对大模型技术与可能的社会影响的思考
Posted sasasatori
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对大模型技术与可能的社会影响的思考相关的知识,希望对你有一定的参考价值。
1. 大模型的技术趋势
本节我们将分析“大模型现象”在语言模型以外的领域的进展情况,主要包括计算机视觉领域和多模态(语言+图像)领域。计算机视觉(Computer Vision,CV)领域和NLP一样,也是本轮深度学习科技热潮中被极大颠覆了的研究领域,2012年被提出的近代深度学习的开山之作AlexNet便是CV领域中的深度卷积神经网络(Convolutional Neural Network,CNN)。而语言+图像的多模态领域,也在随着CV和NLP两个相关领域的不断发展而进步,再次迎来了一轮研究热潮。
本节将首先论述目前CV领域从NLP领域吸取经验的代表性工作,并展示其大模型趋势,然后将讨论在多模态领域这一方向的进展情况。
在深度神经网络的发展初期,CV领域一直领先于NLP领域,围绕CNN结构的优化提出了大量创新方案,持续增加了网络深度与性能,其中的典型便是提出残差结构的ResNet[^13],这一结构至今仍在被广泛的使用(Transformer中亦采用了该结构)。但CV领域在基于CNN架构的模型扩大和大规模自监督预训练上的研究发展速度远不如采用了Transformer架构的NLP领域。而随着Transformer架构在NLP领域取得的巨大成功,研究者们开始尝试将Transformer迁移到CV领域中来,并冲击了CNN主宰的原有范式。
2020年10月,谷歌的研究团队提出了Vision Transformer[1](简称ViT),这一工作的主要思想是将传统的CV任务通过Transformer架构予以解决,而其中最主要的问题就是如何处理图像输入。Transformer原是应用于NLP的结构,语言本身是一维序列,而图像是二维矩阵(多通道),解决这种不适配就需要将图像也处理成序列的形式。ViT给出的答案是将图像切分成多个小块(patch)然后拉成序列即可,再通过postion embedding解决序列化过程中被破坏掉的位置信息。经过预训练后的ViT模型能够做到不输于传统CNN的表现。这一工作奠定了Transformer在CV领域应用的基础,并吸引了大量的跟进工作。
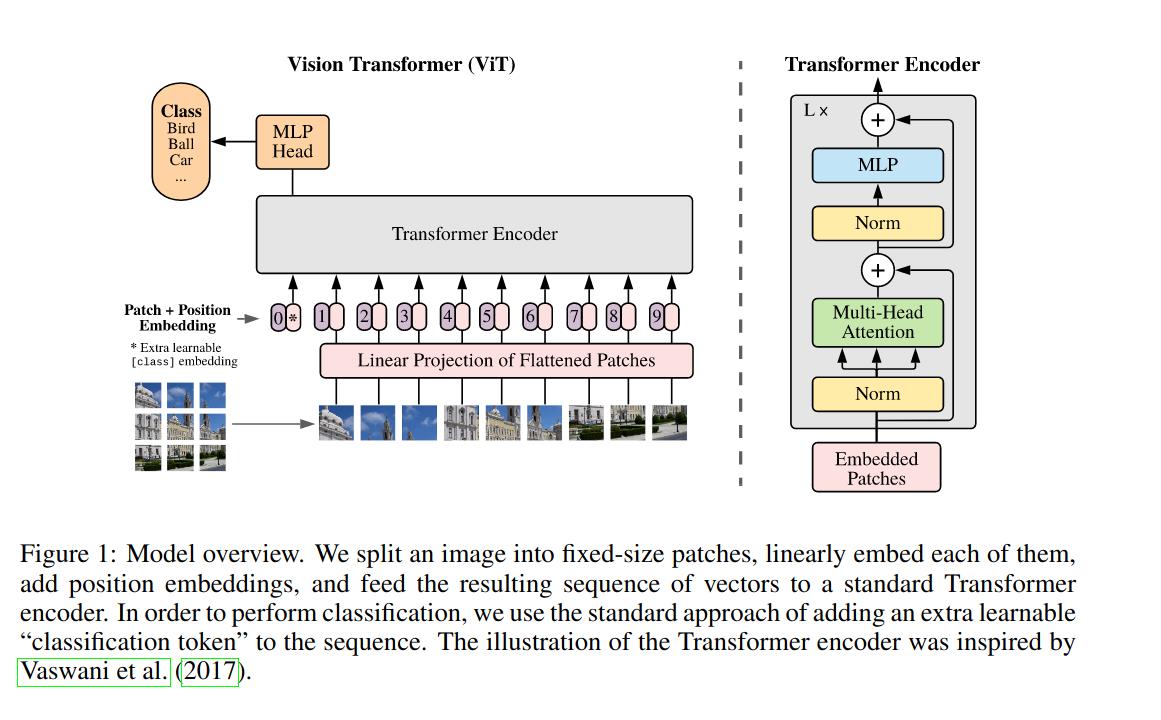
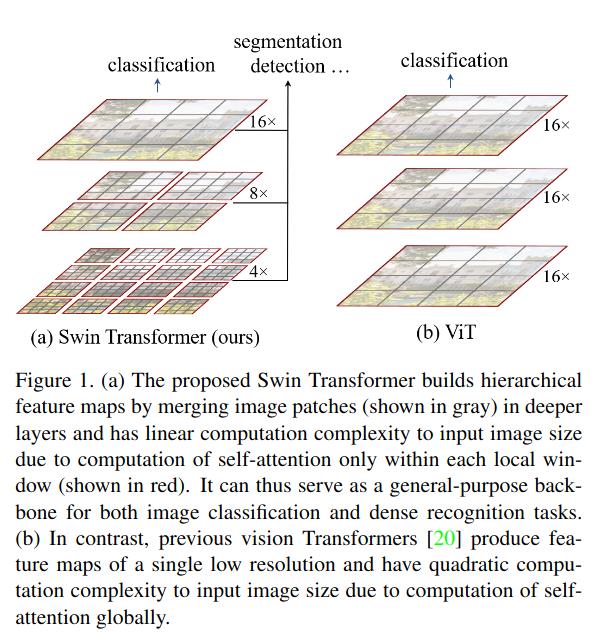
2021年5月,微软亚洲研究院的团队提出了用滑窗机制优化的ViT结构,称为Swin Transformer[2],该工作的主要思想是解决ViT结构在视觉任务上应用时,由于图片中像素的密度相较语句中词的密度要高很多,因此导致的计算量过大的问题。他们借鉴了CNN中的思想,构建了层次化特征图:将ViT中直接对整个图像划分patch的方法改进为了在图像中划分不重叠的窗口,然后在窗口中执行切割patch,再计算自注意力,并在浅层网络中密集划分窗口,而在深层网络则减少窗口划分,使得浅层网络具备更好的局部感知能力,而深层网络具备跟好的全局感知能力。这种处理方式大大减少了计算量,但牺牲了窗口之间关系的建模,不重合的 窗口之间缺乏信息交流影响了模型的表征能力,因此又通过滑动窗口的方式,使上一层相邻的不重合窗口之间在下一层引入连接,大大的增加了感受野。
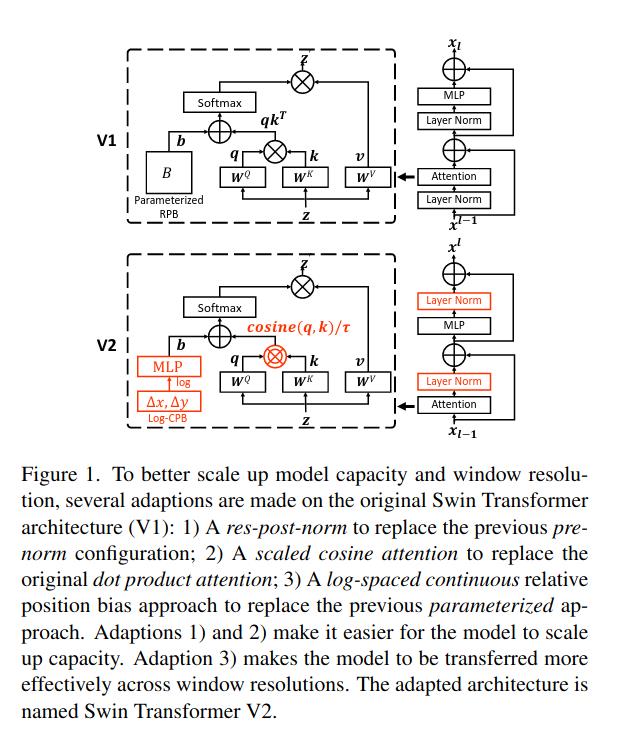
2021年11月,微软亚洲研究院的团队在Swin Transformer的基础上进行模型修改与规模扩大,进一步提出了Swin Transformer v2[3]。论文中明确指出了受到大语言模型的启发,因此提出了大视觉模型(Large Vision Model,LVM)的想法。针对视觉模型如何扩大规模的问题,论文主要提出了三个方法,1. 后归一化技术和缩放余弦attention方法,以提高大视觉模型的稳定性,2. 一种对数空间的连续位置偏置技术,可有效地将低分辨率预训练模型迁移到高分辨率上;3. 一种自监督预训练技术SimMIM[4]。该论文最终的成果是将Swin Transformer的参数规模增加到了30亿,并在部分任务上展现了明显的性能提升。
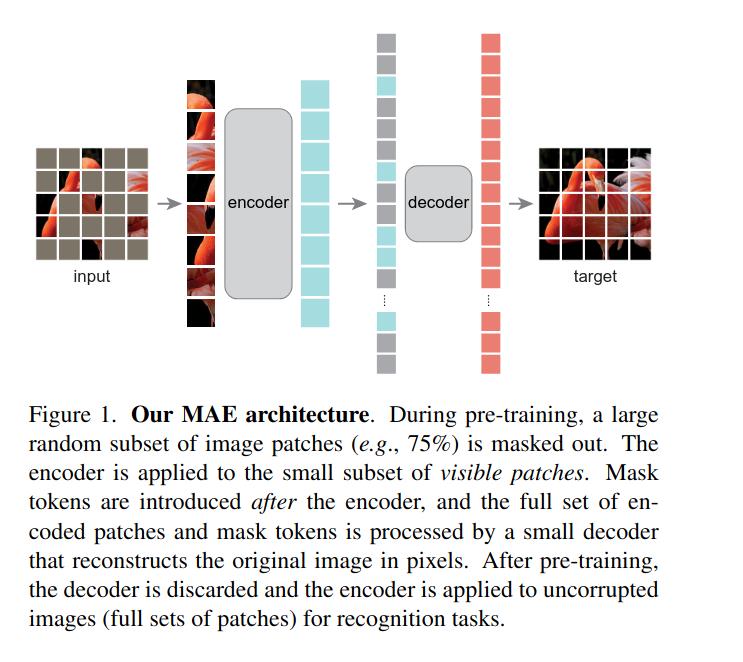
2021年11月,Facebook的研究团队提出了将NLP领域自监督学习中广泛应用的Mask机制应用到CV领域的自监督训练中来的掩码自编码器(Masked Auto Encoder,MAE)[5],这一论文的主要思想是建立可拓展的自监督视觉学习器,通过随机掩盖一些图像块,然后重建丢失的像素作为视觉模型的预训练任务,采用掩码的方式进行预训练降低了计算量要求,训练出的模型也表现出了优秀的迁移能力。
NLP领域相较于CV领域,在大模型的研究进展上是超前许多的,也可以看到上述介绍的工作的根本思想基本普遍来源于对NLP领域大模型技术发展的反思与借鉴。包括扩大模型规模,增加训练数据,采用自监督学习进行预训练等。大语言模型的成功给大视觉模型的研究带来了前所未有的动力,但对于视觉大模型的未来发展,仍存在着数据集不够优质和充足,自监督训练方法不够成熟,以及难以摆脱预训练+微调的范式,真正建立一个通用模型的问题[6]。
前两者的问题更多是数据集和训练方法上有待发展,这也是大模型破茧成蝶的必由之路。对于第三个,如何解决实现跨任务视觉模型的问题,一种想法是纯粹依靠视觉模型本身是无法实现的,参考GPT-2的发展,其实现多任务的思路是改变原有建模形式,将任务类型当作文本输入处理,但这建立在任务描述是可以通过语言实现这一前提下的,而对于图像来说则无法实现任务描述与图像输入的合并,因此一个明显的思路是采取多模态的方式,将多任务图像处理建模成:图像+语言任务描述的形式,例如分类任务可以转化为输入:一张狗的图像+任务描述“图片里面的是什么?”,目标检测任务可以转化为输入:一张杂乱的桌面照片+任务描述“帮我找出桌面上的杯子”,等等。
OpenAI在2021年2月发表的CLIP(即Contrastive Language-Image Pre-training)[7]便体现了这一思想。CLIP在架构上采用神经网络视觉模型(尝试了ResNet和ViT,ViT的表现更好)作为编码器和神经网络语言模型(毫无疑问的Transformer)作为语言编码器,并采用对比学习方法进行预训练,即利用数据集的构建图像文本对,只有匹配的一对图像——文本构成正样本,其他的全部构成负样本。在进行分类任务时,神经网络视觉模型抽取输入图像的特征形成特征向量,神经网络语言模型则把“A photo of a object”,其中object填充可供预测的类型,这句话抽取成特征向量,最后再计算视觉特征向量和多个语言特征向量的余弦相似度,以最大的一项作为分类结果。
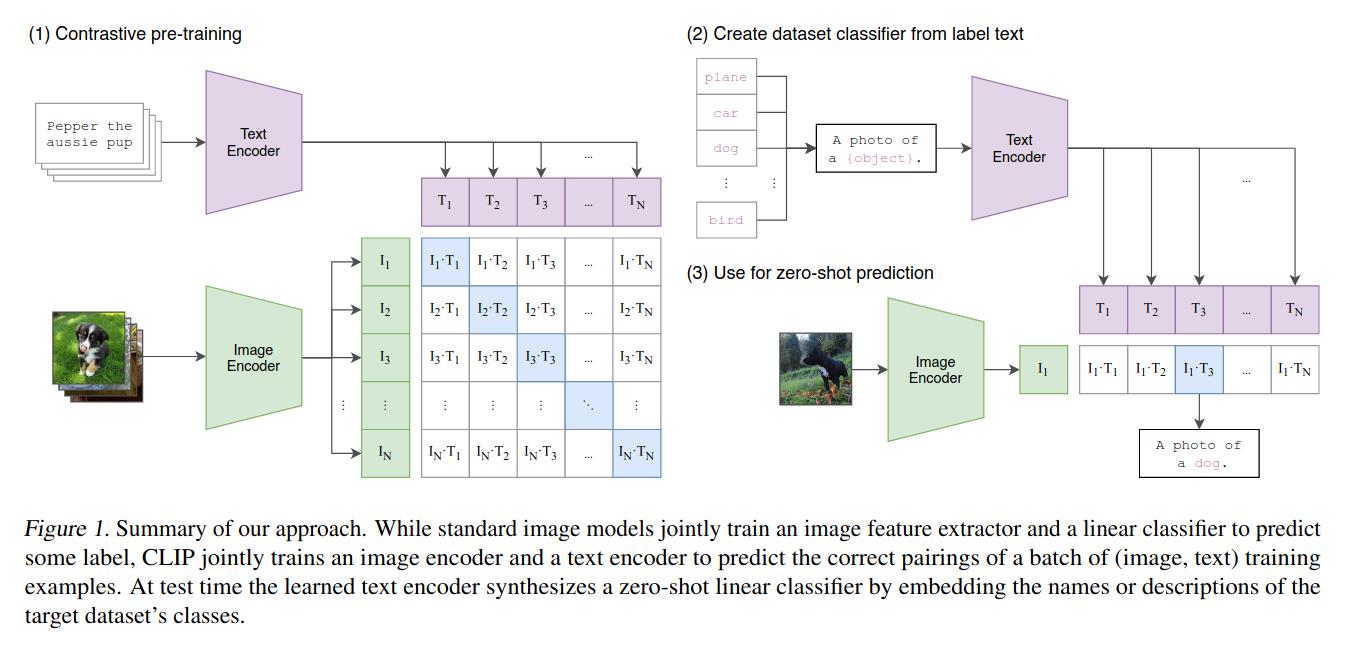
CLIP在实验中展示了极其强劲的迁移能力,在众多不同的数据集和视觉zero-shot任务上的都表现优异。更重要的事情是其对视觉模型原有范式的重大改造,原本的视觉模型高度依赖于训练集中的数据标签,如CIFAR-100中有100类物体的标签,那么在其上训练出的模型只能够识别这100类物体,而一旦用于识别超出这一范围的物体时,模型就会直接失效。但对于CLIP来说,只需要在文本标签中增加这一类型,便可以在分类时识别将其识别,这直接极大的增强了模型的泛化能力,并充分释放了大模型的潜能——使其不再受到训练集中有限标签的限制。不仅如此,CLIP还证明了通过自然语言指导视觉模型工作,使得视觉模型能够有效的执行任务是一条完全可行的技术路径。因此CLIP一经推出,便大大改变了CV领域的原有思想,并引发了大量的后续工作。
本节我们介绍了CV领域受到NLP领域大规模自监督预训练大模型影响后的一系列研究,并讨论了其在通往大模型路径上的主要困难,尤其是如何实现通用多任务模型这一问题,并以OpenAI在多模态领域的重要工作收尾,作为一个可能的解决方案。
在下一节,我们从本节在多模态模型上获得的启发开始谈起,讨论人类历史上对于通用人工智能的追逐,我们是否已经到了距离通用人工智能最近的时候,通过现有的技术路径可能会实现怎样的通用人工智能,以及到来的路上可能还有哪些障碍。
2. 参考资料
《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》https://doi.org/10.48550/arXiv.2010.11929 ↩︎
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》https://doi.org/10.48550/arXiv.2103.14030 ↩︎
《Swin Transformer V2: Scaling Up Capacity and Resolution》https://doi.org/10.48550/arXiv.2111.09883 ↩︎
《SimMIM: A Simple Framework for Masked Image Modeling》https://doi.org/10.48550/arXiv.2111.09886 ↩︎
《Masked Autoencoders Are Scalable Vision Learners》https://doi.org/10.48550/arXiv.2111.06377 ↩︎
《Swin Transformer迎来30亿参数的v2.0,我们应该拥抱视觉大模型吗?》https://www.msra.cn/zh-cn/news/features/swin-transformer-v2 ↩︎
《Learning Transferable Visual Models From Natural Language Supervision》https://doi.org/10.48550/arXiv.2103.00020 ↩︎
以上是关于对大模型技术与可能的社会影响的思考的主要内容,如果未能解决你的问题,请参考以下文章
1.试述大数据对思维方式的重要影响。 2.详细阐述大数据云计算物联网之间的区别与联系。 3.简述你对大数据应用与发展的看法,以及你在这次大数据浪潮中想扮演什么角色。