备战数学建模30-回归分析2
Posted nuist__NJUPT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了备战数学建模30-回归分析2相关的知识,希望对你有一定的参考价值。
目录
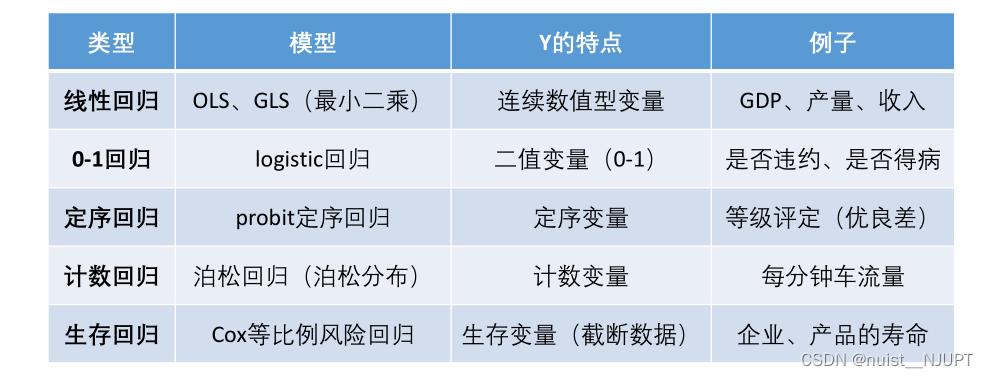
一、回归分析的使命
回归分析的三个使命如下:第一、识别重要变量,可以用逐步回归;第二,判断相关性方向,即正相关还是负相关;第三,估计权重,即计算回归系数。

二、回归分析的分类
创建的回归分析分为如下几类,我们主要考虑的还是线性回归,非线性也可以学习。
当然所说的线性不是严格意义上的线性,如下通过变量替换可以转换成线性的,我们都可以理解为线性,其实严格来说就是非线性转线性了。

三、数据的分类及处理方法
我们需要考虑数据的分类,一般对于横截面数据,我们使用回归分析;
横截面数据:在某一时点收集的不同对象的数据,例如:全国各省份2018年GDP的数据
时间序列数据:对同一对象在不同时间连续观察所取得的数据,例如:中国历年来GDP
横截面数据与时间序列数据综合起来的一种数据资源,例如:2008‐2018年,我国各省份GDP的数据。

四、回归系数的解释
我们对回归方程进行点估计,求出回归系数后,需要对回归系数进行解释,其实就是解释自变量和因变量之间的关系,其实你会发现自变量的个数不同,对回归系数影响是比较大的,也就是说对于核心的解释变量我们需要当作自变量,我们需要使核心解释变量和扰动项无关
我们让误差项和所有的自变量x均不相关,使得模型具有外生性,如果相关,就会存在内生性,导致回归系数的估计值不准确。
我们要使得回归模型无内生性,一般要求解释变量与扰动项无关,但是往往解释变量比较多,我们只考虑价格核心解释变量与扰动项无关即可,不需要考虑所有的解释变量。
有些时候,我们可以对自变量和因变量取对数,取对数有如下三点好处,




五、特殊变量的处理
对于定量变量,一般可以直接回归,对于定性变量,如性别,地域,没有具体的数字,我们需要怎么处理呢,这就需要考虑虚拟变量的问题。
假如研究性别对于工资的影响,如下所示:
我们需要对虚拟变量进行解释,系数可以理解为差异,即再其它自变量都相同的情况下,从平均来看,女性每小时比男性要少挣1.81美元。


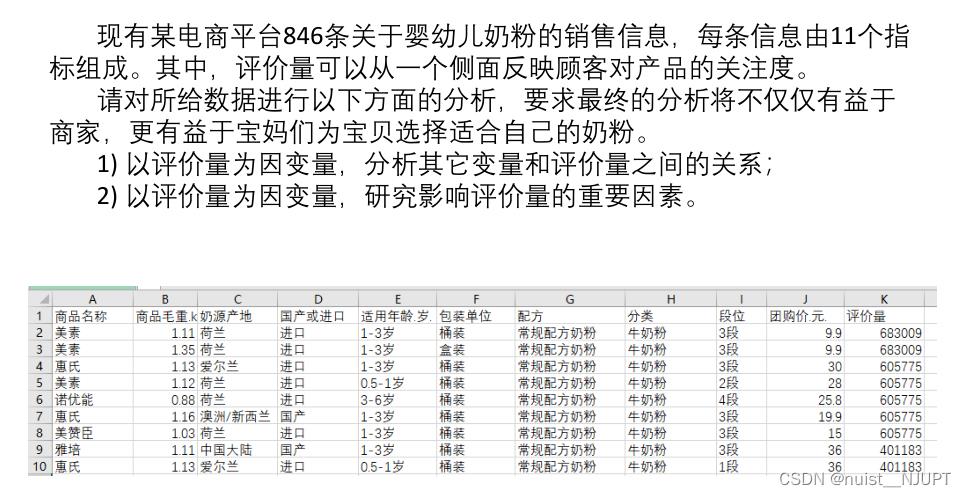
六、回归分析案例
下面的回归分析案例是对回归模型进行解释,一般回归方程用于解释或者预测,此处主要用于解释,另外本题是使用stata软件实现的。
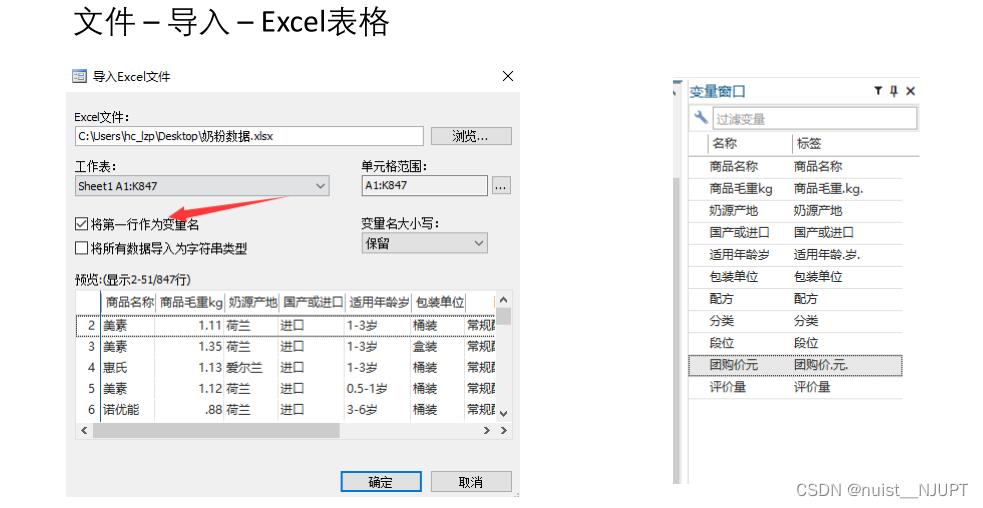
首先将excel中的数据导入stata,具体如下:
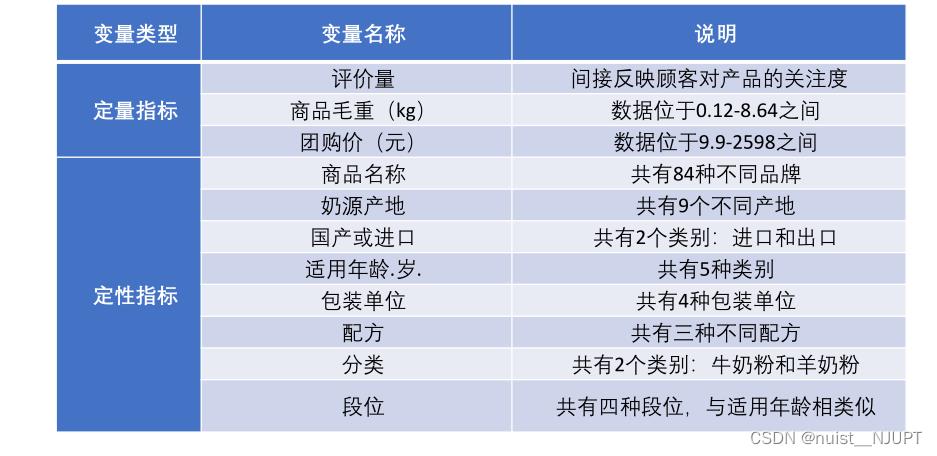
在进行回归之前一般需要进行描述性统计,就是对表中的数据信息进行描述统计,具体如下:我们先将题目中的数据分为定量数据和定性数据,具体如下:
对于定量数据,stata的描述统计方法如下,就是summarize加变量的形式。
对于定性变量,我们想要得到对应变量的频率分布表,并生成对应的虚拟变量,具体如下所示,在命令窗口,使用tabulate即可。
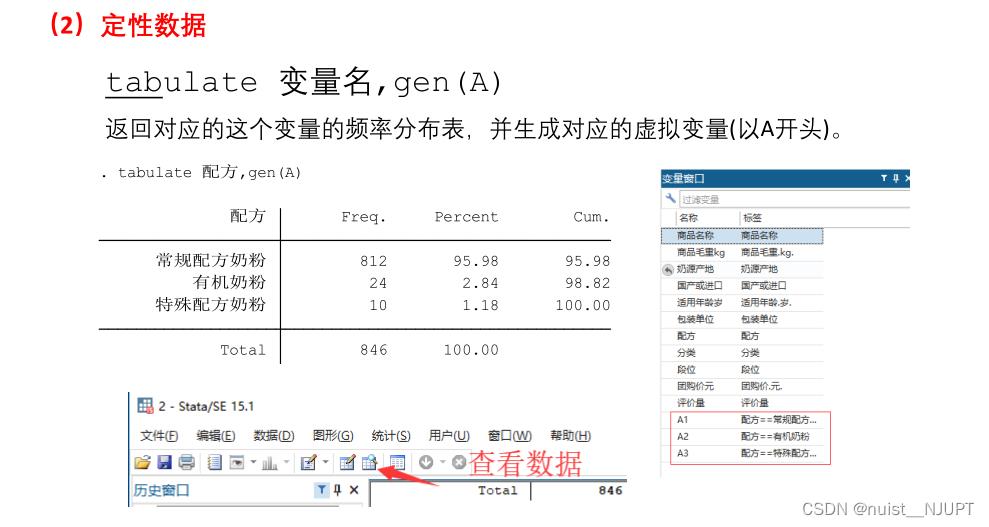
下面我们需要进行建立回归方程,并进行回归分析,stata的回归语句如下所示:,p值小于0.05,拒绝原假设,认为回归莫模型成立。coef是回归系数。
对于定量数据直接使用regress语句进行回归就可以,对于定性的语句,我们需要添加虚拟变量后,再进行回归,这样第一问就解决了,具体如下:
我们观察一下,p约等于0,可以拒绝原假设,说明回归方程整体显著,会发现只有两个变量是显著的,所有就用两个自变量解释评价量。
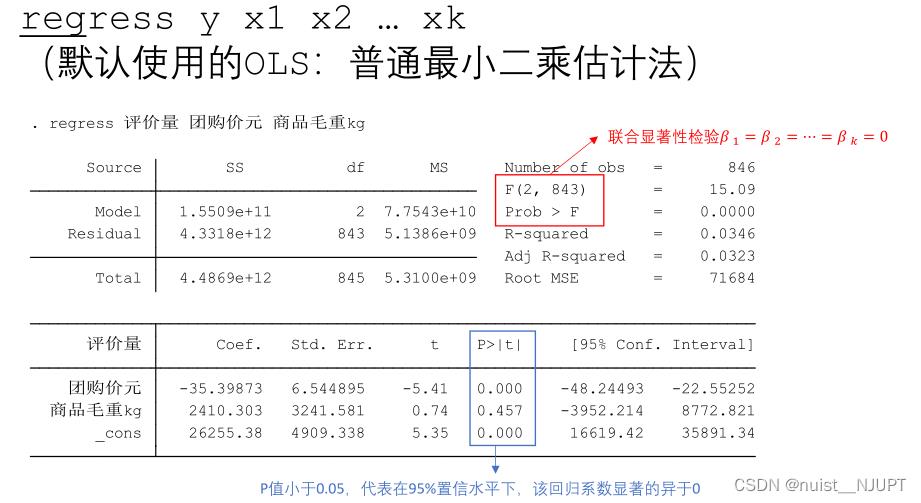

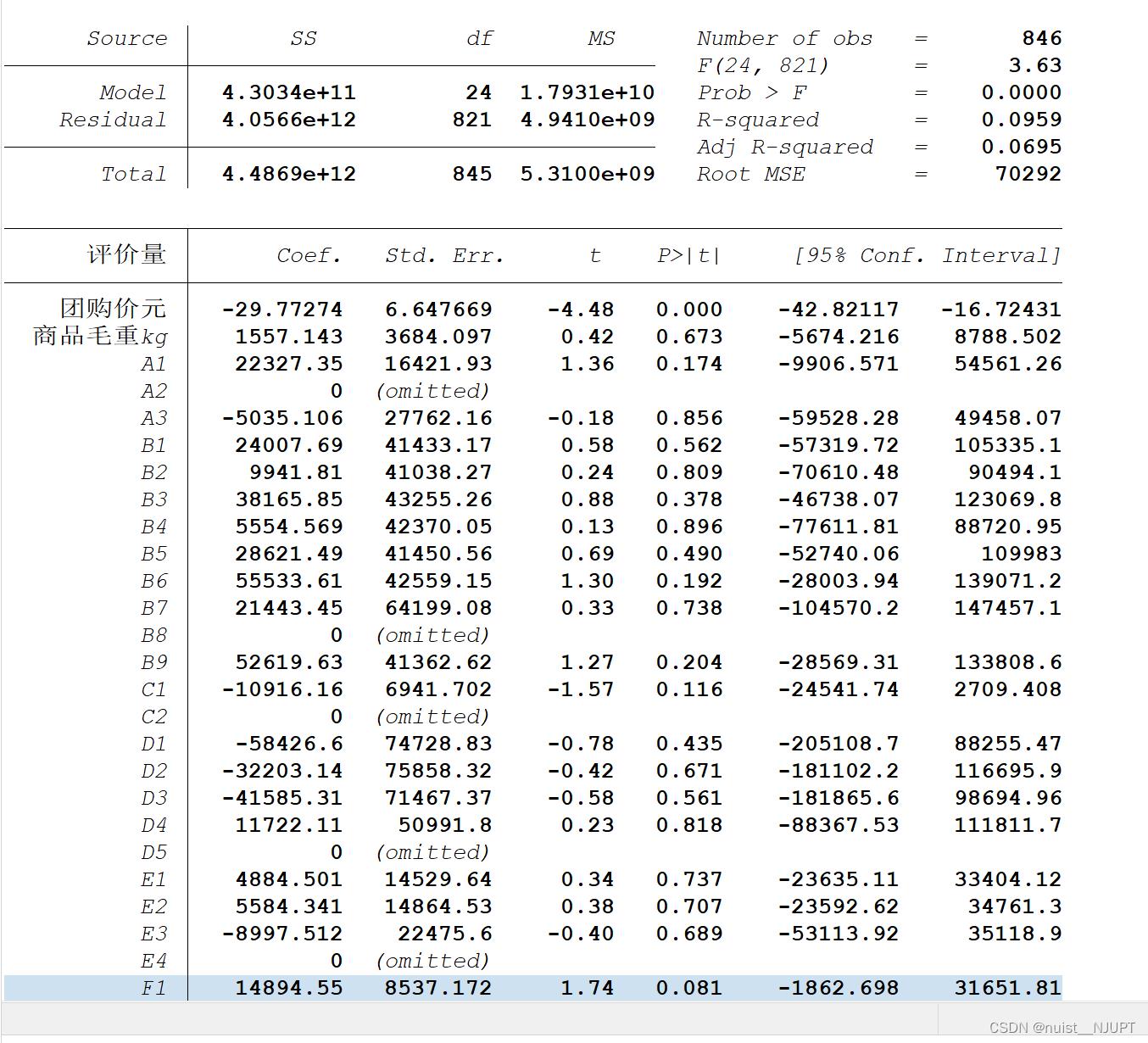
进行回归分析,我们通常需要考虑拟合优度问题,一般对于解释型回归,不太看重拟合优度,预测回归更看重拟合优度。对于回归模型,我们更希望使用调整后的拟合优度。

对于第2问,研究评价量的重要因素,我们可以使用标准化回归,将原始数据标准化后,用标准化后的数据建立回归方程,回归系数的绝对值越大,则说明对评价量的影响越大。

对于扰动项,需要满足同方差和无自相关性两个条件,所以需要进行异方差检验。
同方差:扰动项的方差值相同,任意两个扰动项的相关性为0。
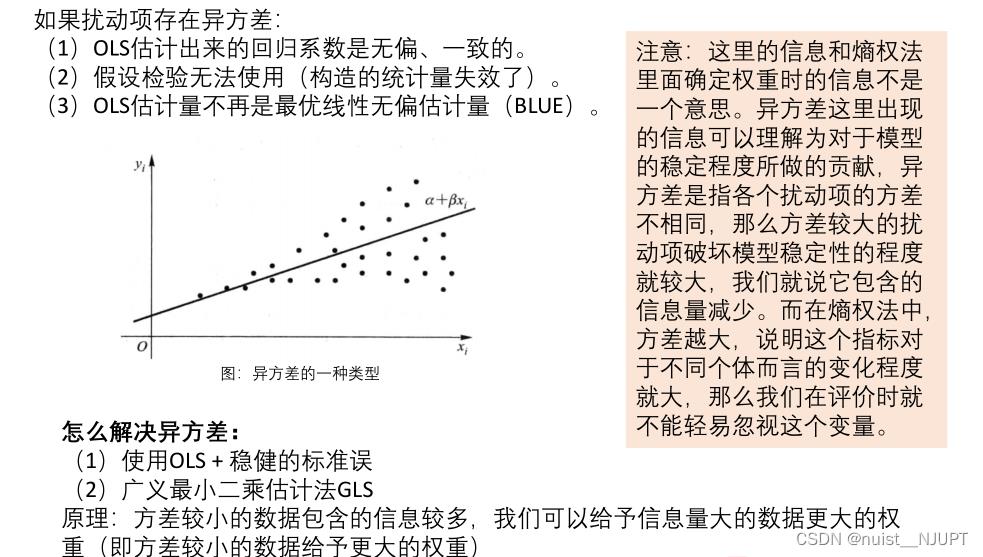
如果扰动项出现异方差,则会导致假设检验无法使用,且普通最小二乘不再是最优线性无偏估计。
我们可以使用stata中的命令绘制散点图,推测扰动项是否存在异方差。当拟合值很小,数据无波动,当数据较大的时候,数据的波动较大。团购价很小的时候,数据波动大,后面的话,波动小,故推测存在异方差。
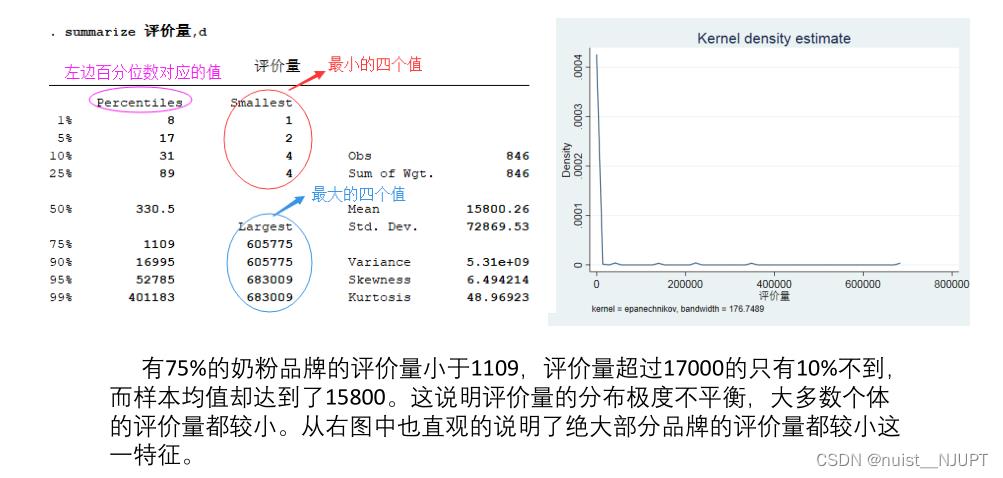
其实我们发现拟合值出现了负数的情况,可以绘制概率密度函数图,可以发现评价量的分布是不均匀的,使用summarize指令可以得到评价量的描述统计;因为评价量分布不均匀导致拟合优度较小,拟合值出现负数,具体分析如下:
图形进行异方差检验比较粗糙,我们使用异方差的假设检验,主要两种:BP检验和怀特检验两种。我们看一下:
我们发现P值小于0.05,拒绝原假设,说明存在异方差。
下面看一下怀特检验,拒绝原假设,则存在异方差,反正,不存在异方差。
如果出现异方差,我们使用第1种方法解决异方差问题,





对于可能出现多重共线性问题,我们一般采用逐步回归解决,如果解释变量之间线性相关,则说明存在多重共线性问题,多重工共线性将会导致系数估计不合理,甚至与预期的符号相反等问题。
我们一般使用方差膨胀因子去检验多重工共线性,认为VIF大于10,则说明该回归方程存在严重的多重共线性。
对于出现多重共线性问题,我们一般采取以下处理方法,如果使用方程进行预测,则不需要考虑多重共共线性问题。另外虽然关系具体的回归系数,但是多重共线性不影响所关心变量的显著性,也不需要考虑,仅当多重共线性影响了所考虑的变量的显著性才考虑使用逐步回归。
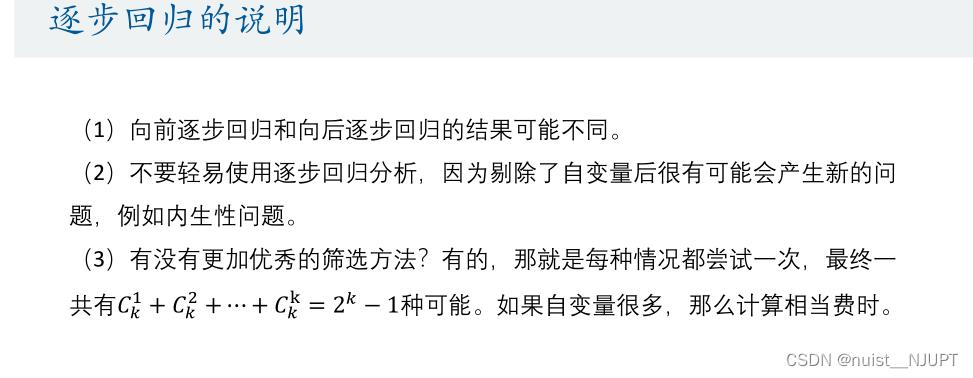
对于逐步回归,我们可以考虑使用先前逐步回归或者向后逐步回归,具体如下:
stata实现逐步回归的语句如下所示:
两种逐步回归的结果可能不同,且需要注意的是进行逐步回归需要提前提出完全多重共线性的变量,否则会报错,普通的回归,则不需要手动剔除,stata会自动剔除。





stata源码如下所示,除了进行回归,也进行了残差分析和异方差检验等。
clear
// 清屏 和 matlab的clc类似
cls
// 导入数据(其实是我们直接在界面上粘贴过来的,我们用鼠标点界面导入更方便 本条请删除后再复制到论文中,如果评委老师看到了就知道这不是你写的了)
// import excel "C:\\Users\\hc_lzp\\Desktop\\数学建模视频录制\\第7讲.多元回归分析\\代码和例题数据\\课堂中讲解的奶粉数据.xlsx", sheet("Sheet1") firstrow
import excel "C:\\Users\\nuist__NJUPT\\Desktop\\数模算法源码-王国栋\\回归分析\\课堂中讲解的奶粉数据.xlsx", sheet("Sheet1") firstrow
// 定量变量的描述性统计
summarize 团购价元 评价量 商品毛重kg
// 定性变量的频数分布,并得到相应字母开头的虚拟变量
tabulate 配方,gen(A)
tabulate 奶源产地 ,gen(B)
tabulate 国产或进口 ,gen(C)
tabulate 适用年龄岁 ,gen(D)
tabulate 包装单位 ,gen(E)
tabulate 分类 ,gen(F)
tabulate 段位 ,gen(G)
// 下面进行回归
regress 评价量 团购价元 商品毛重kg
// 下面的语句可帮助我们把回归结果保存在Word文档中
// 在使用之前需要运行下面这个代码来安装下这个功能包(运行一次之后就可以注释掉了)
//ssc install reg2docx, all replace
// 如果安装出现connection timed out的错误,可以尝试换成手机热点联网,如果手机热点也不能下载,就不用这个命令吧,可以自己做一个回归结果表,如果觉得麻烦就直接把回归结果截图。
est store m1
reg2docx m1 using m1.docx, replace
// *** p<0.01 ** p<0.05 * p<0.1
// Stata会自动剔除多重共线性的变量
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4
est store m2
reg2docx m2 using m2.docx, replace
// 得到标准化回归系数
regress 评价量 团购价元 商品毛重kg, b
// 画出残差图
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4
rvfplot
// 残差与拟合值的散点图
graph export a1.png ,replace
// 残差与自变量团购价的散点图
rvpplot 团购价元
graph export a2.png ,replace
// 为什么评价量的拟合值会出现负数?
// 描述性统计并给出分位数对应的数值
summarize 评价量,d
// 作评价量的概率密度估计图
kdensity 评价量
graph export a3.png ,replace
// 异方差BP检验
estat hettest ,rhs iid
// 异方差怀特检验
estat imtest,white
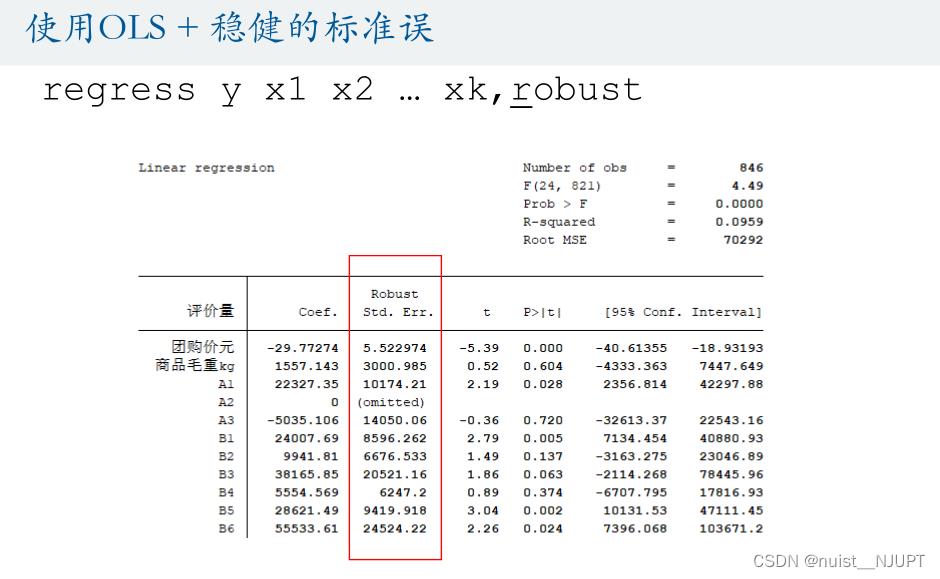
// 使用OLS + 稳健的标准误
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4, r
est store m3
reg2docx m3 using m3.docx, replace
// 计算VIF
estat vif
// 逐步回归(一定要注意完全多重共线性的影响)
// 向前逐步回归(后面的r表示稳健的标准误)
stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r pe(0.05)
// 向后逐步回归(后面的r表示稳健的标准误)
stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r pr(0.05)
// 向后逐步回归的同时使用标准化回归系数(在r后面跟上一个b即可)
stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r b pr(0.05)
// 补充语法 (大家不需要具体的去学Stata软件,掌握我课堂上教给大家的一些命令应对数学建模比赛就可以啦)
// 事实上大家学好Excel,学好后应对90%的数据预处理问题都能解决
// (1) 用已知变量生成新的变量
generate lny = log(评价量)
generate price_square = 团购价元 ^2
generate interaction_term = 团购价元*商品毛重kg
// (2) 修改变量名称,因为用中文命名变量名称有时候可能容易出现未知Bug
rename 团购价元 price
以上是关于备战数学建模30-回归分析2的主要内容,如果未能解决你的问题,请参考以下文章