深度学习系列26:transformer机制
Posted IE06
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习系列26:transformer机制相关的知识,希望对你有一定的参考价值。
1. 多头注意力机制
首先补充一下注意力和自注意力区别:自注意力有3个矩阵KQV;而注意力只有KV,可以理解为最终结果被用来当做Q了。
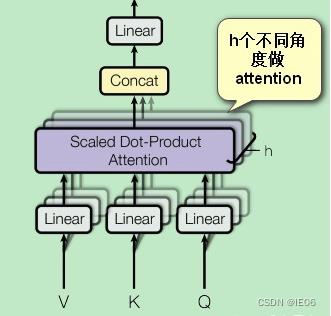
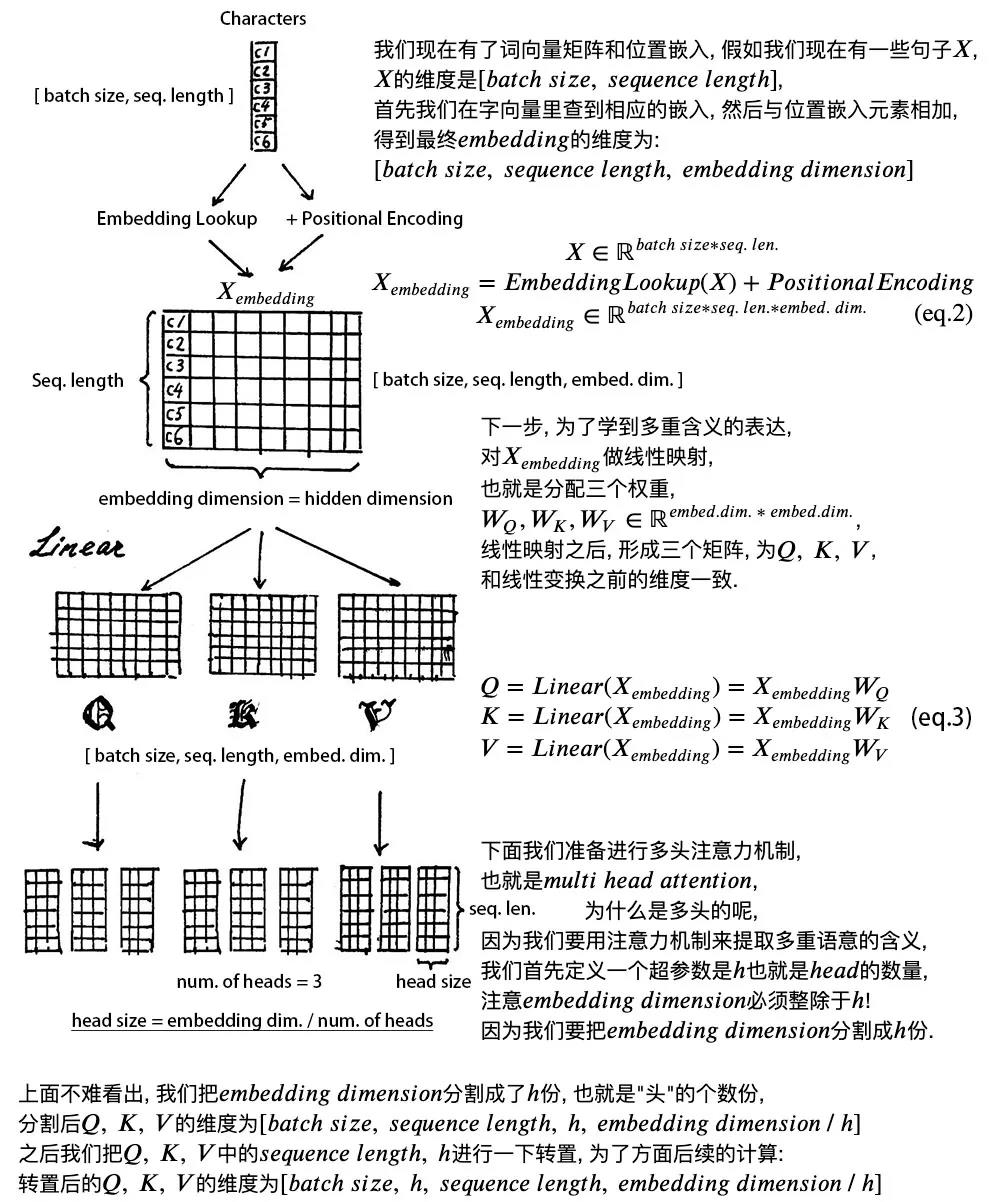
多头注意力机制在自注意力机制上又加了一层多头的概念,即图中从多个不同角度做attention(用不同的方式初始化即可),然后按列拼接起来。一般需要把v/k/q维度也降下来,
d
′
=
d
/
h
d'=d/h
d′=d/h,这样拼接起来后和原来的维度相同。
2. transformer机制
2.1 整体结构
Transformer中抛弃了传统的 CNN 和 RNN,整个网络结构完全由 Attention 机制组成,并且采用了 6 层 Encoder-Decoder 结构。
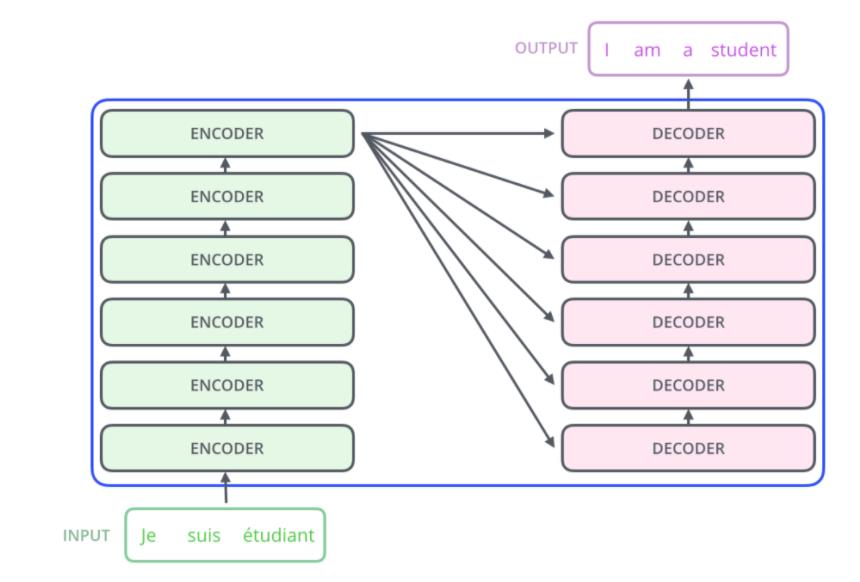
为了方便理解,我们只看其中一个Encoder-Decoder 结构。
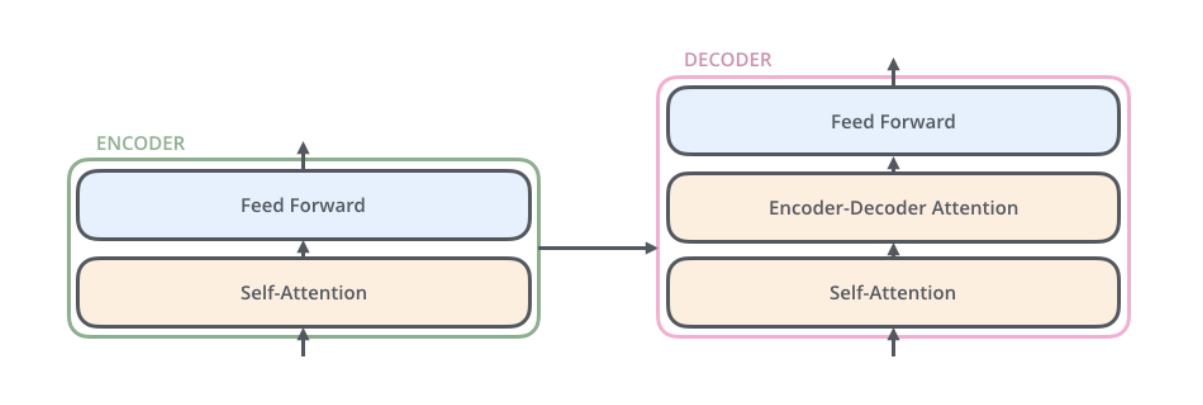
Encoder部分由一个self-attention+前馈网络构成,Decoder部分中间多了一个Encoder-Decoder-attention层。
2.2 Embedding
(1) 将文字转换为固定维度的特征向量,即word2vec。

(2) 加入位置encoding,最简单的可以是直接将绝对坐标 0,1,2 编码。这里使用的是Tranformer的sin-cos 规则:
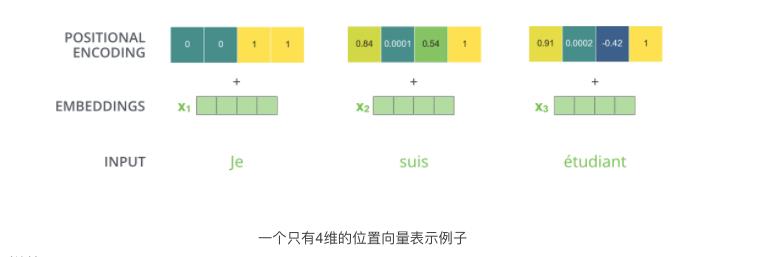
下面是可视化的结果:
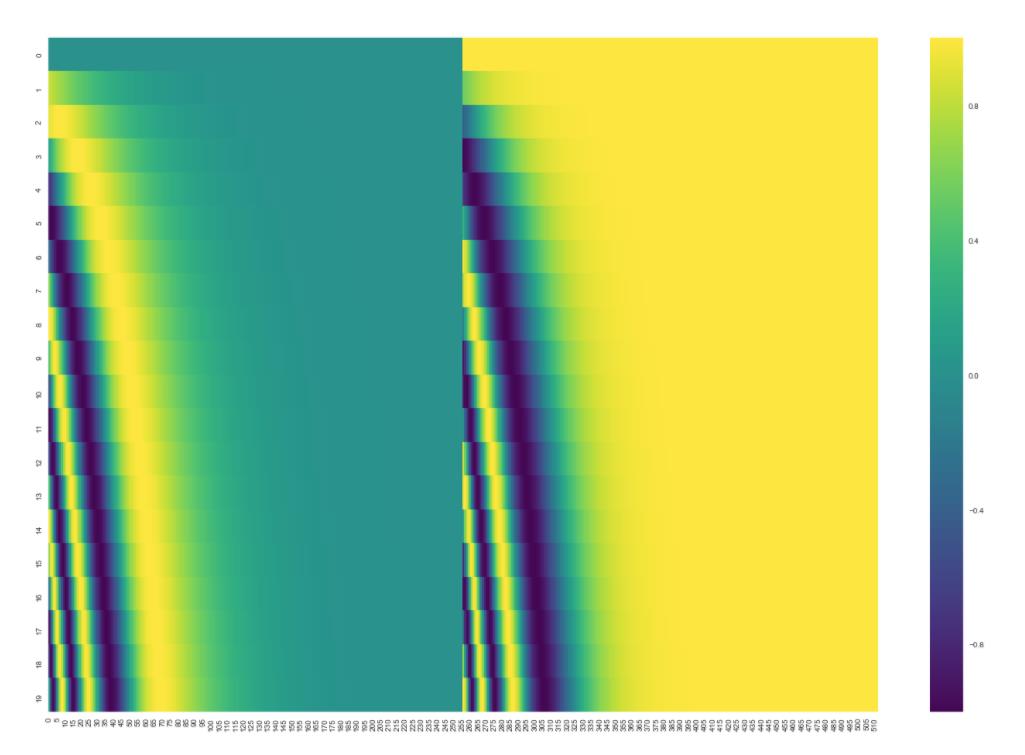
(3)每个编码器的都会接收到一个list(每个元素都是词向量),只不过其他编码器的输入是前个编码器的输出。list的尺寸是可以设置的超参,通常是训练集的最长句子的长度。
2.3 进入self-attention模块
transformer使用了多头机制,赋予attention多种子表达方式。简单来说,就是embedding中加入了更多的句子上下文信息。
像下面的例子所示,在多头下有多组query/key/value-matrix,而非仅仅一组(论文中使用8-heads)。每一组都是随机初始化,经过训练之后,输入向量可以被映射到不同的子表达空间中。
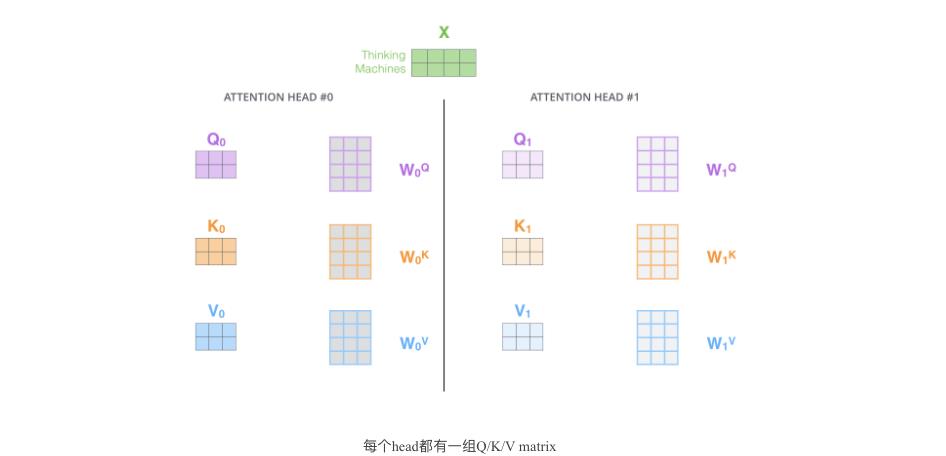
如果我们计算multi-headed self-attention的,分别有八组不同的Q/K/V matrix,我们得到八个不同的矩阵。
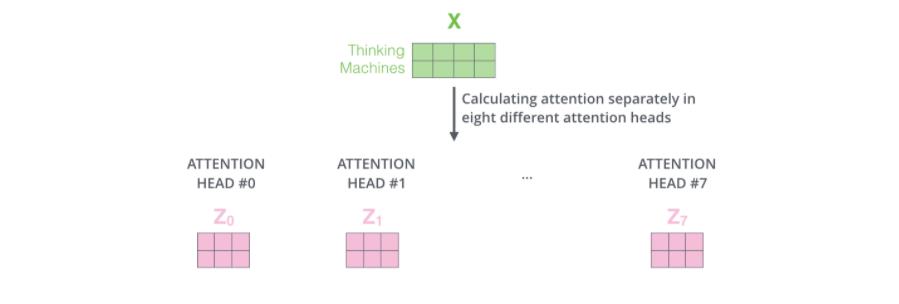
前向网络并不能接收八个矩阵,而是希望输入是一个矩阵,所以要有种方式处理下八个矩阵合并成一个矩阵。
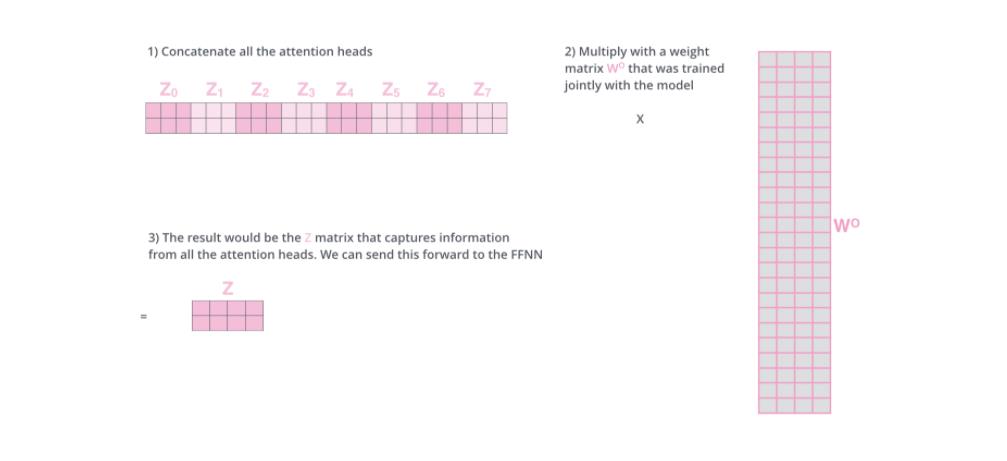
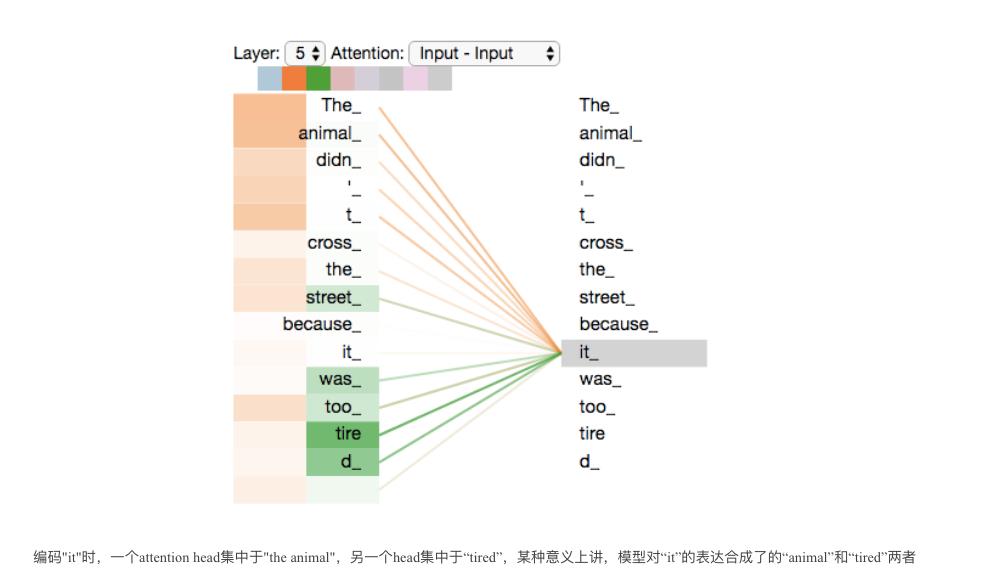
现在加入attention heads之后,重新看下当编码“it”时,哪些attention head会被集中。
2.4 进入前馈模块
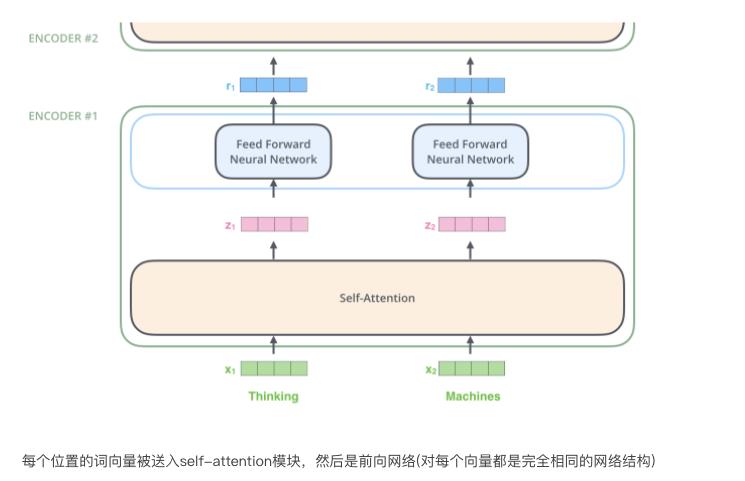
前馈网络比较简单,所有的向量都共享相同的权重。
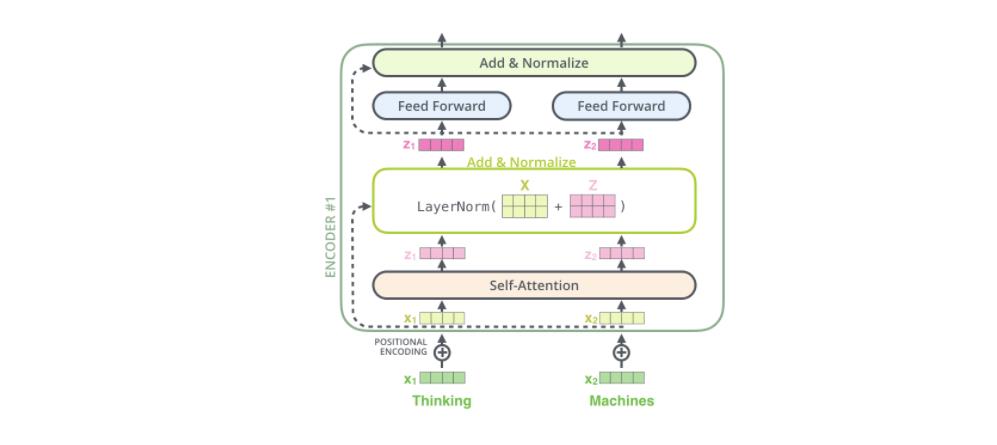
编码器结构中值得提出注意的一个细节是,在每个子层中(self-attention, ffnn),都有残差连接,并且紧跟着layer-normalization(下图的虚线部分)。
2.5 进入解码器
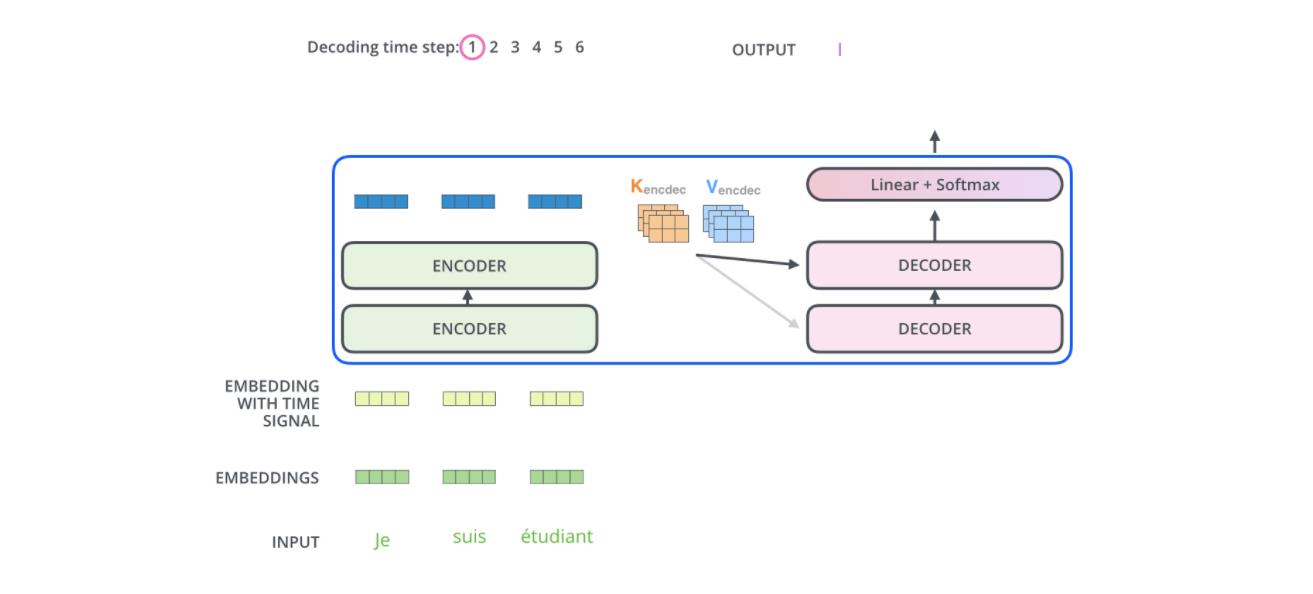
最后的编码器的输出被转换为K和V,它俩被每个解码器的"encoder-decoder atttention"层来使用,帮助解码器集中于输入序列的合适位置。"Encoder-Decoder Attention "层工作方式跟multi-headed self-attention是一样的,除了一点,它从前层获取输出转成query矩阵,接收最后层编码器的key和value矩阵做key和value矩阵。
在解码器中的self attention 层与编码器中的稍有不同,在解码器中,self-attention 层仅仅允许关注早于当前输出的位置。在softmax之前,通过遮挡未来位置(将它们设置为-inf)来实现。
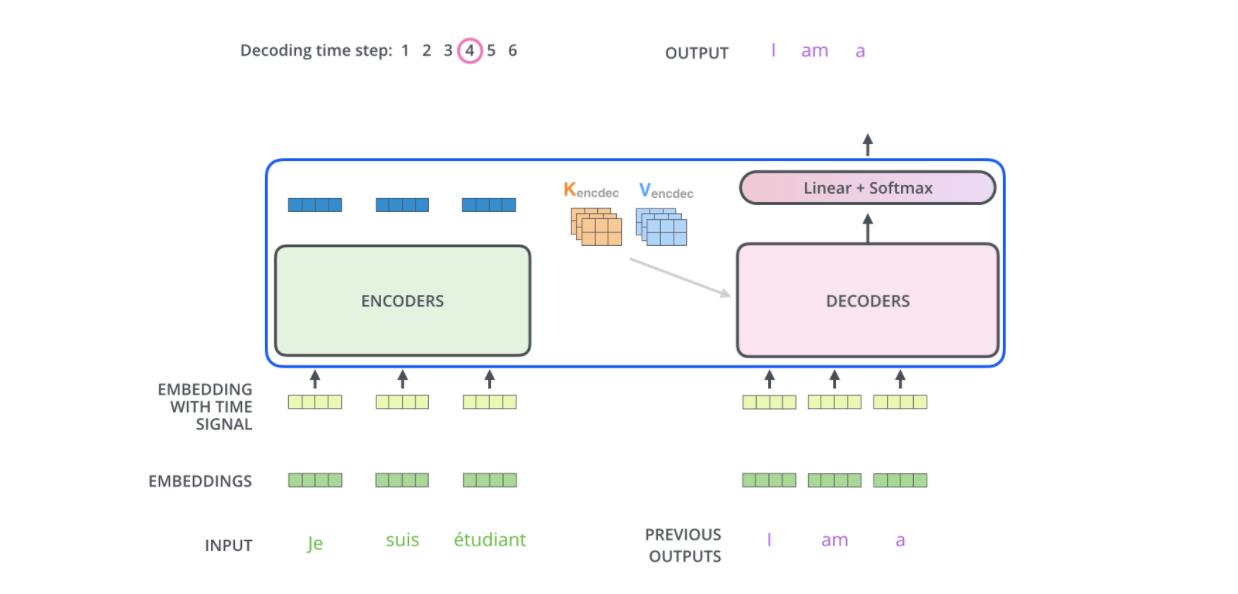
假设两层编码器+两层解码器组成Transformer,由于有残差结构,因此我们看到的设计如下:
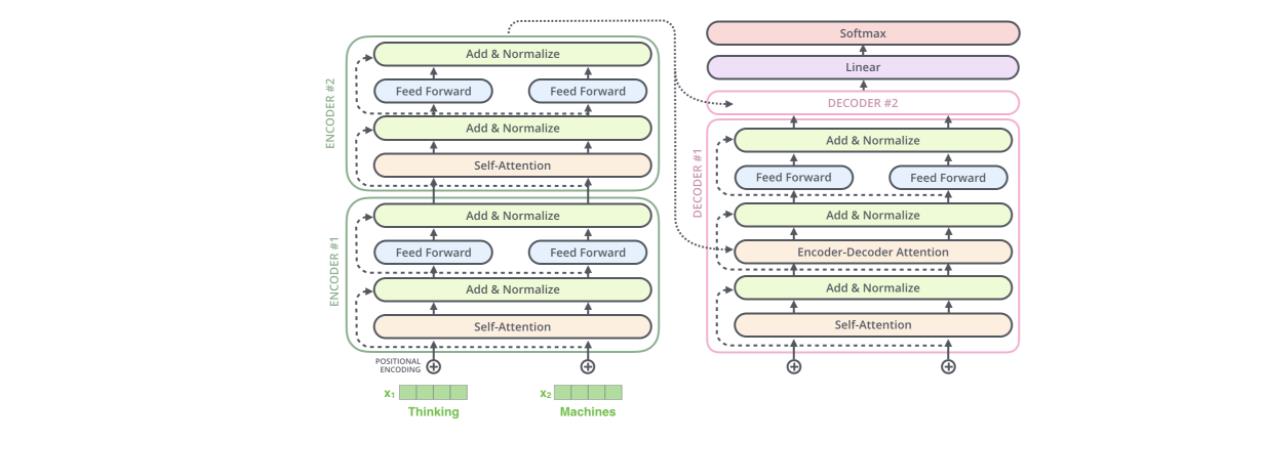
2.6 输出结果
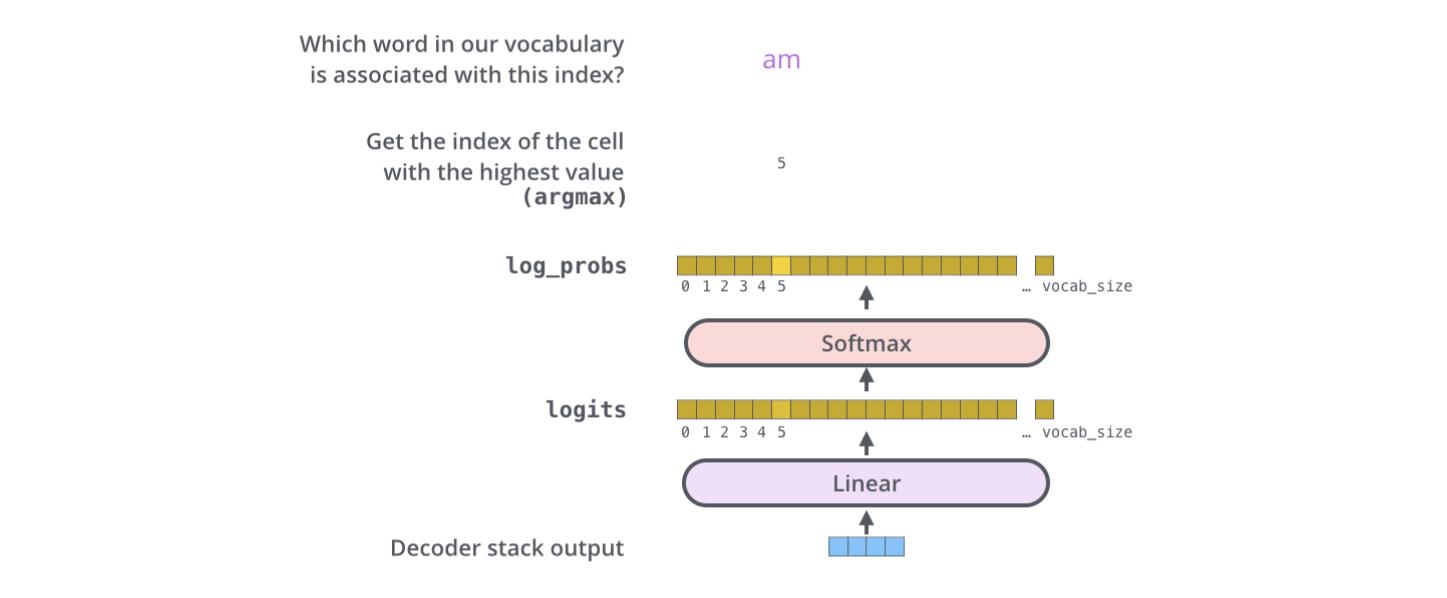
解码器最后输出浮点向量,如何将它转成词?这是最后的线性层和softmax层的主要工作。
线性层是个简单的全连接层,将解码器的最后输出映射到一个非常大的logits向量上。假设模型已知有1万个单词(输出的词表)从训练集中学习得到。那么,logits向量就有1万维,每个值表示是某个词的可能倾向值。
softmax层将这些分数转换成概率值(都是正值,且加和为1),最高值对应的维上的词就是这一步的输出单词。
2.7 损失函数
我们用一个简单的例子来示范训练,比如翻译“merci”为“thanks”。那意味着输出的概率分布指向单词“thanks”,但是由于模型未训练是随机初始化的,不太可能就是期望的输出。
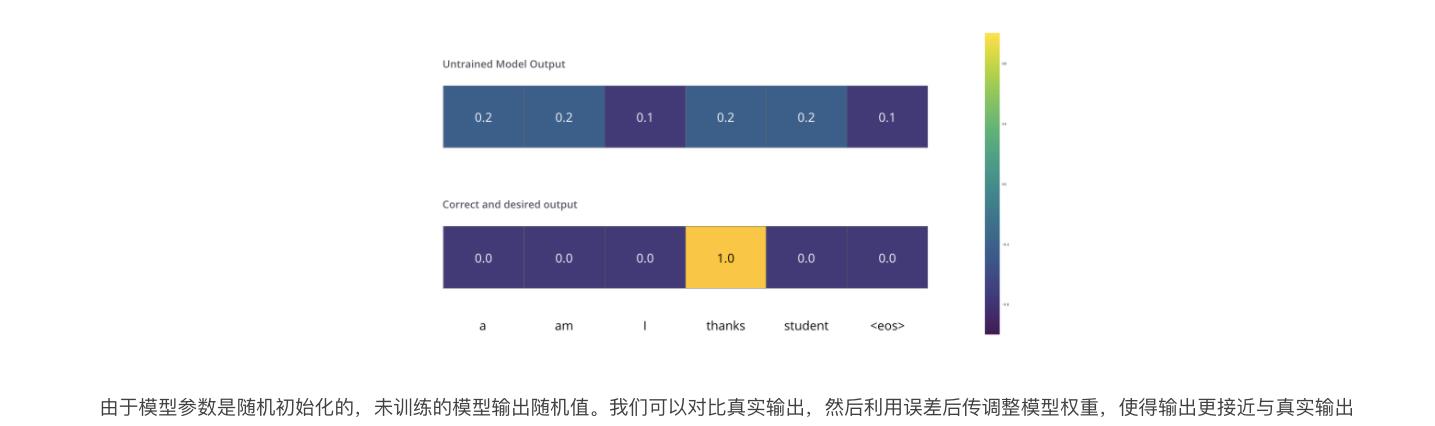
如何对比两个概率分布呢?简单采用 cross-entropy或者Kullback-Leibler divergence中的一种。
鉴于这是个极其简单的例子,更真实的情况是,使用一个句子作为输入。比如,输入是“je suis étudiant”,期望输出是“i am a student”。
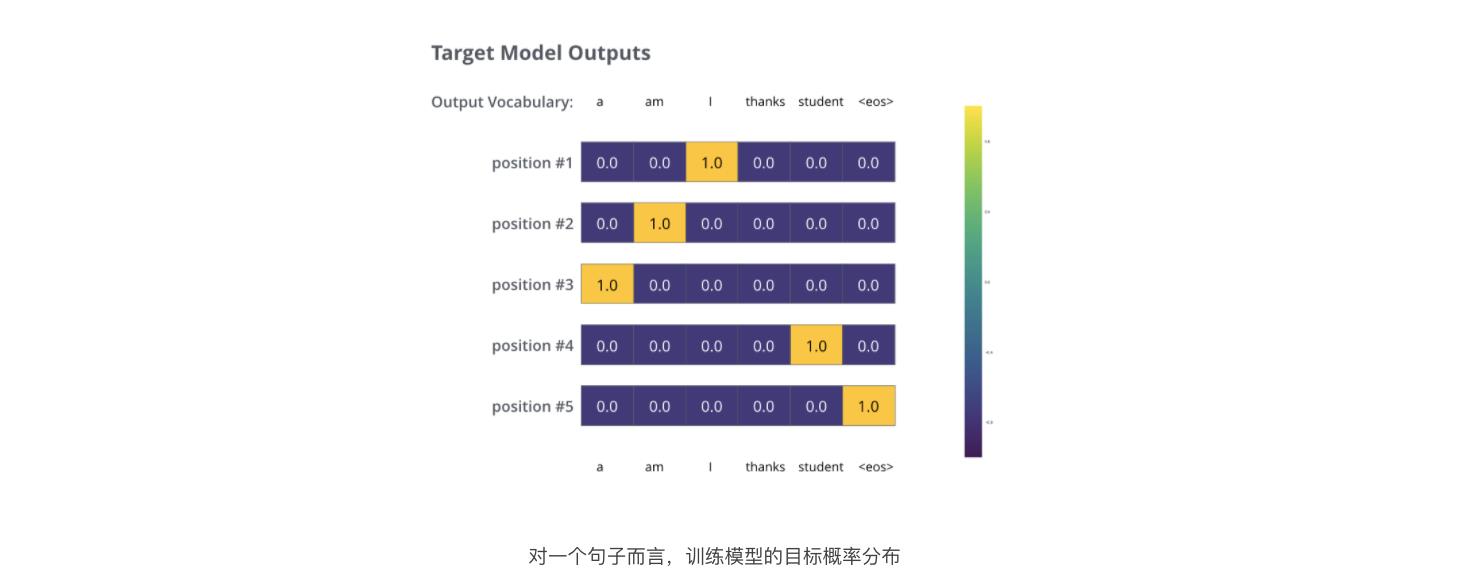
在足够大的训练集上训练足够时间之后,我们期望产生的概率分布如下所示:
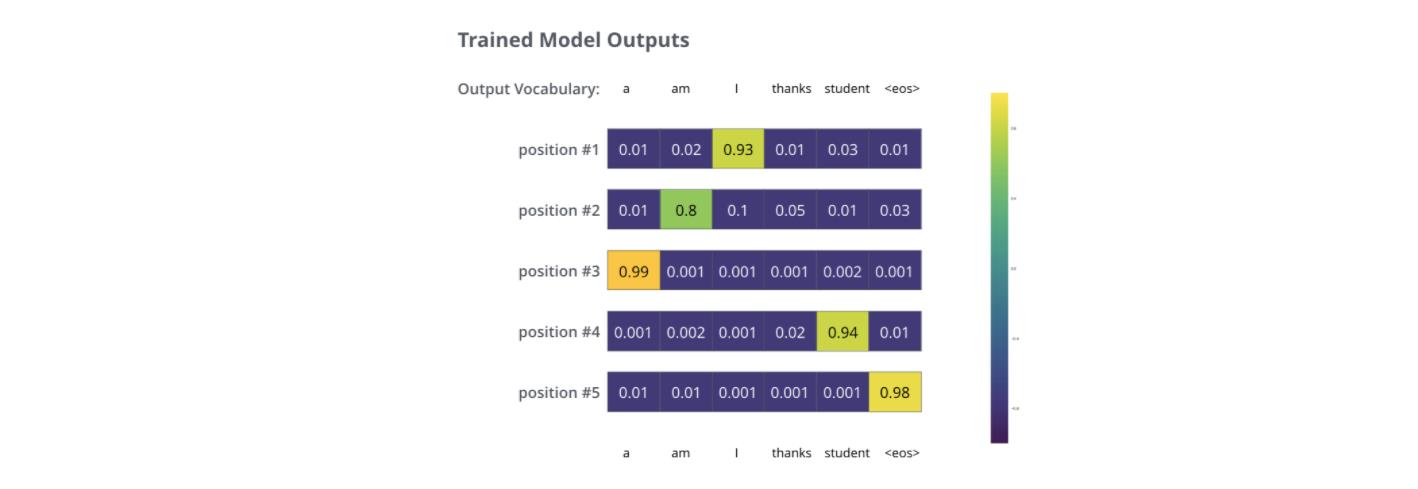
现在,因为模型每步只产生一组输出,假设模型选择最高概率,扔掉其他的部分,这是种产生预测结果的方法,叫做greedy 解码。另外一种方法是beam search,每一步仅保留最头部高概率的两个输出,根据这俩输出再预测下一步,再保留头部高概率的两个输出,重复直到预测结束。top_beams是超参可试验调整。
2.8 完整示意图
多头的意义在于,
Q
K
T
QK^T
QKT得到的矩阵就叫注意力矩阵,它可以表示每个字与其他字的相似程度。因为,向量的点积值越大,说明两个向量越接近。
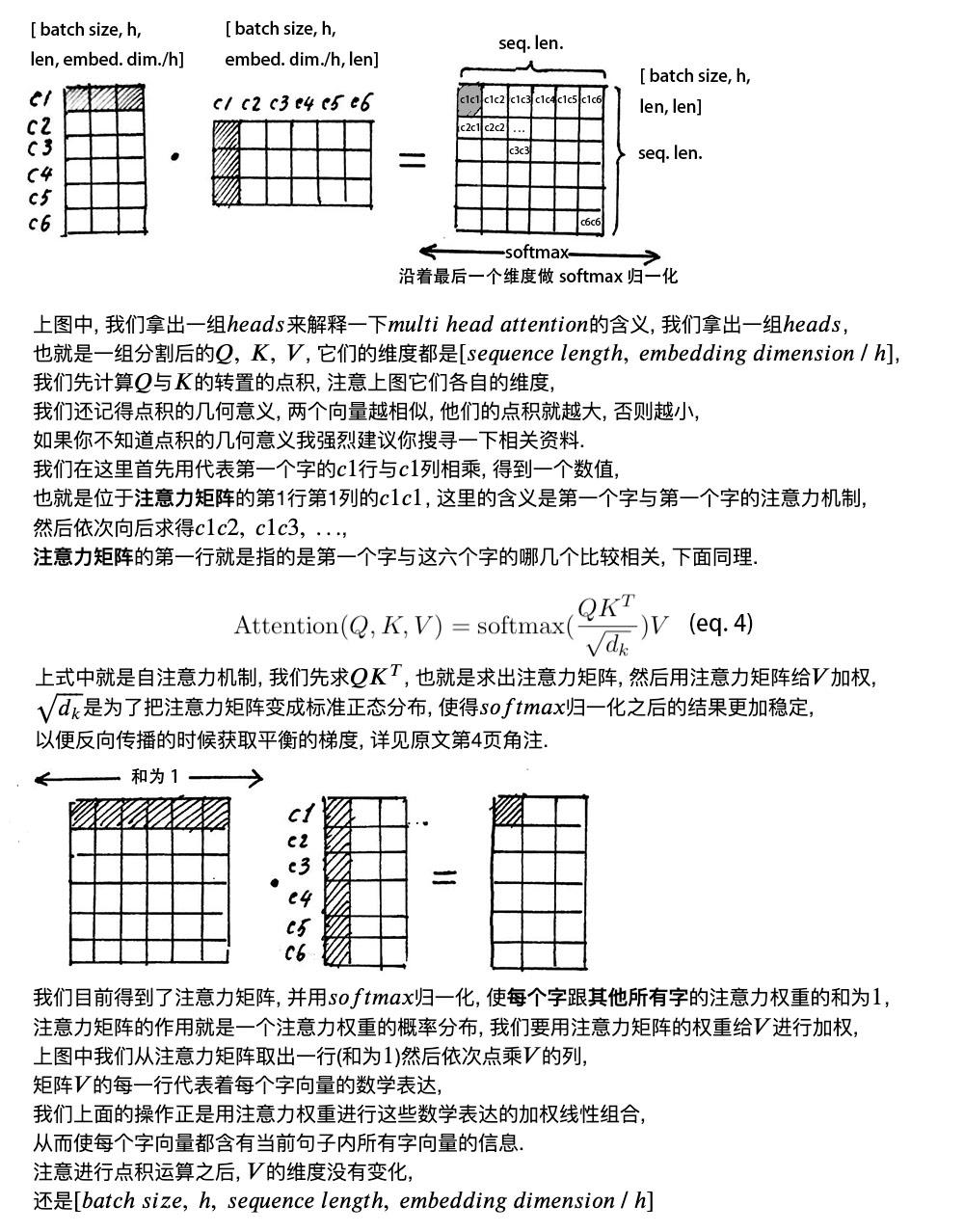
我们的目的是,让每个字都含有当前这个句子中的所有字的信息,用注意力层,我们做到了。
需要注意的是,在上面 𝑠𝑒𝑙𝑓 𝑎𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 的计算过程中,我们通常使用 𝑚𝑖𝑛𝑖 𝑏𝑎𝑡𝑐ℎ,也就是一次计算多句话,上文举例只用了一个句子。
每个句子的长度是不一样的,需要按照最长的句子的长度统一处理。对于短的句子,进行 Padding 操作,一般我们用 0 来进行填充。
最后加入了残差设计和层归一化操作,目的是为了防止梯度消失,加快收敛。
- 残差设计:我们在上一步得到了经过注意力矩阵加权之后的 𝑉, 也就是 𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄, 𝐾, 𝑉),我们对它进行一下转置,使其和 𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 的维度一致, 也就是 [𝑏𝑎𝑡𝑐ℎ 𝑠𝑖𝑧𝑒, 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛] ,然后把他们加起来做残差连接,直接进行元素相加,因为他们的维度一致。在之后的运算里,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加,从而得到残差连接,训练的时候可以使梯度直接走捷径反传到最初始层。
- 层归一化
作用是把神经网络中隐藏层归一为标准正态分布,也就是 𝑖.𝑖.𝑑 独立同分布, 以起到加快训练速度, 加速收敛的作用。
之后引入两个可训练参数 α , β \\alpha,\\beta α,β来弥补归一化的过程中损失掉的信息,注意表示元素相乘而不是点积。
最后加入两层线性映射并用激活函数激活。
以上是关于深度学习系列26:transformer机制的主要内容,如果未能解决你的问题,请参考以下文章
《自然语言处理实战入门》深度学习基础 ---- attention 注意力机制 ,Transformer 深度解析与学习材料汇总
《自然语言处理实战入门》深度学习基础 ---- attention 注意力机制 ,Transformer 深度解析与学习材料汇总