优化算法笔记(二)优化算法的分类
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优化算法笔记(二)优化算法的分类相关的知识,希望对你有一定的参考价值。
参考技术A (以下描述,均不是学术用语,仅供大家快乐的阅读)在分类之前,我们先列举一下常见的优化算法(不然我们拿什么分类呢?)。
1遗传算法Genetic algorithm
2粒子群优化算法Particle Swarm Optimization
3差分进化算法Differential Evolution
4人工蜂群算法Artificial Bee Colony
5蚁群算法Ant Colony Optimization
6人工鱼群算法Artificial Fish Swarm Algorithm
7杜鹃搜索算法Cuckoo Search
8萤火虫算法Firefly Algorithm
9灰狼算法Grey Wolf Optimizer
10鲸鱼算法Whale Optimization Algorithm
11群搜索算法Group search optimizer
12混合蛙跳算法Shuffled Frog Leaping Algorithm
13烟花算法fireworks algorithm
14菌群优化算法Bacterial Foraging Optimization
以上优化算法是我所接触过的算法,没接触过的算法不能随便下结论,知之为知之,不知为不知。其实到目前为止优化算法可能已经有几百种了,我们不可能也不需要全面的了解所有的算法,而且优化算法之间也有较大的共性,深入研究几个之后再看其他优化算法上手速度会灰常的快。
优化算法从提出到现在不过50-60年(遗传算法1975年提出),虽种类繁多但大多较为相似,不过这也很正常,比较香蕉和人的基因相似度也有50%-60%。当然算法之间的相似度要比香蕉和人的相似度更大,毕竟人家都是优化算法,有着相同的目标,只是实现方式不同。就像条条大路通罗马,我们可以走去,可以坐汽车去,可以坐火车去,也可以坐飞机去,不管使用何种方式,我们都在去往罗马的路上,也不会说坐飞机去要比走去更好,交通工具只是一个工具,最终的方案还是要看我们的选择。
上面列举了一些常见的算法,即使你一个都没见过也没关系,后面会对它们进行详细的介绍,但是对后面的分类可能会有些许影响,不过问题不大,就先当总结看了。
再对优化算法分类之前,先介绍一下算法的模型,在笔记(一)中绘制了优化算法的流程,不过那是个较为简单的模型,此处的模型会更加复杂。上面说了优化算法有较大的相似性,这些相似性主要体现在算法的运行流程中。
优化算法的求解过程可以看做是一个群体的生存过程。
有一群原始人,他们要在野外中寻找食物,一个原始人是这个群体中的最小单元,他们的最终目标是寻找这个环境中最容易获取食物的位置,即最易存活下来的位置。每个原始人都去独自寻找食物,他们每个人每天获取食物的策略只有采集果实、制作陷阱或者守株待兔,即在一天之中他们不会改变他们的位置。在下一天他们会根据自己的策略变更自己的位置。到了某一天他们又聚在了一起,选择了他们到过的最容易获取食物的位置定居。
一群原始人=优化算法中的种群、群体;
一个原始人=优化算法中的个体;
一个原始人的位置=优化算法中个体的位置、基因等属性;
原始人变更位置=优化算法中总群的更新操作;
该位置获取食物的难易程度=优化算法中的适应度函数;
一天=优化算法中的一个迭代;
这群原始人最终的定居位置=优化算法所得的解。
优化算法的流程图如下:
对优化算法分类得有个标准,按照不同的标准分类也会得到不一样的结果。首先说一下我所使用的分类标准(动态更新,有了新的感悟再加):
按由来分类比较好理解,就是该算法受何种现象启发而发明,本质是对现象分类。
可以看出算法根据由来可以大致分为有人类的理论创造而来,向生物学习而来,受物理现象启发。其中向生物学习而来的算法最多,其他类别由于举例有偏差,不是很准确,而且物理现象也经过人类总结,有些与人类现象相交叉,但仍将其独立出来。
类别分好了,那么为什么要这么分类呢?
当然是因为要凑字数啦,啊呸,当然是为了更好的理解学习这些算法的原理及特点。
向动物生存学习而来的算法一定是一种行之有效的方法,能够保证算法的效率和准确性,因为,如果使用该策略的动物无法存活到我们可以对其进行研究,我们也无法得知其生存策略。(而这也是一种幸存者偏差,我们只能看到行之有效的策略,但并不是我们没看到的策略都是垃圾,毕竟也发生过小行星撞地球这种小概率毁灭性事件。讲个冷笑话开cou心zhi一shu下:一只小恐龙对他的小伙伴说,好开心,我最喜欢的那颗星星越来越亮了(完)。)但是由于生物的局限性,人们所创造出的算法也会有局限性:我们所熟知的生物都生存在三维空间,在这些环境中,影响生物生存的条件比较有限,反应到算法中就是这些算法在解决较低维度的问题时效果很好,当遇到超高维(维度>500)问题时,结果可能不容乐观,没做过实验,我也不敢乱说。
按更新过程分类相对复杂一点,主要是根据优化算法流程中更新位置操作的方式来进行分类。更新位置的操作按我的理解可大致分为两类:1.跟随最优解;2.不跟随最优解。
还是上面原始人的例子,每天他有一次去往其他位置狩猎的机会,他们采用何种方式来决定今天自己应该去哪里呢?
如果他们的策略是“跟随最优解”,那么他们选取位置的方式就是按一定的策略向群体已知的最佳狩猎位置(历史最佳)或者是当前群体中的最佳狩猎位置(今天最佳)靠近,至于是直线跑过去还是蛇皮走位绕过去,这个要看他们群体的策略。当然,他们的目的不是在最佳狩猎位置集合,他们的目的是在过去的途中看是否能发现更加好的狩猎位置,去往已经到过的狩猎地点再次狩猎是没有意义的,因为每个位置获取食物的难易程度是固定的。有了目标,大家都会朝着目标前进,总有一日,大家会在谋个位置附近相聚,相聚虽好但不利于后续的觅食容易陷入局部最优。
什么是局部最优呢?假设在当前环境中有一“桃花源”,拥有上帝视角的我们知道这个地方就是最适合原始人们生存的,但是此地入口隐蔽“山有小口,仿佛若有光”、“初极狭,才通人。”,是一个难以发现的地方。如果没有任何一个原始人到达了这里,大家向着已知的最优位置靠近时,也难以发现这个“桃源之地”,而当大家越聚越拢之后,“桃源”被发现的可能性越来越低。虽然原始人们得到了他们的解,但这并不是我们所求的“桃源”,他们聚集之后失去了寻求“桃源”的可能,这群原始人便陷入了局部最优。
如果他们的策略是“不跟随最优解”,那么他们的策略是什么呢?我也不知道,这个应该他们自己决定。毕竟“是什么”比“不是什么”的范围要小的多。总之不跟随最优解时,算法会有自己特定的步骤来更新个体的位置,有可能是随机在自己附近找,也有可能是随机向别人学习。不跟随最优解时,原始人们应该不会快速聚集到某一处,这样一来他们的选择更具多样性。
按照更新过程对上面的算法分类结果如下
可以看出上面不跟随最优解的算法只有遗传算法和差分进化算法,他们的更新策略是与进化和基因的重组有关。因此这些不跟随最优解的算法,他们大多依据进化理论更新位置(基因)我把他们叫做进化算法,而那些跟随群体最优解的算法,他们则大多依赖群体的配合协作,我把这些算法叫做群智能算法。
目前我只总结了这两种,分类方法,如果你有更加优秀的分类方法,我们可以交流一下:
目录
上一篇 优化算法笔记(一)优化算法的介绍
下一篇 优化算法笔记(三)粒子群算法(1)
SVM分类基于灰狼算法优化SVM实现数据分类matlab源码
一、神经网络-支持向量机
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。 1 数学部分 1.1 二维空间 
![]()

![]()

![]()

![]()

![]()

![]()

![]()

![]()

![]() 2 算法部分
2 算法部分 
![]()
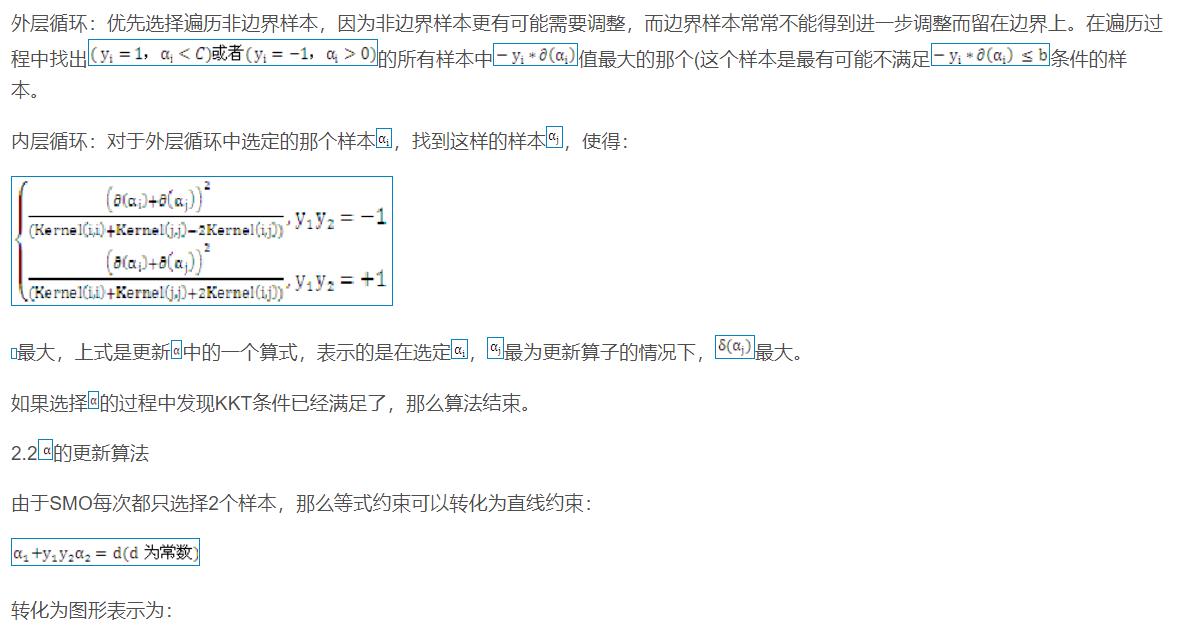
![]()

![]()

二、灰狼算法
灰狼算法
1 前言:
灰狼优化算法(Grey Wolf Optimizer,GWO)由澳大利亚格里菲斯大学学者 Mirjalili 等人于2014年提出来的一种群智能优化算法。该算法受到了灰狼捕食猎物活动的启发而开发的一种优化搜索方法,它具有较强的收敛性能、参数少、易实现等特点。近年来受到了学者的广泛关注,它己被成功地应用到了车间调度、参数优化、图像分类等领域中。
2 算法原理:
灰狼隶属于群居生活的犬科动物,且处于食物链的顶层。灰狼严格遵守着一个社会支配等级关系。如图:

社会等级第一层:狼群中的头狼记为  , 狼主要负责对捕食、栖息、作息时间等活动作出决策。由于其它的狼需要服从 狼的命令,所以 狼也被称为支配狼。另外, 狼不一定是狼群中最强的狼,但就管理能力方面来说, 狼一定是最好的。
, 狼主要负责对捕食、栖息、作息时间等活动作出决策。由于其它的狼需要服从 狼的命令,所以 狼也被称为支配狼。另外, 狼不一定是狼群中最强的狼,但就管理能力方面来说, 狼一定是最好的。
社会等级第二层: 狼,它服从于 狼,并协助 狼作出决策。在 狼去世或衰老后, 狼将成为 狼的最候选者。虽然 狼服从 狼,但 狼可支配其它社会层级上的狼。
狼,它服从于 狼,并协助 狼作出决策。在 狼去世或衰老后, 狼将成为 狼的最候选者。虽然 狼服从 狼,但 狼可支配其它社会层级上的狼。
社会等级第三层: 狼,它服从 、 狼,同时支配剩余层级的狼。 狼一般由幼狼、哨兵狼、狩猎狼、老年狼及护理狼组成。
狼,它服从 、 狼,同时支配剩余层级的狼。 狼一般由幼狼、哨兵狼、狩猎狼、老年狼及护理狼组成。
社会等级第四层: 狼,它通常需要服从其它社会层次上的狼。虽然看上去 狼在狼群中的作用不大,但是如果没有 狼的存在,狼群会出现内部问题如自相残杀。
狼,它通常需要服从其它社会层次上的狼。虽然看上去 狼在狼群中的作用不大,但是如果没有 狼的存在,狼群会出现内部问题如自相残杀。
GWO 优化过程包含了灰狼的社会等级分层、跟踪、包围和攻击猎物等步骤,其步骤具体情况如下所示。
1)社会等级分层(Social Hierarchy)当设计 GWO 时,首先需构建灰狼社会等级层次模型。计算种群每个个体的适应度,将狼群中适应度最好的三匹灰狼依次标记为 、 、 ,而剩下的灰狼标记为 。也就是说,灰狼群体中的社会等级从高往低排列依次为; 、 、 及 。GWO 的优化过程主要由每代种群中的最好三个解(即 、 、 )来指导完成。
2)包围猎物( Encircling Prey )灰狼捜索猎物时会逐渐地接近猎物并包围它,该行为的数学模型如下:
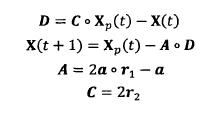
式中:t 为当前迭代次数:。表示 hadamard 乘积操作;A 和 C 是协同系数向量;Xp 表示猎物的位置向量; X(t) 表示当前灰狼的位置向量;在整个迭代过程中 a 由2 线性降到 0; r1 和 r2 是 [0,1] 中的随机向量。
3)狩猎( Hunring)
灰狼具有识别潜在猎物(最优解)位置的能力,搜索过程主要靠 、 、 灰狼的指引来完成。但是很多问题的解空间特征是未知的,灰狼是无法确定猎物(最优解)的精确位置。为了模拟灰狼(候选解)的搜索行为,假设 、 、 具有较强识别潜在猎物位置的能力。因此,在每次迭代过程中,保留当前种群中的最好三只灰狼( 、 、 ),然后根据它们的位置信息来更新其它搜索代理(包括 )的位置。该行为的数学模型可表示如下:

式中: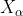 、
、 、
、 分别表示当前种群中 、 、 的位置向量;X表示灰狼的位置向量;
分别表示当前种群中 、 、 的位置向量;X表示灰狼的位置向量; 、
、 、
、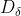 分别表示当前候选灰狼与最优三条狼之间的距离;当|A|>1时,灰狼之间尽量分散在各区域并搜寻猎物。当|A|<1时,灰狼将集中捜索某个或某些区域的猎物。
分别表示当前候选灰狼与最优三条狼之间的距离;当|A|>1时,灰狼之间尽量分散在各区域并搜寻猎物。当|A|<1时,灰狼将集中捜索某个或某些区域的猎物。
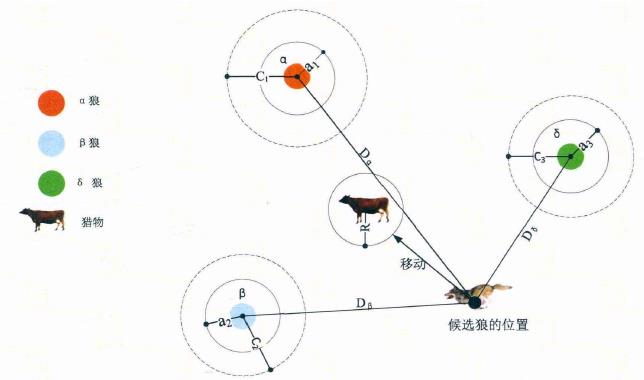
从图中可看出,候选解的位置最终落在被 、 、 定义的随机圆位置内。总的来说, 、 、 需首先预测出猎物(潜 在最优解)的大致位置,然后其它候选狼在当前最优兰只狼的指引下在猎物附近随机地更新它们的位置。
4)攻击猎物(Attacking Prey)构建攻击猎物模型的过程中,根据2)中的公式,a值的减少会引起 A 的值也随之波动。换句话说,A 是一个在区间[-a,a](备注:原作者的第一篇论文里这里是[-2a,2a],后面论文里纠正为[-a,a])上的随机向量,其中a在迭代过程中呈线性下降。当 A 在[-1,1]区间上时,则捜索代理(Search Agent)的下一时刻位置可以在当前灰狼与猎物之间的任何位置上。
5)寻找猎物(Search for Prey)灰狼主要依赖 、 、 的信息来寻找猎物。它们开始分散地去搜索猎物位置信息,然后集中起来攻击猎物。对于分散模型的建立,通过|A|>1使其捜索代理远离猎物,这种搜索方式使 GWO 能进行全局搜索。GWO 算法中的另一个搜索系数是C。从2)中的公式可知,C向量是在区间范围[0,2]上的随机值构成的向量,此系数为猎物提供了随机权重,以便増加(|C|>1)或减少(|C|<1)。这有助于 GWO 在优化过程中展示出随机搜索行为,以避免算法陷入局部最优。值得注意的是,C并不是线性下降的,C在迭代过程中是随机值,该系数有利于算法跳出局部,特别是算法在迭代的后期显得尤为重要。
三、代码
% Grey Wolf Optimizer
function [Alpha_score,Alpha_pos,Convergence_curve]=GWO(SearchAgents_no,Max_iter,lb,ub,dim,fobj)
% initialize alpha, beta, and delta_pos
Alpha_pos=zeros(1,dim);
Alpha_score=inf; %change this to -inf for maximization problems
Beta_pos=zeros(1,dim);
Beta_score=inf; %change this to -inf for maximization problems
Delta_pos=zeros(1,dim);
Delta_score=inf; %change this to -inf for maximization problems
%Initialize the positions of search agents
Positions=initialization(SearchAgents_no,dim,ub,lb);
Convergence_curve=zeros(1,Max_iter);
l=0;% Loop counter
% Main loop
while l<Max_iter
for i=1:size(Positions,1)
% Return back the search agents that go beyond the boundaries of the search space
Flag4ub=Positions(i,:)>ub;
Flag4lb=Positions(i,:)<lb;
Positions(i,:)=(Positions(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;
% Calculate objective function for each search agent
fitness=fobj(Positions(i,:));
% Update Alpha, Beta, and Delta
if fitness<Alpha_score
Alpha_score=fitness; % Update alpha
Alpha_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness<Beta_score
Beta_score=fitness; % Update beta
Beta_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness>Beta_score && fitness<Delta_score
Delta_score=fitness; % Update delta
Delta_pos=Positions(i,:);
end
end
a=2-l*((2)/Max_iter); % a decreases linearly fron 2 to 0
% Update the Position of search agents including omegas
for i=1:size(Positions,1)
for j=1:size(Positions,2)
r1=rand(); % r1 is a random number in [0,1]
r2=rand(); % r2 is a random number in [0,1]
A1=2*a*r1-a; % Equation (3.3)
C1=2*r2; % Equation (3.4)
D_alpha=abs(C1*Alpha_pos(j)-Positions(i,j)); % Equation (3.5)-part 1
X1=Alpha_pos(j)-A1*D_alpha; % Equation (3.6)-part 1
r1=rand();
r2=rand();
A2=2*a*r1-a; % Equation (3.3)
C2=2*r2; % Equation (3.4)
D_beta=abs(C2*Beta_pos(j)-Positions(i,j)); % Equation (3.5)-part 2
X2=Beta_pos(j)-A2*D_beta; % Equation (3.6)-part 2
r1=rand();
r2=rand();
A3=2*a*r1-a; % Equation (3.3)
C3=2*r2; % Equation (3.4)
D_delta=abs(C3*Delta_pos(j)-Positions(i,j)); % Equation (3.5)-part 3
X3=Delta_pos(j)-A3*D_delta; % Equation (3.5)-part 3
Positions(i,j)=(X1+X2+X3)/3;% Equation (3.7)
end
end
l=l+1;
Convergence_curve(l)=Alpha_score;
end
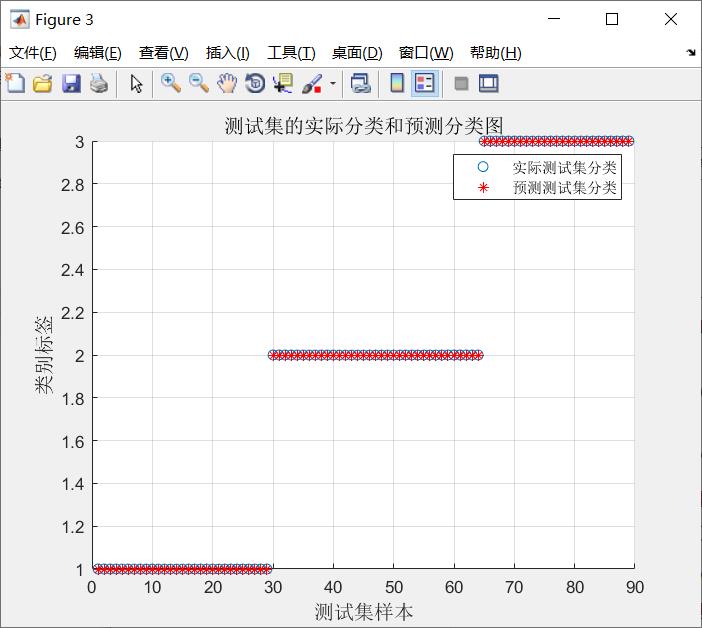
5.参考文献:
书籍《MATLAB神经网络43个案例分析》

以上是关于优化算法笔记(二)优化算法的分类的主要内容,如果未能解决你的问题,请参考以下文章