如何防止softmax函数overflow和underflow?
Posted mathlxj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何防止softmax函数overflow和underflow?相关的知识,希望对你有一定的参考价值。
- 上溢出:c极其大的时候,计算 e c e^c ec
- 下溢出:当c趋于负无穷的时候,分母是一个极小的数,导致下溢出
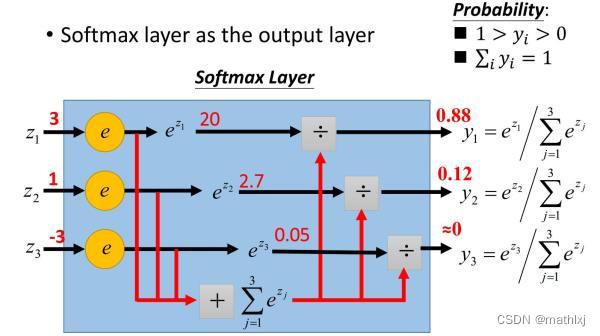
- 解决方法
令 M = max x i , i = 1 , 2 , ⋯ , n M=\\maxx_i, i=1,2,\\cdots,n M=maxxi,i=1,2,⋯,n, 也就是所有 x i x_i xi中的最大值,只要将 f ( x ) i f(x)_i f(x)i的值改为 f ( x ) i − M f(x)i-M f(x)i−M即可解决上溢和下溢的问题,并且,计算结果在理论上仍然和 f ( x ) i f(x)_i f(x)i保持一致.
在很多数值计算的库中,都采用了此类方法保持数值稳定.
softmax函数解释的导数[关闭]
【中文标题】softmax函数解释的导数[关闭]【英文标题】:Derivative of a softmax function explanation [closed] 【发布时间】:2016-10-13 22:40:57 【问题描述】:我正在尝试计算 softmax 激活函数的导数。我发现了这个:https://math.stackexchange.com/questions/945871/derivative-of-softmax-loss-function 似乎没有人给出正确的推导,我们将如何得到 i=j 和 i!= j 的答案。有人可以解释一下吗!当在 softmax 激活函数的分母中涉及求和时,我对导数感到困惑。
【问题讨论】:
我投票结束这个问题,因为它与编程无关 是的。神经网络中有一种叫做 softmax 函数的东西,虽然可以使用库,但了解底层数学是一个优势。 @desertnaut @mLstudent33 我们有不少于 3 个 (!) 专门的 SE 站点来解决此类 非编程 ML 问题,这些问题在这里是题外话;请参阅***.com/tags/machine-learning/info 中的介绍和注意事项 我投票结束这个问题,因为它与 help center 中定义的编程无关,而是关于 ML 理论和/或方法 - 请参阅 ***.com/tags/neural-network/info 中的说明 @mLstudent33 衷心感谢关于 softmax 和库的小型讲座,但我想我明白了 ***.com/questions/34968722/… 【参考方案1】:求和的导数是导数之和,即:
d(f1 + f2 + f3 + f4)/dx = df1/dx + df2/dx + df3/dx + df4/dx
为了推导出p_j 相对于o_i 的导数,我们开始:
d_i(p_j) = d_i(exp(o_j) / Sum_k(exp(o_k)))
我决定将d_i 用于与o_i 相关的导数,以便于阅读。
使用我们得到的乘积规则:
d_i(exp(o_j)) / Sum_k(exp(o_k)) + exp(o_j) * d_i(1/Sum_k(exp(o_k)))
查看第一项,如果i != j,导数将是0,这可以用delta function 表示,我称之为D_ij。这给出(对于第一个任期):
= D_ij * exp(o_j) / Sum_k(exp(o_k))
这就是我们原来的函数乘以D_ij
= D_ij * p_j
对于第二项,当我们单独导出和的每个元素时,唯一的非零项将是 i = k,这给了我们(不要忘记幂规则,因为和在分母中)
= -exp(o_j) * Sum_k(d_i(exp(o_k)) / Sum_k(exp(o_k))^2
= -exp(o_j) * exp(o_i) / Sum_k(exp(o_k))^2
= -(exp(o_j) / Sum_k(exp(o_k))) * (exp(o_j) / Sum_k(exp(o_k)))
= -p_j * p_i
将两者放在一起,我们得到了一个非常简单的公式:
D_ij * p_j - p_j * p_i
如果您真的需要,我们可以将其分为i = j 和i != j 两种情况:
i = j: D_ii * p_i - p_i * p_i = p_i - p_i * p_i = p_i * (1 - p_i)
i != j: D_ij * p_i - p_i * p_j = -p_i * p_j
这是我们的答案。
【讨论】:
非常感谢!这很清楚。我不能要求更好的解释了! :) 我很高兴我现在完全理解了推导。我将把它引用到 math.stack 交换上的未回答者! @SirGuy 你的第三个表达式不应该是d_i(exp(o_j)) / Sum_k(exp(o_k)) + exp(o_j) * d_i(1/Sum_k(exp(o_k))) 吗?最后一个o_k之前缺少exp
@harveyslash 首先,在您链接到的问题中,您错误地说您将雅可比行列式的元素相加以获得“最终”导数。这是不正确的,而不是将雅可比视为导数,而不是导致导数的中间步骤。
@harveyslash 在我的解决方案中,i 和 j 指的是雅可比矩阵的元素。您似乎认为趋于 0 的“事物”是导数,但它只是偏导数的一部分。您手动写出每个导数(用于 4 个输入),而我处理的是一般情况。
@harveyslash 到达 0 的是子表达式 d_i(exp(o_j)),它是子表达式 d_i(exp(o_j)) / Sum_k(exp(o_k)) 的一部分。仔细看括号,你会看到这是the derivative of exp(o_j)`,相对于o_i 除以Sum over k of exp(o_k)。 Sum_k(exp(o_k)) 相对于o_i 的导数在乘积规则扩展的第二部分处理。这是否有助于解决问题?【参考方案2】:
对于它的价值,这是我基于 SirGuy 答案的推导:(如果发现任何错误,请随时指出)。
【讨论】:
非常感谢!我只有一个疑问:为什么Σ_k ( ( d e^o_k ) / do_i ) 从第 4 步到第 5 步评估为 e^o_i?如果您能就该问题提供任何见解,我将不胜感激。
@duhaime 好问题。逐一考虑该总和的所有条款,看看每个条款会发生什么。您会看到有两种情况:当 i = k 时,术语是 d/do_i e^o_i,即 e^o_i。当 i != k 时,你会得到一堆零。【参考方案3】:
假设你有一个形状为 (N, 1) 的数组
import numpy as np
def softmax(x):
return np.exp(x) / np.sum(np.exp(x))
def softmax_dash(x):
I = np.eye(x.shape[0])
return softmax(x) * (I - softmax(x).T)
【讨论】:
以上是关于如何防止softmax函数overflow和underflow?的主要内容,如果未能解决你的问题,请参考以下文章