CV开山之作:《AlexNet》深度学习图像分类经典论文总结学习笔记(原文+总结)
Posted 耿鬼喝椰汁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CV开山之作:《AlexNet》深度学习图像分类经典论文总结学习笔记(原文+总结)相关的知识,希望对你有一定的参考价值。
本文将为大家总结经典CV神经网络的开山力作——AlexNet(ImageNet Classification with Deep Convolutional Neural Networks)
论文原文:https://dl.acm.org/doi/pdf/10.1145/3065386
目录
六.Qualitative Evaluations-定性评估
前言
为此文章为深度学习在计算机视觉领域的开山之作AlexNet,也是非常适合深度学习领域的小白观看的经典论文,本文为在学习论文期间的论文总结,也算是学习笔记,希望能帮助到大家,有不足地方还希望大家谅解,以后会给大家带来更高质量的学习论文笔记总结。
一.Abstract-摘要
摘要中主要提到这三件事: ①AlexNet的结构;
②AlexNet使用的非饱和(non-saturating)神经元(ReLU)和GPU的合理使用加快了训练;
③防止过拟合的方式:dropout。
二.Introduce-介绍
当前的复杂的图像识别任务需要更大的数据集,ImageNet图像的数量还不够,还得对图像进行处理后得到新图像来扩大数据集。CNN是用于图像的效果比较好的神经网络,且比起传统的feedforward neuralnetwork,它所需的参数更少,且效果不差。
AlexNet作者认为本文的贡献有:①提出一些技巧加快了训练;
②由于网络过大,提出了防止过拟合的一些技巧;
③AlexNet的网络层数是很好的,去掉任何一层都会使性能下降。
三.The Dataset-数据集
本文采用数据集:ImageNet。有很多图就对了。由于每张图的大小不一样,作者要统一裁剪成256 x256的图片 。
剪裁方法:先对原始图片进行缩放,使得图片较短的一边长度是256,另一个长边在这一步操作中也会根据长宽比进行调整,然后从图片中心对长边进行两侧的裁剪,最终得到256*256的尺寸大小的图片。
四.The Architecture-网络结构
网络结构主要包含以下几个关键点:
1.ReLU函数:作者将修正线性单元(ReLU,为非饱和非线性激活函数)用在了模型里,发现训练速度显著提高,原因在于原来所使用的传统函数为饱和非线性激活函数:sigmoid和tanh,这两个激活函数都是saturating(饱和非线性)的,会把两边的梯度压成0,而对于ReLU,它是non-saturating(非饱和非线性)的,只要input是正的,就不会发生这种情况。从而使用ReLU函数可以加快训练速度,克服梯度消失的问题。

上图为作者使用tanh和ReLU训练模型的结果,可以清晰看出在相同性能的情况下,ReLU只需5个epoch就能实现,而tanh则需要36个epoch。
2.用多个GPU进行训练:因为当时的GPU内存还不够大,限制了训练网络的最大大小,且实验使用的训练样本任务对于一个GPU来说太大了。
因此作者提出创新方法:把网络存在两个GPU里,有的层需要跨GPU计算,有的不需要。这里就不具体展开了。
使用多个GPU后带来的好处:① 错误率下降了:与在一个GPU上训练的网络相比,这种组合让本文的top-1和top-5错误率分别下降了1.7%和1.2%。
②训练时间更少:本文的两个GPU网络训练花费的时间比一个GPU的时间要少。
3.局部响应归一化(Local Response Normalization):对于sigmoid和tanh,为了防止input值过大或过小导致梯度变为0,就需要对input做normalization把input变为zero-centered;而对于ReLU则不需要,因为只要input是正的,梯度就不会为0。但文章还是提出了在ReLu层之前应用了一种新的normalization的方式:局部响应归一化(Local Response Normalization),定义为:
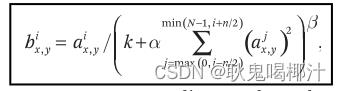
使用局部响应归一化后带来的好处:①错误率降低了,Top-1和Top-5错误率分别降低了1.4%和1.2%。
②在CIFAR-10数据集上验证了该方案的有效性:一个四层的CNN 在没有归一化的情况下测试错误率为13%,在加入了归一化后测试错误率为11%。
实验证明这样操作让准确度提高了。(现在基本没人用这个了)
4.重叠池化(Overlapping Pooling):传统的池化层的卷积核的步长应等于核的宽,而作者改进后选取了小于核的宽的步长。
使用重叠池化后带来的好处:①错误率降低了,与非重叠方案 比,该方案的top-1和top-5错误率分别降低了0.4%和0.3%。
②在训练过程中观察到,使用重叠池的模型发现过度拟合的差异变大。
(对传统的用Pooling的方法做了一定的改动,改动不大,但效果很好)

这里最初的输入图像大小是224x224x3是因为经过裁剪了。网络结构采用两个GPU,所以结构一分为2,整个结构分为八层,每一层都使用了ReLu函数,而局部响应归一化运用到了第一层和第二层,前面五层均为卷积层,注意第1,2,4,5层的卷积是只在各自的GPU上做的。后面三层为全连接层,最后为softmax。
五.Reducing Overfitting-减少过拟合
(接下来文章讲为了防止过拟合的几个技巧)
1.数据增强(Data Augmentation)其实就是把原有图像经过处理后来人为扩充数据集。比如:(1)裁剪图像后水平翻转(论文里是裁了大小为224x224 x 3的图)。在测试的时候预测图像属于的类的方式是:分别裁剪图像的四个角落与中心的大小为224 x 224 x3的图,并且水平翻转,从而得到10个inputs。然后将10个softmax的outputs的值求平均,得到最终分类结果。(2)改变图像RGB每个通道的灰度值。
2.Dropout: 普通的dropout。想法就是将dropout看作一种集成(ensemble)的算法,集成了多个模型训练,防止了过拟合。现在大家认为它就是一个正则项。
六.Qualitative Evaluations-定性评估

最主要是右边的图。作者把倒数第二层的向量拿出来,进行计算,从而得到相近的图片,这表明神经网络有效地提取了图像特征。
总结
1.本论文利用深度神经网络,来进行图片分类。而且取得了十分不错的效果。(用的数据集是ImageNet)
2.作者解决关键:(1)把网络存在两个GPU里,有的层需要跨GPU计算,有的不需要。(2)AlexNet使用的非饱和(non-saturating)神经元(ReLU)和GPU的合理使用加快了训练。用ReLU可以加快训练速度。(3)dropout可以有效减少过拟合。(4)整体架构:前面五层均为卷积层,注意第1,2,4,5层的卷积是只在各自的GPU上做的。后面三层为全连接层,最后为softmax。(4)数据集:ImageNet。(6).overlapping pooling(重叠池):一般来说两个Pooling是不会重叠的,但我现在要重叠。(对传统的用Pooling的方法做了一定的改动,改动不大,但效果很好)
3.论文贡献:推广了SGD算法,在此之后,SGD基本上在机器学习界成为了最主流的一个优化算法。
4.补充:训练使用模型:用SGD(随机梯度下降法)来训练模型,我们的权重用的是均值为0方差为0.01的高斯随机变量来初始化的,在第二层,第四层和第五层的卷积层把偏移量初始化成1,剩下的全部初始化为0,全连接层也都初始化为1。每一层用一个同样的学习率,我们的学习率是从0.01开始的,如果验证误差不往下降了,就将学习率手动降低十倍。
以上是关于CV开山之作:《AlexNet》深度学习图像分类经典论文总结学习笔记(原文+总结)的主要内容,如果未能解决你的问题,请参考以下文章