Lucene Solr Elasticsearch三者之间的关系,怎么选?
Posted 旧言.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene Solr Elasticsearch三者之间的关系,怎么选?相关的知识,希望对你有一定的参考价值。
Lucene简介:
Lucene主要用于构建文本搜索应用程序,包括Web搜索引擎、桌面搜索工具和商业应用程序。它提供了诸如单词分析、查询解析、搜索结果排序等功能,可以轻松地在大量文档中快速搜索和查找相关信息。
Lucene具有以下特点:
可扩展性:Lucene可以轻松处理大规模的数据集,支持分布式搜索,可轻松扩展以处理更多数据。
高性能:Lucene使用了许多高效的算法和数据结构,可以在大型文档集合中快速进行搜索。
全文搜索:Lucene支持全文搜索,可以搜索文档中的所有内容,包括文本、数字、日期等。
多语言支持:Lucene支持多种语言,可以轻松处理不同语言的文本。
易于使用:Lucene提供了简单易用的API,使开发人员可以轻松地构建搜索应用程序。
Lucene是一个强大的文本搜索引擎库,具有高性能、可扩展性和易用性,可以用于构建各种文本搜索应用程序。
Solr简介:
Solr是基于Apache Lucene搜索引擎库构建,提供了强大的全文检索和高级搜索功能,支持多种数据格式和多种查询方式。Solr使用Java语言编写,可以运行在任何支持Java虚拟机的操作系统上。
Solr主要用于构建大规模的搜索应用程序,如电子商务网站、新闻门户网站、社交媒体应用程序等。Solr具有高度可扩展性、高性能、高可用性和易于集成的特点,支持多种部署模式,如独立模式、云模式、集群模式等。
Solr提供了丰富的API和插件,可以轻松地集成到现有的应用程序中,还提供了强大的管理和监控工具,可用于管理索引、监控性能和进行故障排除。此外,Solr还支持多种数据格式和多种查询方式,包括基于文本、XML、JSON等格式的查询,以及支持复杂查询逻辑的查询方式。
Solr是一种强大的搜索平台,它提供了全面的搜索功能和易于集成的特点,适用于各种类型的应用程序。
Elasticsearch简介:
Elasticsearch是基于Lucene搜索引擎的分布式、开源的搜索和分析引擎。它能够快速地搜索、分析和存储大量的数据,并且可以轻松地水平扩展,以处理任何规模的数据。
Elasticsearch主要用于大规模应用程序的搜索、数据分析和数据可视化。它能够快速地搜索和分析大规模数据集,并提供实时的数据可视化。它也可以用于日志分析、安全分析、企业搜索等应用程序中。
Elasticsearch支持以下数据类型:
文本类型(Text):用于全文搜索的长文本,支持分析和索引。
关键字类型(Keyword):用于精确匹配的短文本,不支持分析和索引。
数值类型(Numeric):用于数值的存储和范围查询,支持整数、浮点数和双精度浮点数。
日期类型(Date):用于日期和时间的存储和范围查询。
布尔类型(Boolean):用于布尔值的存储和查询。
二进制类型(Binary):用于二进制数据的存储和查询。
地理位置类型(Geo):用于地理位置的存储和查询,支持点、线、多边形等多种类型的位置。
IP地址类型(IP):用于IP地址的存储和查询。
嵌套类型(Nested):用于嵌套的文档结构的存储和查询。
此外,Elasticsearch还支持自定义数据类型,可以通过插件或自定义分析器等方式进行扩展。
Elasticsearch的优点包括:
分布式架构:可以水平扩展,处理大量数据;
实时搜索和分析:能够快速地搜索和分析大规模数据集;
多种查询方式:支持全文搜索、短语搜索、模糊搜索、正则表达式搜索等;
多种数据类型支持:支持文本、数字、日期、地理位置等多种数据类型;
易于使用:提供简单的RESTful API和丰富的客户端库;
开源:遵循Apache 2.0许可证。
Elasticsearch是一个功能强大的搜索和分析引擎,具有广泛的应用领域,适用于各种规模和类型的应用程序。
Solr 和Elasticsearch怎么选
Solr和Elasticsearch都是流行的开源搜索引擎,具有许多相似之处,但也有一些不同之处。选择哪个搜索引擎取决于您的需求、技术能力和预算。
以下是一些可能帮助您选择的因素:
数据存储:Elasticsearch具有分布式数据存储的能力,可以处理大规模数据集。Solr则更适合小型或中型数据集,因为它使用单个节点存储数据。
查询功能:Elasticsearch在复杂查询方面表现更好。它使用lucene引擎,支持更多的查询类型,如嵌套查询、聚合查询等。Solr也具有强大的查询功能,但它没有像Elasticsearch那样的内置聚合。
可扩展性:Elasticsearch天生就具有水平扩展性,可以很容易地添加或删除节点。Solr也可以扩展,但需要手动配置和管理。
实时搜索:Elasticsearch是一个实时搜索引擎,能够在毫秒级别内返回查询结果。Solr也具有实时搜索功能,但查询速度可能较慢。
社区支持和文档:Elasticsearch在这方面的表现更好,拥有更广泛的社区和更完整的文档。Solr也有一个庞大的社区,但Elasticsearch的社区更加活跃。
如果您处理大型数据集,需要高级查询和实时搜索功能,并且具有足够的技术能力和预算,Elasticsearch可能是更好的选择。如果您处理的是小型或中型数据集,需要更简单的查询,并且预算较低,Solr可能更适合。
倒排索引和正排索引
倒排索引:
倒排索引(Inverted Index)是一种常见的文本索引技术,用于加快文本搜索的速度和效率。在倒排索引中,对于每个单词,记录它出现在哪些文档中以及出现的位置信息。
举个例子,假设有3个文档:
文档1:the quick brown fox jumps over the lazy dog
文档2:the quick brown fox jumps over the brown dog
文档3:the quick brown fox jumps over the brown dog again
对于每个单词,我们可以记录它出现在哪些文档中,以及在文档中出现的位置。例如,单词“quick”出现在文档1、文档2和文档3中,分别在第1个、第1个和第1个位置。因此,我们可以将它们记录在一个倒排索引表中:
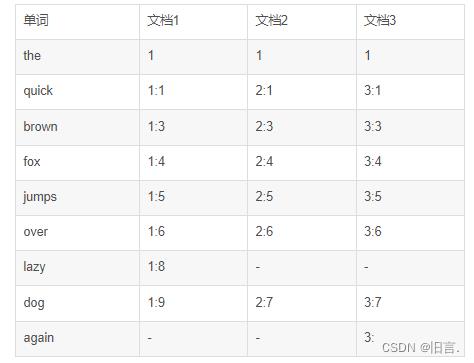
在这个倒排索引表中,每一行代表一个单词,每个单词出现在哪些文档中以及在文档中的位置都被记录下来。例如,“quick”的记录“1:1”表示它出现在文档1中,出现在文档1的第1个位置。通过这种方式,当我们需要搜索某个单词时,我们可以很快地找到包含该单词的所有文档和它们在文档中的位置,从而实现高效的文本搜索
正排索引:
正排索引(Forward Index)是指根据文本内容建立的索引,通常用于实现全文检索。正排索引将文本按照一定的格式(如文档、段落或句子等)分块存储,并为每个块分配一个唯一的标识符,以便后续检索和显示。在正排索引中,每个文本块还包含了该块的一些元信息,如文本的标题、作者、时间戳等等。
正排索引通常是由搜索引擎等系统在建立文本索引时所使用的一种索引结构,它将文本中的每个块(如单词、短语、句子等)都存储在索引结构中,并对每个块建立倒排索引,以支持快速的检索和排序。正排索引在搜索引擎等系统中扮演着非常重要的角色,它可以提高搜索的效率、准确性和可靠性,从而提高用户的搜索体验。
ElasticSearch、Sphinx、Lucene、Solr、Xapian。哪个适合哪个用途? [关闭]
【中文标题】ElasticSearch、Sphinx、Lucene、Solr、Xapian。哪个适合哪个用途? [关闭]【英文标题】:ElasticSearch, Sphinx, Lucene, Solr, Xapian. Which fits for which usage? [closed] 【发布时间】:2011-01-17 07:32:48 【问题描述】:我目前正在寻找其他搜索方法,而不是使用庞大的 SQL 查询。 我最近看到了elasticsearch,并玩弄了whoosh(搜索引擎的Python实现)。
你能给出你选择的理由吗?
【问题讨论】:
Sphinx 与 Solr 比较:***.com/questions/1284083/… Lucene 与 Solr:***.com/questions/1400892/… 嗖嗖诉 Solr:***.com/questions/3226596/… 我真的不明白关闭这样一个建设性问题的人。这样的问题真的很重要…… 那些也是移动目标问题。 【参考方案1】:作为 ElasticSearch 的创建者,也许我可以给你一些理由,说明我为什么要继续创建它:)。
使用纯 Lucene 具有挑战性。如果你想让它真正表现良好,你需要注意很多事情,而且它是一个库,所以没有分布式支持,它只是一个你需要维护的嵌入式 Java 库。
就 Lucene 的可用性而言,早在我创建 Compass 的时候(差不多 6 年了)。它的目的是简化 Lucene 的使用,让日常的 Lucene 变得更简单。我一次又一次遇到的是能够分发 Compass 的要求。我开始在 Compass 内部进行工作,通过与 GigaSpaces、Coherence 和 Terracotta 等数据网格解决方案集成,但这还不够。
分布式 Lucene 解决方案的核心是需要分片。此外,随着 HTTP 和 JSON 作为无处不在的 API 的进步,这意味着可以轻松使用具有不同语言的许多不同系统的解决方案。
这就是我继续创建 ElasticSearch 的原因。它具有非常先进的分布式模型,原生使用 JSON,并公开了许多高级搜索功能,所有这些都通过 JSON DSL 无缝表达。
Solr 也是一种通过 HTTP 公开索引/搜索服务器的解决方案,但我认为ElasticSearch 提供了一个非常出色的分布式模型和易用性(尽管目前缺少一些搜索功能,但不适用于很长,无论如何,我们的计划是将所有 Compass 功能引入 ElasticSearch)。当然,我是有偏见的,因为我创建了 ElasticSearch,所以你可能需要自己检查。
至于Sphinx,我没用过,所以无法评论。我可以向您推荐的是this thread at Sphinx forum,我认为这证明了 ElasticSearch 的卓越分布式模型。
当然,ElasticSearch 的功能远不止分布式。它实际上是在考虑云的情况下构建的。您可以在网站上查看功能列表。
【讨论】:
“你知道,用于搜索”。为 Hudsucker 代理 +1。另外,我对这个软件很感兴趣;) 另外,视频做得很好。你应该再添加一些! 很好,我发现我可以在 heroku 中免费使用 elasticsearch,而不是使用像 solr 这样需要花钱的东西...... ElasticSearch 在没有数据的情况下全新安装后在 64 位 Ubuntu 上使用 230MB 的大内存。我真的希望 Elasticsearch 可以在 PostgreSQL 或 Redis 等较小的 VPS 上运行。 @Xeoncross 你是如何让它工作的?我有 1gb ram VPS,我总是遇到无法分配内存错误..【参考方案2】:我使用过 Sphinx、Solr 和 Elasticsearch。 Solr/Elasticsearch 建立在 Lucene 之上。它添加了许多常用功能:Web 服务器 API、分面、缓存等。
如果您只想进行简单的全文搜索设置,Sphinx 是更好的选择。
如果您想完全自定义搜索,Elasticsearch 和 Solr 是更好的选择。它们非常可扩展:您可以编写自己的插件来调整结果评分。
一些示例用法:
狮身人面像:craigslist.org Solr:Cnet、Netflix、digg.com Elasticsearch:Foursquare、Github【讨论】:
【参考方案3】:我们经常使用 Lucene 来索引和 搜索数以千万计的文档。 搜索足够快,我们使用 不需要的增量更新 很长时间。我们确实花了一些时间 到达这里。的强项 Lucene 是它的可扩展性,一个大 一系列的功能和一个活跃的 开发者社区。使用裸机 Lucene 需要使用 Java 编程。
如果您重新开始,Lucene 家族中适合您的工具是Solr,它比裸 Lucene 更容易设置,并且几乎拥有 Lucene 的所有功能。它可以轻松导入数据库文档。 Solr 是用 Java 编写的,因此对 Solr 的任何修改都需要 Java 知识,但是您可以通过调整配置文件来做很多事情。
我还听说过关于 Sphinx 的好消息,尤其是与 MySQL 数据库结合使用时。不过没用过。
IMO,你应该根据:
所需的功能 - 例如你需要一个法语词干分析器吗? Lucene 和 Solr 有一个,其他的我不知道。 精通实现语言 - 如果您不懂 Java,请不要接触 Java Lucene。您可能需要 C++ 来处理 Sphinx。 Lucene 也被移植到otherlanguages。如果您想扩展搜索引擎,这一点非常重要。 易于实验 - 我相信 Solr 在这方面是最好的。 与其他软件的接口 - Sphinx 与 MySQL 有良好的接口。 Solr 支持 ruby、XML 和 JSON 接口作为 RESTful 服务器。 Lucene 只允许您通过 Java 进行编程访问。 Compass 和 Hibernate Search 是 Lucene 的包装器,可将其集成到更大的框架中。【讨论】:
您提出了一个重要概念,即搜索引擎必须具有适应性。 我从未使用过 Xapian。它看起来像一个很好的搜索库,其功能与 Lucene 的不相上下。同样,最重要的是您的应用程序需求、您希望搜索引擎运行的环境、您对实现语言的熟练程度(Xapian 搜索中的 C++,与许多其他语言的绑定)以及引擎的可定制性。 【参考方案4】:我们在一个带有 10.000.000 + 条 MySql 记录和 10 多个不同数据库的垂直搜索项目中使用 Sphinx。 它对 MySQL 有非常出色的支持,并且在索引方面具有很高的性能,研究速度很快,但可能比 Lucene 略逊一筹。 但是,如果您需要每天快速建立索引并使用 MySQL 数据库,那么它是正确的选择。
【讨论】:
【参考方案5】:compare ElasticSearch and Solr的实验
【讨论】:
【参考方案6】:我的 sphinx.conf
source post_source
type = mysql
sql_host = localhost
sql_user = ***
sql_pass = ***
sql_db = ***
sql_port = 3306
sql_query_pre = SET NAMES utf8
# query before fetching rows to index
sql_query = SELECT *, id AS pid, CRC32(safetag) as safetag_crc32 FROM hb_posts
sql_attr_uint = pid
# pid (as 'sql_attr_uint') is necessary for sphinx
# this field must be unique
# that is why I like sphinx
# you can store custom string fields into indexes (memory) as well
sql_field_string = title
sql_field_string = slug
sql_field_string = content
sql_field_string = tags
sql_attr_uint = category
# integer fields must be defined as sql_attr_uint
sql_attr_timestamp = date
# timestamp fields must be defined as sql_attr_timestamp
sql_query_info_pre = SET NAMES utf8
# if you need unicode support for sql_field_string, you need to patch the source
# this param. is not supported natively
sql_query_info = SELECT * FROM my_posts WHERE id = $id
index posts
source = post_source
# source above
path = /var/data/posts
# index location
charset_type = utf-8
测试脚本:
<?php
require "sphinxapi.php";
$safetag = $_GET["my_post_slug"];
// $safetag = preg_replace("/[^a-z0-9\-_]/i", "", $safetag);
$conf = getMyConf();
$cl = New SphinxClient();
$cl->SetServer($conf["server"], $conf["port"]);
$cl->SetConnectTimeout($conf["timeout"]);
$cl->setMaxQueryTime($conf["max"]);
# set search params
$cl->SetMatchMode(SPH_MATCH_FULLSCAN);
$cl->SetArrayResult(TRUE);
$cl->setLimits(0, 1, 1);
# looking for the post (not searching a keyword)
$cl->SetFilter("safetag_crc32", array(crc32($safetag)));
# fetch results
$post = $cl->Query(null, "post_1");
echo "<pre>";
var_dump($post);
echo "</pre>";
exit("done");
?>
示例结果:
[array] =>
"id" => 123,
"title" => "My post title.",
"content" => "My <p>post</p> content.",
...
[ and other fields ]
Sphinx 查询时间:
0.001 sec.
Sphinx 查询时间(1k 并发):
=> 0.346 sec. (average)
=> 0.340 sec. (average of last 10 query)
MySQL查询时间:
"SELECT * FROM hb_posts WHERE id = 123;"
=> 0.001 sec.
MySQL 查询时间(1k 并发):
"SELECT * FROM my_posts WHERE id = 123;"
=> 1.612 sec. (average)
=> 1.920 sec. (average of last 10 query)
【讨论】:
你试过 sphinx 或 elasticsearch 吗? @dzen 这是狮身人面像;他使用 mysql 查询作为查询执行速度的比较。【参考方案7】:到目前为止,我能找到的唯一 elasticsearch 与 solr 性能比较如下:
Solr vs elasticsearch Deathmatch!
【讨论】:
那很糟糕。他没有提供cmets!看到这个讨论:groups.google.com/a/elasticsearch.com/group/users/browse_thread/… -1 因为“我的您的评论正在等待审核。”和其他人也看到上面的谷歌组链接 -1 ,一年多后,该线程不允许使用cmet,我会认真考虑完全忽略它。【参考方案8】:Lucene 很不错,但是它们的停用词集很糟糕。我不得不手动向 StopAnalyzer.ENGLISH_STOP_WORDS_SET 添加大量停用词,以使其接近可用。
我没有使用过 Sphinx,但我知道人们对它的速度和近乎神奇的“易于设置与令人敬畏”的比率发誓。
【讨论】:
【参考方案9】:试试 indextank。
作为弹性搜索的例子,它被认为比 lucene/solr 更容易使用。它还包括非常灵活的评分系统,无需重新索引即可进行调整。
【讨论】:
使用 solr 也可以在运行时进行 tweek 评分 现在没有索引罐了 LinkdenIn 开源 IndexTank,github.com/linkedin/indextank-engine以上是关于Lucene Solr Elasticsearch三者之间的关系,怎么选?的主要内容,如果未能解决你的问题,请参考以下文章
Lucene Solr Elasticsearch三者之间的关系,怎么选?