深度学习 Transformer架构解析
Posted 落花雨时
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习 Transformer架构解析相关的知识,希望对你有一定的参考价值。
文章目录
一、Transformer背景介绍
1.1 Transformer的诞生
2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!
论文地址: https://arxiv.org/pdf/1810.04805.pdf
而在BERT中发挥重要作用的结构就是Transformer, 之后又相继出现XLNET,roBERT等模型击败了BERT,但是他们的核心没有变,仍然是:Transformer.
1.2 Transformer的优势
相比之前占领市场的LSTM和GRU模型,Transformer有两个显著的优势:
- Transformer能够利用分布式GPU进行并行训练,提升模型训练效率.
- 在分析预测更长的文本时, 捕捉间隔较长的语义关联效果更好.
下面是一张在测评比较图:
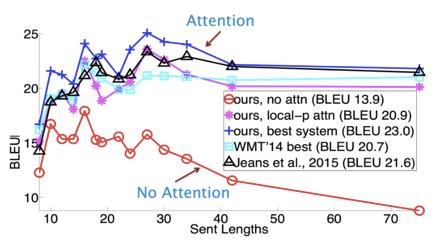
1.3 Transformer的市场
在著名的SOTA机器翻译榜单上, 几乎所有排名靠前的模型都使用Transformer,
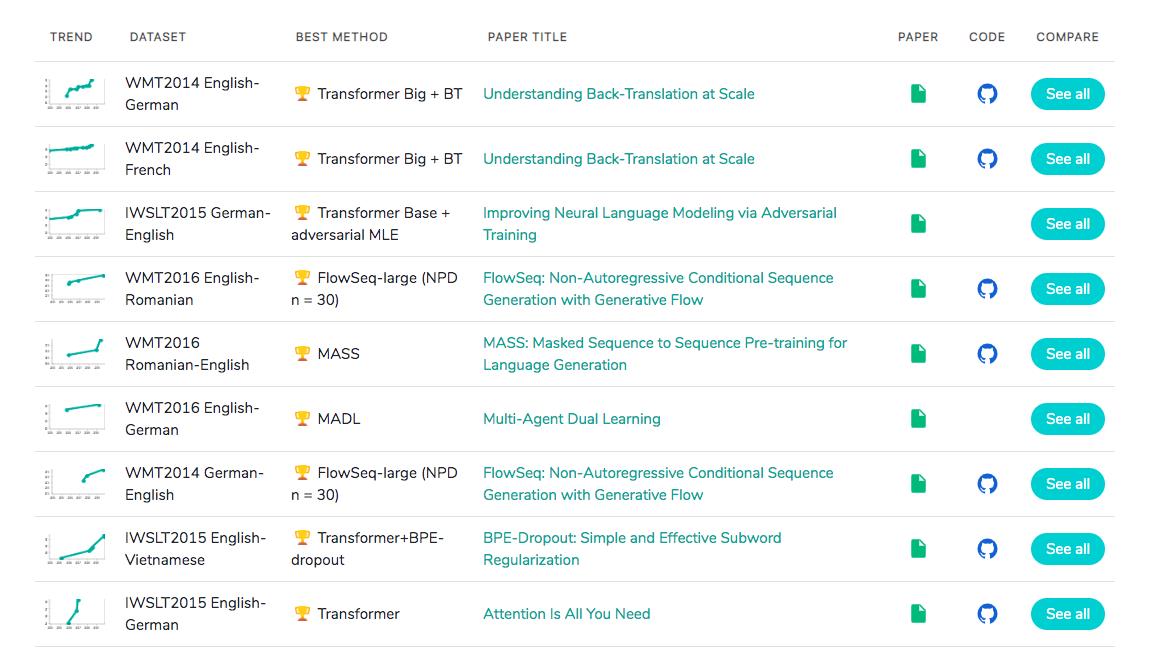
其基本上可以看作是工业界的风向标, 市场空间自然不必多说!
二、Transformer架构解析
2.1 认识Transformer架构
2.1.1 Transformer模型的作用
基于seq2seq架构的transformer模型可以完成NLP领域研究的典型任务, 如机器翻译, 文本生成等. 同时又可以构建预训练语言模型,用于不同任务的迁移学习.
声明:
在接下来的架构分析中, 我们将假设使用Transformer模型架构处理从一种语言文本到另一种语言文本的翻译工作, 因此很多命名方式遵循NLP中的规则. 比如: Embeddding层将称作文本嵌入层, Embedding层产生的张量称为词嵌入张量, 它的最后一维将称作词向量等.
2.1.2 Transformer总体架构图
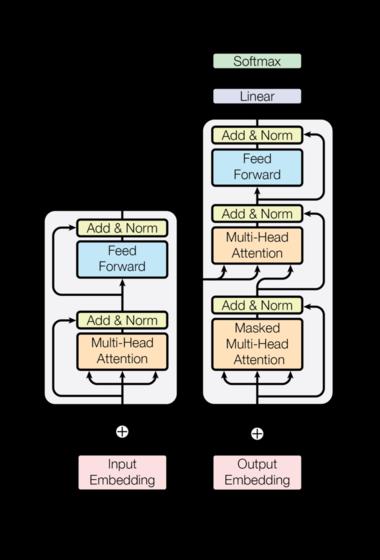
Transformer总体架构可分为四个部分:
- 输入部分
- 输出部分
- 编码器部分
- 解码器部分
输入部分包含:
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
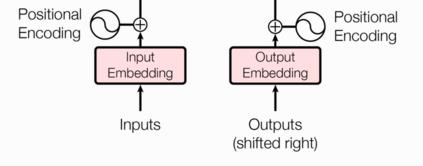
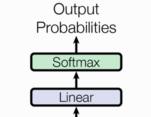
输出部分包含:
- 线性层
- softmax层
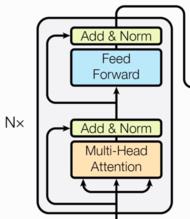
编码器部分:
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
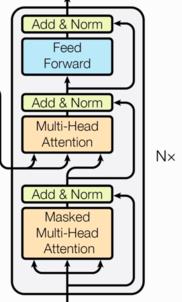
解码器部分:
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
2.2 输入部分实现
输入部分包含:
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
2.2.1 文本嵌入层的作用
无论是源文本嵌入还是目标文本嵌入,都是为了将文本中词汇的数字表示转变为向量表示, 希望在这样的高维空间捕捉词汇间的关系.
文本嵌入层的代码分析:
# 导入必备的工具包
import torch
# 预定义的网络层torch.nn, 工具开发者已经帮助我们开发好的一些常用层,
# 比如,卷积层, lstm层, embedding层等, 不需要我们再重新造轮子.
import torch.nn as nn
# 数学计算工具包
import math
# torch中变量封装函数Variable.
from torch.autograd import Variable
# 定义Embeddings类来实现文本嵌入层,这里s说明代表两个一模一样的嵌入层, 他们共享参数.
# 该类继承nn.Module, 这样就有标准层的一些功能, 这里我们也可以理解为一种模式, 我们自己实现的所有层都会这样去写.
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
"""类的初始化函数, 有两个参数, d_model: 指词嵌入的维度, vocab: 指词表的大小."""
# 接着就是使用super的方式指明继承nn.Module的初始化函数, 我们自己实现的所有层都会这样去写.
super(Embeddings, self).__init__()
# 之后就是调用nn中的预定义层Embedding, 获得一个词嵌入对象self.lut
self.lut = nn.Embedding(vocab, d_model)
# 最后就是将d_model传入类中
self.d_model = d_model
def forward(self, x):
"""可以将其理解为该层的前向传播逻辑,所有层中都会有此函数
当传给该类的实例化对象参数时, 自动调用该类函数
参数x: 因为Embedding层是首层, 所以代表输入给模型的文本通过词汇映射后的张量"""
# 将x传给self.lut并与根号下self.d_model相乘作为结果返回
return self.lut(x) * math.sqrt(self.d_model)
- nn.Embedding演示:
>>> embedding = nn.Embedding(10, 3)
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])
>>> embedding = nn.Embedding(10, 3, padding_idx=0)
>>> input = torch.LongTensor([[0,2,0,5]])
>>> embedding(input)
tensor([[[ 0.0000, 0.0000, 0.0000],
[ 0.1535, -2.0309, 0.9315],
[ 0.0000, 0.0000, 0.0000],
[-0.1655, 0.9897, 0.0635]]])
- 实例化参数:
# 词嵌入维度是512维
d_model = 512
# 词表大小是1000
vocab = 1000
- 输入参数:
# 输入x是一个使用Variable封装的长整型张量, 形状是2 x 4
x = Variable(torch.LongTensor([[100,2,421,508],[491,998,1,221]]))
- 调用:
emb = Embeddings(d_model, vocab)
embr = emb(x)
print("embr:", embr)
- 输出效果:
embr: Variable containing:
( 0 ,.,.) =
35.9321 3.2582 -17.7301 ... 3.4109 13.8832 39.0272
8.5410 -3.5790 -12.0460 ... 40.1880 36.6009 34.7141
-17.0650 -1.8705 -20.1807 ... -12.5556 -34.0739 35.6536
20.6105 4.4314 14.9912 ... -0.1342 -9.9270 28.6771
( 1 ,.,.) =
27.7016 16.7183 46.6900 ... 17.9840 17.2525 -3.9709
3.0645 -5.5105 10.8802 ... -13.0069 30.8834 -38.3209
33.1378 -32.1435 -3.9369 ... 15.6094 -29.7063 40.1361
-31.5056 3.3648 1.4726 ... 2.8047 -9.6514 -23.4909
[torch.FloatTensor of size 2x4x512]
2.2.2 位置编码器的作用
因为在Transformer的编码器结构中, 并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中, 以弥补位置信息的缺失.
位置编码器的代码分析:
# 定义位置编码器类, 我们同样把它看做一个层, 因此会继承nn.Module
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
"""位置编码器类的初始化函数, 共有三个参数, 分别是d_model: 词嵌入维度,
dropout: 置0比率, max_len: 每个句子的最大长度"""
super(PositionalEncoding, self).__init__()
# 实例化nn中预定义的Dropout层, 并将dropout传入其中, 获得对象self.dropout
self.dropout = nn.Dropout(p=dropout)
# 初始化一个位置编码矩阵, 它是一个0阵,矩阵的大小是max_len x d_model.
pe = torch.zeros(max_len, d_model)
# 初始化一个绝对位置矩阵, 在我们这里,词汇的绝对位置就是用它的索引去表示.
# 所以我们首先使用arange方法获得一个连续自然数向量,然后再使用unsqueeze方法拓展向量维度使其成为矩阵,
# 又因为参数传的是1,代表矩阵拓展的位置,会使向量变成一个max_len x 1 的矩阵,
position = torch.arange(0, max_len).unsqueeze(1)
# 绝对位置矩阵初始化之后,接下来就是考虑如何将这些位置信息加入到位置编码矩阵中,
# 最简单思路就是先将max_len x 1的绝对位置矩阵, 变换成max_len x d_model形状,然后覆盖原来的初始位置编码矩阵即可,
# 要做这种矩阵变换,就需要一个1xd_model形状的变换矩阵div_term,我们对这个变换矩阵的要求除了形状外,
# 还希望它能够将自然数的绝对位置编码缩放成足够小的数字,有助于在之后的梯度下降过程中更快的收敛. 这样我们就可以开始初始化这个变换矩阵了.
# 首先使用arange获得一个自然数矩阵, 但是细心的同学们会发现, 我们这里并没有按照预计的一样初始化一个1xd_model的矩阵,
# 而是有了一个跳跃,只初始化了一半即1xd_model/2 的矩阵。 为什么是一半呢,其实这里并不是真正意义上的初始化了一半的矩阵,
# 我们可以把它看作是初始化了两次,而每次初始化的变换矩阵会做不同的处理,第一次初始化的变换矩阵分布在正弦波上, 第二次初始化的变换矩阵分布在余弦波上,
# 并把这两个矩阵分别填充在位置编码矩阵的偶数和奇数位置上,组成最终的位置编码矩阵.
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 这样我们就得到了位置编码矩阵pe, pe现在还只是一个二维矩阵,要想和embedding的输出(一个三维张量)相加,
# 就必须拓展一个维度,所以这里使用unsqueeze拓展维度.
pe = pe.unsqueeze(0)
# 最后把pe位置编码矩阵注册成模型的buffer,什么是buffer呢,
# 我们把它认为是对模型效果有帮助的,但是却不是模型结构中超参数或者参数,不需要随着优化步骤进行更新的增益对象.
# 注册之后我们就可以在模型保存后重加载时和模型结构与参数一同被加载.
self.register_buffer('pe', pe)
def forward(self, x):
"""forward函数的参数是x, 表示文本序列的词嵌入表示"""
# 在相加之前我们对pe做一些适配工作, 将这个三维张量的第二维也就是句子最大长度的那一维将切片到与输入的x的第二维相同即x.size(1),
# 因为我们默认max_len为5000一般来讲实在太大了,很难有一条句子包含5000个词汇,所以要进行与输入张量的适配.
# 最后使用Variable进行封装,使其与x的样式相同,但是它是不需要进行梯度求解的,因此把requires_grad设置成false.
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
# 最后使用self.dropout对象进行'丢弃'操作, 并返回结果.
return self.dropout(x)
- nn.Dropout演示:
>>> m = nn.Dropout(p=0.2)
>>> input = torch.randn(4, 5)
>>> output = m(input)
>>> output
Variable containing:
0.0000 -0.5856 -1.4094 0.0000 -1.0290
2.0591 -1.3400 -1.7247 -0.9885 0.1286
0.5099 1.3715 0.0000 2.2079 -0.5497
-0.0000 -0.7839 -1.2434 -0.1222 1.2815
[torch.FloatTensor of size 4x5]
- torch.unsqueeze演示:
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])
- 实例化参数:
# 词嵌入维度是512维
d_model = 512
# 置0比率为0.1
dropout = 0.1
# 句子最大长度
max_len=60
- 输入参数:
# 输入x是Embedding层的输出的张量, 形状是2 x 4 x 512
x = embr
Variable containing:
( 0 ,.,.) =
35.9321 3.2582 -17.7301 ... 3.4109 13.8832 39.0272
8.5410 -3.5790 -12.0460 ... 40.1880 36.6009 34.7141
-17.0650 -1.8705 -20.1807 ... -12.5556 -34.0739 35.6536
20.6105 4.4314 14.9912 ... -0.1342 -9.9270 28.6771
( 1 ,.,.) =
27.7016 16.7183 46.6900 ... 17.9840 17.2525 -3.9709
3.0645 -5.5105 10.8802 ... -13.0069 30.8834 -38.3209
33.1378 -32.1435 -3.9369 ... 15.6094 -29.7063 40.1361
-31.5056 3.3648 1.4726 ... 2.8047 -9.6514 -23.4909
[torch.FloatTensor of size 2x4x512]
- 调用:
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)
print("pe_result:", pe_result)
- 输出效果:
pe_result: Variable containing:
( 0 ,.,.) =
-19.7050 0.0000 0.0000 ... -11.7557 -0.0000 23.4553
-1.4668 -62.2510 -2.4012 ... 66.5860 -24.4578 -37.7469
9.8642 -41.6497 -11.4968 ... -21.1293 -42.0945 50.7943
0.0000 34.1785 -33.0712 ... 48.5520 3.2540 54.1348
( 1 ,.,.) =
7.7598 -21.0359 15.0595 ... -35.6061 -0.0000 4.1772
-38.7230 8.6578 34.2935 ... -43.3556 26.6052 4.3084
24.6962 37.3626 -26.9271 ... 49.8989 0.0000 44.9158
-28.8435 -48.5963 -0.9892 ... -52.5447 -4.1475 -3.0450
[torch.FloatTensor of size 2x4x512]
- 绘制词汇向量中特征的分布曲线:
import matplotlib.pyplot as plt
# 创建一张15 x 5大小的画布
plt.figure(figsize=(15, 5))
# 实例化PositionalEncoding类得到pe对象, 输入参数是20和0
pe = PositionalEncoding(20, 0)
# 然后向pe传入被Variable封装的tensor, 这样pe会直接执行forward函数,
# 且这个tensor里的数值都是0, 被处理后相当于位置编码张量
y = pe(Variable(torch.zeros(1, 100, 20)))
# 然后定义画布的横纵坐标, 横坐标到100的长度, 纵坐标是某一个词汇中的某维特征在不同长度下对应的值
# 因为总共有20维之多, 我们这里只查看4,5,6,7维的值.
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
# 在画布上填写维度提示信息
plt.legend(["dim %d"%p for p in [4,5,6,7]])
输出效果:
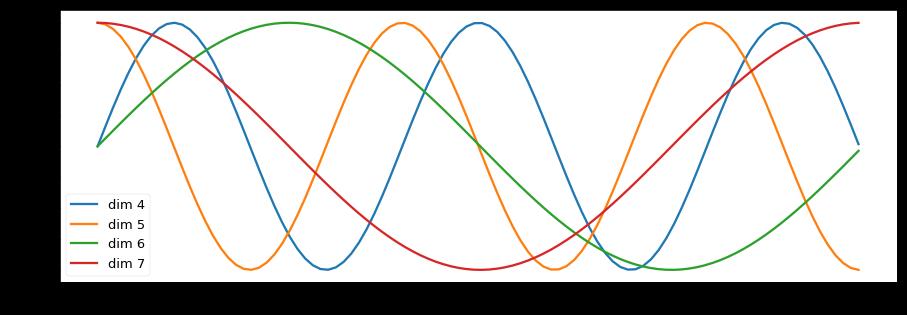
效果分析:
- 每条颜色的曲线代表某一个词汇中的特征在不同位置的含义.
- 保证同一词汇随着所在位置不同它对应位置嵌入向量会发生变化.
- 正弦波和余弦波的值域范围都是1到-1这又很好的控制了嵌入数值的大小, 有助于梯度的快速计算.
2.3 编码器部分实现
编码器部分:
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
2.3.1 掩码张量
- 什么是掩码张量:
- 掩代表遮掩,码就是我们张量中的数值,它的尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或者不被遮掩,至于是0位置被遮掩还是1位置被遮掩可以自定义,因此它的作用就是让另外一个张量中的一些数值被遮掩,也可以说被替换, 它的表现形式是一个张量.
- 掩码张量的作用:
- 在transformer中, 掩码张量的主要作用在应用attention(将在下一小节讲解)时,有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的,因此,未来的信息可能被提前利用. 所以,我们会进行遮掩. 关于解码器的有关知识将在后面的章节中讲解.
生成掩码张量的代码分析:
def subsequent_mask(size):
"""生成向后遮掩的掩码张量, 参数size是掩码张量最后两个维度的大小, 它的最后两维形成一个方阵"""
# 在函数中, 首先定义掩码张量的形状
attn_shape = (1, size, size)
# 然后使用np.ones方法向这个形状中添加1元素,形成上三角阵, 最后为了节约空间,
# 再使其中的数据类型变为无符号8位整形unit8
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
# 最后将numpy类型转化为torch中的tensor, 内部做一个1 - 的操作,
# 在这个其实是做了一个三角阵的反转, subsequent_mask中的每个元素都会被1减,
# 如果是0, subsequent_mask中的该位置由0变成1
# 如果是1, subsequent_mask中的该位置由1变成0
return torch.from_numpy(1 - subsequent_mask)
- np.triu演示:
>>> np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]], k=-1)
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 0, 8, 9],
[ 0, 0, 12]])
>>> np.triu([[1,2,3],[4,5,以上是关于深度学习 Transformer架构解析的主要内容,如果未能解决你的问题,请参考以下文章
《自然语言处理实战入门》深度学习基础 ---- attention 注意力机制 ,Transformer 深度解析与学习材料汇总
《自然语言处理实战入门》深度学习基础 ---- attention 注意力机制 ,Transformer 深度解析与学习材料汇总
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 keras构建多头自注意力(Transformer)模型
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 keras构建多头自注意力(Transformer)模型