、bs4、Scrapy、Selenium等。
urllib
urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求。其常被用到的子模块在Python3中的为urllib.request和urllib.parse,在Python2中是urllib和urllib2。
requests
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更简洁方便。
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用:)
Requests 继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。
requests 的底层实现其实就是 urllib3
Requests的文档非常完备,中文文档也相当不错。Requests能完全满足当前网络的需求,支持Python 2.6—3.5,而且能在PyPy下完美运行。
开源地址:https://github.com/kennethreitz/requests
中文文档 API: http://docs.python-requests.org/zh_CN/latest/index.html
Scrapy
Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。
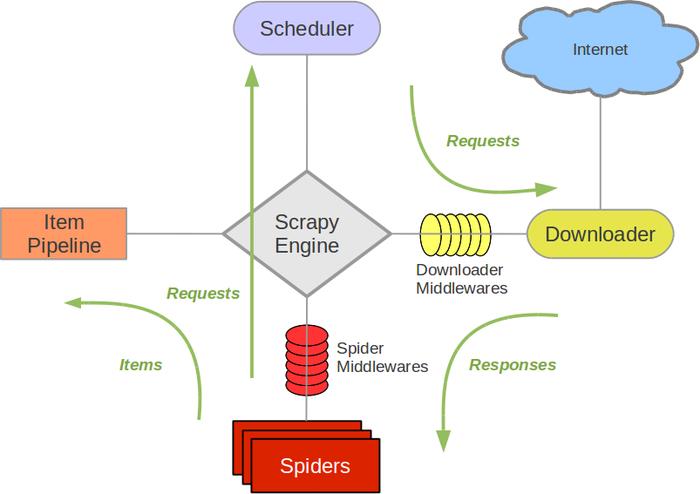
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
Pyspider
pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。
Java
WebMagic
官网:http://webmagic.io/
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。
WebCollector
GitHub: https://github.com/CrawlScript/WebCollector
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
技术分析
网络请求
发送一个正确的网络请求是爬虫的第一步。
参考:爬虫基础——网络请求
获取请求
得到一个网络请求的所有数据才能知道如何编写爬虫
浏览器开发者工具
浏览器插件
- HackBar
网络抓包工具
- Postman
- Fiddler
- BurpSuite
- Wireshark
- …
请求认证
拷贝认证
直接拷贝认证相关的信息到爬虫程序中,以达到认证的目的。
认证请求
根据网络抓包、编写认证过程、让程序完成认证过程,保存认证信息。
-
认证方式
- Basic Auth
- OAuth2
- JWT
- UsernamePassword
此外,以上认证方式也可能组合使用,比如OAuth2 + JWT
-
数据加密
部分网站会对认证信息进行加密处理,例如Base64、AES、RSA等。
模拟认证
对于目标网站认证过程比较复杂的情况下、使用Selenium等操作模拟工具,模拟输入、点击等操作,完成认证,保存认证信息。
验证码
验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart” 的缩写(全自动区分计算机和人类的图灵测试),是一种区分用户是计算机还是人的公共全自动程序。
-
绕过验证码
某一些情形下,并不需要去识别验证码- 验证码只出现一次并且一段时间内不需要重复操作,比如登录
- 服务器端并没有对是否通过验证码进行判断
-
文本
一串随机生成的字母或数字序列(显示为扭曲的图像)和一个文本框。要通过测试并证明您的人类身份,只需在文本框中输入您在图像中看到的字符即可。
为了增加难度,提供了数学验证码,该验证码显示有容易阅读的数字,并且涉及基本的数学运算问题;同时还有3D验证码,该验证码显示具有3D效果的字符。
解决方案:-
人工
-
打码平台
爬虫程序将验证码传给打码平台的识别接口,打码平台将验证码发给后端的“佣工”进行识别,并获取识别结果。参考:https://zhuanlan.zhihu.com/p/24011861
-
OCR识别(涉及人工智能相关领域-图像识别,文本识别)
OCR,即 Optical Character Recognition,光学字符识别。是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。也可以调用API接口,例如百度OCR
-
-
图像
通常为用户提供的是物体、动物、人或风景的图像,而不是失真的文本,以此来区分人和计算机程序。验证码要求用户选择它们标识的正确图像,或将滑块拖动到图像中以使其完整。
解决方案:-
图像识别(涉及人工智能相关领域-图像识别,图像分类)
参考:https://www.sohu.com/a/304263172_814235
也可以调用API接口,例如百度PaddleOCR
-
-
音频
利用从录音中提取的随机单词或数字,将它们组合在一起,甚至给它们添加一些噪音,然后要求用户输入在录音中听到的单词或数字。
解决方案:-
语音识别(涉及人工智能相关领域)
也可以调用API接口,例如百度、阿里云、腾讯云
-
-
短信
解决方案:- 虚拟手机号平台
-
其他
IP限制
如果目标网站对访问的速度或次数要求较高,那么你的 IP 就很容易被封掉,也就意味着在一段时间内无法再进行下一步的工作。
-
伪造X-Forwarded-For
X-Forwarded-For(XFF)是用来识别通过HTTP代理或负载均衡方式连接到Web服务器的客户端最原始的IP地址的HTTP请求头字段。 Squid 缓存代理服务器的开发人员最早引入了这一HTTP头字段,并由IETF在Forwarded-For HTTP头字段标准化草案中正式提出。
这一HTTP头一般格式如下:X-Forwarded-For: client1, proxy1, proxy2
其中的值通过一个 逗号+空格 把多个IP地址区分开, 最左边(client1)是最原始客户端的IP地址, 代理服务器每成功收到一个请求,就把请求来源IP地址添加到右边。
但是这种方式容易被防范:关于X-Forwarded-For被伪造情况下获取真实ip的处理 -
IP代理
代理IP又称代理服务器,是网络信息的中转站,这是一种特殊的网络服务,简单来说使用IP代理可以更改用户的IP地址。它是介于浏览器和Web服务器之间的一台服务器,有了它之后,Request信号会先送到代理服务器,由代理服务器来取回浏览器所需要的信息并传送给你的浏览器。在日常生活中,我们使用IP代理,大多数是用来连接INTERNET(国际互联网)和INTRANET(局域网)。 -
ADSL
ADSL 全称叫做 Asymmetric Digital Subscriber Line,非对称数字用户环路,因为它的上行和下行带宽不对称。它采用频分复用技术把普通的电话线分成了电话、上行和下行三个相对独立的信道,从而避免了相互之间的干扰。 有种主机叫做动态拨号 VPS 主机,这种主机在连接上网的时候是需要拨号的,只有拨号成功后才可以上网,每拨一次号,主机就会获取一个新的 IP,也就是它的 IP 并不是固定的,而且 IP 量特别大,几乎不会拨到相同的 IP,如果我们用它来搭建代理,既能保证高度可用,又可以自由控制拨号切换。
UA限制
UA即为用户代理(User-Agent),服务器通过UA识别访问者的身份。当网站针对指定UA的访问,返回异常页面(如403,500)或跳转到其他页面的情况,即为UA禁封。
解决方案:
- UA字典
反爬机制:UA检测
反反爬策略:UA伪装
流量限制
- 爬虫限速
爬虫限速,模拟真实用户浏览。 - IP代理
请求签名
对请求的url、header、body一部分或者多部分进行签名。
这种请求往往数据中会出现sign等代表签名的字段。
参考:https://blog.csdn.net/sergiojune/article/details/93555686
请求加密
对请求的url、header、body一部分或者多部分进行加密。
流程控制
多线程并发
对于,获取单一类型的不同数据情况下,比如获取用户信息,对于每一个用户的之间是不会影响的,可以采用多线程同时去获取多个用户的数据。
内容提取
压缩
请求headers的Accept-Encoding字段表示浏览器告诉服务器自己支持的压缩算法(目前最多的是gzip),如果服务器开启了压缩,返回时会对响应体进行压缩,爬虫需要自己解压;
加密
有些敏感数据的请求,会对数据内容进行加密。
javascript脚本
前大多数网页属于动态网页(内容由javascript动态填充),尤其是在移动端,SPA/PWA应用越来越流行,网页中大多数有用的数据都是通过ajax/fetch动态获取后然后再由js填充到网页dom树中,单纯的html静态页面中有用的数据很少。
-
模拟JS操作
-
引入JavaScript 引擎执行JS脚本
Python中执行JS代码,通常两个库: js2py、pyexecjs
HTML
正则表达式
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。
xpath
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
BeautifulSoup
BeautifulSoup是一个Python模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查找指定元素,从而使得在HTML或XML中查找指定元素变得简单。
Jsoup
Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
JSON
json
Python2.7中自带了JSON模块,直接import json即可。
FastJson
FastJson是阿里巴巴的开源Java JSON解析库,它可以解析JSON格式的字符串,支持将Java Bean序列化为JSON字符串,也可以从JSON字符串反序列化到JavaBean
媒体
- 直接下载
- 识别
其他
数据存储
文本
CSV
JSON
POI
eg:Word、Execl
数据库
参考文章
- 爬虫技术浅析
- 爬虫技术现状分析
- 浅谈爬虫技术
- Python 爬虫介绍
- Python 爬虫一 简介
- java爬虫(一)主流爬虫框架的基本介绍
- 爬虫访问中,如何解决网站限制IP的问题?
- 爬虫如何解决验证码的问题
- 爬虫基础(动态加载,数据解析)
以上是关于基础网络爬虫(Web crawler)相关技术浅析的主要内容,如果未能解决你的问题,请参考以下文章