机器学习李宏毅——Transformer
Posted FavoriteStar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习李宏毅——Transformer相关的知识,希望对你有一定的参考价值。
Transformer具体就是属于Sequence-to-Sequence的模型,而且输出的向量的长度并不能够确定,应用场景如语音辨识、机器翻译,甚至是语音翻译等等,在文字上的话例如聊天机器人、文章摘要等等,在分类问题上如果有问题是一些样本同时属于多个类也可以用这个的方法来求解。只要是输入向量,输出向量都可以用这个模型来求解。
那么Seq2seq的大致结构如下:
也就是有一个Encoder和一个Decoder,将输入的向量给Encoder进行处理,处理后的结果交给Decoder,由Decoder来决定应该输出一个什么样的向量。
Encoder

以上便是Encoder的作用,输入一排向量,输出也是一排向量,而这个功能呢实际上用自注意力机制、RNN等都可以实现(在Transformer中用的就是自注意力机制,可以查看我这篇推博客了解自注意力机制[点此跳转]([机器学习]李宏毅——自注意力机制(Self-attention) - 掘金 (juejin.cn)))。我们将这个Encoder进行详细解析,其内部结构可以看下图:

实际上一个Encoder里面有很多个Block(一个Block不止有一层layer),而每一个Block实现的功能都是输入一排向量然后也是输出一排向量,而我们从图的右边可以看到每一个Block内部的实现,就是一排向量先经过自注意力机制后得到一排处理过的向量,那么再逐个放于全连接的全向网络之中,最终的输出也是一排向量。
但其实在Transformer中关于block的实现会更复杂一点:

其中不同点我已经圈出来了,其具体的流程为:
- 一排向量经过Self-attention之后的输出,需要和对应的输出向量一一相加起来,如图中的a需要和它对应的输入b相加起来,这种网络架构(将输出与输入相加)称为residual connection。
- 得到真正的输出之后,需要经过一次Layer normolization,其特别的地方在于是直接对向量进行标准化(减去均值除以标准差),因为向量中的每个元素是属于不同的维度的,属于不同的特征的。
- 将经过norm之后的向量作为全连接的前向网络的输入,然后输出需要再与输入相加,并且再一次经过norm,才能够真正作为这一层block的输出。
因此,在Transformer中的Encoder就很容易理解了:

其中主要的不同就在于输入的地方加入了一个Positional Encoding,这是因为在Transformer中需要明确各个向量之间的位置关系,但在输入的时候有可能这个位置关系已经丢失了,那么就通过这个模块来告诉模型这些向量彼此之间的顺序关系。
Decoder
Decoder有两种,分别是Autoregressive和Non-Autoregressive
Autoregressive
由前述可知,经过Encoder之后会得到一排输出向量,那我们目前先假设存在某种方法能够将这些向量作为Decoder的输入,而要“启动”Decoder,需要输入一个向量特殊向量BEGIN,那么Decoder结合Encoder的输入,还有这个Begin的向量,就会输出一个向量,再经过softmax之后就得到我们想要的向量,如下图:

这个目标向量它的长度跟机器当前认知的词汇长度一样长(机器认识多少个字就有多长),然后经过softmax之后相当于得到了每个汉字的输出概率,那取其中的概率最大值对应的文字就可以作为当前这个向量所代表的输出了,例如这里是机。
那么接下来呢再将这个“机”的向量作为Decoder的输入,同时它还会考虑BEGIN这个向量的输入,以及Encoder的输入,结合这三部分它再输出一个经过softmax的向量,这个向量跟上一个输出向量也是相同的性质,那我们同样取其中概率最高的作为最终的输出文字,如下图中的“习”,以此类推不断循环直到满足要求:

那么可以来看一下原始Transformer论文中Decoder的内部结构,大致如下:

从上图中可以看出,如果我们将绿色圈圈中的结构忽略掉的话,其实Encoder和Decoder的结构相差是不大的。但仍然需要注意我箭头的地方,在Decoder中的自注意力机制变成了Masked版本的,那么这个版本的特点在于:
原先的自注意力机制在考虑每一个向量的输出时,都是综合考虑了前后所有输入的向量
但是在Masked中,每个向量要做输出时只能够考虑它之前的向量,不能够考虑它之后的向量。
从下图可以更直观的理解:


上面的第一张图是原来的版本,第二张图是Masked版本,那么就可以很直观的看出区别了。那么需要认识到为什么要用到Masked的版本:因为在Decoder中,我们刚才认识到其工作流程是单个向量按照顺序的输入进去的,并不是跟Encoder一样所有向量一起进入,因此在输入当前的向量的时候它只知道之前已经输入的向量,它不知道未来输入的向量,那么它就只能够考虑之前的向量而不能够考虑之后的向量。
那么下一个问题就在于如何决定Decoder输出的长度呢,如果不加限制的话上述的例子将会不断重复下去,不断找到下一个概率最大的文字并且输出,这不是我们想要的结果。
具体的做法就是在前面所述的输出向量的长度中,除了包含汉字以外还包含两个特殊字符,一个就是刚才提及的BEGIN,另一个就是END,那么具体结束的方式就承接上文那个例子:

就是要让机器学会看到Encoder的输入加上BEGIN、机器学习这些之后,它就明白该结束了,因此它输入“习”时输出的向量中END的字符的概率最大,因此输出为END,那么就结束了这个过程。
Non-Autoregressive(NAT)
它与前面AT的不同在于,它的输出并不是一个一个的字符产生的,它是一次性输出所有字符,即:

每一个输入都是一个BEGIN,然后再根据Encoder输出对应的字符,那么现在的问题就在于我们如何确定这个Decoder要输入多少个BEGIN呢?可能的做法有下面几种:
- 增加一个分类器,这个分类器接受Encoder输出的所有向量,然后它输出为一个数字,这个数字就代表Decoder需要输入几个BEGIN
- 假设一个输出长度的上限,然后每次给Decoder都是那个上限值数目对应的BEGIN,那么也会输出上限值对应的输出个数,然后再在里面找哪一个输出对应字符END,这个字符后面的输出就都不用考虑了
NAT的优点在于平行化,速度相当于AT要更快;同时如果有一个控制输出长度的分类器,那么我们就可以很好的控制长度。但总体来说其表现不如AT。
Encoder-Decoder
本节讲解的内容是Encoder如何将其信息传递到Decoder。
实际上它们之间信息的传递就是用到下图中框框中的模块,该模块称为Cross attention,可以看到该模块接受Encoder两个输入,接受Decoder一个输入:

其具体的运作流程如下:
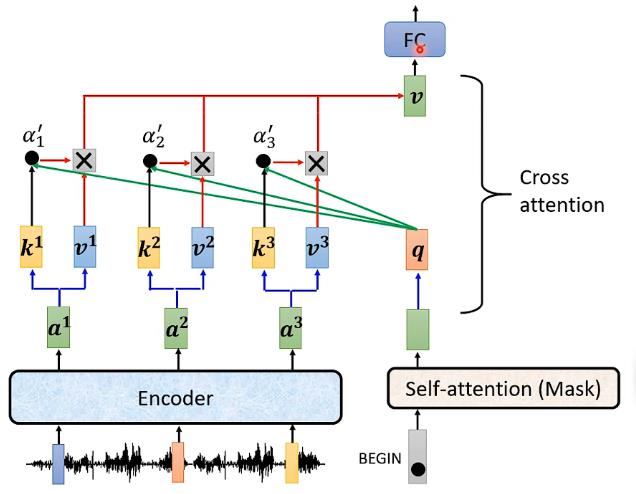
- 首先Encoder中接受了输入之后产生了对应的输出向量,而Decoder中最开始的自注意力机制(带Mask)中也接受了BEGIN这个输入,产生对应的向量,并将该向量乘以一个矩阵得到向量q
- Encoder中的输出向量分别乘以矩阵K得到各个向量k,然后再将向量k个向量q去计算Attention的分数,这部分需要用到自注意力机制中计算分数 α \\alpha α的内容,具体可以参考我这篇博文[点此跳转]([机器学习]李宏毅——自注意力机制(Self-attention) - 掘金 (juejin.cn)),这里我觉得是要将向量k和向量q进行点乘就得到了 α \\alpha α,不确定用不用再乘以矩阵 W q W^q Wq和 W k W^k Wk。而图片中加一个撇是表明这里的 α \\alpha α可以去进softmax变换
- 将Encoder中的输出向量分别乘以矩阵V得到各个向量v,然后再其与对应的 α \\alpha α相乘,并进行相加得到向量V(这里 α \\alpha α是一个常数,因此可以看成各个向量v的加权和)
- 得到的这个向量V就是Cross attention的输出,接下来会放入全连接的网络中进行处理
- 同样的Decoder下一个输入进入也是进行相同的流程
另外一个值得注意的问题是Encoder有很多层,Decoder也有很多层,而在原始的论文中Decoder中的每一层的Cross attention都是用Encoder最后一层的输出,但是也存在众多对此的研究,尝试各种方式。
Train
下面需要对Transformer 如何进行训练进行讲解:

我们的输出BEGIN后得到的输出是一个分布,其中代表着取到每一个汉字的概率,而我们希望它输出的正确答案为一个One-hat-vector,那么损失函数就是这个分布和正确答案的向量之间的交叉熵,我们希望它们越接近越好,因此应该最小化它们之间的交叉熵。

而在多个向量的时候也是同样的道理,我们希望每一个输出都能够和正确答案对应的向量之间的交叉熵足够小。但这边需要注意的是在训练的时候我们给Decoder看的是正确答案,例如上图给Decoder输入的是BEGIN、机器学习等都是正确的One-hat-vector,这种让机器在学习的时候看到正确答案的方法称为Teacher-Forcing,但在测试集的时候就不会给正确答案。
Tips(关于Sequence-to-Sequence模型的训练注意事项)
Copy Mechanism
在Sequence-to-Sequence的任务中,很多时候我们并不需要机器完全从零开学会产生正确答案,在一些很复杂的词语的时候我们可以让机器学会复制输入来进行输出,例如:

对于机器来说“库洛洛、不能使用念能力”这种词汇是很难在训练资料中看到并且学会的,因此在这种情况下就很难让机器自己学会输出这种词语,因此我们可以训练机器在例如看到我是某某某的时候就直接把某某某复制过来进行使用,这样就不需要花费过多的时间精力去训练各种复杂、奇怪的词汇。另一种应用场景是在训练机器读文章写摘要的过程中,因为摘要很多词语都是从文章中直接摘录出来的,因此并没有必要让机器从零产生这些词语,学习复制更加重要。
Guided Attention
在做语音辨识、文字转语音等任务中,我们无法看到Sequence-to-Sequence这个模型它内部训练的好坏,但可能在结果会出乎意料,例如在语音辨识中经常会有一段语音机器没有处理出结果,在文字转语音中也会经常漏字等等,那这个时候就可以考虑是不是机器学习完成后再处理的过程中的顺序不够正确,例如下图:

例如正确的顺序是上部分,即计算Attention scores的时候应该是从左到右的顺序依次计算,但在实际训练过程中可能会出现下半部分的处理顺序,那么就说明机器学习到的处理顺序并不正确,那么处理方法就是我们可以用Guided Attention这项技术使得机器一定要学习到从左到右的这个处理顺序。类似的算法在右上角。
Beam Search
假设当前输出只有两种可能性A和B,那么在按照顺序处理多个向量的时候如下图:

- 第一种思想就是每一次选择的时候都考虑当前可选择中的概率最大的那个,例如从最下面的点开始选择ABB,每一步都是概率最大的点,这种称为贪心思想。但是这种思想并不一定最终结果是最优的
- 另一种思想是:如果第一次选择了概率较小的B,而发现后面的概率突然就很大了,那么最终结果是BBB,这样最终的概率为 0.4 × 0.9 × 0.9 > 0.6 × 0.6 × 0.6 0.4\\times 0.9\\times 0.9 >0.6\\times 0.6\\times 0.6 0.4×0.9×0.9>0.6×0.6×0.6,即最终的结果是更好的,即可能在某次选择的时候选择较差的概率,后面可能会得到更好的结果。
那么我们应该如何确定什么时候应该选择概率最大而什么时候应该选择概率小的呢?一种可能的解决方案为Beam Search,它会提供一个可能不是那么精确的解决方案来解决这个问题,但是有的时候有用,有的时候就没用。例如在语音转文字的时候因为它的答案只有一个,因此如果我们能够找到概率最大的那个输出可能其结果会更好一些。但是如果在文章续写这种具有多个答案,需要随机性的任务中使用Beam Search算法就很难得到好的结果。
优化评估策略
在训练的时候我们用的是对每一个输出向量进行交叉熵的形式来作为损失函数,但是在测试的时候并不是这样,在测试的时候是用输出的整个句子和正确的句子来计算BLEU score(评论文本的一个指标)来作为评价的好坏,如下图:

但我们在训练的时候用的是最小化交叉熵的策略,其实这并不能够保证就能够最大化BLEU score,因此在验证集的时候通常不是继续考虑最小化交叉熵的那个模型,而是考虑能最大化BLEU score的那个模型。
而如果在训练的时候就用这个BLEU score来作为损失函数的话是行不通的,因为这样的损失函数是不可微分的。
exposure bias
前面我们已经提到了,在训练的时候Decoder每次的输入都是正确的东西,但是在测试的时候Decoder看到的是自己的输出,这并不能够保证一定正确,如果发生错误的话就可能会导致接下来都发生错误。那么具体的办法就是在训练的时候不要让Decoder看到的全都是正确的东西,可以偶尔让它看到错误的东西,如下图:

这个思想具体称为Scheduled Sampling。
以上是关于机器学习李宏毅——Transformer的主要内容,如果未能解决你的问题,请参考以下文章