简单有效的预测网络
Posted 宇智波鼬~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单有效的预测网络相关的知识,希望对你有一定的参考价值。
简单有效的预测网络,小白立学立会

目录
作者|付松
单位|哈尔滨工业大学 讲师
研究方向|智能运维
本文解读了一种新的深度无监督领域自适应算法,即深度域不变性残差LSTM(Deep residual LSTM with Domain-invariance)。
从功能上讲,深度域不变性残差LSTM是一种面向强噪声、领域差异的多维时序数据的域不变性特征学习方法。本文首先回顾了相关基础知识,然后介绍了深度域不变性残差LSTM的动机和具体实现,希望对大家有所帮助。
写在前面
鉴于已有多位小伙伴加我QQ咨询关于上述论文的相关问题,无法做到及时回复,向小伙伴们道歉!为了便于小伙伴们快速理解,本文将对这篇论文的思想、方法进行解读。这样,当小伙伴们得不到及时回复时,可以上CSDN了解本篇论文,因为作者实在没办法做到及时回复,毕竟现在是一个卷的时代,作者也十分忙。当然,作者也非常乐意和小伙伴们进行学术交流,共同进步。这也是本人在知乎上发布的第一篇关于学术的文章,如有不足之处,希望大家原谅,作者诚恳接受大家的意见。
论文标题:Deep residual LSTM with Domain-invariance for Remaining Useful Life
论文链接:https://www.sciencedirect.com/science/article/pii/S0951832021005214;https://www.researchgate.net/publication/354292481_Deep_Residual_LSTM_with_Domain-invariance_for_Remaining_Useful_Life_Prediction_Across_Domains(论文已附源码)
摘要
目前开发的无监督域自适应(UDA)方法在一定程度上改善了航空发动机跨域RUL预测的预测性能,但大部分仅通过优化一个单一指标(MMD或对抗机制)以减少领域差异,限制了预测性能进一步提升。此外,学习一组好的特征也一直是RUL预测中的一个长期问题。为了解决这个问题,研究了一种有效的UDA方法,即具有域不变性的深度残差LSTM(DIDRLSTM),以提高预测性能。首先,DRLSTM被设计为特征提取器,用于从源域和目标域学习高级特征。DRLSTM中引入残差连接使得更深层次的网络避免了降级问题,并且更容易优化。其次,集成了两个模块以进一步减少域差异。一种是域自适应,通过添加MK-MMD约束将特征映射到RHKS来减少域差异。另一种是域混淆,通过最小化在对抗优化策略下训练的域分类器的域辨别能力来减少域差异。最后,在C-MAPSS数据集和FEMTO-ST数据集上验证了DIDRLSTM的出色性能。实验结果表明,DIDRLSTM优于五种最先进的UDA方法。
相关基础
深度域不变性残差LSTM网络主要建立在两部分的基础之上:深度残差长短期记忆网络(DRLSTM)、无监督领域自适应
1.1 深度残差长短期记忆网络(DRLSTM)
残差LSTM是LSTM的一种变体,被提出用于解决网络深度增加时传统LSTM的性能下降和训练困难的问题。如图1所示,残差LSTM(ResLSTM)由n个LSTM层和跨层路径(恒等映射)组成,其中恒等映射用于将输入向量直接映射到输出。深度残差LSTM网络由多个残差LSTM堆叠而成,如图2所示。和深度残差网络类似,深度残差LSTM网络可以有效缓解深层LSTM训练过程中的梯度弥散问题,从而解决深层LSTM的训练困难问题。
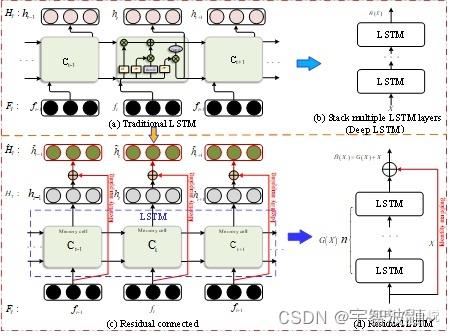
Fig. 1 Structures of traditional LSTM and residual LSTM
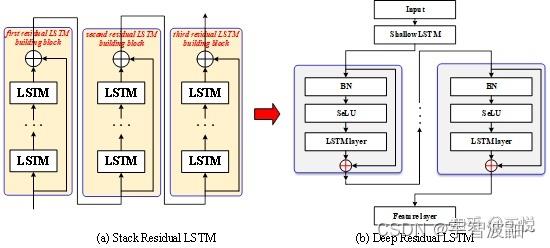
Fig.2 the schematic diagram of DRLSTM
1.2 无监督领域自适应
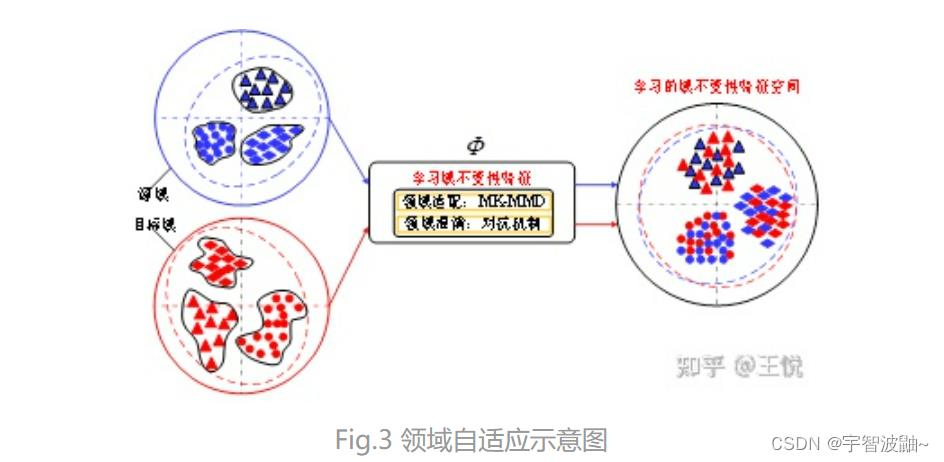
无监督领域自适应旨在降低源域和目标域样本的分布差异,然后基于源域样本的丰富标注信息,完成对目标域样本的预测。在剩余寿命(RUL)预测中,可以将收集的历史运行数据作为源域,将未来飞行的运行数据作为目标域。图3描述了无监督领域自适应的示意图,其中三角形代表剩余寿命为a的样本,圆形代表剩余寿命为b的样本,菱形代表剩余寿命为c的样本。无监督领域自适应的目标是构建一种特征映射关系,可以同时将来自源域和目标域的样本映射到特征空间中,并且使来自不同域的样本在特征空间中混合在一起。多核最大均值差异(MK-MMD)和对抗机制(adversarial mechanism)是衡量领域差异的两种不同视角,它们越来越流行于减少领域差异。
(1)Domain distribution discrepancy measured by MK-MMD
MMD是目前用于衡量两个领域分布差异的流行方法之一,其主要是将两个相关但分布不同的领域同时映射到再生希尔伯特(RHKS, 这里用H表示)空间中,然后通过均值距离衡量两个领域之间的差异。MMD的性能好坏取决于核函数的选择,因为不同的核函数可以将概率分布映射到不同的RHKS空间中,从而导致不同的结果。MK-MMD是MMD的一个变种,其假设MMD中的最优核可以由多个核的线性组合得到,已经被证明具有比MMD更好的性能。由深度神经网络较深层所学习的特征描述了特定领域内的特定任务所具有特定的特征。因此,利用DRLSTM所学习得到的源域样本和目标域样本的深度特征的分布必然存在较大的差异,仅采用一种核函数很难使MMD在衡量这种差异时性能达到最优。相反,基于MK-MMD的多内核k可以通过不同的核函数来增强特征间分布的适配性,达到最优。因此,本文通过MK-MMD衡量来自源域和目标域样本的特征分布差异性。
(2) Domain confused achieved by adversarial mechanism
另一种减小领域差异的流行方法是基于对抗机制的领域混淆方法。与MK-MDD不同,基于对抗机制的领域混淆方法通过最小化在对抗优化策略下训练的域分类器的领域判别能力来混淆不同的域,从而使所提取的深度特征具有较好的领域不变性。在对抗机制中,通过领域间的H-散度来衡量两个不同领域间的差异。由于H-散度的计算非常困难的,通常利用经验H-散度来近似等于H-散度。
深度域不变性残差LSTM网络
2.1 动机
在航空发动机跨域RUL预测中,需要关注两个固有问题:(1)建立输入数据和RUL之间的映射,以便所建立的模型能够预测输入样本的RUL;(2)减少域差异,使所建立的模型几乎不受域差异的影响。为了解决上述两个问题,本文仔细分析了发动机监测数据的特点,然后详细分析了基于这些特点的跨域RUL预测方法的实际需求。最后,根据实际需求,设计了一种适用于航空发动机跨域RUL预测的方法,即所提出的DIDRLSTM。图4显示了整个过程的思维导图,详细描述如下。
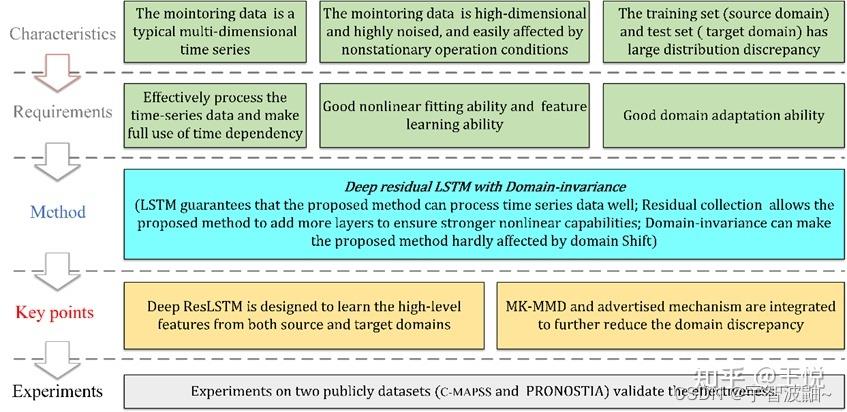 Fig. 4 思维导图
Fig. 4 思维导图
首先,航空发动机监测数据是典型的多维时间序列数据,并且发动机性能退化随着运行时间的增加而增加。所设计的方法必须能够充分利用时间序列数据中的时间相关性(即有效地处理时间序列数据)
其次,收集的航空发动机监测数据是高维、高噪声的,并且容易受到非平稳运行条件的影响。所设计的方法需要具有较强的非线性拟合能力,即添加更多的非线性层来逼近非线性数据。
第三,多变的退化模式(例如,航空发动机在运行过程中可能以意想不到的模式退化),非平稳运行条件和较大的个体差异(例如,不同发动机的退化特征在相同的退化模式下表现出不同)导致预测过程中的领域差异(即,训练集和测试集的分布完全不同)。在实践中,不同的分布严重限制了模型的适用性,这要求设计的方法几乎不受域偏移(即域自适应)的影响。
为了满足上述实际需求,本文设计了一种具有域不变性的深度残差LSTM,即:DIDRLSM。在设计的DIDRLSTM中,DRLSTM被设计从多维时间序列数据中自动学习代表性退化特征。DRLSTM不仅保持了LSTM出色的时间序列处理能力,而且由于引入了残差连接,允许添加更多的非线性层来学习高级特征。因此,DRLSTM更适合处理高噪声、高维和高度非线性的航空发动机监测数据。此外,在提出的DIDRLSTM中集成了MK-MMD和对抗机制,以学习域不变特征。MK-MMD和对抗机制的集成可以充分利用它们各自的优势,这可以进一步减少领域差异。因此,有理由相信所提出的DIDRLSTM可以在航空发动机跨域RUL预测中表现优异。
2.2 实现
图5显示了提出的DIDRLSTM的具体结构,由三个模块组成,即特征提取、域不变性学习和RUL估计。三个模块的详细描述如下。
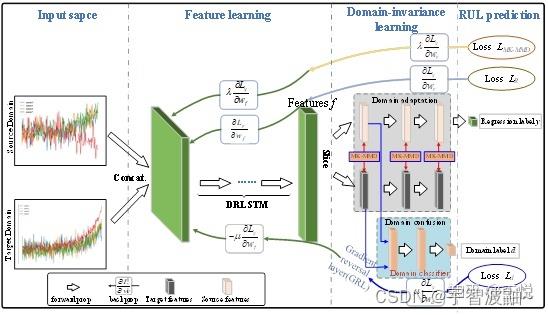
Fig. 5 The schematic diagram of the developed DIDRLSTM
特征提取模块 由DRLSTM充当,旨在同时从源域和目标域的多维时间序列数据中提取高级特征。DRLSTM不仅保持了处理时间序列的出色能力,还允许添加更多层来学习高级退化特征。
域不变性学习模块 由3个MK-MMD层(这里是域自适应模块)和一个域分类器(这里是区域混淆模块)组成,旨在确保所学习的高级特征是域不变性的。MK-MMD层与特征提取模块直接连接,而域分类器与第一个MK-MD层连接。特别地,域分类器由在对抗优化策略下训练的二进制分类器来执行。MK-MMD和对抗机制的集成可以充分利用它们各自的优势,这可以进一步减少领域差异。
RUL预测模块 由回归网络执行,该回归网络旨在建立学习域不变特征与RUL之间的映射,并在目标域中实现RUL估计。
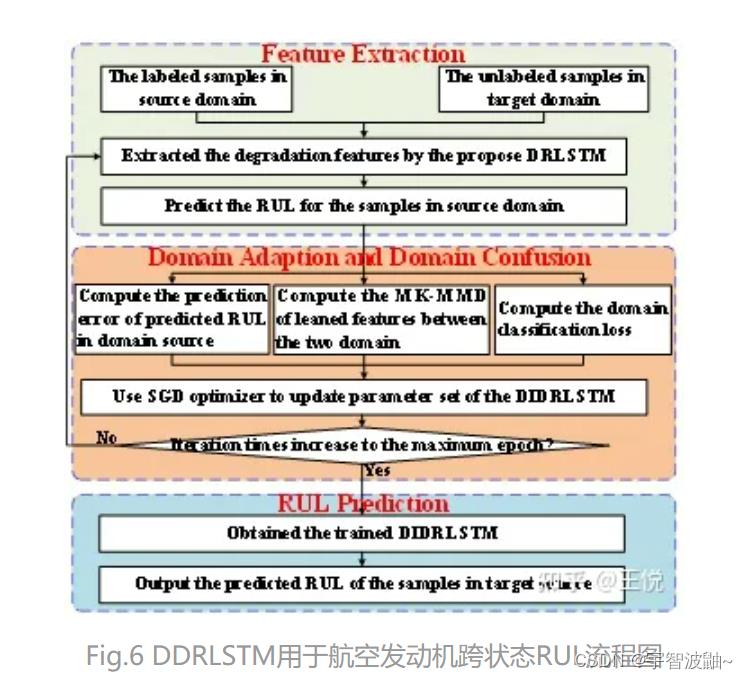
上述分析可知,所提出的DIDRLSTM包含三个优化目标:(1)源域样本的预测损失L_r;(2)域自适应损失L_MK-MMD;(3)域混淆损失L_d。在训练过程中,通过最小化预测损失和域自适应损失、最大化域混淆损失,对DIDRLSTM进行训练,如图6所示。一旦训练完成,训练完成的DIDRLSTM具有优秀的领域不变性从而可以对目标域无标签样本进行准确地预测而不受领域差异影响。
2.3 优势
(1)DRLSTM被设计作为特征提取器,用于从域源和目标源学习高级退化特征。DRLSTM不仅保持了LSTM出色的时间序列处理能力,而且由于引入了残差连接,允许添加更多的非线性层来学习高级特征。
(2)DIDRLSTM同时集成MK-MMD和对抗机制,从不同的两个方面(领域对齐和领域混淆)学习领域不变性特征,形成优势互补,使得DIDRLSTM适合任何一种迁移学习任务,并且领域自适应性能不受领域差异大小影响。
结论
领域差异是无处不在的,深度域不变性残差LSTM网络,或者说这种“特征提取”+“无监督领域自适应”的思路,有着广阔的拓展空间和应用范围。
以上是关于简单有效的预测网络的主要内容,如果未能解决你的问题,请参考以下文章
LSTM预测基于matlab鲸鱼算法优化双向长短时记忆BiLSTM航空发动机寿命预测 (多输入单输出)含Matlab源码 2288期