[机器学习] UFLDL笔记 - 反向传播算法(Backpropagation)
Posted WangBo_NLPR
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习] UFLDL笔记 - 反向传播算法(Backpropagation)相关的知识,希望对你有一定的参考价值。
前言
[机器学习] UFLDL笔记系列是以我学习UFLDL Tutorial(Andrew Ng老师主讲)时的笔记资料加以整理推出的。内容以无监督特征学习和深度学习为主,同时也参考了大量网上的相关资料。
本文主要整理自UFLDL的“Backpropagation”章节的笔记,结合笔者的一些心得对内容进行了补充,并纠正了几处错误。反向传播的本质是利用微分的链式法则高效计算梯度,是基于计算图的算法的优化的关键!网上有很多关于反向传播算法的资料,讲解都十分清晰透彻(文章末尾会给出资料链接),所以本文不再重复讲解,只针对UFLDL-Backpropagation中的例子进行补充完善,以便初学者更容易理解。
文章小节安排如下:
1)Example 1: Objective for weight matrix in sparse coding
2)Example 2: Smoothed topographic L1 sparsity penalty in sparse coding
3)Example 3: ICA reconstruction cost
4)结语
5)参考资料
一、Example 1: Objective for weight matrix in sparse coding
1.1 Objective Function
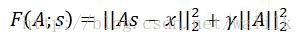
这里式子是Sparse Coding中的目标函数,第一项为重构项(reconstruction term),第二项是稀疏惩罚项(sparsity penalty term)。
我们简单复习一下,在这个式子中,A是由基向量组成的矩阵(一组超完备基):

s是系数向量:
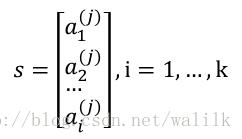
Sparse Coding的目标就是学习出 x 的一个高度拟合的近似表达式,具体来说就是找到一组超完备(over-complete bases)和一个系数向量,重构输入:
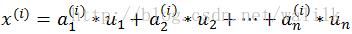
1.2 Computational Graph
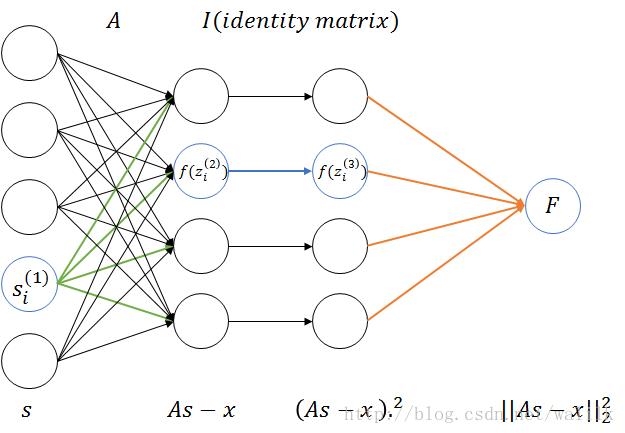
将目标函数的式子看作一个神经网络,就可以利用反向传播算法计算网络中任何一个结点的偏导数。
1.3 Activation Function
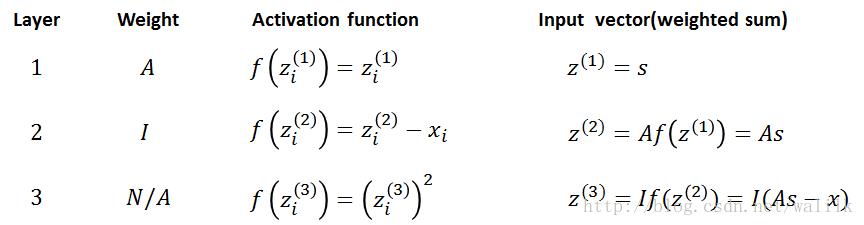
这里给出了激励函数和加权和z,其实神经网络的前馈计算也就是输入向量s、权重矩阵A、激励函数f三部分。
1.4 Delta

这里想强调的有两点,
第一,只要一个式子可以展开成神经网络的图结构,那么每一层神经节点的Delta和每一个权重矩阵的偏导数的计算形式就都是一致的;
第二,一定要学会向量化计算的技巧和思维方式。
1.5 Gradient
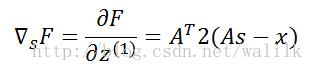
二、Example 2: Smoothed topographic L1 sparsity penalty in sparse coding
2.1 Objective Function
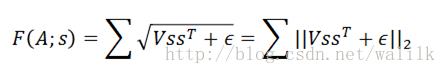
这里式子是Topographic Sparse Coding中目标函数的L2 sparsity penalty(UFLDL中说是L1是不对的),其中V是分组矩阵,s是系数向量(也就是最后学习到的特征向量),该惩罚项的目的是希望学习得到一组有某种“秩序(orderly)”的特征集,也就是希望相邻的特征(adjacent features)是相似的。
不过我觉得这个式子不太对,因为在惩罚项中,第一步应该计算的是s各项的平方,所以这样写更合适:
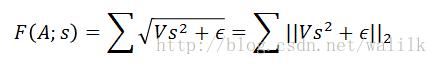
2.2 Computational Graph
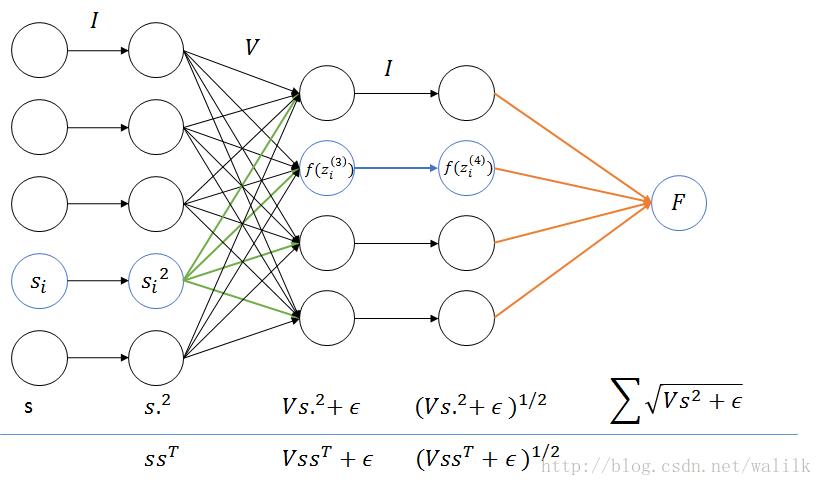
UFLDL中的计算图将第二个隐层的计算标注为ss T并不恰当,其实是s中各项的平方。
2.3 Activation Function

我们将第一层的激励函数看作是f(x)=x,第二层的激励函数看作是f(x)=x^2。
注意,UFLDL中的表把layer1和layer2写反了。
2.4 Delta

2.5 Gradient
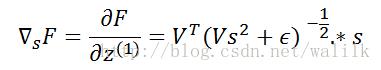
三、Example 3: ICA reconstruction cost
1.1 Objective Function
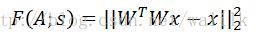
这里式子是ICA(Independent Component Analysis)中目标函数的重构项(reconstruction term),其中W是权重矩阵,x是输入向量。
2.2 Computational Graph
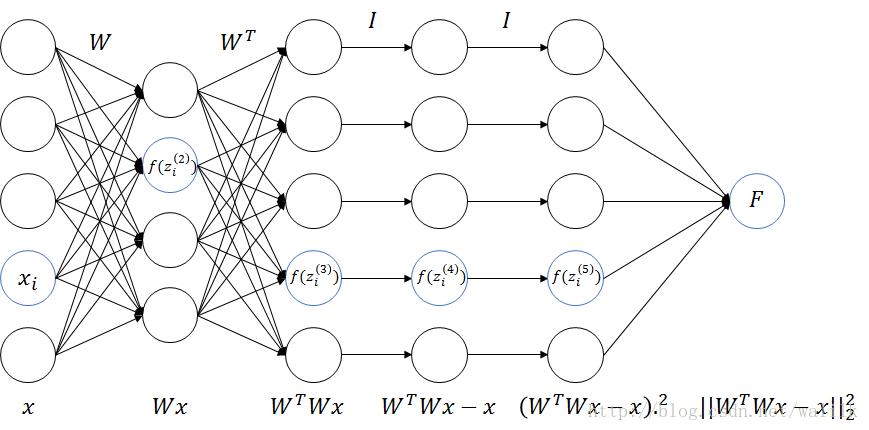
2.3 Activation Function

注意,将上述目标函数看作是一个神经网络,应该是有5个Layer,4个Weight matrix,但UFLDL中只写了4个Layer,似乎是不对的。
2.4 Delta

2.5 Gradient
计算F关于W的梯度,首先计算F对网络中每个W的梯度,再将其相加求和,即可得到F关于W的最终梯度。注意,关于W^T的梯度需要进行转置来得到关于W的梯度。
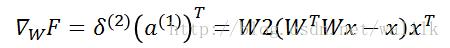
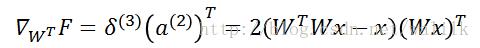
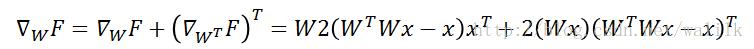
注意,UFLDL中F关于W的梯度计算不对,结果式子中第一个W不应该有转置符号。
结语
反向传播算法是复杂目标函数求梯度的利器,也是神经网络研究中必备的基础技术,一方面,我们要掌握反向传播算法的数学推导,另一方面,我们也要熟悉如何编程实现反向传播算法,尤其要掌握向量化计算的思维方式。
参考资料
Calculus on Computational Graphs: Backpropagation
http://colah.github.io/posts/2015-08-Backprop/
BackPropagation : a collection of notes, tutorials, demo, and codes
https://algorithmsdatascience.quora.com/BackPropagation-a-collection-of-notes-tutorials-demo-and-codes
NotesonBackpropagation
https://www.ics.uci.edu/~pjsadows/notes.pdf
Deriving gradients using the backpropagation idea
http://deeplearning.stanford.edu/wiki/index.php/Deriving_gradients_using_the_backpropagation_idea
CS231n: Convolutional Neural Networks for Visual Recognition - backprop notes
http://cs231n.github.io/optimization-2/
Principles of training multi-layer neural network using backpropagation
http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html
以上是关于[机器学习] UFLDL笔记 - 反向传播算法(Backpropagation)的主要内容,如果未能解决你的问题,请参考以下文章
[机器学习] UFLDL笔记 - Convolutional Neural Network - 反向传播与梯度计算
[机器学习] UFLDL笔记 - Convolutional Neural Network - 反向传播与梯度计算
[机器学习] UFLDL笔记 - Convolutional Neural Network - 矩阵运算