解开Kafka神秘的面纱:kafka单机部署和集群部署
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解开Kafka神秘的面纱:kafka单机部署和集群部署相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
本文主要介绍kafka的单机和集群模式部署。
二、kafka单机安装
2.1 下载压缩包
需要先到官网下载zookeeper和kafka压缩包,先下载zookeeper,如下


然后进入kafka官网下载,如下图:

下载到本地

2.2 zookeeper安装
第一步:使用FileZilla或者xftp可以通过ftp将zookeeper压缩包上传到 192.168.100.120 机器,解压,进入到 conf 目录,看到 zoo_sample.cfg 文件,cp 复制生成 zoo.cfg 文件,如下:

第二步,启动并查看状态
启动zookeeper
./bin/zkServer.sh start
查看zookeeper状态
./bin/zkServer.sh status

standalone代表单机启动,后面讲解集群启动
2.3 kafka安装
第一步:使用FileZilla或者xftp可以通过ftp将kafka压缩包上传到 192.168.100.120 机器,解压,进入到 conf 目录,看到config/server.properties 文件,并做如下修改

第二步:启动kafka
./bin/kafka-server-start.sh config/server.properties &

第三步:新建topic并查看状态
./bin/kafka-topics.sh --create --topic test2 --bootstrap-server 192.168.100.120:9092
--partitions 1 --replication-factor 1
./bin/kafka-topics.sh --describe --topic test2 --bootstrap-server 192.168.100.120:9092

然后zoo.cfg指定的目录就有了topic了

第五步:生产消息和消费消息
# 生产消息
./bin/kafka-console-producer.sh --bootstrap-server 192.168.100.120:9092 --topic test2
# 消费消息
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.100.120:9092 --topic test2 --from-beginning
生产的消息被消费了

三、kafka集群安装
同时准备好三个虚拟机, 我这里192.168.100.136、192.168.100.137、192.168.100.138,下面无论是zookeeper还是kafka,我们都先对136操作,然后配置文件复制到137、138上面去,改一改就好了。
3.1 zookeeper安装
第一步:使用FileZilla或者xftp可以通过ftp将zookeeper压缩包上传到192.168.100.136机器,解压,进入到 conf 目录,看到 zoo_sample.cfg 文件,cp 复制生成 zoo.cfg 文件,如下:
第二步,在192.168.100.136机器上,修改zoo.cfg,如下:
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/logs
server.1=192.168.100.136:8880:7770
server.2=192.168.100.137:8880:7770
server.3=192.168.100.138:8880:7770
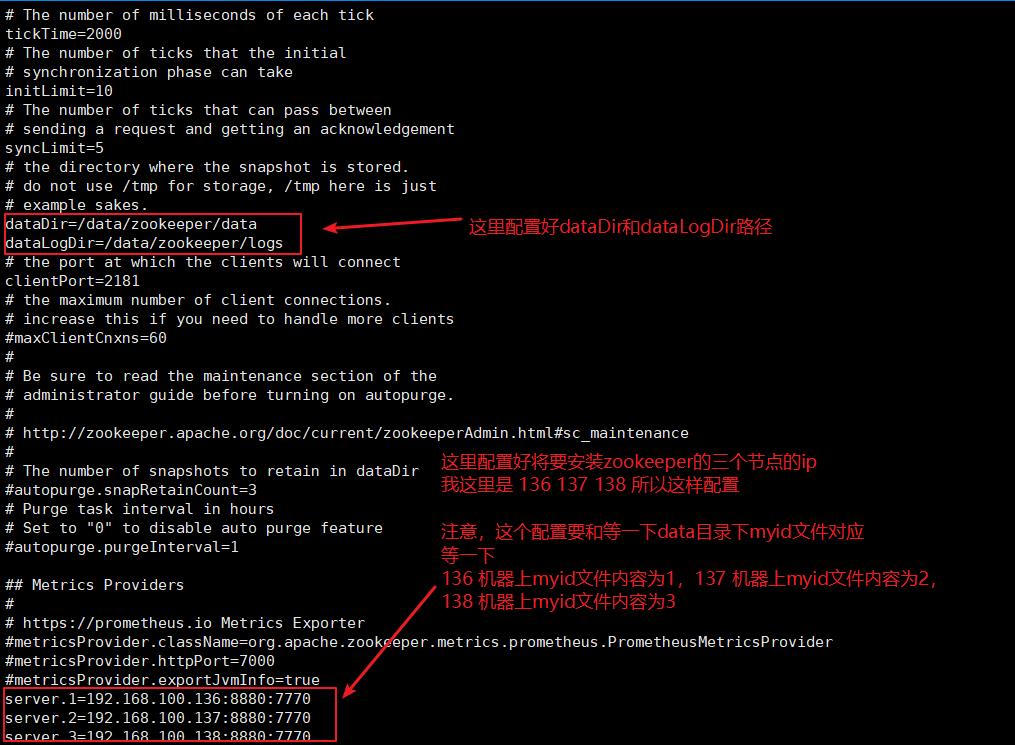
第三步:在192.168.100.136机器上,新建 /data/zookeeper/data 和 /data/zookeeper/logs 目录,因为 zoo.cfg 配置文件中指定了这两个目录,所以需要新建出来。

第四步:将 zoo.cfg 复制到另外两个节点192.168.10.137、192.168.100.138上,并在这两个机器上新建 /data/zookeeper/data 和 /data/zookeeper/logs 目录。
第五步:分别在三个节点的 dataDir (即/data/zookeeper/data) 目录下创建myid文件,内容为:
第一个节点 192.168.100.136 为 1,
第二个节点 192.168.100.137 为 2,
第三个节点 192.168.100.138 为 3。
注意:myid文件里的值是和刚才zoo.cfg文件配置的server.1 server.2 server.3 对应的,第一台服务器就是 192.168.100.136,第二台服务器就是 192.168.100.137,第三台服务器就是 192.168.100.138。
第六步:三台机器上,启动zookeeper,并查看zookeeper状态,确定zookeeper启动是否正常
启动zookeeper
./bin/zkServer.sh start
查看zookeeper状态
./bin/zkServer.sh status
注意,zk三个命令
停止: ./bin/zkServer.sh stop
启动: ./bin/zkServer.sh start
查看状态:./bin/zkServer.sh status
如果是启动第一个节点,查看状态如下,没关系,这是因为才启动一个节点,还没有形成集群的原因,用 ps -ef|grep zookeeper 可以看到进程启动了就行了。

只要看到启动了就好了
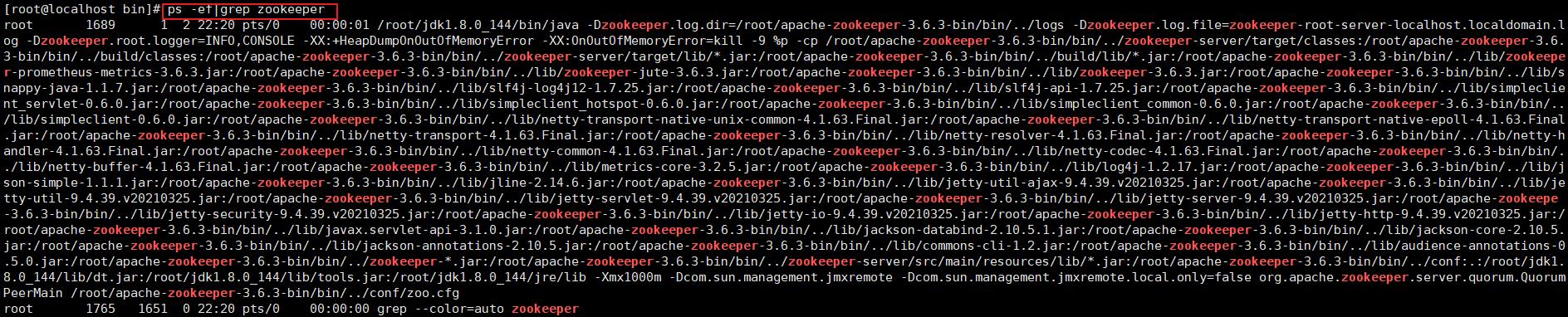
三个节点zookeeper均启动之后,如下:

eg1: zookeeper的注册中心和配置中心只是zk分布式协调的两个功能而已,主要协调数据一致性;
eg2: zookeeper集群只能部署奇数个节点(2n+1)个节点,避免选主失败;
eg3: kafka生产消息不需要依赖zookeeper,只有消费消息的时候,需要zookeeper用来记录offset。
3.2 kafka的安装
第一步:使用FileZilla或者xftp可以通过ftp将kafka压缩包上传到 192.168.100.136 机器,解压,进入到 conf 目录,看到config/server.properties 文件,并做如下修改
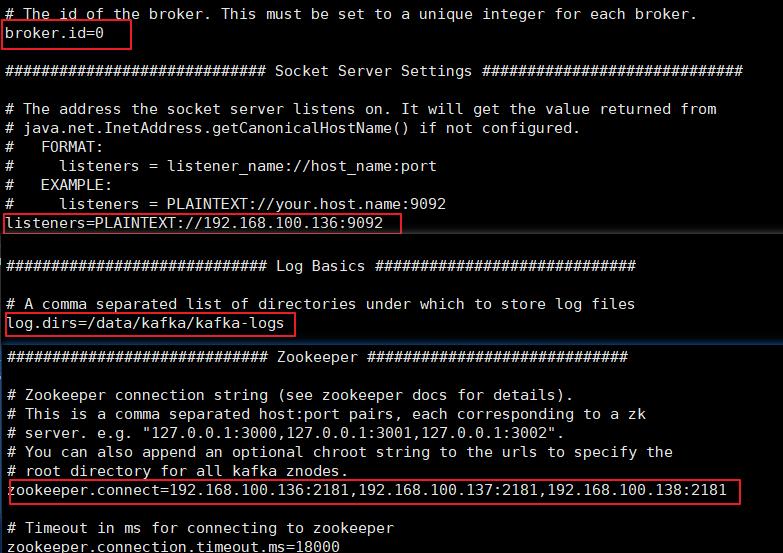
broker.id=0
listeners=PLAINTEXT://192.168.100.136:9092
log.dirs=/data/kafka/kafka-logs
zookeeper.connect=192.168.100.136:2181,192.168.100.137:2181,192.168.100.138:2181
同理,使用FileZilla或者xftp可以通过ftp将kafka压缩包上传到 192.168.100.137 机器,解压,进入到 conf 目录,看到config/server.properties 文件,并做如下修改
broker.id=1
listeners=PLAINTEXT://192.168.100.137:9092
log.dirs=/data/kafka/kafka-logs
zookeeper.connect=192.168.100.136:2181,192.168.100.137:2181,192.168.100.138:2181
注意:这里的 broker.id 和 listeners 这两个需要修改,log.dirs 和 zookeeper.connect 不需要改变,三个节点 broker.id 不能重复,哪个机器配哪个broker.id,就和 zoo.cfg 文件保持一致即可,listener 这里配置自己的ip地址。
继续,使用FileZilla或者xftp可以通过ftp将kafka压缩包上传到 192.168.100.138 机器,解压,进入到 conf 目录,看到config/server.properties 文件,并做如下修改
broker.id=2
listeners=PLAINTEXT://192.168.100.138:9092
log.dirs=/data/kafka/kafka-logs
zookeeper.connect=192.168.100.136:2181,192.168.100.137:2181,192.168.100.138:2181
也是 broker.id 和 listeners 需要改变,log.dirs 和 zookeeper.connect 不需要改变。
第二步:三个节点kafka启动
在 192.168.100.136、192.168.100.137、192.168.100.138 三个机器上,分别运行这句
./bin/kafka-server-start.sh config/server.properties &
额外注意:有的时候,zookeeper或kafka启动会失败,这个一般是zk日志中有老数据,删掉各个节点 /data/zookeeper/data 和 /data/zookeeper/logs 就好,一般只要 zookeeper 不出问题,kafka启动是不会出问题的。
第三步:创建topic(默认需要手动创建,可以修改配置文件让kafka自动创建不存在的topic)
创建一个名称为 test2 的 topic ,指定 test topic有一个分区,一个副本。
./bin/kafka-topics.sh --create --topic test2 --bootstrap-server 192.168.100.137:9092 --partitions 1 --replication-factor 1
注意理解一下分区数和副本数的意思:因为这个topic只设置存放一个分区,且每个分区一个副本,所以 1 * 1 = 1 ,分区名称就是 test2-0,如果是三个分区,每个分区三个副本,所以 3 *3 = 9 个,如图:
查看topic信息
./bin/kafka-topics.sh --describe --topic test2 --bootstrap-server 192.168.100.137:9092


额外注意: kafka 中 topic 的概念类似rabbitmq 中 exchage 的概念。不同的是,rabbitmq中,消息存在在queue队列中,生产者生产消息的时候,如果没有这个exchange,会自己创建一个并发送消息到rabbitmq,经过exchange中转到queue队列中;但是,kafka中,生产者生产消息的时候,如果没有这个topic,不会自己创建一个并完成发送消息到kafka的partition中,而是会直接报错,所以,需要先创建topic,再发送消息。
第四步:发送消息,用kafka自带的命名模拟消息发送
./bin/kafka-console-producer.sh --bootstrap-server 192.168.100.137:9092 --topic test2
第五步:消费消息,用kafka自带的命名模拟消息消费
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.100.136:9092 --topic test2 --from-beginning

生产消息和消费消息都是需要指定topic的;
消费消息还需要指定从头开始消费还是从尾开始消费,指定参数–from-beginning从头开始.
eg: 消费位置也可以通过auto.offset.reset 参数来指定,如下:
(1) earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费。
(2) latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据。
(3) none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常。
小结:kafka常见
./bin/kafka-server-start.sh 启动
./bin/kafka-server-stop.sh 停止
./bin/kafka-topics.sh topic创建与查看状态
./bin/kafka-console-producer.sh 生产
sh./bin/kafka-console-consumer.sh 消费
3.3 两种Topic
除了程序员自己手动用命令创建的topic,kafka中还有一种topic。
第一次消费topic的时候,kafka会默认创建一个名为__consumer_offsets的topic,这个topic有50个partition,每个partition一个副本replication,所以一共是 50*1=50个,这50个partition分布到整个kafka集群中,单机模式是分布到 192.168.100.120 机器上,集群模式是分布到 192.168.100.136、192.168.100.137、192.168.100.138 三个机器上。
这种设计为了应对有很多个consumer来消费,所以kafka默认为集群创建50个partition,我们可以通过命令随时查看kafka集群上的topic,如下:
./bin/kafka-topics.sh --bootstrap-server 192.168.100.120:9092 --list

如上图,我们看到了, __consumer_offset就是一个topic名,当第一次消费的时候,kafka自动创建的一个名为 __consumer_offset 的topic,还有一个test2是程序员自己用命令手动创建的topic,不管是哪种,都存放在server.properties中log.dirs指定的目录下,如下图:
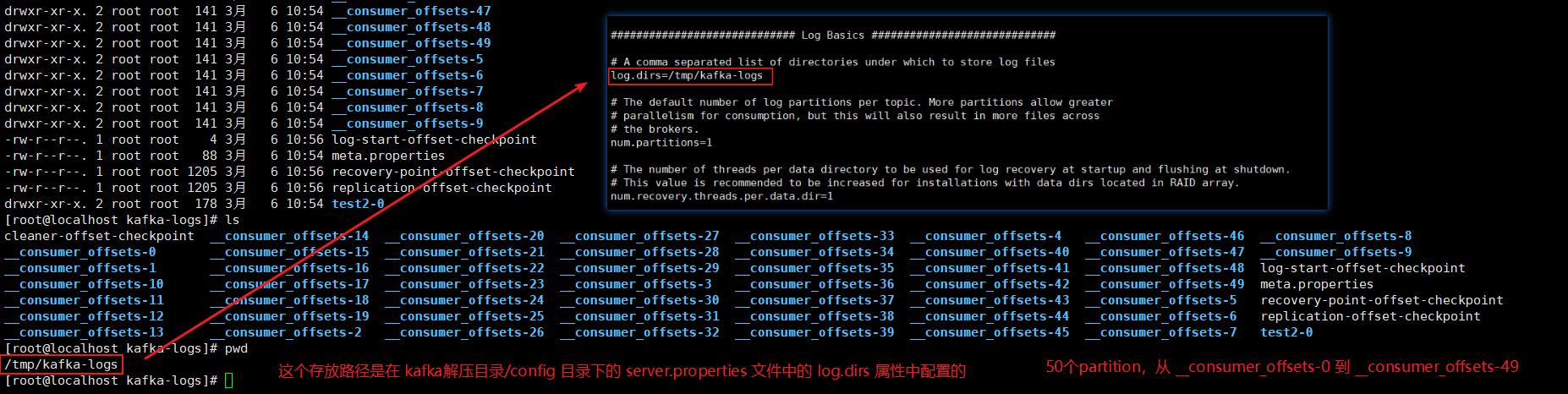
我们需要区分好两种topic,如下:
(1) __consumer_offset 就是一个topic,这个topic是在消息被第一次消费的时候,kafka自动创建的,默认有50个partition,每个partition只有一个副本,就是自己,均放在kafka中server.properties文件配置的 log.dirs 属性指定目录下;
(2) test2 也是topic,这个topic是程序员手动命令创建的,也是存放在partition里面,分区数partition和副本数replication也是自己设置。
eg: 集群情况下也是这样,经过第一次消费,我们可以看到50个partition,只是这50个partition被分布到整个kafka集群上,我们这里是 192.168.100.136、192.168.100.137、192.168.100.138 三个机器上。
四、尾声
本文主要介绍了kafka的单机和集群模式部署。
天天打码,天天进步!!
以上是关于解开Kafka神秘的面纱:kafka单机部署和集群部署的主要内容,如果未能解决你的问题,请参考以下文章
解开Kafka神秘的面纱:kafka stream及interceptor