李宏毅深度学习CP13Transformer(part2)
Posted 奇跡の山
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅深度学习CP13Transformer(part2)相关的知识,希望对你有一定的参考价值。
学习总结
(1)上一小节主要是先讲Encoder,这次是学习Decoder(根据并行性分为AT和NAT两种)、Encoder和Decoder之间的关系(通过Cross Attention机制)还有训练的一些tips(好多tips呜呜)。
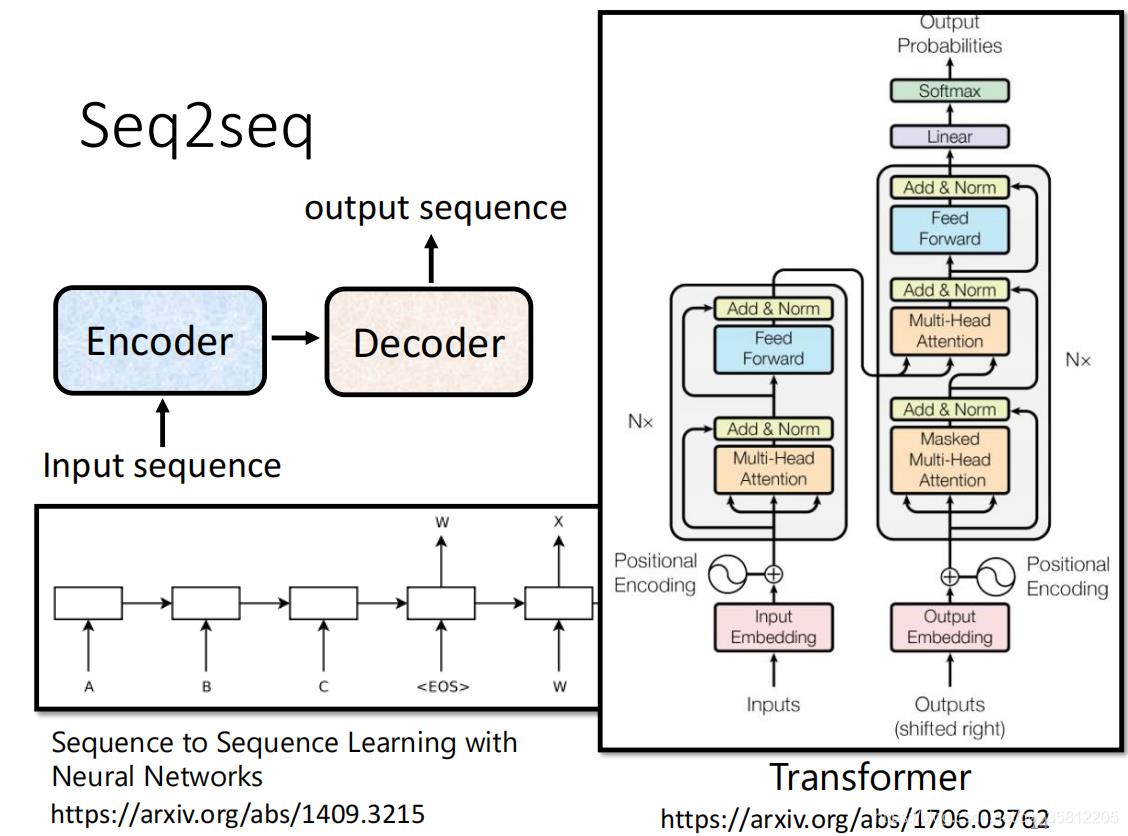
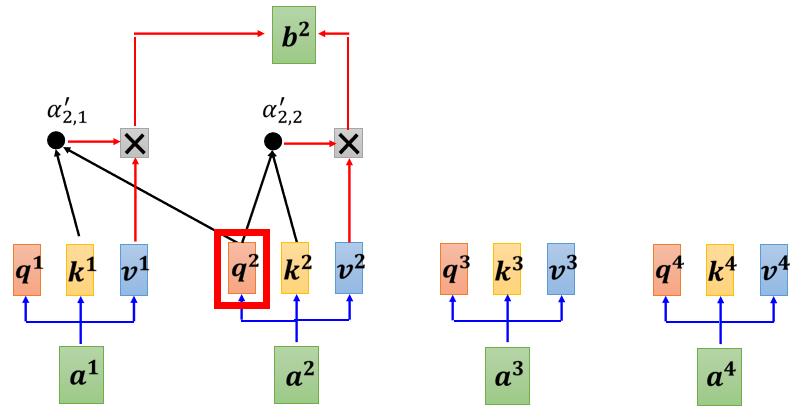
(2)Cross Attention:比如在Decoder输入 BEGIN 输入“机”,产生一个向量,该向量一样乘上一个 Linear 的 Transform 后得到 q’(得到一个 Query),这个 Query 一样跟
k
1
k
2
k
3
k^1 k^2 k^3
k1k2k3去计算 Attention 的分数(得到
α
1
α
2
α
3
α_1 α_2 α_3
α1α2α3),attention再跟
v
1
v
2
v
3
v^1 v^2 v^3
v1v2v3 做 Weighted Sum 做加权,然后加起来得到 v’,交给接下来 Fully-Connected Network 做处理。
ps:QKV三个矩阵都是来源于词向量矩阵。
(3)在(2)中是计算完attention即
α
i
α_i
αi(即对应各个向量value的权重)后还要乘这些value加权求和。就像一张图,attention只是告诉你你的注意力要注意在左上角,但是没告诉你左上角是什么你还是不知道这张图表达了什么——【关系程度】最后要和【上下文】结合,也即将向量再编码下。
附:秋阳大佬画的图哈哈哈:

文章目录
一、Decoder – Autoregressive (AT)
Decoder有两种,比较常见的是Autoregressive Decoder。我们上小节说了Encoder是做了输入一个vector sequence,输出另外一个vector sequence。接下来轮到Decoder产生输出,如产生语音识别的结果。
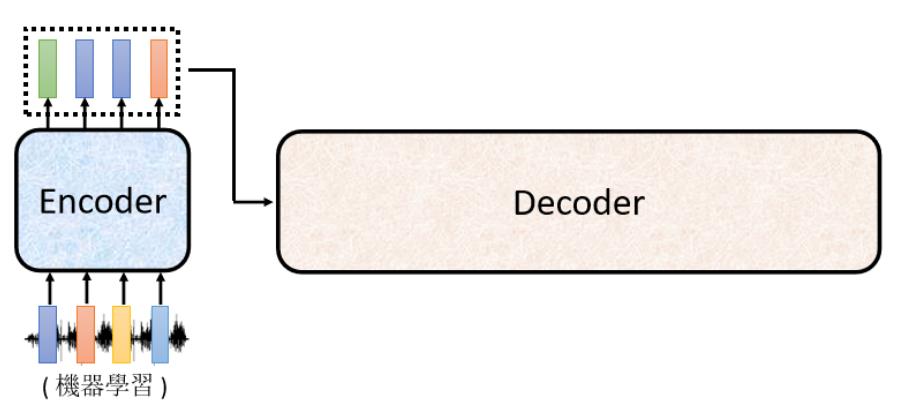
Decoder做的事情是把Encoder的输出先读进去。那Decoder是怎么产生一段文字的:
(1)先给它一个特殊的符号——代表开始,在开始的ppt里写Begin Of Sentence(缩写是BOS),这是一个special的token。就是在你的Lexicon(字典)里面,即Decoder可能产生的文字里面多加一个特殊的字——该字代表begin(开始)。
假设你要处理NLP问题,每一个Token都可以用一个One-Hot的Vector来表示(就其中一维是1,其他是0),所以begin也是用One-Hot Vector来表示。
(2)接着Decoder会吐出一个很长的vector(和vocabulary的size一样)
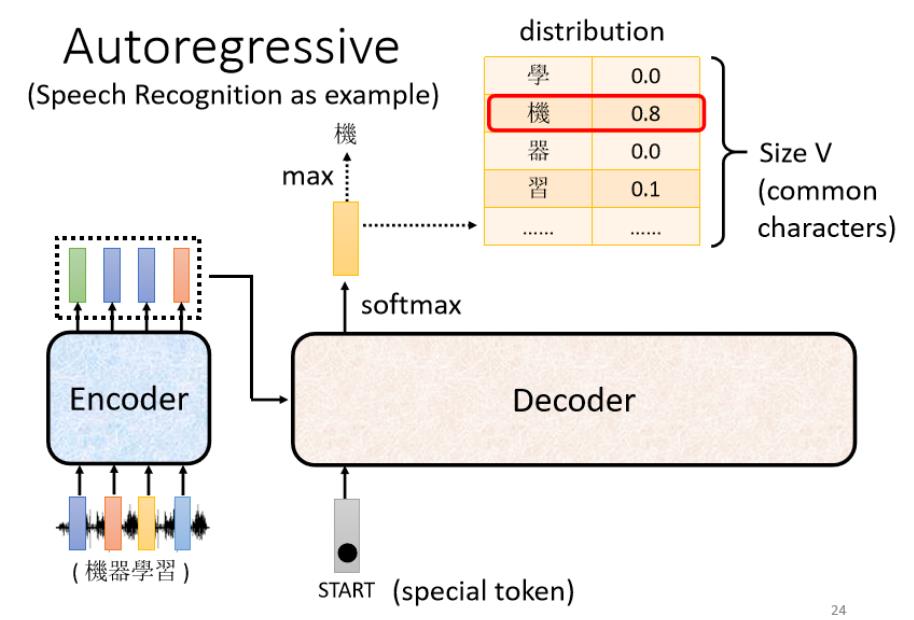
vocabulary size是什么意思?
先想好Decoder输出的单位是什么,如果做得是中文的语音识别则我们Decoder输出的是中文,那么vocabulary size可能就是中文方块字的数目
不同的字典size可能是不同的,常用的中文方块字大约三千,一半人可能人的四五千,那么这个Decoder能够输出常见的3000个方块字就好(这个取决于你对该语言的理解)。
再举栗子:可以选择输出字母A到Z输出英文的字母,而如果觉得字母这个单位太小了,可以用英文单词的“词根”作为单位。
每一个中文的字对应到一个数值,因为在产生这个向量之前,通常会先跑一个softmax(和分类一样),所以这个向量里面的分数积一个Distribution,即该向量里面的值全部加起来等于1。分数最高的一个中文字,它就是最终的输出。
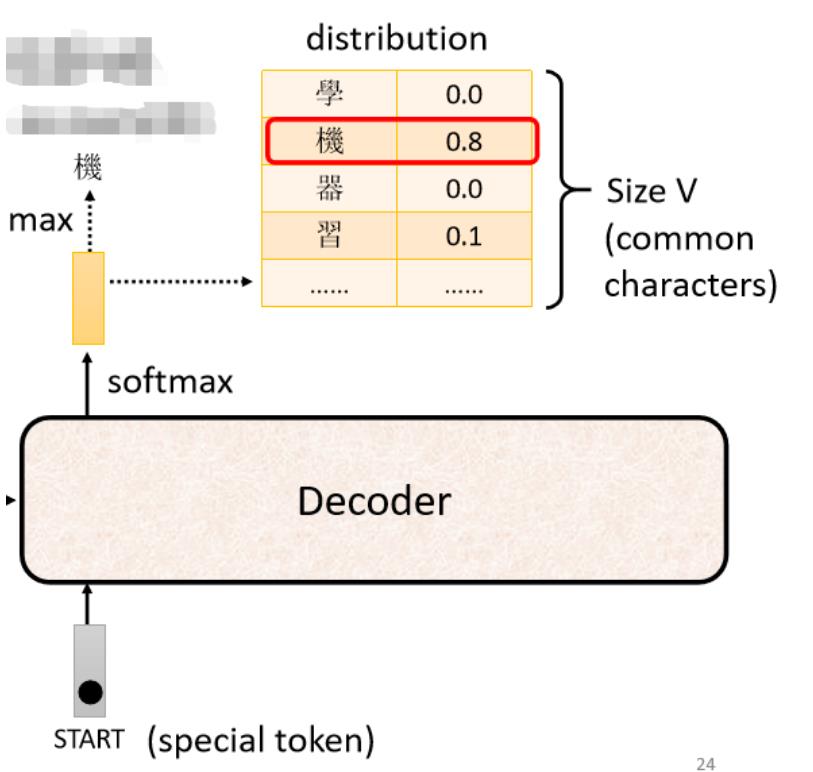
而在上面例子中“机”字的分数最高,所以就是这个Decoder第一个输出的东东,然后把“机”字当做是Decoder新的input(原来Decoder的input只有begin这个特别的符号,现在它除了begin外还有“机”作为其input)。
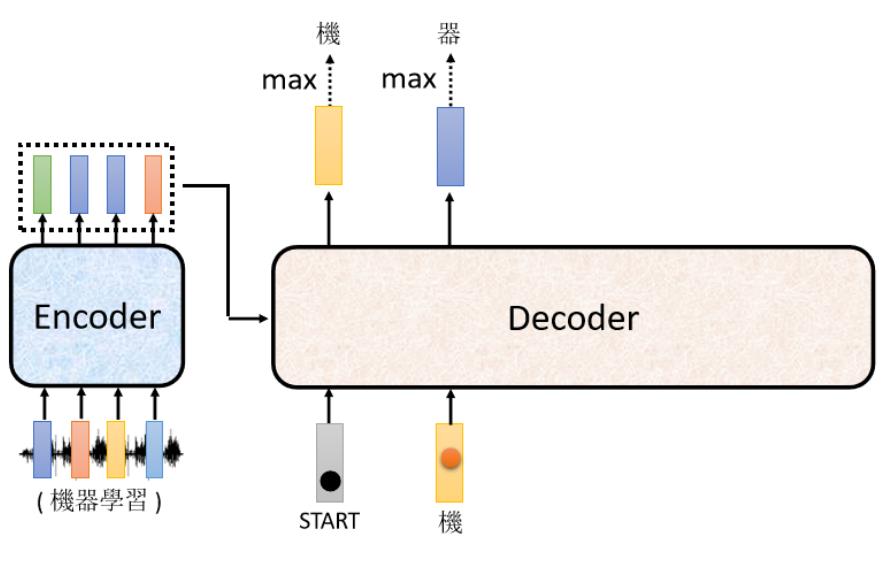
同理:根据这两个输入,它输出一个蓝色的向量,根据这个蓝色的向量里面,给每一个中文的字的分数,我们会决定第二个输出,哪一个字的分数最高,它就是输出,假设"器"的分数最高,"器"就是输出
最后,现在 Decode:
- 看到了 BEGIN
- 看到了"机"
- 看到了"器"
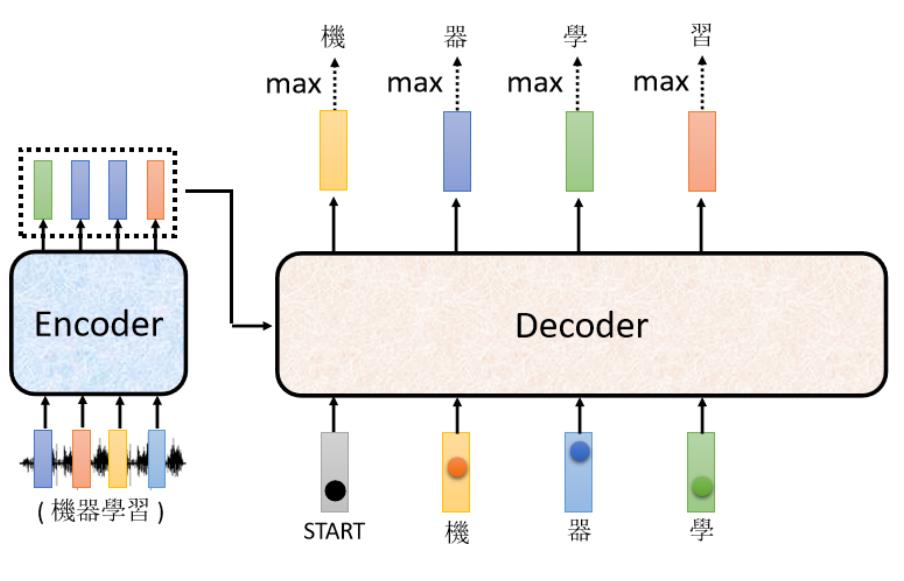
- 还有"学"
Encoder 这边其实也有输入,等一下再讲 Encoder 的输入,Decoder 是怎麼处理的,所以 Decoder 看到 Encoder 这边的输入,看到"机" 看到"器" 看到"学",决定接下来输出一个向量,这个向量里面"习"这个中文字的分数最高的,所以它就输出"习"
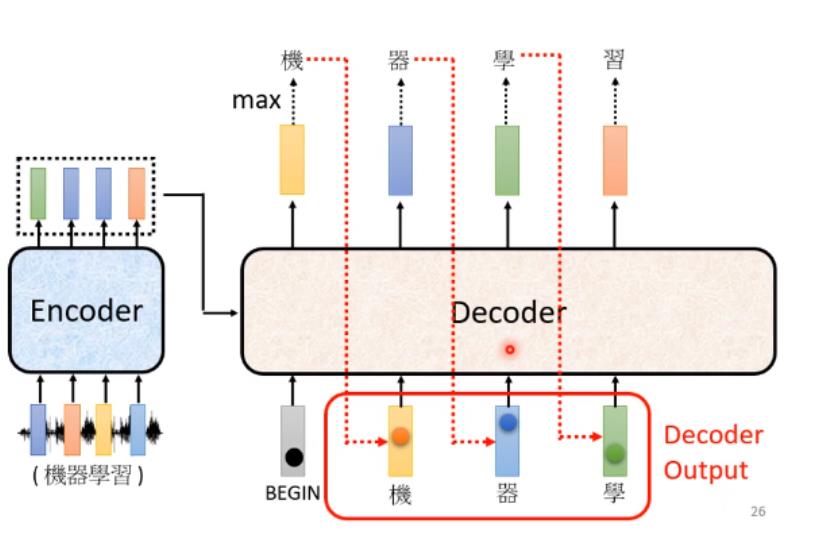
上面这个过程反复持续,其中有个关键之处(上图红色虚线),Decoder看到的输入起始是它在前一个时间点自己的输出。而如果Decoer看到错误的输入后,让Decoer看到自己错误的输入再被Decoder自己吃进去后,会不会造成Error Propagation(一步错步步错)问题?——是有可能的(后面会讲)。
Decoder内部结构
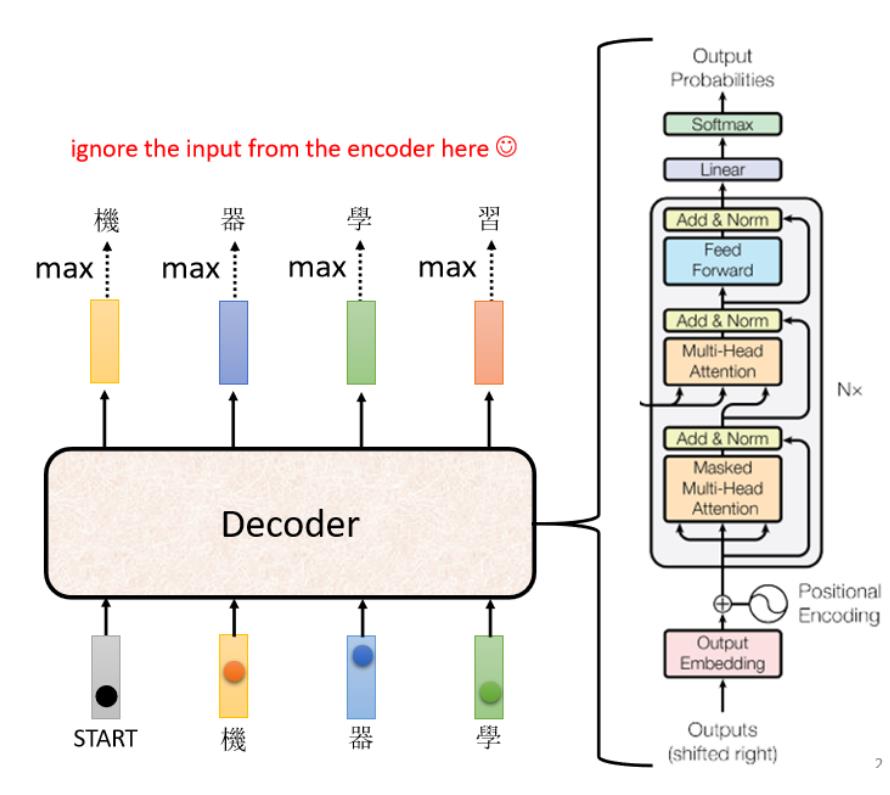
先省略Encoder部分,在transformer里面的Decoder结构如下图所示,比Encoder稍微复杂点:
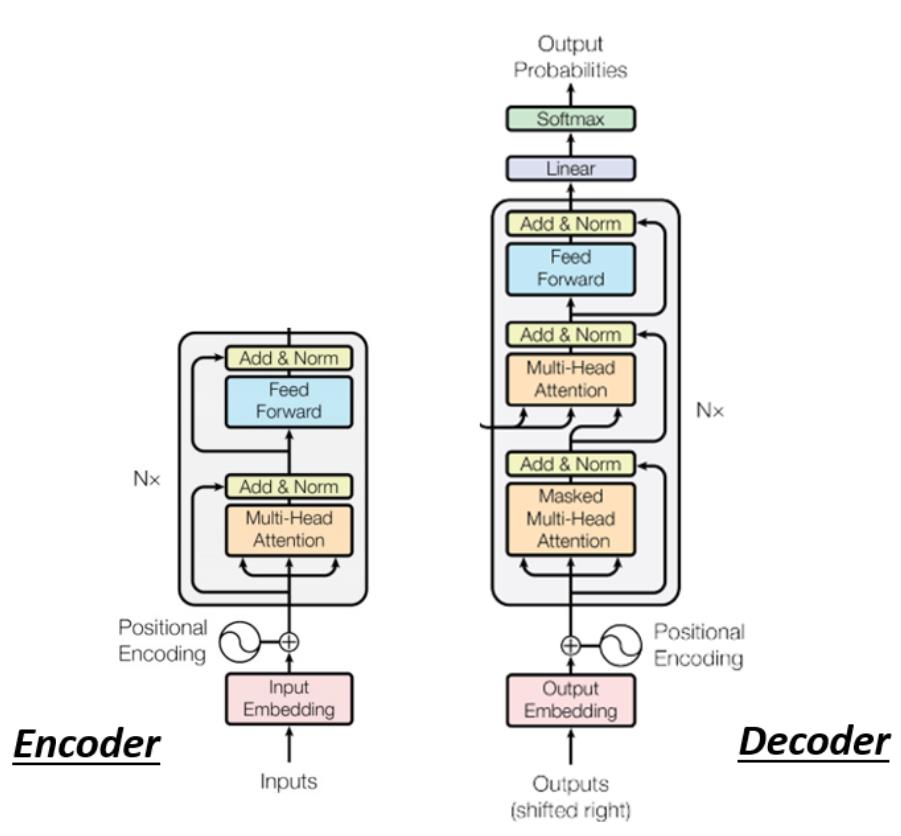
但是我们现在把Decoder中间的一块先盖起来,会发现Encoder和Decoder是差不多的(如下图)。两者都是先Multi-Head Attention,然后Add & Norm,再Feed Forward,Add & Norm,重复N次。只是最后可能会再做一个softmax,使得输出变成一个概率。
ps:注意有个地方不同,在Decoder的Multi-Head Attention这个Block上面还加了一个Masked。
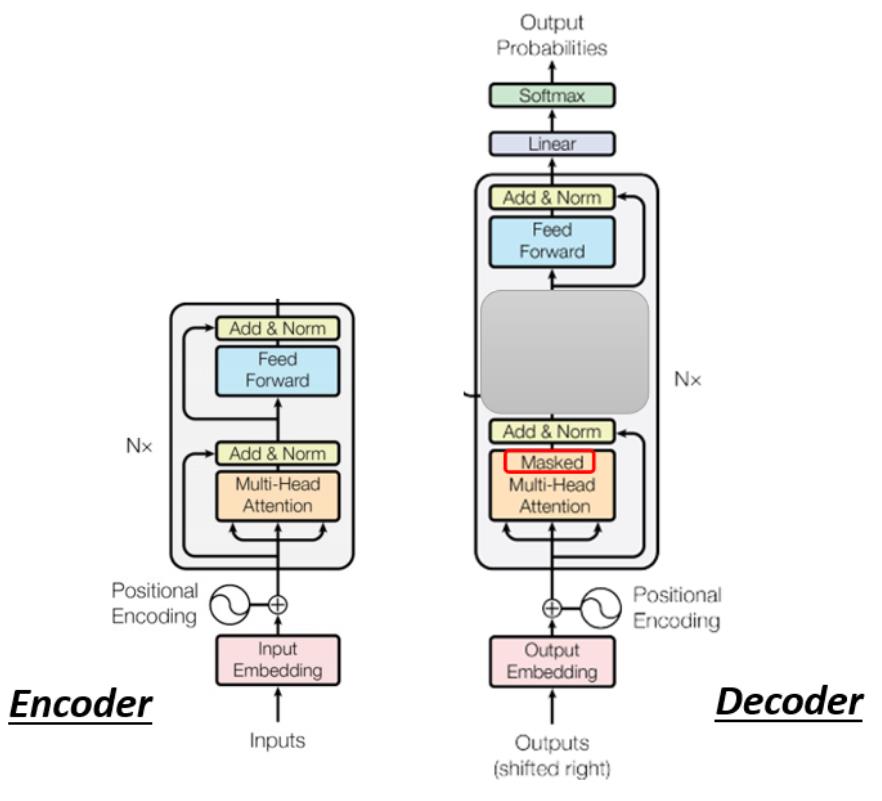
1)带Masked的MHA
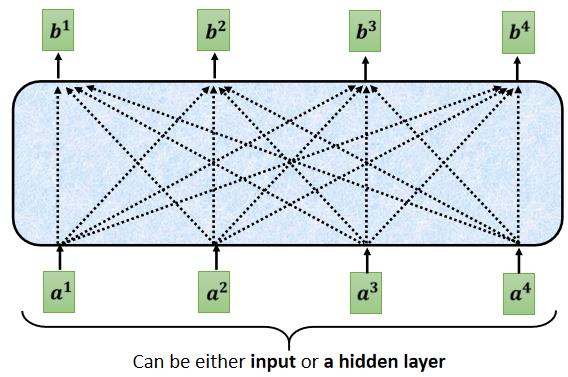
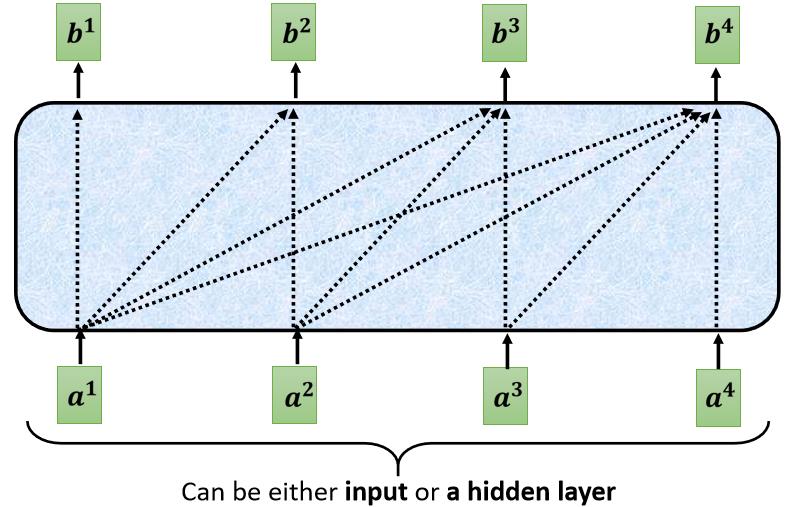
这个 Masked 的意思是这样子的,首先这是我们原来的 Self-Attention
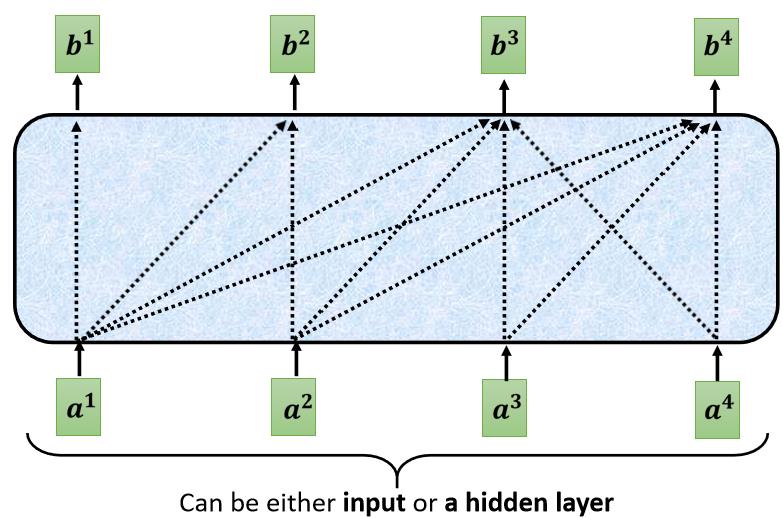
Input 一排 Vector,Output 另外一排 Vector,这一排 Vector 每一个输出,都要看过完整的 Input 以后,才做决定,所以输出 b 1 b^1 b1 的时候,其实是根据 a 1 a^1 a1 到 a 4 a^4 a4 所有的资讯,去输出 b 1 b^1 b1
当我们把 Self-Attention,转成 Masked Attention 的时候,它的不同点是,现在我们不能再看右边的部分,也就是產生 b 1 b^1 b1 的时候,我们只能考虑 a 1 a^1 a1 的资讯,你不能够再考虑 a 2 a^2 a2 a 3 a^3 a3 a 4 a^4 a4
產生 b 2 b^2 b2 的时候,你只能考虑 a 1 a^1 a1 a 2 a^2 a2 的资讯,不能再考虑 a 3 a^3 a3 a 4 a^4 a4 的资讯
產生 b 3 b^3 b3 的时候,你就不能考虑 a 4 a^4 a4 的资讯,
產生 b 4 b^4 b4 的时候,你可以用整个 Input Sequence 的资讯,这个就是 Masked 的 Self-Attention,
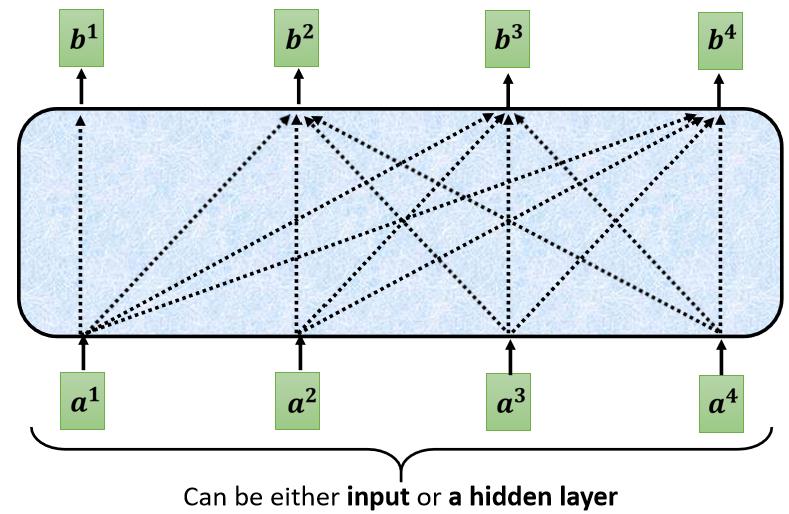
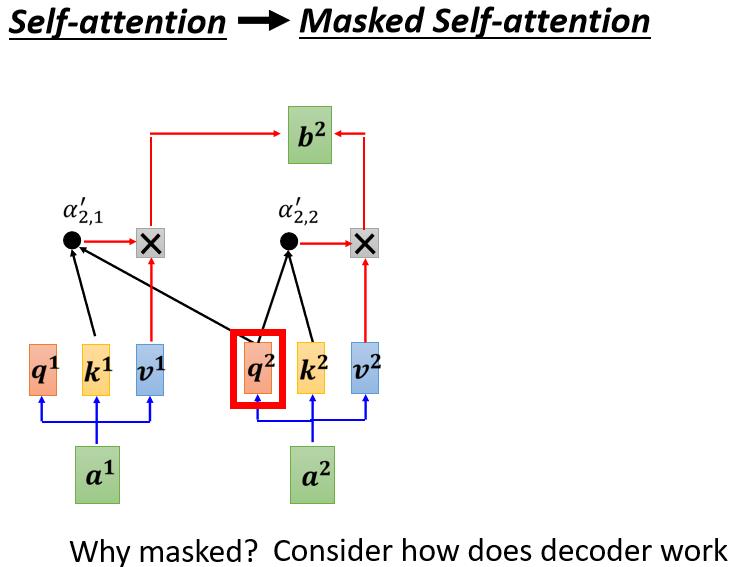
讲得更具体一点,你做的事情是,当我们要產生 b 2 b^2 b2 的时候,我们只拿第二个位置的 Query b 2 b^2 b2,去跟第一个位置的 Key,和第二个位置的 Key,去计算 Attention,第三个位置跟第四个位置,就不管它,不去计算 Attention
我们这样子不去管这个 a 2 a^2 a2 右边的地方,只考虑 a 1 a^1 a1 跟 a 2 a^2 a2,只考虑 q 1 q^1 q1 q 2 q^2 q2,只考虑 k 1 k^1 k1 k 2 k^2 k2, q 2 q^2 q2 只跟 k 1 k^1 k1 跟 k 2 k^2 k2 去计算 Attention,然后最后只计算 b 1 b^1 b1 跟 b 2 b^2 b2 的 Weighted Sum
然后当我们输出这个 b 2 b^2 b2 的时候, b 2 b^2 b2 就只考虑了 a 1 a^1 a1 跟 a 2 a^2 a2,就没有考虑到 a 3 a^3 a3 跟 a 4 a^4 a4
为什么需要加 Masked
这件事情其实非常地直觉:我们一开始 Decoder 的运作方式,它是一个一个输出,所以是先有 a 1 a^1 a1 再有 a 2 a^2 a2,再有 a 3 a^3 a3 再有 a 4 a^4 a4
这跟原来的 Self-Attention 不一样,原来的 Self-Attention, a 1 a^1 a1 跟 a 4 a^4 a4 是一次整个输进去你的 Model 裡面的,在我们讲 Encoder 的时候,Encoder 是一次把 a 1 a^1 a1 跟 a 4 a^4 a4,都整个都读进去
但是对 Decoder 而言,先有 a 1 a^1 a1 才有 a 2 a^2 a2,才有 a 3 a^3 a3 才有 a 4 a^4 a4,所以实际上,当你有 a 2 a^2 a2,你要计算 b 2 b^2 b2 的时候,你是没有 a 3 a^3 a3 跟 a 4 a^4 a4 的,所以你根本就没有办法把 a 3 a^3 a3 a 4 a^4 a4 考虑进来
所以这就是為什麼,在那个 Decoder 的那个图上面,Transformer 原始的 Paper 特别跟你强调说,那不是一个一般的 Attention,这是一个 Masked 的 Self-Attention,意思只是想要告诉你说,Decoder 它的 Token,它输出的东西是一个一个產生的,所以它只能考虑它左边的东西,它没有办法考虑它右边的东西
2)特殊符号END
Decoder 必须自己决定,输出的 Sequence 的长度。你没有办法轻易的从输入的 Sequence 的长度,就知道输出的 Sequence 的长度是多少,因为并不是说输入是 4 个向量,输出一定就是 4 个向量。按照我们介绍的流程不断重复,可能会一直像“推文接龙”游戏一样推出每个字然后不会
以上是关于李宏毅深度学习CP13Transformer(part2)的主要内容,如果未能解决你的问题,请参考以下文章