论文阅读Attention Bottlenecks for Multimodal Fusion---多模态融合,音视频分类,注意力机制
Posted me_yundou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读Attention Bottlenecks for Multimodal Fusion---多模态融合,音视频分类,注意力机制相关的知识,希望对你有一定的参考价值。
本博客系本人阅读该论文,结合个人理解所写,非逐句翻译,欲知文章详情,请参阅论文原文。
论文标题:Attention Bottlenecks for Multimodal Fusion;
作者:Arsha Nagrani, Shan Yang, Anurag Arnab, Aren Jansen, Cordelia Schmid, Chen Sun,
anagrani, shanyang, aarnab, arenjansen, cordelias, chensun@google.com
Google Research;
出处:NIPS 202
代码地址:
paperwithcode:Attention Bottlenecks for Multimodal Fusion | Papers With Code
github:https://github.com/google-research/scenic/tree/main/scenic/projects/mbt
摘要:
人们对世界的认知,对信息的处理是多模态的,而大多的机器学习模型却是仅针对单模态的。同时,处理多模态问题的模型,大多还是使用late-stage的fusion方法,先分别处理单个模态数据之后fusion为多模态结果。本文提出一种基于transformer的多层fusion方法,借助于“fusion bottlenecks”。本文让不同模态的信息穿过许多小的bottlenecks,迫使模型collate和share不同模态中最重要的信息。作者发现通过这种方式,模型的fusion性能更好,且计算消耗降低。本文做了完整的消融实验,在多个音视频分类基准数据集上取得了SOTA的性能,包括Audioset, Epic-Kitchens and VGGSound。代码和模型已公开。
一、引言
同时的多模态感觉是人类感知学习的关键推动因素。然而对于人工学习系统而言,设计一个unified模型能够处理同时处理多个模态的数据,进行fusion是有难度的:(1)不同模态间学习动态的不同;(2)不同模态内的噪声结构不同,比如某个模态中信息可能对当前任务更有用,而其他模态信息对当前任务可能不太有用;(3)不同的输入数据的表示。音频和视觉的输入表示之间的差距尤其大 --- 许多最先进的音频分类方法依赖于短期傅立叶分析来生成对数梅尔频谱图,然后将它们输入CNN 网络中(这些CNN是专为图像处理设计的)。但是显然,音频的time-frequency表示和图像是有着完全不同的分布的。视频中视觉流一般是三个维度的(两个空间维度和一个时间维度),虽然图像不同空间的区域对应着不同的objects,但是跨帧的图像之间有很多冗余信息,这也是视频处理的一个独特挑战。因此,无论是输入数据的表示,还是神经网络的结构,对不同模态来说都是很不一样的。
本文的目标是视频分类,也就是做音频和视觉(图像)信息的fusion。由于transformer的成功(太成功了,使用场景非常多,适用模态也非常多,这里不再赘述),本文也基于transformer构建自己的模型。一个最简单的思路就是将音频数据和视觉数据先拼接成一个sequence,然后输入进标准的transformer,不需要对transformer结构作大的修改。这样的方式其实就是early-fusion。通过这种方式,transformer里面的attention能够自由、充分地接触和处理来自每个模态的每个维度的信息,但是这种自由是不必要的。因为不同模态间的信息会有冗余,视频的图像帧之间也会有信息冗余。另一方面,这样的attention无法很好进行扩展,对于长时间的视频处理,计算量太大。
针对上述问题,本文设计了两种方式来解决原始transformer中attention的问题。1.如同多数多模态fusion模型一样,将fusion部分往后推移,先让模型单独处理单个模态的信息,然后再做fusion(做mid fusion,而不是early fusion)。这样能够充分提取单模态内部的信息,毕竟不同模态的数据结构和分布差距很大,使用一样的处理方式是不合理的。2.在layer内的不同模态的tokens之间做跨模态的attention。单模态内部仍然是原始的self-attention,但是跨模态的fusion使用每个模态的部分tokens信息来做cross-attention。这样就能降低计算量并且处理部分冗余信息(问题:单模态内部直接使用self-attention,那么其冗余信息就没有处理?或者说在提取单模态信息做 fusion的时候,避开冗余的信息,只提取有效的,这样也算是成功避免了单模态内部冗余信息的影响?毕竟最终的目的是做 fusion)。
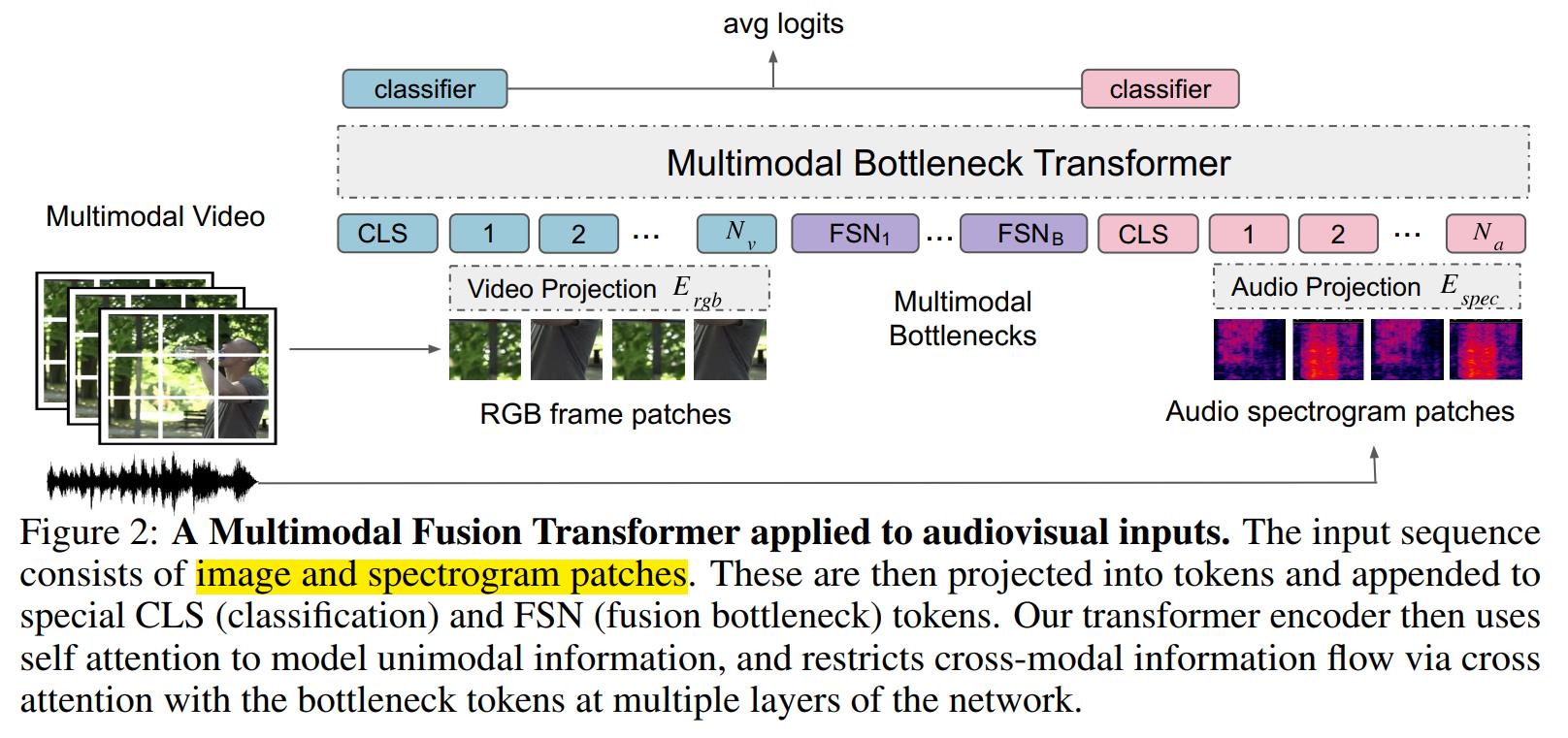
三、多模态融合transformer
本节介绍作者提出的Multimodal Bottleneck Transformer (MBT)结构。首先对最近提出的视觉分类模型Vision Transformer (ViT) 和 音频分类模型Audio Spectrogram Transformer (AST) 做一个总结。然后介绍本文对transformer改进以使之处理音视频分类问题。
3.1 ViT 和 AST 模型
ViT(AST)将图像(音频)数据转换为transformer可接受的一维表示,并且尽可能少修改原始transformer结构,以达到处理视觉(音频)数据的目的。Vit中先将图像分割为N个patches,每个patch可以表示为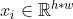 ,(实际上,这里的h和w不是三维图像(H * W* C)的这个意义。这里xi的维度是
,(实际上,这里的h和w不是三维图像(H * W* C)的这个意义。这里xi的维度是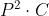 ,其中P是patches的大小,C是图像通道数,具体过程看ViT论文中的解释)。通过线性映射矩阵E,ViT将每个patches映射为一维(维度为d)向量
,其中P是patches的大小,C是图像通道数,具体过程看ViT论文中的解释)。通过线性映射矩阵E,ViT将每个patches映射为一维(维度为d)向量 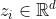 并和类别向量
并和类别向量 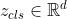 进行拼接,最后再加上位置编码
进行拼接,最后再加上位置编码 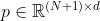 ,就将一张图像转换为了标准transformer可接受的输入形式。
,就将一张图像转换为了标准transformer可接受的输入形式。

然后这些patches(也就是transformer的tokens)被送入后续L个transformer层。每一个transformer层包含使用残差连接的多头自注意力模块 Multi-Headed Self-Attention (MSA), 层正则化模块 Layer Normalisation (LN) 和多层感知机模块 Multilayer Perceptron (MLP) 。将一个transformer层表示为 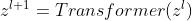 ,那么其过程可表示为:
,那么其过程可表示为:

其中,MSA进行点积的注意力操作,其querys,keys 和 values 是同一个向量经过不同的线性映射得到的,可表示为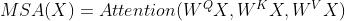 。本文稍后定义的在两个不同向量X,Y之间进行的cross-attention操作,其中querys来自X,而keys和values来自Y,可以表示为:
。本文稍后定义的在两个不同向量X,Y之间进行的cross-attention操作,其中querys来自X,而keys和values来自Y,可以表示为: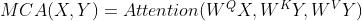 。
。
3.2 多模态transformer
本文先提出三种处理音频和视觉信息的多模态transformer的不同的fusion设计方式。
3.2.1 用最平凡的self-attention做fusion
最直接的处理多模态信息的方式就是将视觉和音频信息拼接为一个sequence,然后输入原始的不更改任何结构的transformer中处理。该模型对长 t 秒的视频采样出 F 帧图像,并将音频波形转换为单个频谱图。然后使用ViT中的方式对图像和音频分别进行编码,最后将视觉和音频表示拼接在一起作为一个单独的sequence。
假设从 F 帧图像中一共提取出 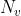 个RGB pathces,每个patches表示为
个RGB pathces,每个patches表示为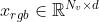 ,以及
,以及 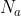 个频谱图patches,记为
个频谱图patches,记为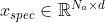 ,那么最终得到的 sequence表示是(将图像和频谱图的一个个patch视为一个个token) :
,那么最终得到的 sequence表示是(将图像和频谱图的一个个patch视为一个个token) :
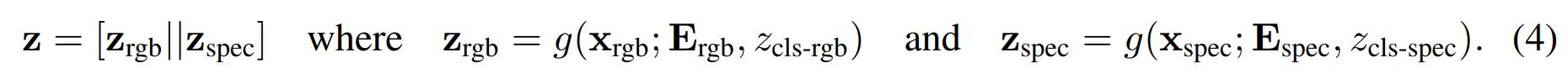
其中 || 代表拼接操作,视觉和音频的映射矩阵 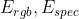 是不同的,他们的类别标签
是不同的,他们的类别标签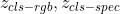 也是每个模态特有的。
也是每个模态特有的。
然后使用原始的transformer对上述sequence进行处理: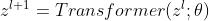 。
。
该模型下,transformer中的self-attention模块能够自由地提取和处理来自不同模态的所有信息(视觉patches和音频patches)。
3.2.2 用 modality-specific 参数做 fusion
作者将3.2.1的模型改为每种模态各自训练自己的参数(即modality-specific),然后使用cross-attention来做信息交换。因此,作者定义了一个cross-transformer层:
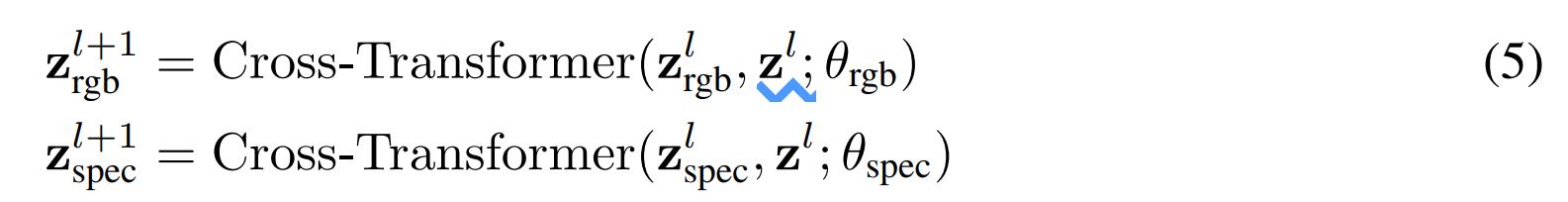
其中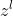 是
是
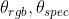 一样时,本节的方法和3.2.1就是一样的。
一样时,本节的方法和3.2.1就是一样的。
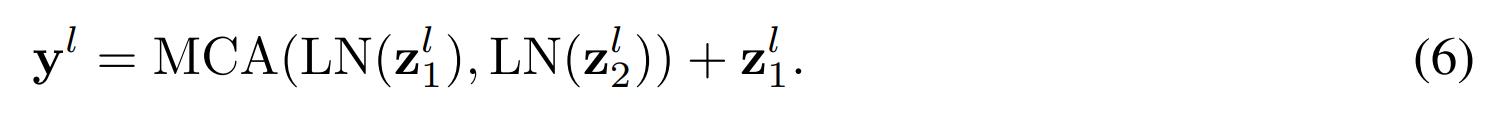
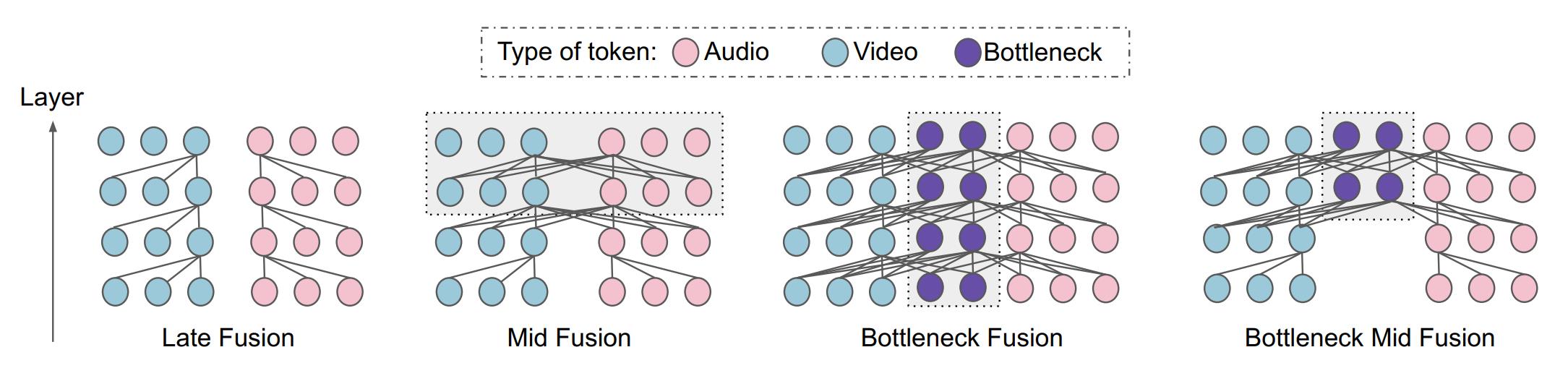
3.2.3 使用attention bottlenecks做fusion
为了降低原始attention的计算复杂性,作者在transformer的输入sequence中引入了B个 fusion bottleneck tokens ,记为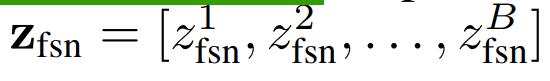
如图2所示。那么现在的输入就变成了:

然后作者将跨模态的attention限制在这些bottlenecks内,对于层layer而言,计算过程变为:
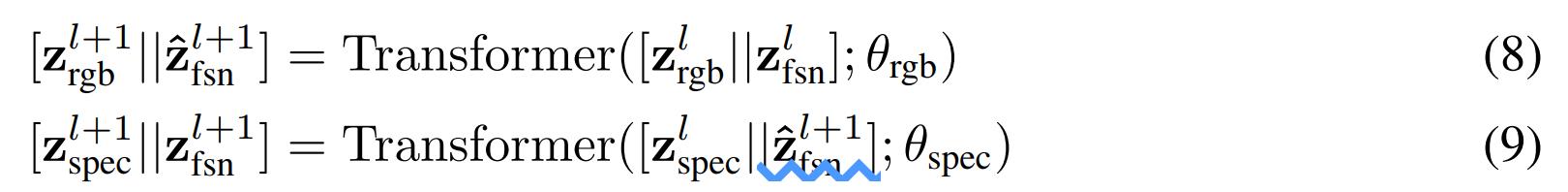
因此,视觉和音频的向量更新只能通过bottleneck tokens来进行,作者通过限制bottleneck tokens的数量远小于原始tokens的数量,来降低计算复杂度。并且通过较少的bottleneck传递跨模态信息时,模型迫使每个模态浓缩自己的信息,且仅传递最重要的信息给另一个模态(避免了模态中冗余信息的传递和计算)。该公式中,bottleneck tokens的向量更新了两次,先用visual信息更新一次(公式8),再用audio信息更新一次(公式9)。(问题:这样的话,模型两个模态的处理过程就成了串行的,先处理visual,再处理audio,会不会影响模型的计算速度呢?)后续实验证明,该模型在保持甚至超越其他模型性能的情况下,降低了计算量。
3.3 fuse的位置:early,mid and late
上一节介绍的是一个transformer layer 内的计算方式,大多数基于transformer的工作堆叠的多个 transformer layer都使用相同的操作(比如ViT)。然而在多模态transformer中,一个共识是在前期先让各个模态分别学习自己的特征,后期再进行多模态的融合。因为我们通常认为前面的层用来学low-level的特征,后面的层学习high-level的特征,而low-level的不同模态特征之间可能还没有出现明显的关联关系,所以融合要放在后面层进行。
本文采用这样的方式实现对fuse位置的控制:在模型的前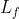 层transformer先做简单的单模态内的self-attention,然后将两个模态的向量拼接起来,作为后面的
层transformer先做简单的单模态内的self-attention,然后将两个模态的向量拼接起来,作为后面的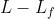 层fusion transformer的输入(后面这些层的fusion方法使用3.2中的方式)。这样的话,当
层fusion transformer的输入(后面这些层的fusion方法使用3.2中的方式)。这样的话,当 就是early fusion,
就是early fusion, 就是late fusion,
就是late fusion,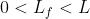 就是mid fusion。也就是下面这样:
就是mid fusion。也就是下面这样:

(3.2节介绍的不同layer内fusion方法,在这一节的应用其实只在后面层。因为后面这些才是fusion层,前面的层是单独处理每个模态信息的部分,不做fusion。一个错误的理解是前面层不是很像3.2.1的计算方式吗?其实概念完全不同。)
3.4 分类
对本文中所有模型及其变体,都使用CLS token作为分类器的输入。作者将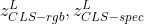 输入相同的线性分类器,然后得到pre-softmax logits的均值。
输入相同的线性分类器,然后得到pre-softmax logits的均值。
4.实验
实验任务:视频分类;
数据集:AudioSet, Epic-Kitchens-100 and VGGSound(附录中还有数据集Moments in
Time and Kinetics上的结果);
数据集详情见论文,包括样本数量和处理方式。
本文使用ViT-Base作为backbone,bottleneck tokens的数目设置为B=4。
4.3 消融分析
本节对不同的模型结构做了消融实验。
4.3.1 fusion策略
本文对3.2中的三种fusion方式分别进行了实验:
(1)最直接的self-attention:层内的attention可以不受限制地访问所有隐式单元(也就是视觉和音频的单模态表示拼接之后直接输入后面原始的transformer层做fusion);
(2)使用不同参数的简单cross-attention:不同模态的transformer层参数不同,每种模态的表示的更新都会访问到所有模态的信息(理解主要看3.2.2的公式),也就是attention依然是面向所有模态信息的;
(3)bottleneck fusion:此方式下的每种模态的表示的更新只能通过访问bottleneck tokens进行,也就是attention只在单模态信息和bottleneck tokens之间进行。
上面的(2)(3)的fusion方式只是单layer内的,为了测试early,mid,late fusion方式对模型的影响,本文还对的值进行实验。
不同模态share weights:
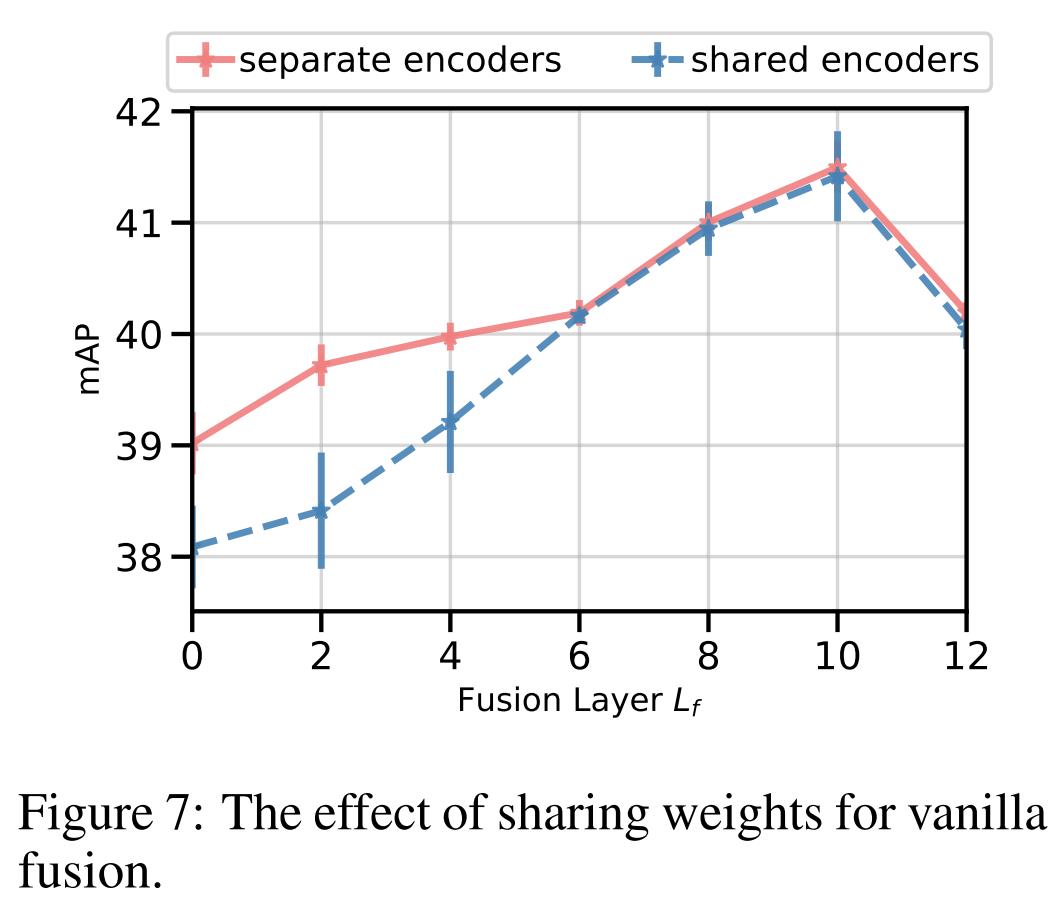
本文还对不同模态(策略(1)和(2)中)之间是否share weights的影响进行了实验。结果在附录的图7中,如下图7所示。当fusion的层数较早时,使用separate的参数效果更好。当late fusion时,是否share weights差距不大。(这是否说明模型的前面层所捕获的信息更modal-specfic,后面的更multimodal了)
融合层的选择:
本文对3.2.2和3.2.3两种fusion方法做了不同融合层选择的实验, 。从下图3左可以看出,mid fusion比early fusion()和late fusion(
。从下图3左可以看出,mid fusion比early fusion()和late fusion( )好。这意味着将融合层放在later的位置,前面的层用来提取模态各自的特征,是有效果的。
)好。这意味着将融合层放在later的位置,前面的层用来提取模态各自的特征,是有效果的。
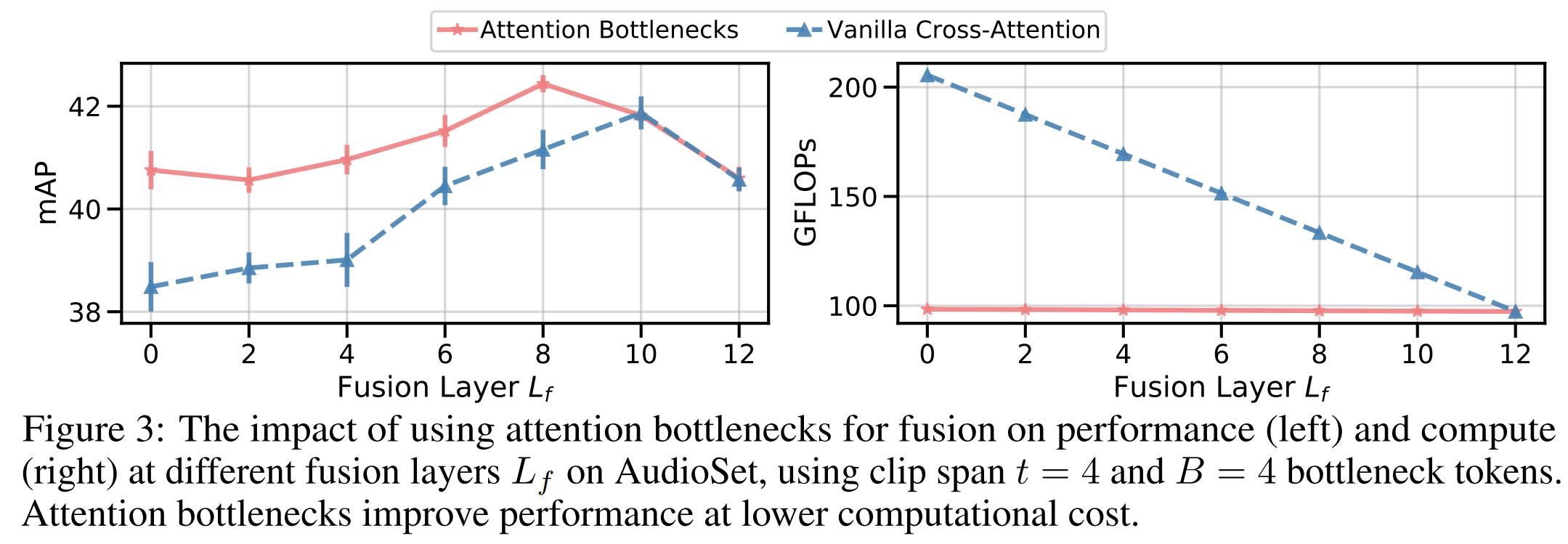
attention bottlenecks:
在上图3左中可以看出,使用attention bottleneck的模型在所有fusion层数选择下结果都比简单的cross-attention模型好。本文还对模型的计算量进行了实验,使用GFLOPs指标,如上图3右。从中可以看出只用很少的bottleneck tokens数目(B=4),本文的模型计算量(红色线条)就比cross-attention(蓝色线条)低很多,且不随着Lf的变化而变化。
bottleneck tokens的数目B:
本文还对B=4,36,64,256,1024进行了实验。发现实验结果差距不大(少于0.5mPA),所以本文后续实验均设置B=4。只用4个bottleneck tokens就可以实现多模态融合的性能提升,以及大大降低模型计算量,说明本文的设计很有用。
4.3.2 输入采样和数据集大小
本节探讨了不同模态上采样策略的影响,同时和单模态模型baselines--仅作用于RGB图像上的纯视觉的transformer和仅作用于音频上的纯音频的transformer进行了对比。
采样窗口大小t:本文transformer模型的一个优势就是可以处理变长的输入长度(为什么?我不懂,transformer的输入tokens数目是固定的吧,不足长的补全)。本文对视频的不同采样窗口t值2,4,6,8进行了实验,结果如下图4所示。在推理时,作者统一采样多个窗口以便能覆盖整个视频。当音频的频谱图 patches数目随着t变化时,作者保持RGB patches的数目不变而改变采样帧的步长(避免内存溢出)。从图4中可以看出,随着输入的增多,audio-only和audio-visual的模型性能跟着增加,但是纯视觉的模型visual-only性能却在降低(作者猜测,可能是增大的步长导致采样出的帧数目减少,训练数据少了)。后文实验中设置t=8s。

同步与异步采样:因为视频中音频和视频(图像)并不一定是完全对齐的,这里实验了不同模态中异步采样带来的影响。结果与分析详见附录。作者发现采样方式对结果影响不大,所以最终选择了同步采样。
模态混合:在将 Mixup rerularization 应用于训练时,有两种不同的方法可以将其应用于多模态输入——标准方法是使用概率参数 α 对一组混合权重进行采样,并使用它来生成所有虚拟模态 -标签对。 此外,本文还探索了一个称之为模态混合的修改版本,它为每个模态采样一个独立的权重。 模态混合比标准混合施加更强的增强,带来 AudioSet 上的性能略有提高。
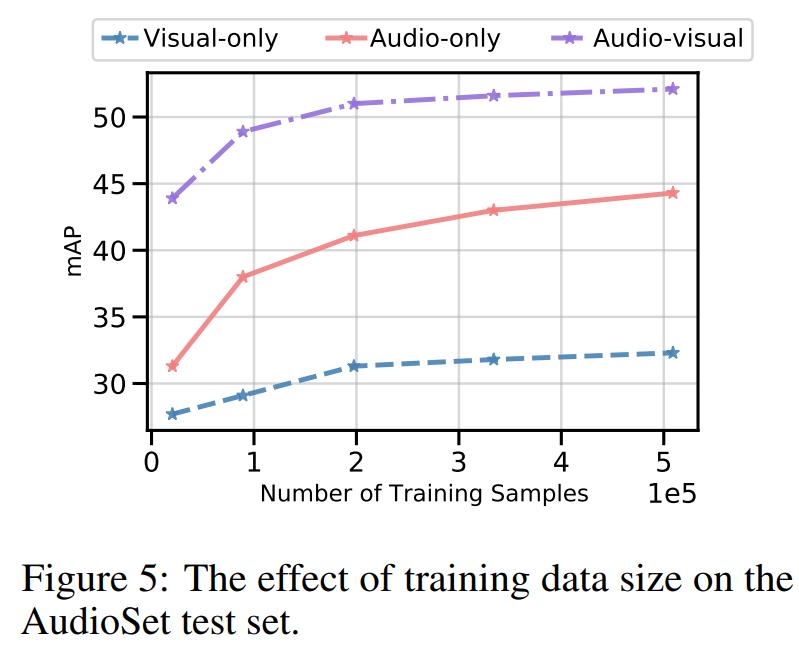
数据集规模的影响:图5中体现了训练样本规模不同的差距。
4.4 结果
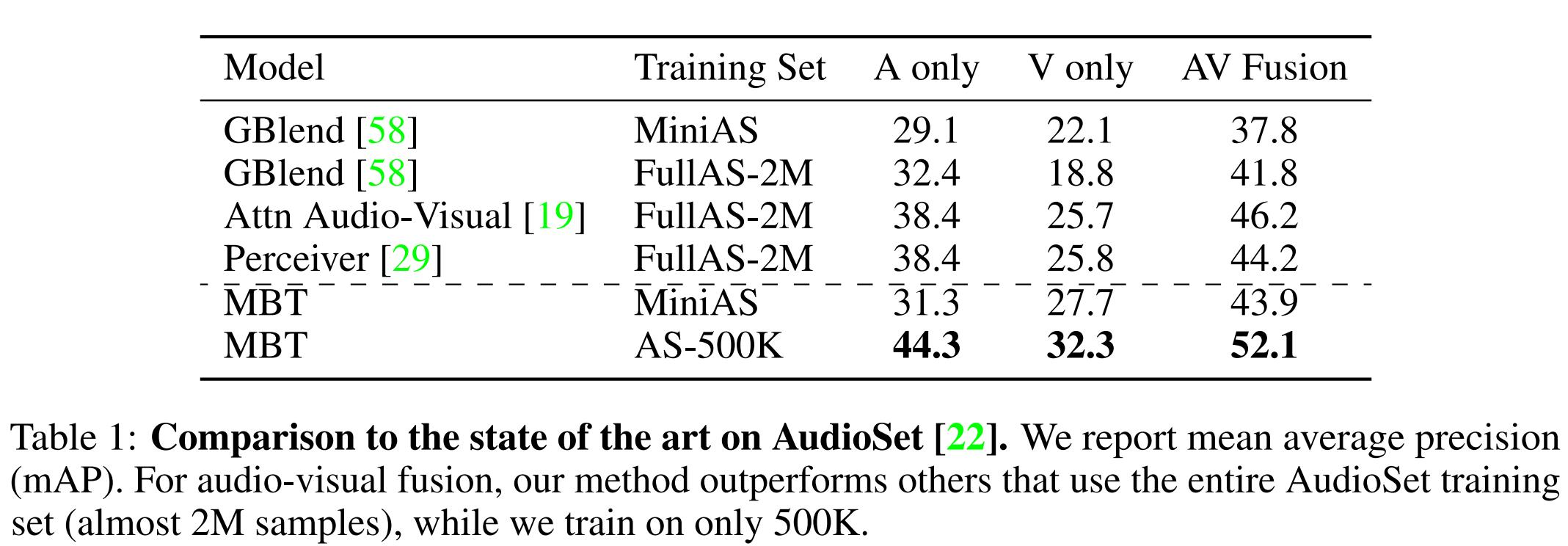
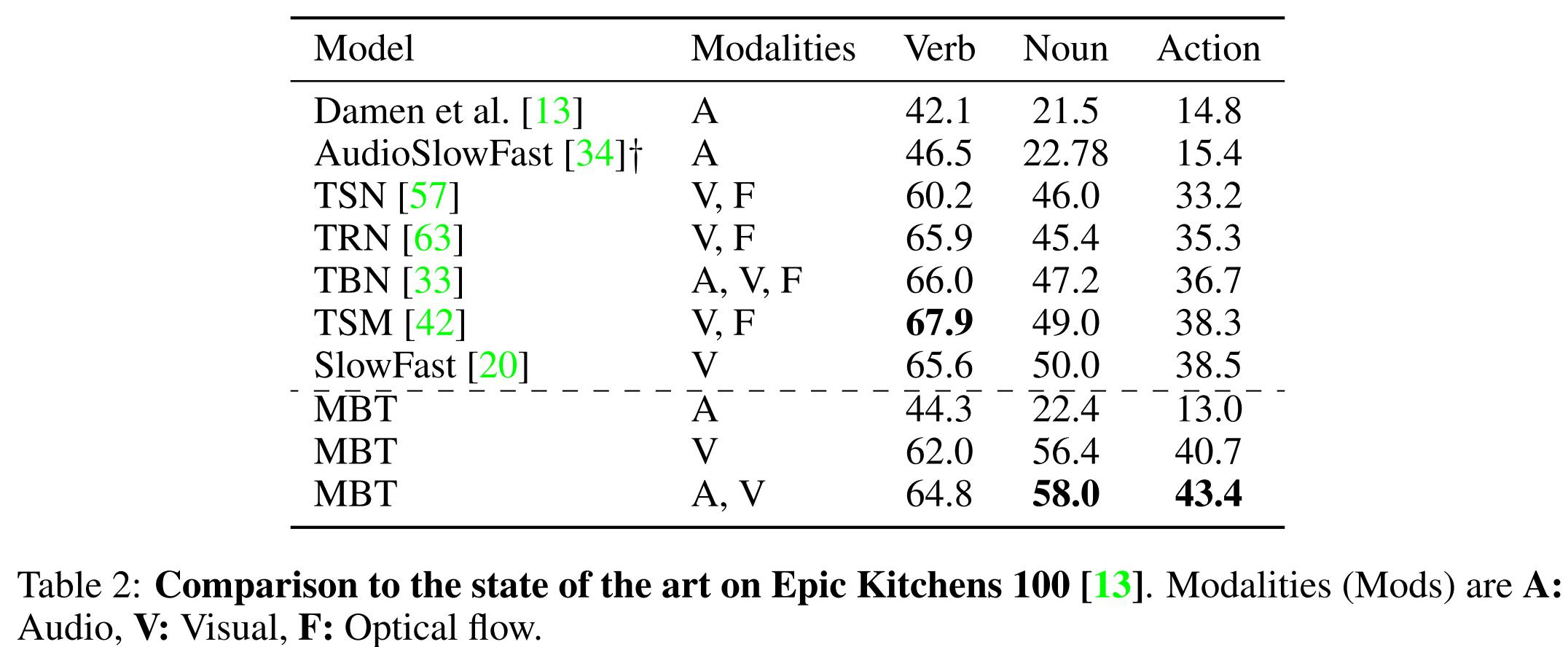
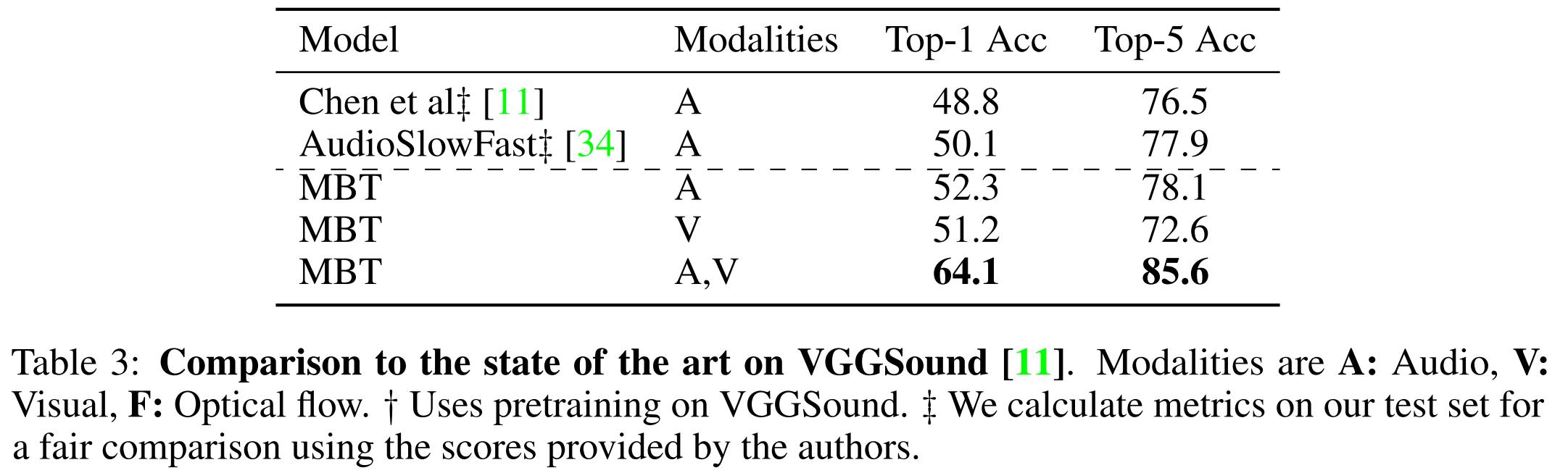
与单模态性能对比:见下表1,2,3.
与SOTA模型对比:见下表1,2,3.
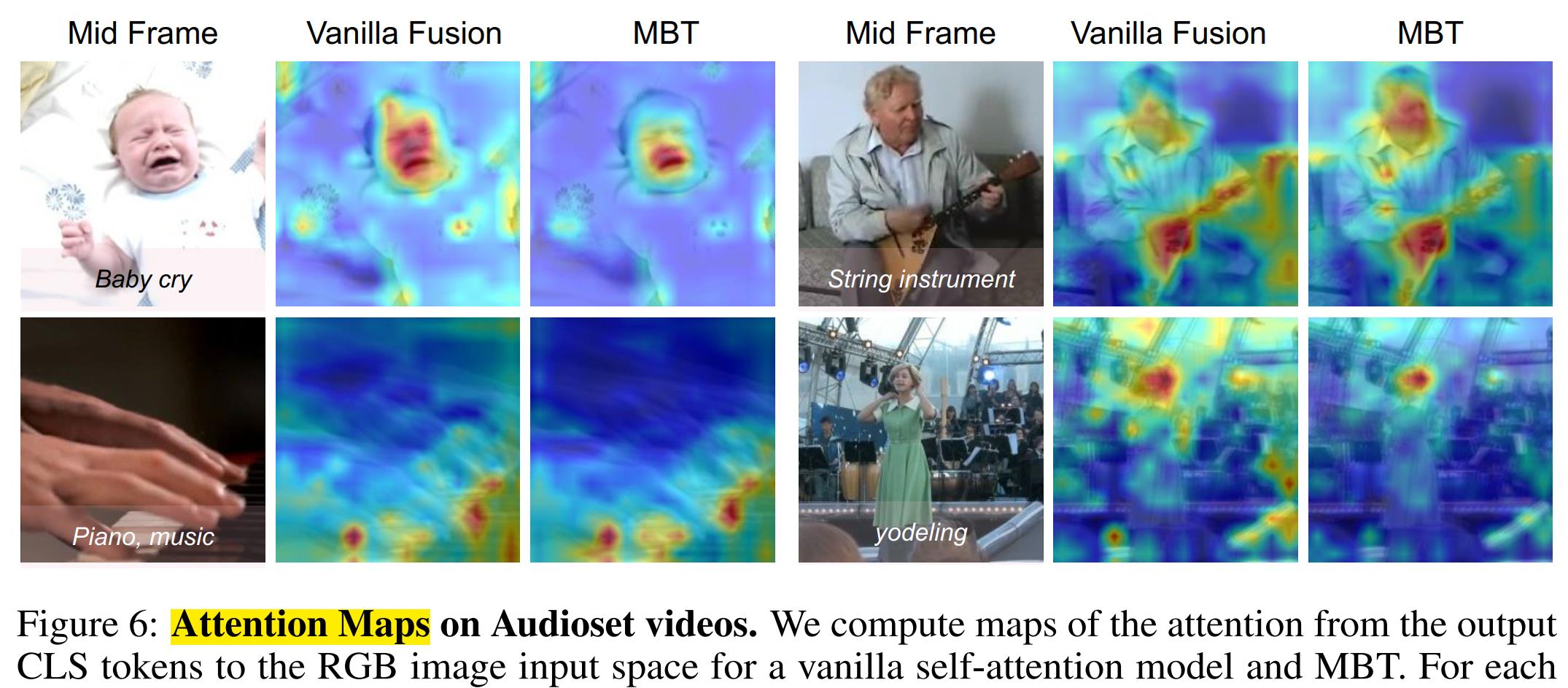
attention maps的可视化:
5.总结
本文提出了一个新的基于transformer的音视频融合结构,探讨了一些列使用cross-attention进行模态融合的策略。
未来可以考虑将MBT应用于更多模态,比如文本和光流。
进一步的影响:
- 多模态融合是机器学习中的一个重要领域,对许多单模态问题的解决提供了新的思路。
- transformer很好用但是计算量较大,本文提出的bottlenecks策略可以有效降低其计算复杂性。有利于transformer的广泛利用。
- 作者发现训练数据集如果包含偏差,可能会使在其上训练的模型不适合某些任务。因此,人们可能会(有意或无意)使用分类模型来做出对社会不同群体产生不同影响的决策,在部署、分析和构建这些模型时牢记这一点很重要。
个人总结:
本文任务是视频分类,方法是多模态视觉(图像)和音频融合。
主要思路是:原始transformer里面的attention层能够freely接触和处理每个token之间的关系,这样对于模态内的冗余信息会造成计算量浪费。所以本文将原始transformer中attention层修改为模态内attention(保持self-attention结构不变)+ 模态间attention(设计cross-attention只在每个模态的部分token之间做attention,避免过度计算冗余信息,降低计算量。并且选择了mid fusion,探讨了fusion层在模型early,mid,late部分的影响。
以上是关于论文阅读Attention Bottlenecks for Multimodal Fusion---多模态融合,音视频分类,注意力机制的主要内容,如果未能解决你的问题,请参考以下文章
#论文阅读#attention is all you need
论文阅读-ICLR2019-ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS
【CV论文笔记】MobileNetV2: Inverted Residuals and Linear Bottlenecks(MobileNetV2理解)
论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
论文阅读 Forecasting Human-Object Interaction: Joint Prediction of Motor Attention and Actions in First
论文阅读之Attention-based Conditioning Methods for External Knowledge Integration(2019)