「2020IEEE」Learning in the Air: Secure Federated Learning for UAV-Assisted Crowdsensing
Posted Jackie-MAX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「2020IEEE」Learning in the Air: Secure Federated Learning for UAV-Assisted Crowdsensing相关的知识,希望对你有一定的参考价值。
论文题目:Learning in the Air: Secure Federated Learning for UAV-Assisted Crowdsensing
核心思想:在联邦学习中加入区块链技术,利用区块链的抗单点故障和不可变性,解决联邦学习仍存在的安全性问题;利用强化学习的两层激励机制,使联邦学习的各参与方能够持续的参与联邦过程。
场景
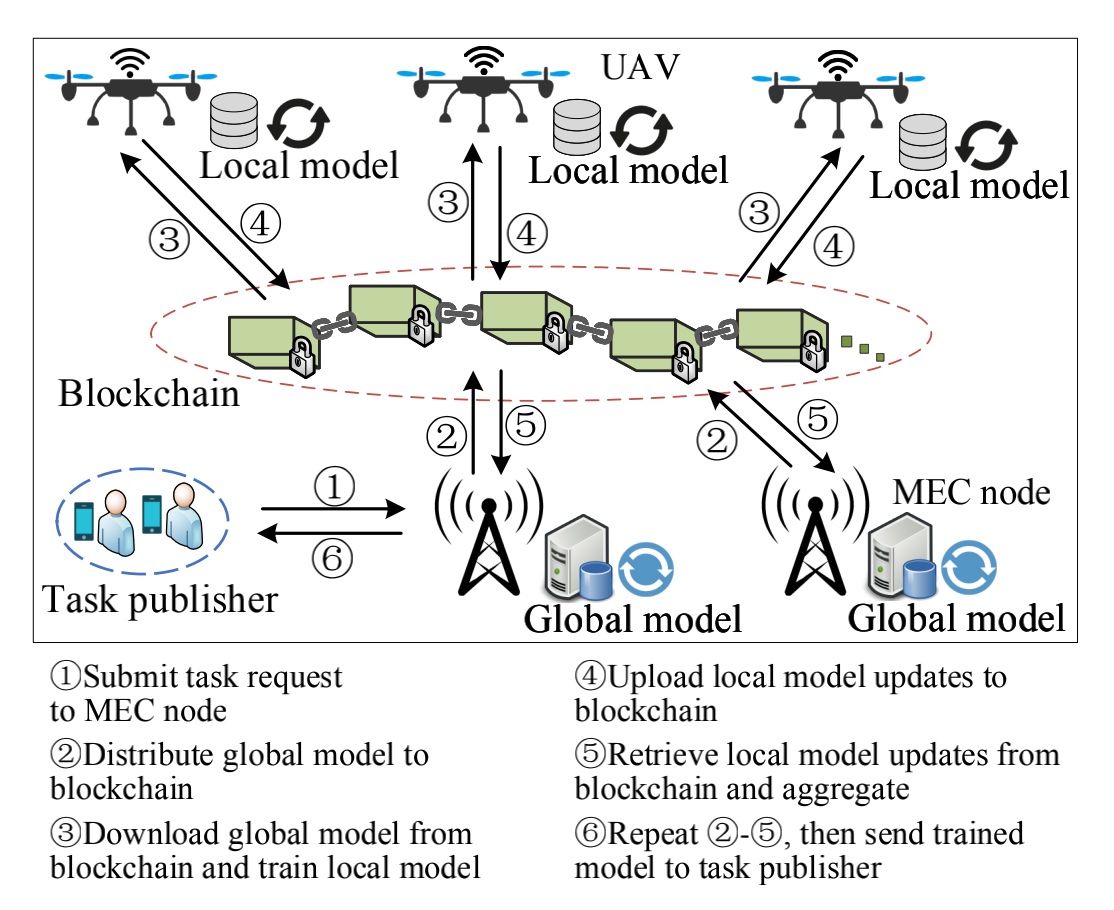
- 4种角色:UAVs、任务发布者、边缘计算(MEC)节点、联盟链
- 6个过程:
- 1:任务发布者向MEC节点提交任务请求
- 2:MEC节点发布全局模型到区块链
- 3:UAVs从区块链中下载全局模型,利用本地数据训练本地模型
- 4:UAVs训练结束后上传本地模型更新到区块链
- 5:MEC节点从区块链中检索本地模型更新进行聚合
- 6:重复1-5直到模型收敛或达到最大训练轮次,最后将训练好的模型发送给任务发布者
贡献
-
采用区块链、LDP(本地差分隐私)、强化学习技术,提出了SFAC,即在无人机辅助移动众包感知场景下,一种安全的联邦学习框架。考虑了网络中的三种攻击,并提出了相应的措施来保护UAVs的协作学习;
-
采用联盟链网络,利用其不可变性、相互验证和分布式共识机制,致力于分布式数据训练、模型共享和贡献追踪;
-
设计了差异隐私算法用于保护UAVs共享模型的隐私,同时保证了全局聚合精度;
-
基于强化学习,可以在不感知网络的准确参数情况下,
获得任务发布者的最优支付策略和UAVs的最优本地模型质量策略; -
仿真实验验证了SFAC的有效性。SFAC可以有效的激发高质量的模型共享,得到最优策略和更好的效用。
系统模型
网络模型
场景图中包含4中角色:UAVs、任务发布者、MEC节点、联盟链。
-
UAVs
不同无人机在相同类型的传感器上具有不同的传感能力。定义
S C i , g ∈ [ 0 , 1 ] SC_i,g\\in[0,1] SCi,g∈[0,1],表示第i架UAV上第g个传感器的传感能力;0/1分别表示具有最低/最高传感能力。 -
任务发布者
任务发布者作为用户,向附近的MEC节点提交感知任务,每个人任务分发给在指定位置上配备有一组传感器的UAVs。 -
MEC节点
每个MEC节点都部署在一个地面基站上,可以提供边缘计算和无线通信。MEC节点之间以一种协作的方式工作,这样的好处就是,每个任务都可以分配给一个可以覆盖该任务指定位置的MEC节点。 -
联盟链
在区块链中,只有授权节点才能参与去中心化网络,这里考虑两种授权节点:全节点和轻量节点。- 全节点: 存储了所有的区块数据,并作为区块链中的公示节点用于新交易的验证、ledge management和区块链更新。
- 轻量节点:只存储块头,可以从全节点上下载最新的区块链数据,可以生成、转发和交换交易,但不能进行共识过程。
在该场景中,MEC节点作为全节点,UAVs作为轻量节点。
联邦学习模型
第k轮全局训练过程分为三个阶段:
- k=0时,所有UAVs的本地模型参数被初始化为相同的值;
- 本地更新。k>=1时,所有UAVs通过SDG利用上一轮的全局模型,在本地数据集上进行本地模型训练,然后上传其本地模型到区块链用于相互验证;
- 全局聚合。MEC节点通过检索区块链上的本地模型用于全局模型聚合。
在达到相应的准确率后,学习过程结束,将全局模型或者学习结果返回给任务发布者。
任务模型
系统中,位于MEC节点m的某个特定任务j可以表示为:
t
a
s
k
j
=
<
I
D
j
∣
∣
d
e
s
c
j
∣
∣
l
o
c
j
∣
∣
z
j
∣
∣
T
j
M
A
X
∣
∣
G
j
∣
∣
t
i
m
e
j
∣
∣
S
i
g
j
>
task_j=<ID_j||desc_j||loc_j||z_j||T_j^MAX||G_j||time_j||Sig_j>
taskj=<IDj∣∣descj∣∣locj∣∣zj∣∣TjMAX∣∣Gj∣∣timej∣∣Sigj>
I
D
j
ID_j
IDj为任务j的唯一表示;
d
e
s
c
j
desc_j
descj为任务发布者提交任务j的任务描述;
l
o
c
j
loc_j
locj和
z
j
z_j
zj为任务j指定的水平位置和高度;
T
j
M
A
X
T_j^MAX
TjMAX为任务j的生存时间(TTL);
G
j
G_j
Gj为任务j所需要的传感器类型集;
t
i
m
e
j
time_j
timej为任务j的发布时间;
s
i
g
j
sig_j
sigj为任务发布者的签名。
不同UAVs在全局聚合中具有不同贡献.定义QoLM(本地模型质量)矩阵。直观的看,UAVs配备的传感器传感能力越强,其所收集的传感数据精度越高;因此,可以认为UAVs的传感数据质量与其平均传感能力成正比。
s
i
,
j
=
1
∣
G
j
∣
∑
g
∈
G
j
s
c
i
,
j
s_i,j=\\frac1|G_j|\\sum_g\\in G_jsc_i,j
si,j=∣Gj∣1g∈Gj∑sci,j
因此,UAV i在任务j上的QoLM表示为:
q
i
,
j
=
F
(
s
i
,
j
,
D
i
,
j
)
q_i,j=\\mathitF(s_i,j,D_i,j)
qi,j=F(si,j,Di,j)
移动模型
UAVs的位置表示在三维坐标系下。将任务时间划分为T个等长时隙
T
=
1
,
2
,
.
.
.
T
\\mathbbT=\\big\\1,2,...T\\big\\
T=1,2,...T,时隙
τ
\\tau
τ可以充分小,UAV可以精确表示在某个时隙下。
I
i
=
[
x
i
(
t
)
,
y
i
(
t
)
,
z
i
]
\\mathbfI_i=[x_i(t),y_i(t),z_i]
Ii=[xi(t),yi(t),zi]
在时间范围T内,UAV的飞行轨迹表示为:
I
i
=
I
i
(
1
)
,
I
i
(
2
)
.
.
.
I
i
(
T
)
,
s
.
t
∣
∣
I
i
(
t
+
1
)
−
I
i
(
t
)
∣
∣
≤
τ
V
i
‾
,
1
≤
t
<
T
\\begincases &\\mathbfI_i = \\big\\\\mathbfI_i(1),\\mathbfI_i(2)...\\mathbfI_i(T)\\big\\ ,\\\\ & s.t \\ ||\\mathbfI_i(t+1)-\\mathbfI_i(t)||\\leq\\tau\\overline\\mathbfV_i ,1\\leq t<T\\\\ \\endcases
Ii=Ii(1),Ii(2)...Ii(T),s.t ∣∣Ii(t+1)−Ii(t)∣∣≤τVi,1≤t<T
V
i
‾
\\overline\\mathbfV_i
Vi为UAV最大飞行速度。
通信模型
A2G和G2A路径损失主要为LoS传输,可以描述为准静态块衰落信道模型。
威胁模型
与集中式人工智能方法相比,联邦学习通过将学习阶段分为局部训练和全局聚合,减轻了数据隐私问题。然而,它还是带来了一些新的安全问题。我们定义了UAVs在联邦学习过程中MCS中的隐私和安全威胁。
- 隐私泄露攻击。
在分布式学习过程中,UAV更新的局部模型参数仍可能泄露训练过程中使用的某些数据的信息。此外,攻击者还可以通过差分攻击从局部模型更新中推断出UAV是否存在于特定的任务中。由于每个任务都有指定的传感位置,因此可以披露所涉及的UAV的位置隐私。 - 低质量局部模型更新攻击。
假设所有参与学习过程的UAVs是自私且理性的,他们的目的都是为了最大化自己的利益。如果没有足够的利益用于支付他们的学习过程,他们可能会上传低质量的局部模型,从而导致全局模型的准确率降低。 - 贡献记录篡改攻击。
由于UAVs的贡献记录存储在一个中央节点(如MEC节点),攻击者可以通过各种攻击(单点故障攻击或DDos攻击)篡改、删除、伪造和替换贡献记录。
SFAC方案
基于区块链的分布式联邦学习
由于UAVs网络存在不稳定和不可靠的无线信道和有安全漏洞的中央管理员,提出了基于区块链的联邦学习框架,旨在安全的进行局部模型共享和全局聚合过程。
在区块链中,每个块被分为head和body部分。head主要包括指向上一个块的哈希指针、一个工作量难题的解、块产生率和块生产者;body主要存储一系列有效的事务。
考虑三种类型的事务:
- 任务请求事务(trTx)
- 局部模型更新事务(lmTx)
- 聚合全局模型事务(gmTx)
trTx记录了包含所有相关实体、任务信息和初始模型参数的特定任务发布事件;
lmTx在全球训练轮中记录UAV更新的局部模型参数;
gmTx在全局训练轮中记录MEC节点的聚合全局模型参数。
考虑两种类型的区块:
- 普通块(orBlock)
- 本地模型更新块(lmBlock)
orBlock存储在一个共识时期内有效的trTx和gmTx事务;
lmBlock记录UAVs参与特定任务的lmTx事务。
详细的分布式联邦学习实现分为以下阶段:
- 实体注册和角色选择
- 任务发布和学习初始化
- UAVs的局部模型训练和扰动
- MEC节点的全局聚合
为了在区块链网络中有效达成共识,需要执行以下过程:
- 块产生
- 块传播
- 贡献记录和奖励
涉及区块链知识,不做详细阐述。
隐私保护本地模型更新
为了提高全局模型聚合的准确性,同时保证LDP的安全,为参与UAV开发了一种保护隐私的局部模型更新共享机制。要保护无人机的隐私,每个参与的UAV使用一个扰动函数F,并将模糊的局部模型参数上传到区块链。
基于强化学习的激励机制
在联邦学习过程中,UAVs和任务发布者可能无法或者成本模型和网络模型的准确参数。当精确的网络参数无法获得时,强化学习中的Q学习可以通过实验获得最优的QoLM和定价策略。
- 基于Q学习的定价策略制定
模型训练的高报酬会降低任务发布者的即时效用,但同时又会吸引更多的UAVs参与模型训练。因此,任务发布者的当前支付策略会影响模型训练精度和未来的收益。可以将定价策略建模为一个有限马尔科夫决策过程。 - 基于Q学习的QoLM策略制定
QoLM策略的制定过程可以表示为一个具有有限状态的MDP。由于每架UAV对任务发布者的私有参数几乎没有明确的了解,其最优的QoLM策略不能立即产生。UAVs采用Q学习通过试错找到最优QoLM策略。
仿真结果

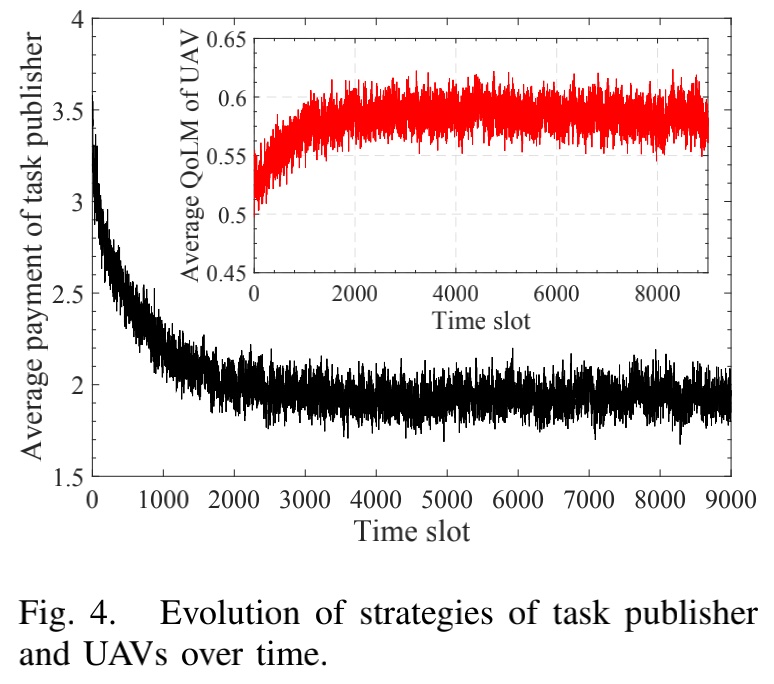
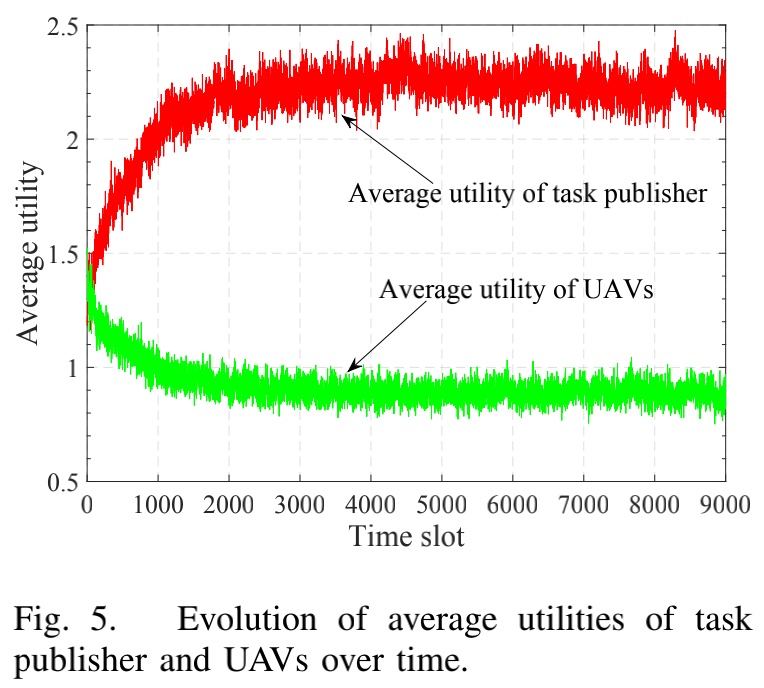
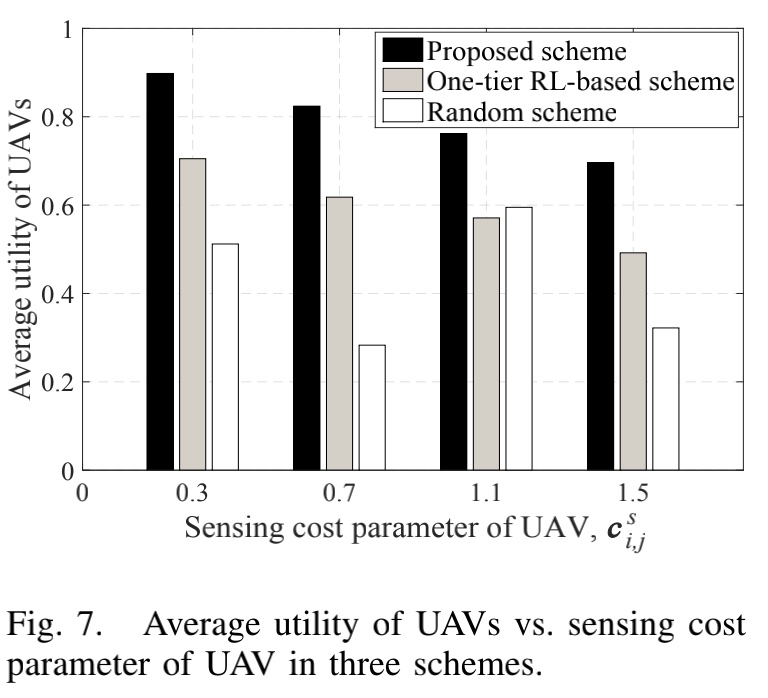
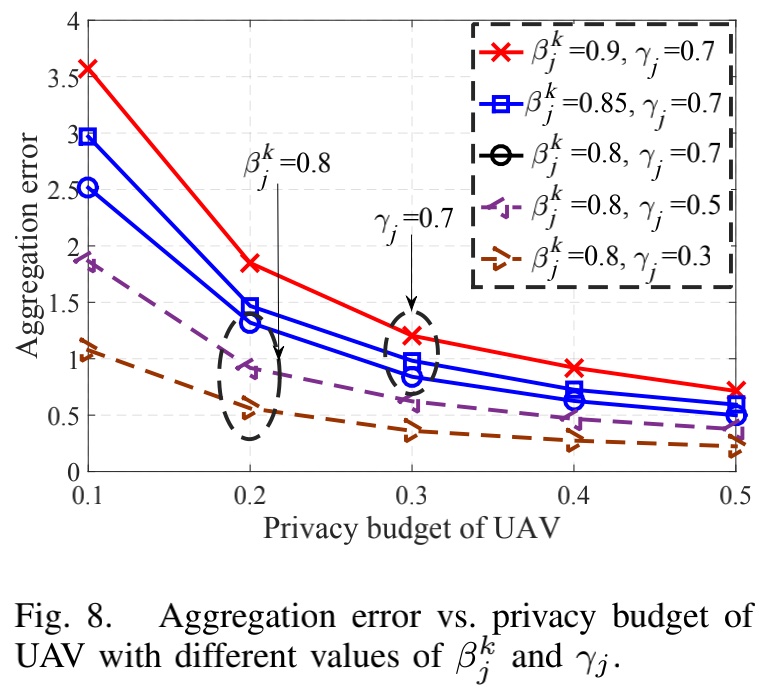
以上是关于「2020IEEE」Learning in the Air: Secure Federated Learning for UAV-Assisted Crowdsensing的主要内容,如果未能解决你的问题,请参考以下文章
Transfer learning & The art of using Pre-trained Models in Deep Learning
Learning-to-See-in-the-Dark跑通及实现方法
[译]深度学习的主要进展(译自:The Major Advancements in Deep Learning in 2016)
(转)Understanding Memory in Deep Learning Systems: The Neuroscience, Psychology and Technology Perspe
learning to see in the dark: 弱光场景下基于相机底层信号的图像处理
《Depth from Videos in the Wild:Unsupervised Monocular Depth Learning from Unknown Cameras》论文笔记