解开Kafka神秘的面纱
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解开Kafka神秘的面纱相关的知识,希望对你有一定的参考价值。
一、前言
二、Kafka消息队列
2.1 生产者生产kafka中的消息数据
2.1.1 生产者生产kafka中的消息数据
第一阶段:一个生产者一个消费者
众所周知,Kafka是一个消息队列,把消息放到队列里边的叫生产者,从队列里边消费的叫消费者。

第二阶段:引入topic,因为多个队列,所以要给队列命名,引入topic
一个消息中间件,队列不单单只有一个,我们往往会有多个队列,而我们生产者和消费者就需要知道:把数据丢给哪个队列,从哪个队列取消息。我们需要给队列取名字,叫做topic(相当于数据库里边表的概念)
(1) topic是kafka中的队列名,类型是与mysql数据库中的表名
(2) partition是kafka队列中的一个分区名,类似于mysql数据库表中的列名
联系:kafka中的数据宏观上是放到topic中,然后从topic中取出,本质上存放到topic中的具体的partition分区,也是从具体的partition分区中取出;mysql中的数据宏观上是放到表中,然后从表中取出,本质上存放到表中的具体的列中,也是从具体的列中存取数据。

现在我们给队列取了名字以后,生产者就知道往哪个队列丢数据了,消费者也知道往哪个队列拿数据了。我们可以有多个生产者往同一个队列(topic)丢数据,多个消费者往同一个队列(topic)拿数据。
第三阶段:引入partition,多个生产者–>一个topic–>多个消费者
对于同一个topic队列,可以有多个生产者存入数据,多个消费者取出数据,为了保证数据不会混乱,topic中还有具体的partition分区空间,所以,生产者实际上是往一个topic名为Java3y中的分区(Partition)丢数据,消费者实际上是往一个topic名为Java3y的分区(Partition)取数据。
第四阶段:天然分布式架构使Partition存储在不同broker上
每一台Kafka服务器又被称为Broker,Kafka集群就是多台Kafka服务器,Kafka是天然分布式的,意思就是一个Partition可以存储在不同broker上,如下:

一个topic会分为多个partition,实际上由于分布式存储,partition会分布在不同的broker中,举个例子:
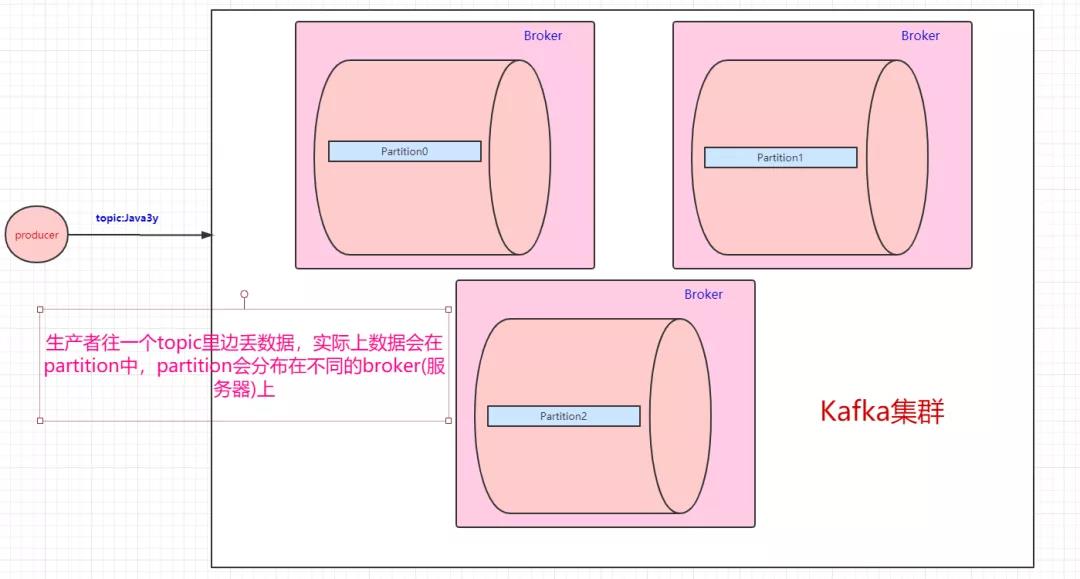
由此得知:Kafka是天然分布式的,分布式集群保证高可用。
第五阶段:Partition主从分区实现高可用
现在我们已经知道了往topic里边丢数据(第2点知道),实际上这些数据会分到不同的partition上(第3点知道),这些partition存在不同的broker上(第4点知道)。
分布式肯定会带来问题:“万一其中一台broker(Kafka服务器)出现网络抖动或者挂了,怎么办?” Kafka是这样做的:我们数据存在不同的partition上,那kafka就把这些partition做备份。比如,现在我们有三个partition,分别存在三台broker上。每个partition都会备份,这些备份散落在不同的broker上。
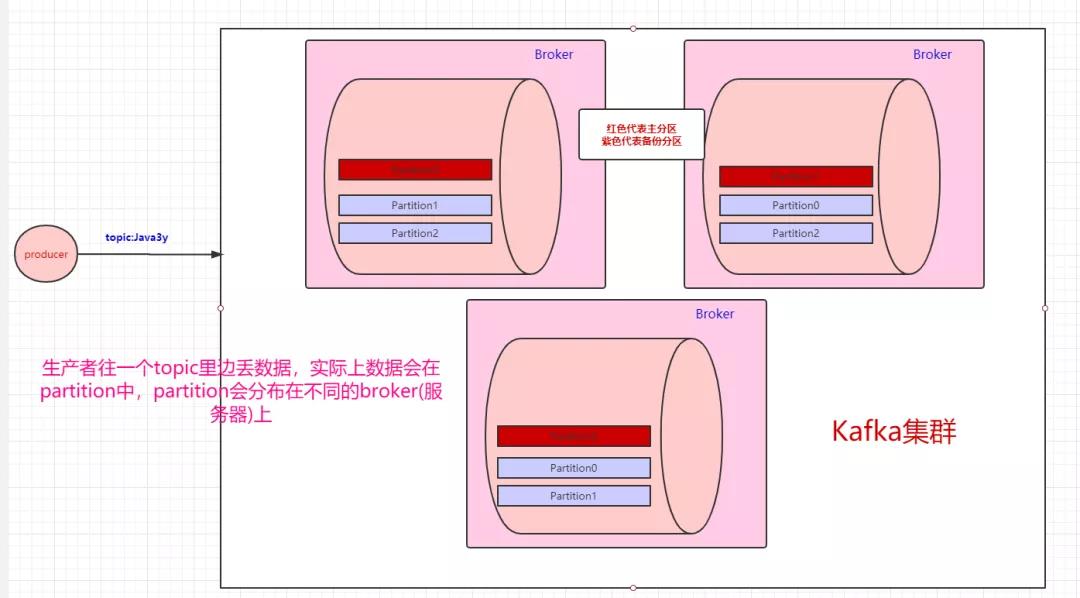
红色块的partition代表的是主分区,紫色的partition块代表的是备份分区。生产者往topic丢数据,是与主分区交互,消费者消费topic的数据,也是与主分区交互。备份分区仅仅用作于备份,不做读写。如果某个Broker挂了,那就会选举出其他Broker的partition来作为主分区,这就实现了高可用。
2.1.2 kafka生产者高效写盘
问题:当生产者把数据丢进topic时,我们知道是写在partition上的,那partition是怎么将其持久化的呢?因为不持久化如果Broker中途挂了,那一定会丢数据。
回答:Kafka中,消息持久化是通过写磁盘来保证,
问题:Kafka如何高效地写磁盘?
回答:为了高效的写盘,Kafka使用了两种策略。
(1) 追加写提高效率:Kafka是将partition的数据写在磁盘的(消息日志),不过Kafka只允许追加写入(底层磁盘原理:顺序访问而不是随机访问,没有寻址时间,加快写入速度),避免缓慢的随机 I/O 操作。
(2) 攒一波一次写/批量写:Kafka也不是partition一有数据就立马将数据写到磁盘上,它会先缓存一部分,等到足够多数据量或等待一定的时间再批量写入(flush)。
2.2 消费者消费kafka中的消息数据
2.2.1 消费者消费kafka中的消息数据
上面讲生产者把数据丢进topic是怎么样的,下面来讲讲消费者是怎么消费的。既然数据是保存在partition中的,那么消费者实际上也是从partition中取数据,如下:
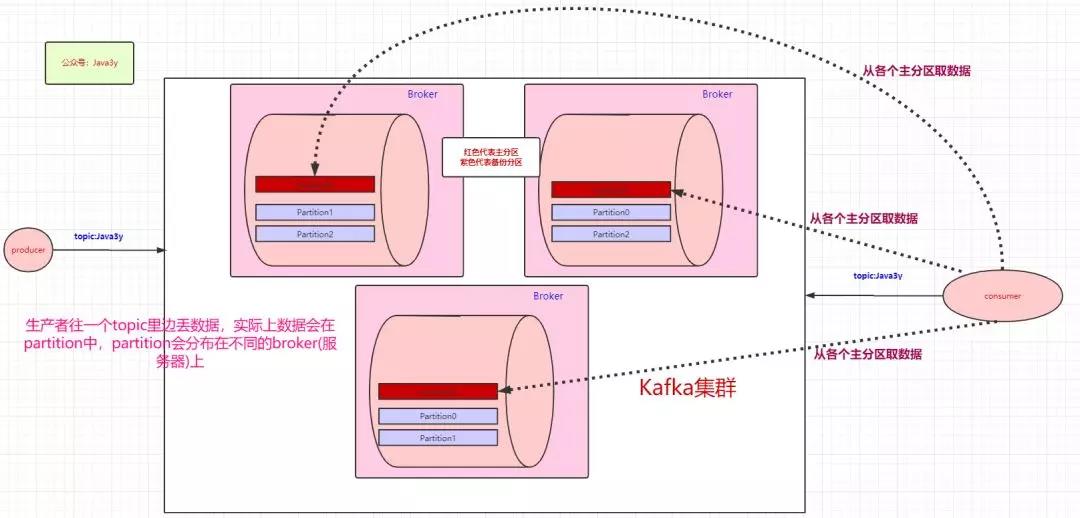
生产者可以有多个,消费者也可以有多个。像上面图的情况,是一个消费者消费三个分区的数据。多个消费者可以组成一个消费者组。
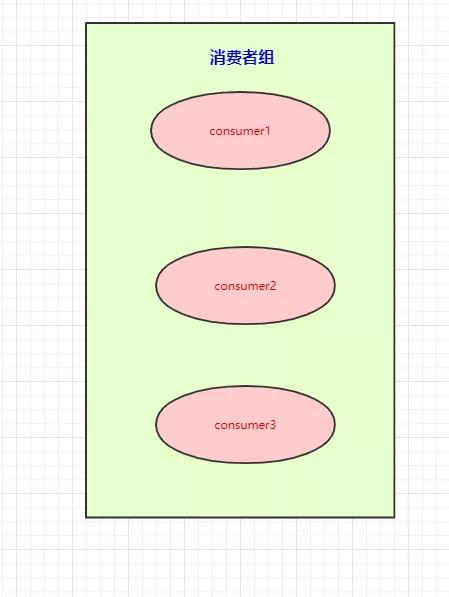
本来是一个消费者消费三个分区的,现在我们有消费者组,就可以每个消费者去消费一个分区(也是为了提高吞吐量),如下:
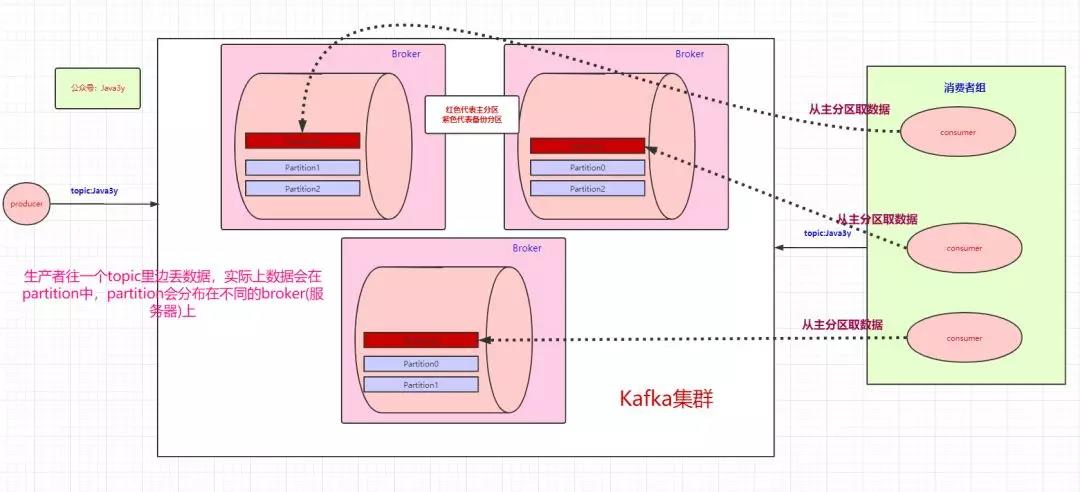
如上图,消费者组消费partition中消息,小结所有情况:
情况1:正常情况,一个消费者组中三个消费者对应三个partition,那么每个消费者消费一个partition;
情况2:如果消费者组中的某个消费者挂了,则一个消费者组中,两个消费者对应三个partition,那么其中一个消费者可能就要消费两个partition了;
情况3:如果只有三个partition,而消费者组有4个消费者,则一个消费者组中,四个消费者对应三个partition,那么一个消费者会空闲;
情况4:如果多加入一个消费者组,则两个消费者组对应三个partition,无论是新增的消费者组还是原本的消费者组,都能消费topic的全部数据(理由:消费者组之间从逻辑上它们是独立的)。
2.2.2 Kafka消费者高效读盘
前面讲解到了生产者往topic里丢数据是存在partition上的,而partition持久化到磁盘是IO顺序访问的,并且是先写缓存,隔一段时间或者数据量足够大的时候才批量写入磁盘的,即写盘的时候通过“顺序IO+批量写”达到最快写盘。
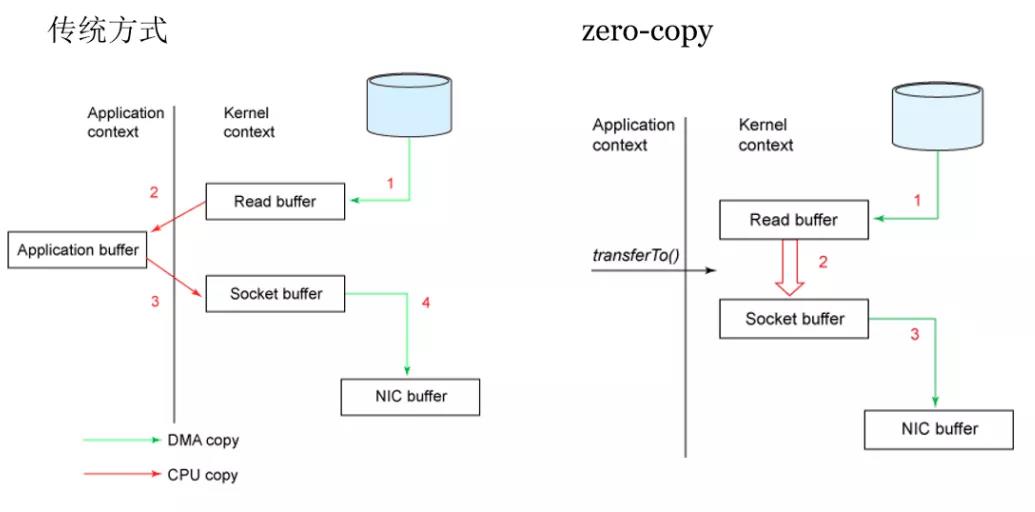
在读的时候也很有讲究,通过零拷贝技术加快读盘速度,每个消费者通过offset记录自己的当前读取位置。
零拷贝:正常的读磁盘数据是需要将内核态数据拷贝到用户态的,而Kafka 通过调用sendfile()直接从内核空间(DMA Direct Memery Access直接内存通过)到内核空间(Socket的),少做了一步拷贝的操作。
问题:消费者是怎么知道自己消费到哪里的呀?Kafka支持的回溯是如何实现?如果一个消费者组中的某个消费者挂了,那挂掉的消费者所消费的分区可能就由存活的消费者消费。那存活的消费者是需要知道挂掉的消费者消费到哪了,否则无法继续下去?
回答:offset。Kafka就是用offset来表示消费者的消费进度到哪了,每个消费者会都有自己的offset。说白了offset就是用来标明消费者的消费进度。在以前版本的Kafka,这个offset是由Zookeeper来管理的,但是,Zookeeper不合适大量的删改操作(注意,这里是说“大量的”,少量还是可以的);在现在版本的Kafka,这个offset在broker以内部topic(__consumer_offsets)的方式来保存起来。每次消费者消费的时候,都会提交这个offset,Kafka可以让你选择是自动提交还是手动提交。
值得注意的是,虽然Zookeeper在新版的Kafka中没有用作于保存客户端的offset,但是Zookeeper是Kafka一个重要的依赖,理由:
(1)探测broker和consumer的添加或移除(每一台kafka服务器就是一个broker)。
(2)负责维护所有partition的领导者/从属者关系(主分区和备份分区),如果主分区挂了,需要选举出备份分区作为主分区。
(3)维护topic、partition等元配置信息metadata。
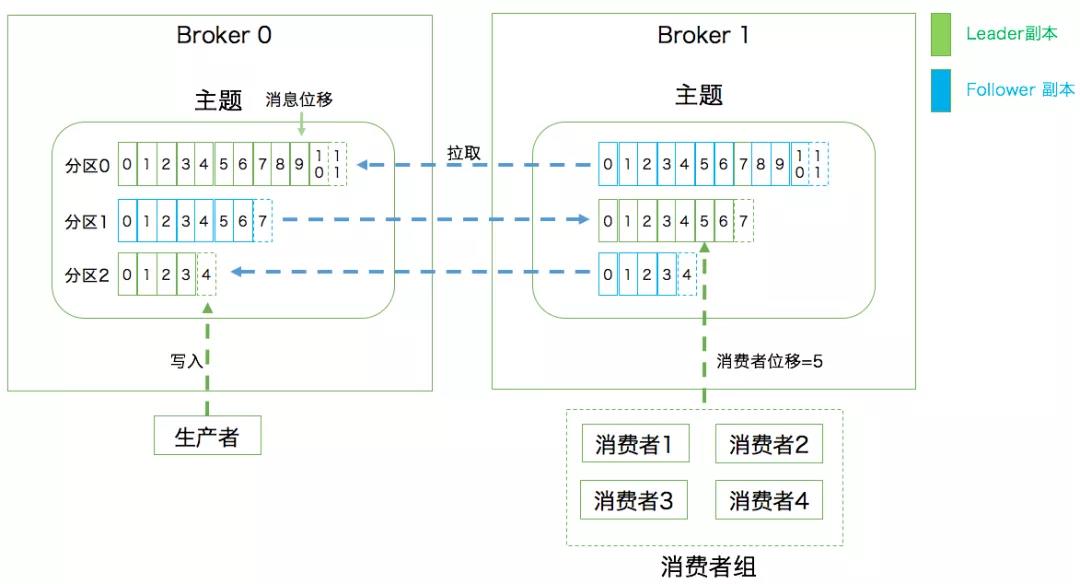
解释上图:每一个kafka服务器就是一个broker,一个broker上面有很多个对应,用不同的topic标识,每一个队列中不同的partition,就是这里的分区0 分区1 分区2,这个partition是kafka实际存储数据的地方,为了数据的高可用,所以同一个partition会放到不同的broker上,形成主从备份,生产者消费者读写的是主分区,从分区不做生产消费,只要按固定的策略同步主分区的数据就好了,待主分区宕机,在zookeeper的协调下选出新的partition,供生产和消费。
如图所示,绿色表示主partition,蓝色表示分partition,生产者将生产的数据放到broker0上的分区2上面,这是一个主分区,消费者消费broker1上的分区1中的数据,这也是一个主分区;分区0和分区2在broker0上,broker1上的这两个分区要来同步数据,分区1的主分区在broker1上,broker0上的分区1要来通过数据。
三、Kafaka存储结构与日志段读写
3.1 Kafka的存储结构
总所周知,Kafka的Topic可以有多个分区,分区其实就是最小的读取和存储结构,即Consumer看似订阅的是Topic,实则是从Topic下的某个分区获得消息,Producer也是发送消息也是如此。
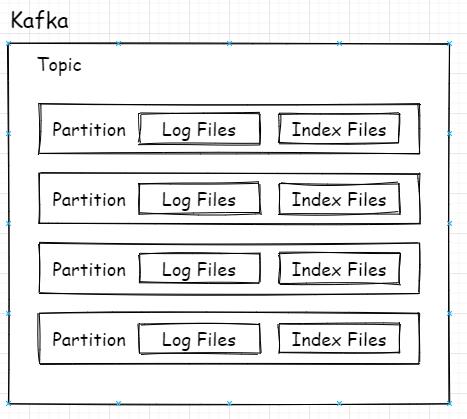
上图是总体逻辑上的关系,映射到实际代码中在磁盘上的关系则是如下图所示:
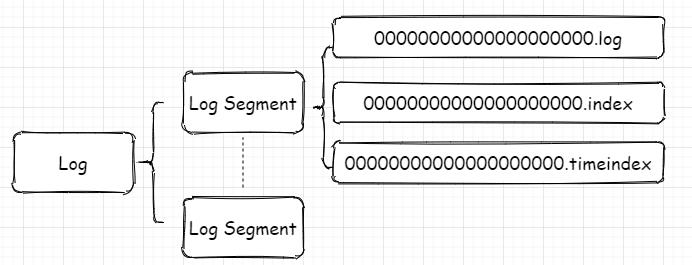
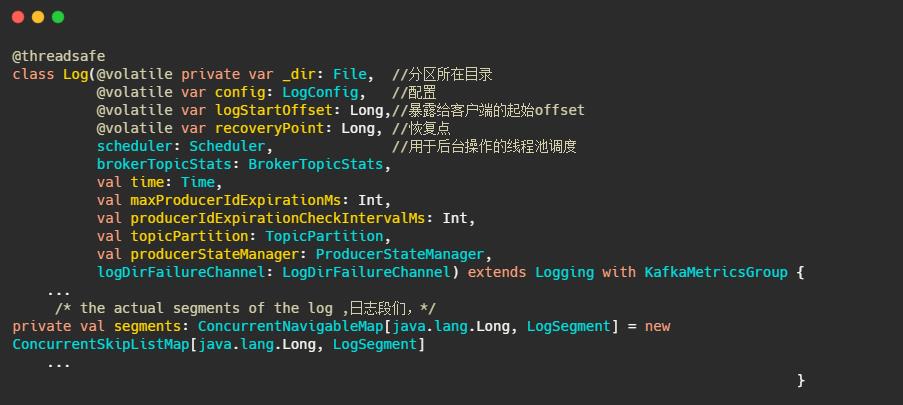
每个分区对应一个Log对象,在磁盘中就是一个子目录,子目录下面会有多组日志段即多Log Segment,每组日志段包含:消息日志文件(以log结尾)、位移索引文件(以index结尾)、时间戳索引文件(以timeindex结尾)。其实还有其它后缀的文件,例如.txnindex、.deleted等等。篇幅有限,暂不提起。以下为日志的定义:
以下为日志段的定义:

indexIntervalBytes可以理解为插了多少消息之后再建一个索引,由此可以看出Kafka的索引其实是稀疏索引,这样可以避免索引文件占用过多的内存,从而可以在内存中保存更多的索引。对应的就是Broker 端参数log.index.interval.bytes 值,默认4KB。
实际的通过索引查找消息过程是先通过offset找到索引所在的文件,然后通过二分法找到离目标最近的索引,再顺序遍历消息文件找到目标文件。这波操作时间复杂度为O(log2n)+O(m),n是索引文件里索引的个数,m为稀疏程度。这就是空间和时间的互换,又经过数据结构与算法的平衡。
再说下rollJitterMs,这其实是个扰动值,对应的参数是log.roll.jitter.ms,这其实就要说到日志段的切分了,log.segment.bytes,这个参数控制着日志段文件的大小,默认是1G,即当文件存储超过1G之后就新起一个文件写入。这是以大小为维度的,还有一个参数是log.segment.ms,以时间为维度切分。
那配置了这个参数之后如果有很多很多分区,然后因为这个参数是全局的,因此同一时刻需要做很多文件的切分,这磁盘IO就顶不住了啊,因此需要设置个rollJitterMs,来岔开它们。怎么样有没有联想到redis缓存的过期时间?过期时间加个随机数,防止同一时刻大量缓存过期导致缓存击穿数据库。
问题:开发中 遇到Kafka Broker物理磁盘 I/O 负载突然这么高?
回答:可能是设置了 log.segment.ms参数,试试设置 log.roll.jitter.ms。
3.2 日志段的写入
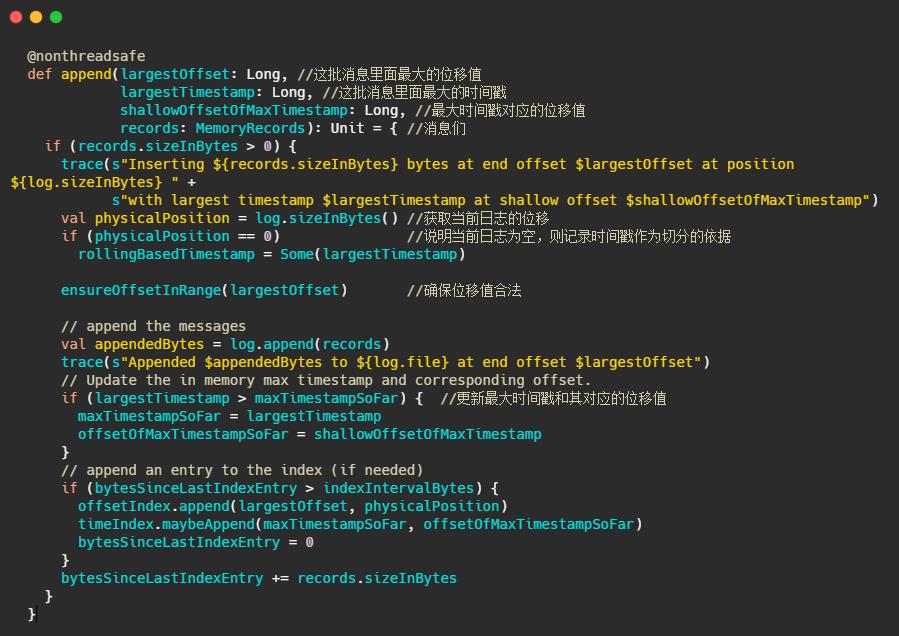
1、判断下当前日志段是否为空,空的话记录下时间,来作为之后日志段的切分依据
2、确保位移值合法,最终调用的是AbstractIndex.toRelative(…)方法,即使判断offset是否小于0,是否大于int最大值。
3、append消息,实际上就是通过FileChannel将消息写入,当然只是写入内存中及页缓存,是否刷盘看配置。
4、更新日志段最大时间戳和最大时间戳对应的位移值。这个时间戳其实用来作为定期删除日志的依据
5、更新索引项,如果需要的话(bytesSinceLastIndexEntry > indexIntervalBytes)
最后再来个流程图

3.3 日志段的读取
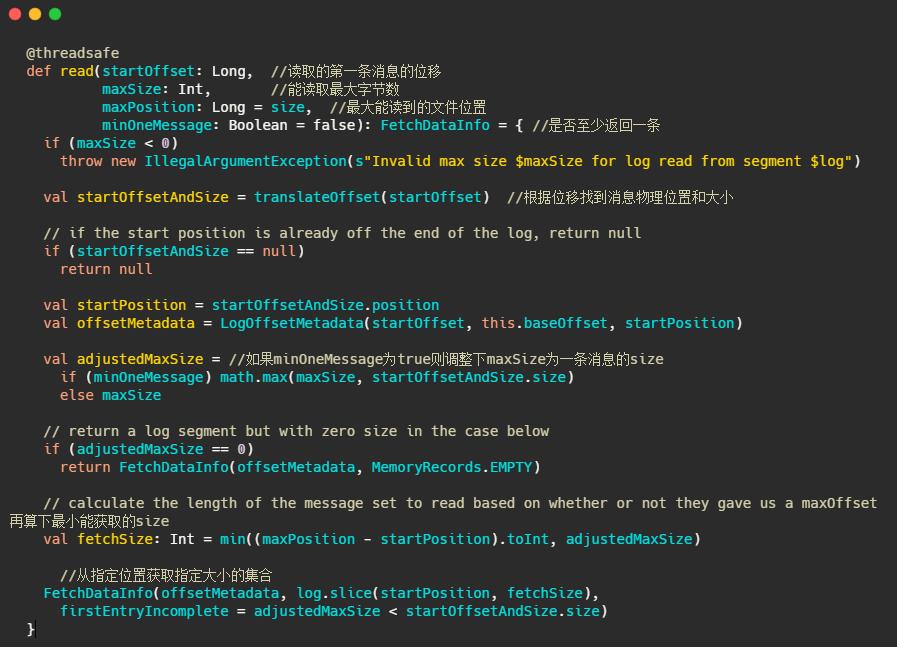
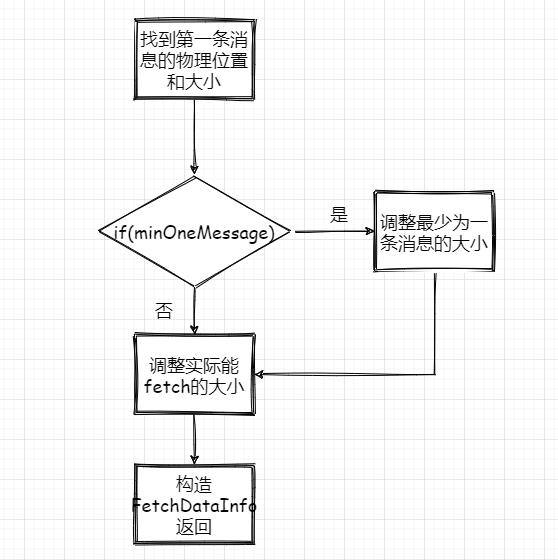
1、根据第一条消息的offset,通过OffsetIndex找到对应的消息所在的物理位置和大小。
2、获取LogOffsetMetadata,元数据包含消息的offset、消息所在segment的起始offset和物理位置
3、判断minOneMessage是否为true,若是则调整为必定返回一条消息大小,其实就是在单条消息大于maxSize的情况下得以返回,防止消费者饿死
4、再计算最大的fetchSize,即(最大物理位移-此消息起始物理位移)和adjustedMaxSize的最小值(这波我不是很懂,因为以上一波操作adjustedMaxSize已经最小为一条消息的大小了)
5、调用 FileRecords 的 slice 方法从指定位置读取指定大小的消息集合,并且构造FetchDataInfo返回
再来个流程图:
四、Kafka 为什么这么快
Kafka 的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka 的特性之一就是高吞吐率。Kafka 之所以能这么快,无非是:顺序写磁盘、大量使用内存页 、零拷贝技术的使用、批量发送、数据压缩。
下面我就从数据写入、数据读取、生产者发送三方面分析,为大家分析下为什么 Kafka 速度这么快。
4.1 Kafka实现生产者高效写盘
对于数据持久化到磁盘中,数据写入 Kafka 会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度 Kafka 采用了两个技术, 顺序写入和 Memory Mapped File 。
4.1.1 顺序写入
Kafka 会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度 Kafka 采用了两个技术, 顺序写入和 MMFile(Memory Mapped File)内存映射文件。
磁盘读写的快慢取决于你怎么使用它,也就是顺序读写或者随机读写。在顺序读写的情况下,磁盘的顺序读写速度和内存持平。因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机 I/O,最喜欢顺序 I/O。为了提高读写硬盘的速度,Kafka 就是使用顺序 I/O。而且 Linux内部 对于磁盘的读写优化也比较多,包括 read-ahead 和 write-behind,磁盘缓存等。
问题:为什么Kafka将消息存储到磁盘而不是内存?
回答:如果在内存做这些读写操作的时候,一个是 Java 对象的内存开销很大,另一个是随着堆内存数据的增多,Java 的 GC 时间会变得很长。使用磁盘操作有以下几个好处:
(1)磁盘顺序读写速度超过内存随机读写。
(2)JVM 的 GC 效率低,内存占用大。使用磁盘可以避免这一问题。
(3)系统冷启动后,磁盘缓存依然可用。
下图就展示了 Kafka 是如何写入数据的, 每一个 Partition 其实都是一个文件 ,收到消息后 Kafka 会把数据插入到文件末尾(虚框部分):
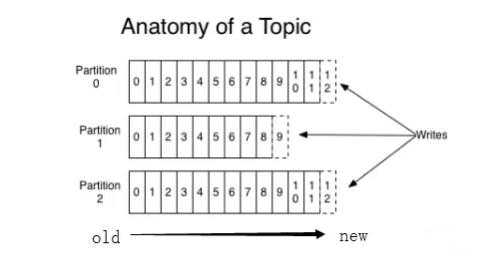
上图中,左边old表示是旧数据,右边new表示是新写入的数据,下面一个箭头很明显,这里表示一个topic下面的三个partition,不断的往里面写数据。这种方法有一个缺陷——没有办法删除数据 ,所以 Kafka 是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个 Topic 都有一个 Offset 用来表示读取到了第几条数据 。
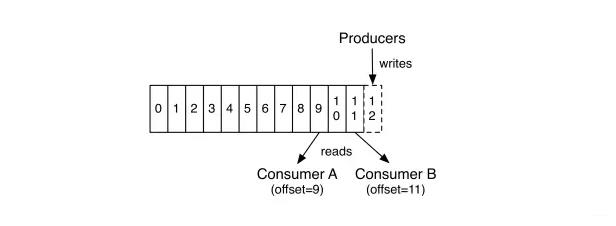
由上图,
对于producer,producer生产的数据不断增加,
对于Consumer消费kafka中的数据,提供一个offset,consumer消费的数据不会减少,只是移动offset,offset之前是已经被消费的,offset之后是没有被消费的。
注意,kafka不会删除数据,只是提供一个offset,这个offset可以用zookeeper管理,
特别注意,这个offset只对consumer消费有用,对producer生产没用。
一般情况下 Offset 由客户端 SDK 负责保存 ,会保存到 Zookeeper 里面 。
关于存在硬盘中的消息,Kafka 也有它的解决方法,可以基于时间和 Partition 文件的大小,正常 Kafka 是默认七天的保存,也可以通过命令来修改,以 users topic 为例。
修改kafka 7天 默认保存周期
kafka-topics.sh --zookeeper 6 --alter --topic users --config retention.ms=100000
问题:kafka不会删除数据,即使被消费掉也是移动offset,不删除数据,所有的数据都持久化到磁盘中,不担心磁盘爆满吗?
回答:为了避免磁盘被撑满的情况,Kakfa 提供了两种策略来删除数据:基于时间(默认七天)删除、基于 Partition 文件大小删除。
4.1.2 内存映射文件
这个和Java NIO中的内存映射基本相同,在大学的计算机原理里我们学过(划重点),mmf (Memory Mapped Files)直接利用操作系统的Page来实现文件到物理内存的映射,完成之后对物理内存的操作会直接同步到硬盘。mmf 通过内存映射的方式大大提高了IO速率,省去了用户空间到内核空间的复制。它的缺点显而易见–不可靠,当发生宕机而数据未同步到硬盘时,数据会丢失,Kafka 提供了produce.type参数来控制是否主动的进行刷新。
Kafka 提供了一个参数 producer.type 来控制是不是主动 Flush:
如果 Kafka 写入到 mmf 之后就立即 Flush,然后再返回 Producer 叫同步 (Sync);
如果 Kafka 写入 mmf 之后立即返回 Producer 不调用 Flush 叫异步 (Async)。
4.2 Kafka实现消费者高效读盘
Kafka实现消费者高效读盘的关键在于零拷贝:作为一个消息系统,不可避免的便是消息的拷贝,常规的操作,一条消息,需要从创建者的socket到应用,再到操作系统内核,然后才能落盘。同样,一条消息发送给消费者也要从磁盘到内核到应用再到接收者的socket,中间经过了多次不是很有必要的拷贝。
传统 Read 方式进行网络文件传输,在传输过程中,文件数据实际上是经过了四次 Copy 操作,其具体流程细节如下:
(1)调用 Read 函数,文件数据被 Copy 到内核缓冲区。
(2)Read 函数返回,文件数据从内核缓冲区 Copy 到用户缓冲区
(3)将文件数据从用户缓冲区 Copy 到内核与 Socket 相关的缓冲区。
(4)数据从 Socket 缓冲区 Copy 到相关协议引擎。
传统Read方式(四次Copy操作):硬盘—>内核 buf—>用户 buf—>Socket buf—>协议引擎
Kafka 把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候 Kafka 直接把文件发送给消费者,配合 mmap 作为文件读写方式,直接把它传给 Sendfile。Sendfile 系统调用则提供了一种减少以上多次 Copy,提升文件传输性能的方法。在内核版本 2.1 中,引入了 Sendfile 系统调用,以简化网络上和两个本地文件之间的数据传输。Sendfile 的引入不仅减少了数据复制,还减少了上下文切换。相较传统 Read/Write 方式,2.1 版本内核引进的 Sendfile 已经减少了内核缓冲区到 User 缓冲区,再由 User 缓冲区到 Socket 相关缓冲区的文件 Copy。减少两次copy。而在内核版本 2.4 之后,文件描述符结果被改变,Sendfile 实现了更简单的方式,再次减少了一次 Copy 操作,则一共减少了三次copy。
传统Read方式(四次Copy操作):硬盘—>内核 buf—>用户 buf—>Socket buf—>协议引擎
SendFile 2.1,硬盘—>内核 buf—>协议引擎
SendFile 2.4,硬盘—>协议引擎
4.3 消息生产者高效发送消息
4.3.1 批量发送
producer发送消息两种方式:同步发送 + 异步发送。
同步发送:就是马上发送消息;
异步发送:就是批量发送消息,producter发送消息的时候,可以将消息缓存在本地,等到了固定条件发送到 Kafka。
问题:异步发送就攒一波再发送,那攒一波到什么使用发送呢?
回答:两种方式:(1) 等消息条数到固定条数;
(2) 一段时间发送一次。
4.3.2 数据压缩
Kafka支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩。压缩的好处就是减少传输的数据量,减轻对网络传输的压力。
Producer压缩之后,在Consumer需进行解压,虽然增加了CPU的工作,但在对大数据处理上,瓶颈在网络上而不是CPU,所以这个成本很值得。
注意:批量发送和数据压缩可以一起使用,但是单条做数据压缩的话,效果不明显
小结:数据压缩后发送的优点和缺点
(1) 优点:压缩包的大小一定比直接发送的大小要小,提高网络传输效率;
(2) 缺点:producer要压缩,consumer要解压,增加producer和consumer的CPU压力
小结:大数据处理上,瓶颈在网络上而不是CPU,只要优点可以覆盖缺点,就应该使用这种方式
4.4 小结
问题:为什么 Apache Kafka虽然使用了硬盘存储,但是仍然可以速度很快?
回答:
(1) 对于producer:批量发送、数据压缩后发送
(2) 对于broker:写磁盘两招:通过 mmap 提高 I/O 速度;写入数据的时候由于单个 Partion 是末尾添加,所以速度最优;读磁盘一招:读取数据的时候配合 Sendfile 直接暴力输出。
写磁盘持久化的是broker,从磁盘中读取发送给consumer的也是broker,producer和consumer只有内存操作。
4.5 Kafka和其他消息队列的区别
Kafka的设计目标是高吞吐量,为了达到这个高吞吐量的目标,那它与其它消息队列的区别就显而易见了:
1、对于broker,顺序写磁盘,内存映射文件写磁盘:Kafka操作的是序列文件 I/O(序列文件的特征是按顺序写,按顺序读),为保证顺序,Kafka强制点对点的按顺序传递消息,这意味着,一个consumer在消息流(或分区)中只有一个位置。
2、对于broker,Kafka的消息存储在OS pagecache:页缓存,page cache的大小为一页,通常为4K,在Linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问。
3、对于broker-consumer,基于SendFile零拷贝读磁盘,并且,不保存消息状态(是否被消费),使用offset记录消费位置:Kafka不保存消息的状态,即消息是否被“消费”。一般的消息系统需要保存消息的状态,并且还需要以随机访问的形式更新消息的状态。而Kafka 的做法是保存Consumer在Topic分区中的位置offset,在offset之前的消息是已被“消费”的,在offset之后则为未“消费”的,并且offset是可以任意移动的,这样就消除了大部分的随机IO。
4、对于broker,批量发送、压缩后发送,kafka在producer端加速/高吞吐量的措施:Kafka支持点对点的批量消息传递。
所以,Kafka和其他消息队列的区别
RabbitMQ:分布式,支持多种MQ协议,重量级
ActiveMQ:与RabbitMQ类似
ZeroMQ:以库的形式提供,使用复杂,无持久化
Redis:单机、纯内存性好,持久化较差
Kafka:分布式,消息不是使用完就丢失,有较长时间持久化,吞吐量高,高性能,轻量灵活
五、Kafka如何保证消息不丢失
Kafka 为什么这么快,又能保证不丢失消息?请看本节。
5.1 消息生产者本地缓存保证消息不丢失
为了得到更好的性能,Kafka 支持在生产者一侧进行本地buffer,也就是累积到一定的条数才发送,如果这里设置不当是会丢消息的。
生产者端设置:producer.type=async, sync,默认是 sync。当设置为 async,会大幅提升性能,因为生产者会在本地缓冲消息,并适时批量发送。如果对可靠性要求高,那么这里可以设置为 sync 同步发送。
一般时候我们还需要设置:min.insync.replicas> 1 ,消息至少要被写入到这么多副本才算成功,也是提升数据持久性的一个参数,与acks配合使用。但如果出现两者相等,我们还需要设置 replication.factor = min.insync.replicas + 1 ,避免在一个副本挂掉,整个分区无法工作的情况。
5.2 Kafka分布式架构保证消息不丢失
(1) 当broker正常运行时:kafka本身就是分布式,partition数据设置至少3个副本分区,保证存储在 broker/partition 中的消息不丢失
为了保证 leader 副本能有 follower 副本能同步消息,我们一般会为 topic 设置 replication.factor >= 3。这样就可以保证每个 分区(partition) 至少有 3 个副本,以确保消息队列的安全性。
(2) 当broker中leader partition宕机时:关闭 unclean leader 选举,减低数据丢失可能性
我们最开始也说了我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。多个 follower 副本之间的消息同步情况不一样,当我们配置了 unclean.leader.election.enable = false 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
5.3 消息消费者ACK机制和消费完后提交位移保证消息不丢失
(1) 对于broker-consumer消费消息:巧用ACK机制,添加 acks=all 这个条件,保证broker发送给consumer的消息不会被丢
Kafka 通过 ACK 机制保证消息送达。Kafka 采用的是至少一次(At least once),消息不会丢,但是可能会重复传输。acks 的默认值即为1,代表我们的消息被leader副本接收之后就算被成功发送。我们可以配置 acks = all ,代表则所有副本都要接收到该消息之后该消息才算真正成功被发送。
(2) 消息消费者消费完之后再手动提交位移
consumer端丢失消息的情形比较简单:如果在消息处理完成前就提交了offset,那么就有可能造成数据的丢失。由于Kafka consumer默认是自动提交位移的,所以在后台提交位移前一定要保证消息被正常处理了,因此不建议采用很重的处理逻辑,如果处理耗时很长,则建议把逻辑放到另一个线程中去做。为了避免数据丢失,现给出几点建议:设置 enable.auto.commit=false 关闭自动提交位移,在消息被完整处理之后再手动提交位移。
六、尾声
解开Kafka神秘的面纱,完成了。
天天打码,天天进步!!!
以上是关于解开Kafka神秘的面纱的主要内容,如果未能解决你的问题,请参考以下文章