深度学习-AlexNet(第一个深度卷积网络)
Posted 吾仄lo咚锵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习-AlexNet(第一个深度卷积网络)相关的知识,希望对你有一定的参考价值。
文章目录
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
简介
AlexNet是第一个深度卷积网络模型,赢得了2012年ImageNet图像分类竞赛的冠军,自98年的LeNet后再次将深度学习研究引热,创造性的提出了很多方法且影响至今,如使用GPU进行训练,使用ReLU 作为非线性激活函数,使用 Dropout 防止过拟合,使用数据增强来提高模型准确率等。
Krizhevsky A, Sutskever I, Hinton G E, 2012. ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems 25. 1106-1114.
AlexNet模型结构如下:
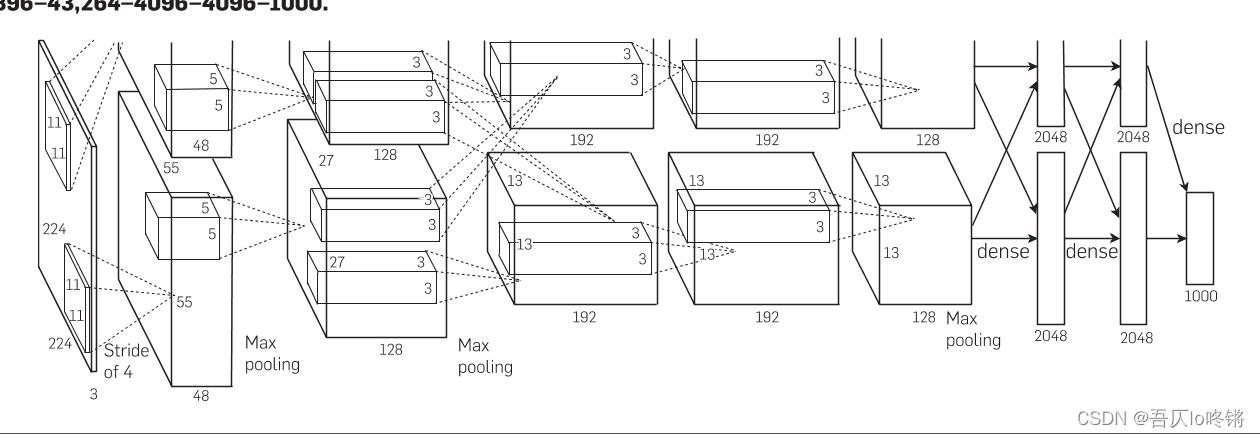
包括5个卷积层、3个全连接层。分别部署在2个GPU上,这里写在一起即可。
-
卷积层1
输入RGB三通道,即3×224×224的图像;
使用96个大小为11×11的卷积核,步长4,填充2;
输出96×55×55特征;
ReLu激活;
最大池化,核大小3×3,步长2(重叠池化);
输出96×27×27特征; -
卷积层2
输入特征图大小96×27×27;
使用256个大小为5×5的卷积核,步长1,填充2;
输出256×27×27特征;
ReLu激活;
最大池化,核大小3×3,步长2(重叠池化);
输出256×13×13特征; -
卷积层3
输入特征图大小256×13×13;
使用384个大小为3×3的卷积核,步长1,填充1;
输出384×13×13特征;
ReLu激活; -
卷积层4
输入特征图大小384×13×13;
使用384个大小为3×3的卷积核,步长1,填充1;
输出384×13×13特征;
ReLu激活; -
卷积层5
输入特征图大小384×13×13;
使用256个大小为3×3的卷积核,步长1,填充1;
输出256×13×13特征;
ReLu激活;
最大池化,核大小3×3,步长2(重叠池化);
输出256×6×6特征; -
全连接层1
Droupout随机置0;
输入25666,输出4096;
ReLu激活; -
全连接层2
Droupout随机置0;
输入4096,输出4096;
ReLu激活; -
全连接层1
输入4096,输出分类数;
数据集
由于ImageNet数据集太大且不提供测试集的标签,这里使用torchversion封装的OxfordIIITPet数据集,包含猫狗共37类,每类约200张图片,共800M左右。
官网https://www.robots.ox.ac.uk/~vgg/data/pets/

由于该数据集尺寸不同,同一缩放为256×256大小,然后采用10剪切,裁出10张224×224大小。
import torch
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torchvision
pet_train = torchvision.datasets.OxfordIIITPet(root='./datasets/', download=True,
transform=transforms.Resize((256, 256)))
pet_test = torchvision.datasets.OxfordIIITPet(root='./datasets/', split='test', download=True,
transform=transforms.Resize((256, 256)))
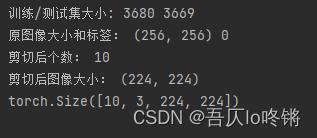
print('训练/测试集大小:', len(pet_train), len(pet_test))
img, label = pet_train[0]
print('原图像大小和标签:', img.size, label)
tenCrop = transforms.TenCrop(224, vertical_flip=False) # 上下左右中心,然后镜像共10张
img = tenCrop(img)
print('剪切后个数:', len(img))
print('剪切后图像大小:', img[0].size)
toTensor = transforms.ToTensor() # 转为10个tensor
tensor_list = []
for i in range(len(img)):
tensor_list.append(toTensor(img[i]))
img_tensor = torch.stack(tensor_list)
print(img_tensor.shape)
writer = SummaryWriter(log_dir='runs/pet') # 可视化
writer.add_images(tag='train', img_tensor=img_tensor)
writer.close()
模型搭建
可以使用直接调用torchvision.models.AlexNet创建一个AlexNet模型。
以下是自定义模型,调整了一些细节,更贴近原文:
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000, dropout: float = 0.5) -> None:
super().__init__()
self.features = nn.Sequential( # (-1,3,224,224)
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True), # (-1,96,55,55)
nn.MaxPool2d(kernel_size=3, stride=2), # (-1,96,27,27)
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2),
nn.ReLU(inplace=True), # (-1,256,27,27)
nn.MaxPool2d(kernel_size=3, stride=2), # (-1,256,13,13)
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(inplace=True), # (-1,384,13,13)
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(inplace=True), # (-1,384,13,13)
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(inplace=True), # (-1,256,13,13)
nn.MaxPool2d(kernel_size=3, stride=2), # (-1,256,6,6)
)
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
模型训练
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000, dropout: float = 0.5) -> None:
super().__init__()
self.features = nn.Sequential( # (-1,3,224,224)
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True), # (-1,96,55,55)
nn.MaxPool2d(kernel_size=3, stride=2), # (-1,96,27,27)
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2),
nn.ReLU(inplace=True), # (-1,256,27,27)
nn.MaxPool2d(kernel_size=3, stride=2), # (-1,256,13,13)
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(inplace=True), # (-1,384,13,13)
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(inplace=True), # (-1,384,13,13)
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(inplace=True), # (-1,256,13,13)
nn.MaxPool2d(kernel_size=3, stride=2), # (-1,256,6,6)
)
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 创建模型
alexNet = AlexNet()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
alexNet = alexNet.to(device) # 若支持GPU加速
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.Adam(alexNet.parameters(), lr=learning_rate)
total_train_step = 0 # 总训练次数
total_test_step = 0 # 总测试次数
epoch = 10 # 训练轮数
writer = SummaryWriter(log_dir='runs/AlexNet') # 可视化
# 数据
pet_train = torchvision.datasets.OxfordIIITPet(root='./datasets/', download=True,
transform=transforms.Resize((256, 256)))
tenCrop = transforms.TenCrop(224, vertical_flip=False) # 上下左右中心,然后镜像共10张
toTensor = transforms.ToTensor() # 转为tensor
# 训练模型
for i in range(epoch):
print("-----第轮训练开始-----".format(i + 1))
loss_sum = 0
alexNet.train() # 训练模式
for img, label in pet_train:
img = tenCrop(img) # 10剪切
img_list, label_list = [], [] # 合为一个tensor
for j in range(len(img)):
img_list.append(toTensor(img[j]))
label_list.append(label)
imgs = torch.stack(img_list)
labels = torch.tensor(label_list)
imgs = imgs.to(device) # 若GPU加速
labels = labels.to(device)
outputs = alexNet(imgs) # 预测
loss = loss_fn(outputs, labels) # 计算损失
optimizer.zero_grad() # 清空之前梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_train_step += 1 # 更新步数
loss_sum += loss.item()
writer.add_scalar("train_loss", loss_sum, total_train_step)
torch.save(alexNet.state_dict(), "alexnet_.pkl".format(i)) # 保存模型
# alexNet.load_state_dict(torch.load("alexnet_.pkl".format(i))) # 加载模型
writer.close()

模型测试
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000, dropout: float = 0.5) -> None:
super().__init__()
self.features = nn.Sequential( # (-1,3,224,224)
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True), # (-1,96,55,55)
nn.MaxPool2d(kernel_size=3, stride=2), # (-1,96,27,27)
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2),
nn.ReLU(inplace=True), # (-1,256,27,27)
nn.MaxPool2d(kernel_size=3, stride=2), # (-1,256,13,13)
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(inplace=True), # (-1,384,13,13)
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(inplace=True), # (-1,384,13,13)
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(inplace=True), # (-1,256,13,13)
nn.MaxPool2d(kernel_size=3, stride=2), # (-1,256,6,6)
)
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
epoch = 10 # 轮数
writer = SummaryWriter(log_dir='runs/AlexNet') # 可视化
# 数据
pet_test = torchvision.datasets.OxfordIIITPet(root='./datasets/', split='test', download=True,
transform=transforms.Resize((256, 256)))
tenCrop = transforms.TenCrop(224, vertical_flip=False) # 上下左右中心,然后镜像共10张
toTensor = transforms.ToTensor() # 转为tensor
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 训练模型
for i in range(epoch):
print("-----第个模型测试开始-----".format(i + 1))
total_test_loss = 0 # 当前轮次模型测试所得损失
total_accuracy = 0 # 当前轮次精确率
alexNet = AlexNet()
alexNet.load_state_dict(torch.load("alexnet_.pkl".format(i))) # 加载模型
for img, label in pet_test:
img = tenCrop(img) # 10剪切
img_list, label_list = [], [] # 合为一个tensor
for j in range(len(img)):
img_list.append(toTensor(img[j]))
label_list.append(label)
imgs = torch.stack(img_list)
labels = torch.tensor(label_list)
imgs = imgs.to(device) # 若GPU加速
labels = labels.to(device)
outputs = alexNet(imgs) # 预测
loss = loss_fn(outputs, labels)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == labels)以上是关于深度学习-AlexNet(第一个深度卷积网络)的主要内容,如果未能解决你的问题,请参考以下文章
深度学习100例-卷积神经网络(AlexNet)手把手教学 | 第11天
卷积神经网络(AlexNet)手把手教学-深度学习100例 | 第11天