Logistic 回归模型的参数估计为啥不能采用最小二乘法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Logistic 回归模型的参数估计为啥不能采用最小二乘法相关的知识,希望对你有一定的参考价值。
首先,的确可以使用「普通最小二乘」,也就是OLS做Y为0/1的回归。但是我们一般不用,为什么呢?因为一般我们的Y为0/1的时候,我们想得到的是Y=1的概率,而概率是不能小于0,不能大于1的,而用OLS则很容易出现小于0或者大于1的概率预测值。这是第一个原因。第二个原因,从稍微计量一点的角度来讲,OLS的关键假设是误差项u与x不相关,但是当Y=0/1的时候,可以想象这个假设是不成立的。第三个原因,不仅仅u与x相关了,而且u的方差也与x相关了,所以u存在着异方差,又违背了BLUE的假设。第四个原因,从线性投影的角度来看OLS,要求Y等向量在一个向量空间里面,但是只能取0/1的Y必然不可能和连续的X一样存在一个N维的向量空间里面。所以如果Y只能取0/1两个值,问题就跳出了线性模型的范围,变成了一个非线性模型。当然由于这个模型比较简单,仍然在「广义线性模型」的框架以内。此外,尽管OLS是不恰当的,但是并不是说「最小二乘」就不能用。因为「最小二乘」广义上来说可不止包含普通最小二乘(OLS),还包括非线性最小二乘(NLS)、加权最小二乘(WLS)等。我觉得某乎上的回答已经非常详细了,所以在此附上链接(仅供参考):/question/23817253/answer/85072173 参考技术A 首先,的确可以使用「普通最小二乘」,也就是OLS做Y为0/1的回归。但是我们一般不用,为什么呢?因为一般我们的Y为0/1的时候,我们想得到的是Y=1的概率,而概率是不能小于0,不能大于1的,而用OLS则很容易出现小于0或者大于1的概率预测值。这是第 参考技术B 可以的,logistic回归分析和一般通过最小二乘法拟合的回归分析不一样,对变量总体分布和方差没有要求。它是通过极大似然估计来拟合的 参考技术C 直接算逻辑斯谛回归与最大熵模型-《统计学习方法》学习笔记
0. 概述:
Logistic回归是统计学中的经典分类方法,最大熵是概率模型学习的一个准则,将其推广到分类问题得到最大熵模型,logistic回归模型与最大熵模型都是对数线性模型。
本文第一部分主要讲什么是logistic(逻辑斯谛)回归模型,以及模型的参数估计,使用的是极大对数似然估计以及梯度下降法,第二部分介绍什么是最大熵模型,首先介绍最大熵原理, 然后根据最大熵原理推出最大熵模型,在求解最大熵模型时候,要引入拉格朗日对偶性(在下一篇文章中)的讲解,将最大熵模型的学习归结为对偶函数的极大化,随后我们证明得对偶函数的极大化等价于最大熵模型的极大似然估计。那么这样的话逻辑斯谛回归模型和最大熵模型的学习归结为以似然函数为目标的最优化问题。最后提出模型学习的方法:IIS(改进的迭代尺度算法)(还有其他的方法,梯度下降法,牛顿和拟牛顿法)。
1.逻辑斯谛回归模型
在介绍logistic回归模型之前,首先简单的讲解一下线性回归模型,这样引入逻辑斯谛会比较容易一些。在线性回归模型中,给定的数据集合D = {(x1, y1), (x2, y2),,…(xm,ym)},其中xi为输入的特征,yi为输出,线性回归试图学得一个线性模型以尽可能的准确的预测实值输出标记。即线性回归试图学得:
![]()
通过衡量h(x)和y之间的差别来确定w和b。使用的方法是试图让均方误差最小,即:
![]()
基于均方误差的最小化求解模型的方法称为“最小二乘法”.
下面正式开始介绍logistic回归,在线性回归的基础上我们考虑二分类问题,也就是说其输出y的取值为0或者是1。而前面提到的线性模型的输出值为实值,于是我们要想办法把线性模型的输出值转化为0/1值,为此我们引入logistic函数:

将线性模型的输出作为logistic函数的输入则得到:

经过变换可以得到:
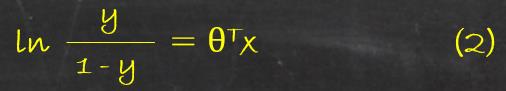
若将y视为x为正例的可能性,则1-y是其为反例的可能性,两者的比值y/(1 - y)称为几率,反应的是x为正例的相对可能性,对几率取对数则得到的对数几率ln y / (1 −y),由此可以看出(2)式实际上是在使用线性回归模型的预测结果去逼近真实标记的对数几率,因此该模型称为“对数几率模型”(logisticre gression)。或者也可以认为logisticre gression就是被sigmoid函数(形状为S型的模型)归一化后的线性模型。
2 模型参数的估计:极大似然估计
若将y视作p(y = 1 | x),也就是x等于1的概率,则由公式(2)可得:
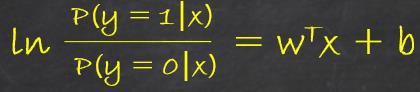
进一步可得:

那么每一个观察到的样本出现的概率为:
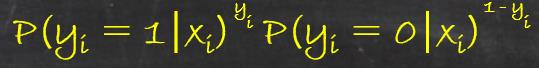
(解释一下上面的这个式子,可以看到当y=1时,后面的一项为1(指数为0),那么得到的是y=1的概率(只剩下前面的一项);同样的当y=0的时候,前面的一项为0, 那么得到的是y=0的概率,所以其始终得到的是在给定的x的条件下得到y的概率,或者说是(x,y)出现的概率)。
此时可以得到似然函数如下:
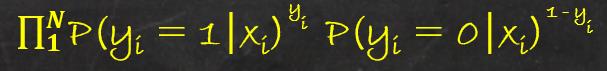
对其取对数得到对数似然函数为:(简单介绍下极大似然估计的原理, 就是要让我们收集到的样本的概率最大,也就是要让上式的值最大).
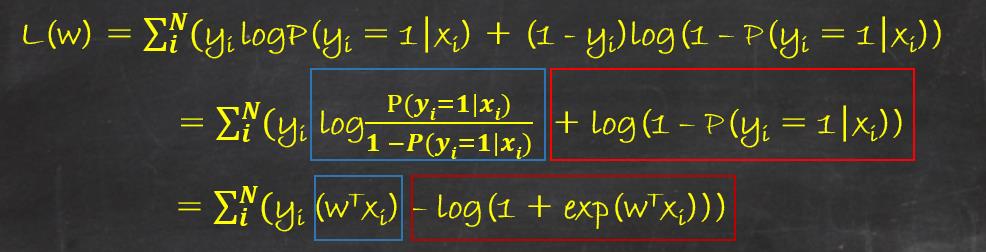
这样问题就变成了以对数似然函数为目标函数的最优化问题,通常采用梯度下降或者拟牛顿法求取参数。
(3).信息论中关于熵的基础知识在介绍最大熵之前,首先简单的介绍下信息论中的熵的有关的基础的知识。
熵是随机变量的不确定性的度量,一个随机变量X的熵H(X)定义为:
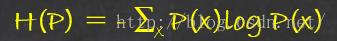
我们知道,如果X服从p(x),则随机变量g(X)的期望可记为Eg(x) = ∑g(x)p(x),那么当g(X)= -log(p(X))时候,X的熵可以解释为变量-log(p(X))的期望值,也就是自信息的期望值。其中自信息是指事件自身所包含的信息,定义为概率的负对数。
直观解释:
熵描述事物的不确定性,或者说事物的信息量。当我们不知道事物的具体状态却知道其所有的可能性时,显然可能性越多,不确定性越大,被获知时得到的信息量越大。反之,当事物是确定的,其信息量为0.假设有X~p(x),对于随机变量的某一个状态x_i,其所包含的信息量由它的不确定性决定,设x_i发生的概率p(x_i),那么他的自信息量可以表示为-log(P(x_i)),另外需要考虑的是,不同的状态发生的概率不同,则信息量也不同,所以自信息不可以用来表征信源的不确定性。而要使用平均自信息量来表征整个信源的信息量。
(更容易的关于熵的理解,摘自http://hutby.blog.163.com/blog/static/1343673122014320229941/)
熵是信息论与编码理论的中心概念。至于条件熵以及互信息都是某种意义上的熵。对于熵的理解是最根本的。几乎所有的信息论教材无一列外的提到熵是刻画信息的多少或者不确定性的。这当然也没有什么问题,但是却立即让人如堕五里雾中,不知熵到底是什么意义。只要稍微钻一下牛角尖,刻画信息或者不确定性为什么非要用这种形式不可呢?在这些书上就难以找到好的答案了。实际上这些定义可以直接从对数的定义得到很清晰的解释。而不需要绕一个圈子从什么信息量、不确定性的角度。刻画信息量或者不确定性可以作为某种解说,但不是最根本最清晰的解说。假定熵的定义公式中对数都是以2为底,那么一个字符序列的熵就是用二进制代码来表示这个字符序列的每个字的最少的平均长度,也就是平均每个字最少要用几个二进制代码。这种说法才是熵的本质意义所在。所以熵这个概念天然地和编码联系在一起,而不是单纯的为了刻画什么信息量或者不确定度之类不着边际的概念。熵就是用来刻画编码的程度或者效率的。
对于一个离散的随机变量X,取值为{x_1,x_2,…x_n}相应的概率为{p_1,p_2,…,p_n}。熵的定义为H(X)=Sum_{i}p_i*log(1/p_i)。在引入比较细致一点的书中,一般会先介绍一个概率事件[X=x_1]的信息量定义为log(1/p_1)=-log(p_1)。一般的书会用小的概率事件含有很大的信息量,大的概率事件含有较少的信息量来解说这个定义。在Shannon的[1]文中还用公理化的方法推导了这个形式。然而这些都掩盖了这种定义内涵的直观含义。实际上这些定义可以直接从对数的定义得到很清晰的解释。为确定起见,这里假定公式中出现的对数(log)都是以2为底的。从对数的定义可以知道log(N)可以理解为用二进制来表示N大约需要多少位。比如log(7)=2.8074,用二进制表示7为三位数字111。那么概率的倒数(1/p_1)是什么意思呢?概率我们知道可以理解为频率,比如一个字符在一个字符序列中出现的概率(频率)是0.1,那么,频率的倒数1/0.1=10。按照比例的意思来理解就是大约在长度为10的字符串中这个字符很可能出现一次,因为这样频率才能是1/10等于概率0.1了。所以一个概率事件的信息量就是观测到这个字符一次(这个事件发生一次)相应的字符串大约多长(用相应的二进制代码长度)。
一个概率事件的信息量按照以上的二进制代码长度来理解之后,那么,熵的意义就很明显了。那就是所有概率事件的相应的二进制代码的平均长度。
再给出条件熵的定义:
条件熵的定义:一个随机变量在给定另一个随机变量下的条件熵,它是条件分布熵关于起条件作用的那个随机变量取平均之后的期望。若(X,Y)~p(x, y),条件熵H(Y|X)定于为:

最大熵原理是概率模型学习的一个准则,最大熵原理认为,学习概率模型时,在所有的可能的概率模型中,熵最大的模型是最好的模型。通常用约束条件来确定概率模型的集合,所以,熵最大原理也可以描述为在满足约束条件的模型集合中选取熵最大的模型。
直观讲, 最大熵原理认为要选择的概率模型
(1)首先必须满足已有的事实,即约束条件。
(2)在没有更多信息的情况下,就假设那些不确定的部分都是等可能的。
但是等可能不容易操作,而熵是一个可优化的数值指标。最大熵原理通过熵的最大化来表示等可能性。
举个例子:假设随机变量X有5个取值{A,B,C,D,E},现在在没有更多的信息的情况下要估计取各个值的概率P(A),P(B),P(C),P(D),P(E).这些概率值满足以下的约束条件,P(A)+P(B)+P(C)+P(D)+P(E)=1,而满足这些条件的概率有无穷多个,在没有其他的任何信息的条件下,最大熵原理告诉我们认为这个分布中去各个值得概率相同是最好的选择,即P(A)=P(B)=P(C)=P(D)=P(E)=1/5.
而在实际问题中,约束条件远远不止一个,很难直接得到概率的分布,所以最大熵模型应运而生。
5.最大熵模型
假设分类模型是一个条件概率分布p(Y|X),这个模型表示的是对于给定的输入X以条件概率P(Y|X)输出Y。
给一个训练集:T ={(x1, y1),(x2, y2),(x3, y3),…(xn,yn)},
学习的目标是用最大熵原理选择最好的分类模型。
该模型能够准确表示随机过程的行为。该模型任务是预测在给定x的情况下,输出y的概率:p(y| x).
(1). 考虑模型应该满足的条件(或者说是样本的特性),给定的训练集合,可以确定的是联合分布P(X,Y)的经验分布和边缘分布P(X)的经验分布,分别以Pt(X,Y)和Pt(X)表示(这里t表示的是经验的意思)这里:
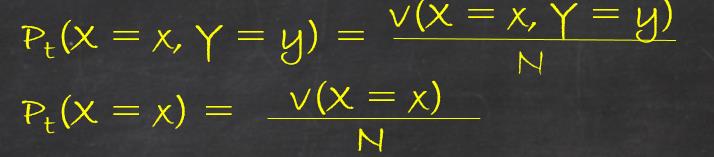
其中V(X = x, Y = y)表示的是训练数据中样本(x,y)出现的频数,V(X =x)表示的是x出现的频数。N是训练集合的大小。
(2).假设给出了很多关于数据的先验信息,也可以理解为约束条件,我们要将这些信息添加到模型中去,为了完成这个目标我们引入了特征函数这个概念。用特征函数f(x, y)描述x和输出y之间的某一个事实,其定义是:

(3). 特征函数f(x, y)关于经验分布的Pt(x, y)的期望值,用EPt(f)表示:(特征的经验概率期望值是所有满足特征要求的经验概率之和):

特征函数f(x,y)关于模型P(Y|X)与经验分布Pt(X)的期望值, 用Ep(f)表示:(特征的真实期望概率是特征在所学习的随机事件中的真实分布) :

如果模型能够获取训练数据集中的信息,那么就可以假设两个期望值是相等的,即:(特征的经验概率与期望概率应该一致),也就是满足下式的要求:
![]() 或者是
或者是![]()
这些称之为模型学习的约束条件,如果有n个特征函数f_i(x,y)就有n个约束条件。
(4)最大熵模型的定义:
假设满足所有的约束条件的模型的集合是:
![]()
定义在条件概率分布上的条件熵为:
![]()
则模型集合C中条件熵H(P)最大的模型称为最大熵模型。(在满足约束条件中选择熵最大的那个。这是一个有约束的优化问题)
5.最大熵模型的学习
最大熵模型的学习过程就是求解最大熵模型的过程,最大模型的学习可以形式化为约束最优化问题:
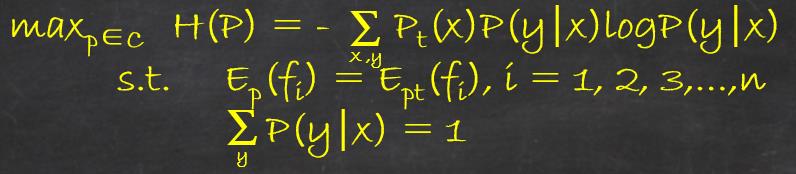
按照最优化的习惯,将求最大值的问题改写为等价的求最小值问题:
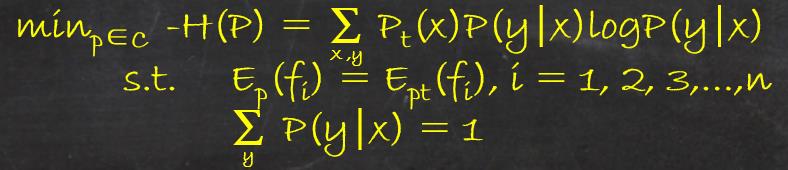
在这里我们将约束最优化的原始问题转化为无约束的最优化的对偶问题(http://blog.csdn.net/robin_xu_shuai/article/details/52803645),通过求解对偶问题来求解原始问题.
(1)首先引入拉格朗日乘子w0,w1,…,wn。定义拉格朗日函数L(P,w).

最优化的原始问题是:

对偶问题是:

(2)求解对偶问题内部的极小化问题,它是关于w的函数,将其记作:

同时,将其解记为:

求L(P, w)对P(y|x)的偏导数:
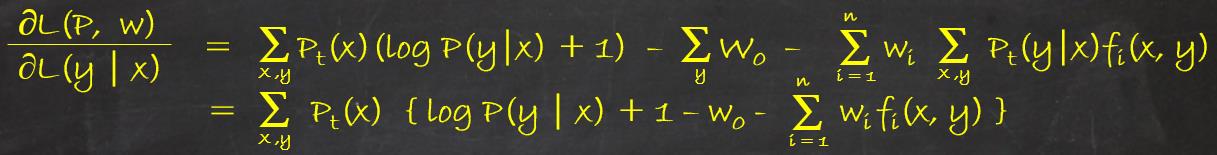
令偏导数为0,P(x)>0的情况下,解得:
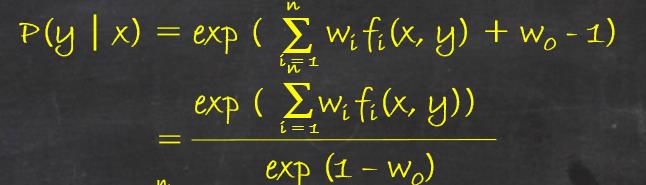
由于:
可得:

最后得到:
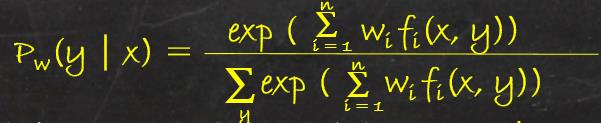
其中f_i(x,y)为特征函数,w_i为特征的权值,式(3)表示的模型P_w = P_w(y | x)就是最大熵模型,w是最大熵模型中的参数向量。
(3)
之后,求解对偶问题外部的极大化问题:
将其解记为w*, 即:
这就是说。可以应用最优化算法求解对偶函数的极大化,得到w*,用来表示P* ∈C,
这里P* = Pw*= Pw*(y|x)是学习到的最优化模型(最大熵模型),也就是说,最大熵模型的学习归结为对偶函数的极大化。
至此,我们得到了最大熵模型,由以下的条件概率分布表示:
下面我们要证明的是对偶函数的极大化等价于最大熵模型的极大似然估计。
6.极大似然估计
目的:证明对偶函数的极大化等价于最大熵模型的极大似然估计。
训练数据的经验概率分布Pt(x,y),条件概率分布P(Y|X)的对数似然函数表示为: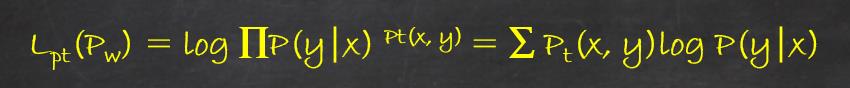
(note:标准的对数似然函数log∏P(y|x),但是在这里为了更好的反应出现x,y关于经验分布Pt(x,y)的分布特征,通过在每个概率上添加相应的指数运算来给出更多的关于经验分布的信息)
(1)当P(y|x)是最大熵模型时,对数似然函数为:
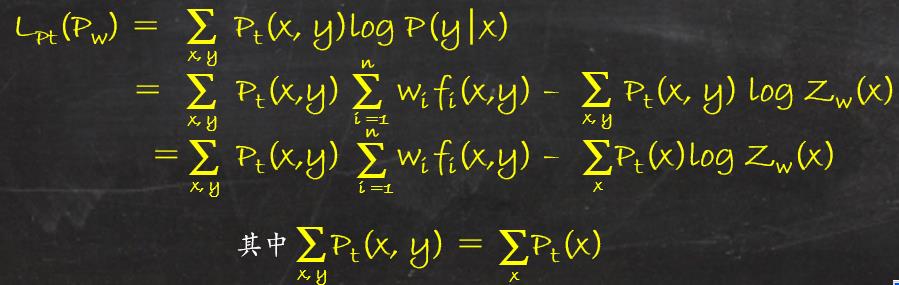
(2)当条件概率分布是P(y|x),再看对偶函数 ψ(w) = min L(P, w) = L(Pw , w)

于是证明了最大熵学习中的对偶函数的极大化等价于最大熵模型的极大似然估计。
7结束
最大熵模型和logistic回归模型有类似的形式,它们又称为对数线性模型。模型学习就是在给定的训练数据条件下对模型进行极大似然估计。也就是说logistic回归模型和最大熵模型学习归结为以似然函数为目标函数的最优化问题,通常通过迭代算法求解。
以上是关于Logistic 回归模型的参数估计为啥不能采用最小二乘法的主要内容,如果未能解决你的问题,请参考以下文章