解开Kafka神秘的面纱:kafka优雅应用
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解开Kafka神秘的面纱:kafka优雅应用相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
本文主要介绍kafka的offset存储演变、kafka的持久化、kafka集群topic和partition数量设置、kafka可视化监控。
二、kafka的offset存储演变
在kafka版本演进过程中,对于消费者offset的存储位置是发生了改变的。
对于kafka版本小于 0.9 的,此时消费者offset存放在 zookeeper 中,默认目录是 /consumers/[group_id]/offsets/[topic]/[broker_id-partition_id] -> offset_counter_value,如果想要查看,可以通过本地使用 zkTools、ZooKeeper Assistant 这些可视化工具查看。
现在最新版本的kafka都已经到2.8.0了,基本上不会再将offset存放到zookeeper,所以这种方式了解即可。
对于kafka版本大于 0.9 的,此时消费者offset存放在 kafka 中,需要做第一次消费,kafka会在内部维护一个__comsumer_offset 的topic,这个topic是第一次消费kafka自动创建的,用来存放消费者offset,默认50个partition,每个partition保存一个副本。那么,offset存放在哪个partition,是如何确定的呢?答案是使用 Utils.abs(grupId.hashCode) % numPattitions 计算,offset存放的位置取决group的hash值,numPattitions的数量默认是50,可以通过 offsets.topic.num.partionts 参数指定。
因为kafka设计的时候向下兼容,所以高版本的client api适配了低版本。
__comsumer_offset 和程序员手工创建的 topic 放在 “kafka解压目录/conf/server.properties” 指定目录下,但是两种 topic 相互独立。
小结:新版本中,message和offset都存放在kafka;旧版本中,message存放在kafka,offset存放在zookeeper。其实,新版本可以也可以将 offset 存放在zookeeper,保证写操作/生产消息时候指定zookeeper,同时读操作/消费消息的时候指定zookeeper,即可实现将offset存放到zookeeper。
三、kafka的持久化
3.1 kafka读写操作
kafka读写文件速度都是极快的,可以完成适用高并发的场景。
写:采用文件追加写,将随机写变为顺序写,将随机IO变为顺序io,砍掉了寻址时间,让廉价的机械硬盘写入速度 接近固态硬盘。
读:因为有了消费者offset,告诉kafka上次读到了什么位置,直接从文件中读,也是顺序读。
kafka中,消息实体和offset归根结底都存放在kafka的topic的partition上面,但是,消息存放到自己创建的topic上面,消费者offset存放到第一次消费自动创建的__consumer_offset_ 上面,两种topic虽然是同一个目录下,但是相互独立。
3.2 kafka中的Segment段
在kafka中,一个index+多个log文件构成了segment,index文件存储的的是position位置,log文件存储的是message,如下图:
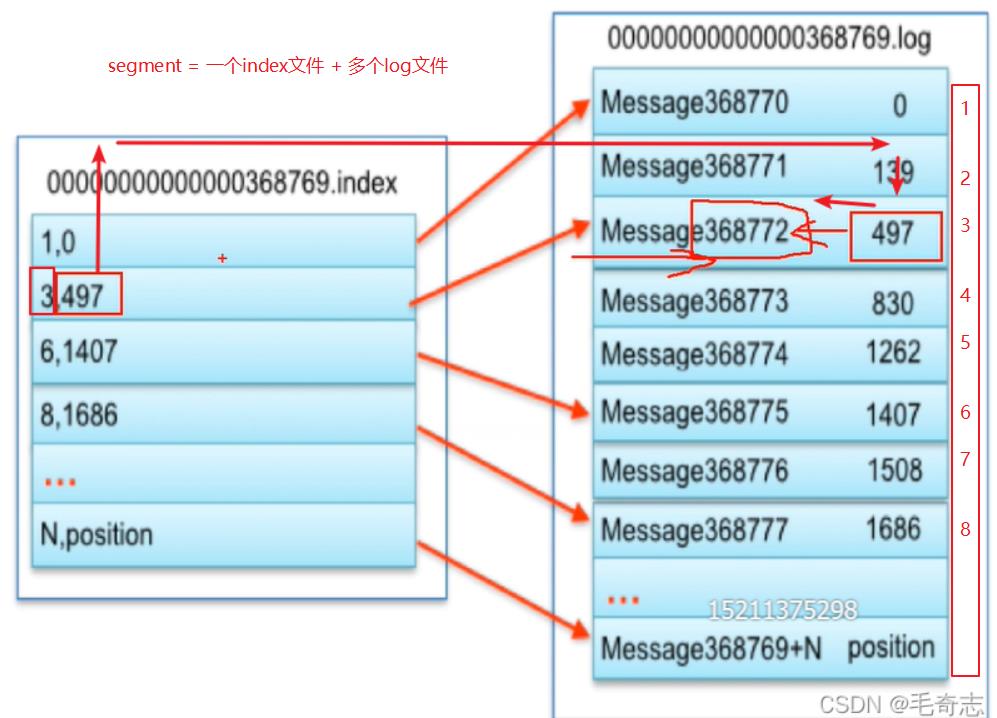
如上图,index文件中存放的是 offset,partition,log文件中存放的是position和message的映射关系,如果需要查找某个message,首先提供offset。例如查找497,则
第一步,查找index文件,根据offset找物理偏离地址position 497;
第二步,查找log文件,根据position找到message,就可以找到497。
查询顺序是offset -> position -> message位置,其中,offset -> position 使用二分查找,position -> message位置 使用线性查找。即先找到段,然后找到文件:就是因为有了index文件,所以可以先大概定位到message在什么地方,然后再次精确查找,所以说,index文件的存在,加快了查找速度。
注意,这个消息存储的offset和消费者consumer offset没任何关系。
问题:分辨两种topic?
回答:自己创建的topic test和kafka消费时自动创建的topic __consumer_offset_,没有任何关系。自己创建的topic test存储的是完整的kafka segment段,即index+log+timestamp组成的消息,kafka消费时自动创建的topic __consumer_offset_,里面存储的是消费者消费消息的offset(存储在kafka上面)。
问题:分辨两种topic中的offset?
回答:test中的offset是topic的offset,不是消费者consumer的offset,消费者consumer的offset在__consumer_offset_上,是完全两个不同的概念,在两个不同的topic里面,test0中的offset是为了加快kafka读写速度,__consumer_offset_ 是为了保存消费者的消费位置,两种topic相互独立,毫无相关。
命令截图:
(1) 仅查看index文件:
./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test2-0/00000000000000000000.log --verify-index-only
(2) 查看index和log文件:
./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test2-0/00000000000000000000.log --print-data-log

存放的消息体就是payload,如下:

注意,kafka中,如果要查看log,必须像上面这样,因为是dump文件,直接cat命令无法查看的。
四、kafka集群topic和partition数量设置
问题:kafka中能够创建多少个topic?
回答:一个kafka集群中,topic数量是由实际业务单元来决定的,而且topic理论数量不超过2000个,超过会有性能问题。
问题:每个topic创建多少个partition用来存储topic?
回答:partition是kafka中存储数据的最小单位,对数据的读写都是通过操作partition来完成的,partition越多越好,最多broker数字个,理论上限是最多不超过30000个,全部宕机了才会丢(如果一个broker宕机,该机器上的parititon都无法使用了),但是如此,磁盘成本+网络同步成本会大大增加。因为partition数量越多,需要的磁盘存储空间越多,更重要的网络同步成本,任何一个topic,都是 1个主partition 和 (N-1) 个从partition,客户端对topic读写消息实际只是操作主partition,从partition需要不断同步主partition的数据。
kafka官网给出一个partition数量计算公式,即 partition数 = max(t/p,t/c) ,其中,p表示生产吞吐量,c表示消费吞吐量,t表示系统想要的最大吞吐量,有了这三个数字,可以算出一个最合适的partition。例如,目标是需要1000吞吐量,使用 1个机器broker,上面只有一个topic,副本数也是1(生产者topic和消费者topic),因为生产者和消费者很少,所以在这个一个机器上需要1000个partition才可以满足1000个吞吐量。
五、kafka可视化监控
kafka的可视化监控,掌握一种就好,这里介绍雅虎的CMAK,直接到 http://github.com/yahoo/CMAK/releases 下载,可以选择最新的版本下载,注意下载压缩包,而不是源码

上传到centos并解压,如下:

注意:cmak需要jdk11才可以运行。
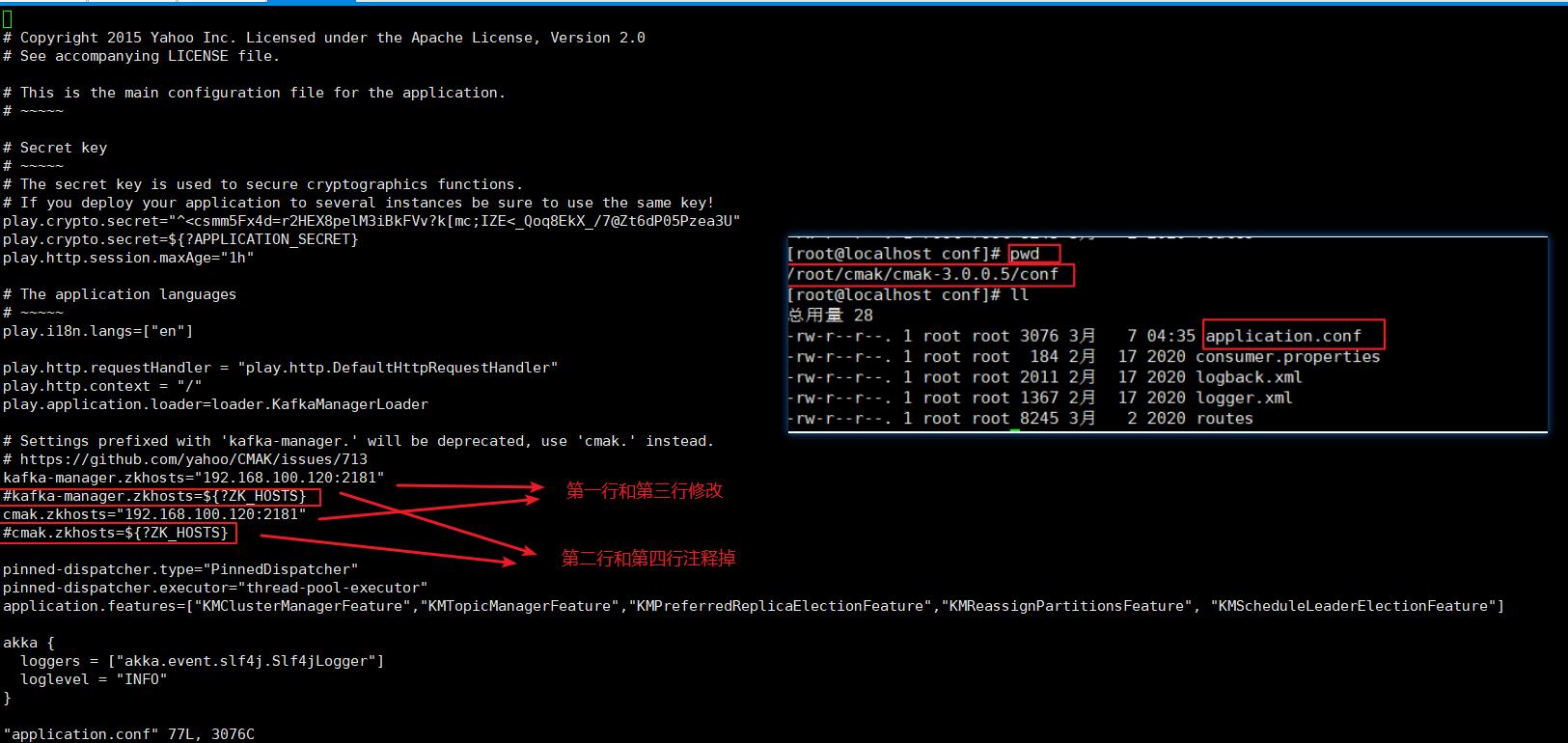
修改application.conf文件,如下:
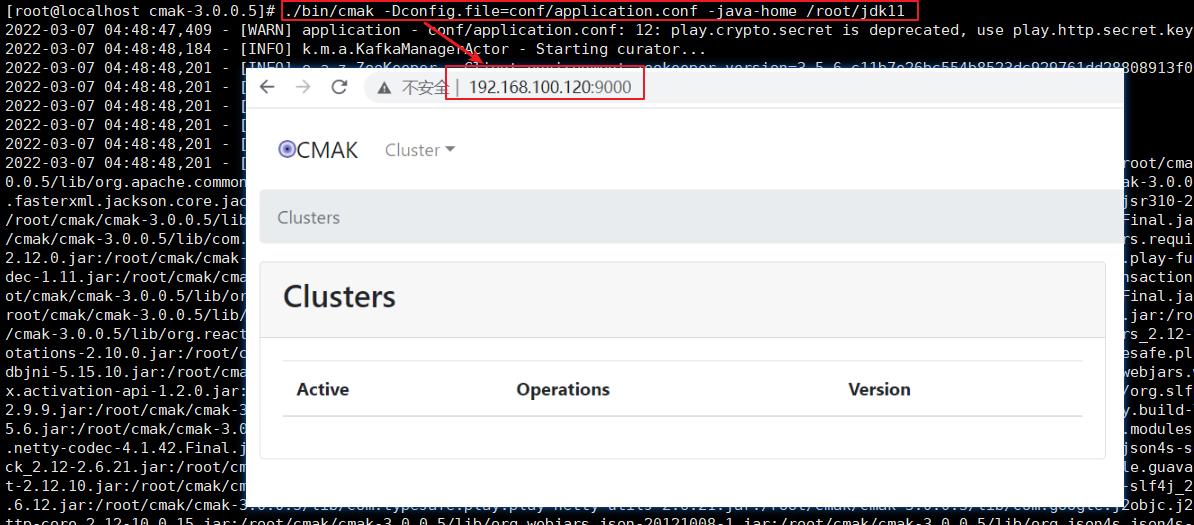
进入到cmak解压目录,执行这条命令
./bin/cmak -Dconfig.file=conf/application.conf -java-home /root/jdk11
cmk最新3.0.0.5版本,需要安装jdk11才可以运行,否则报错:
java.lang.UnsupportedClassVersionError: controllers/routes has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recognizes class file versions up to 52.0
启动之后,可以用 ps -ef|grep cmak 查询,也可以用 netstat -aplt | grep 9000 查询。
刚启动的时候,cmak还没有任何节点,如下:
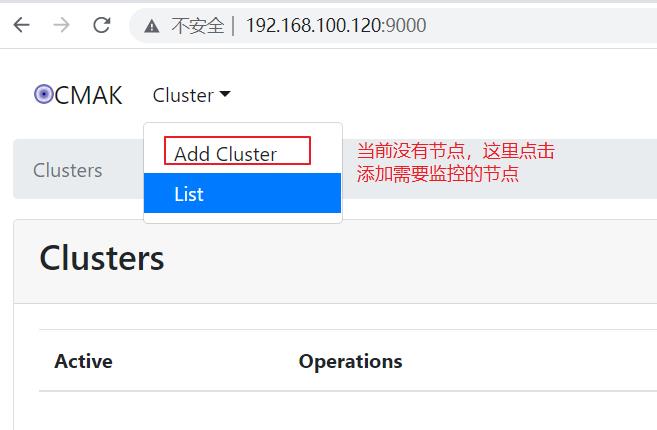
新建一个节点,添加上zookeeper的ip:port,也可以是zookeeper集群,用英文逗号分隔,如下:

有了节点,就可以查看节点的信息了,这个zookeeper上关联了kafka,可以直接看kafka上的topics的信息,如下:
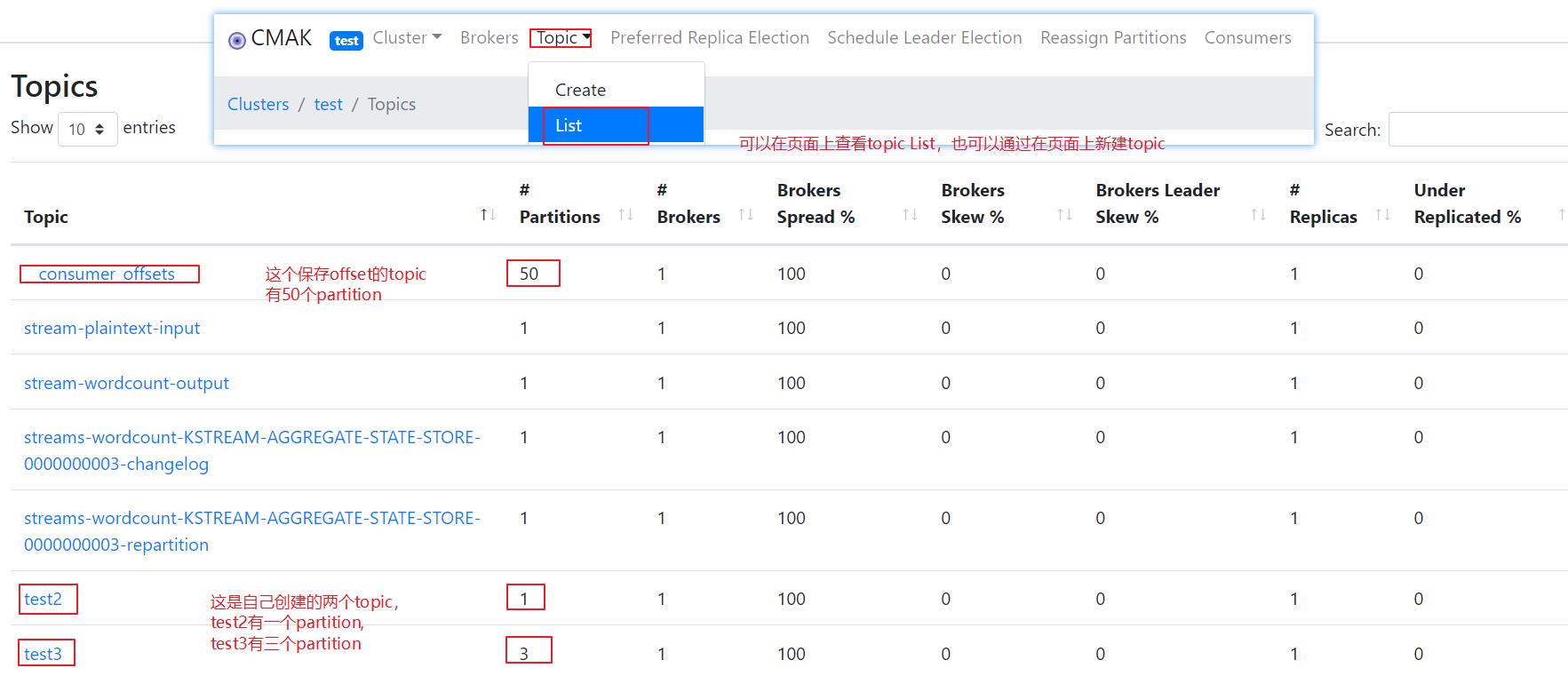
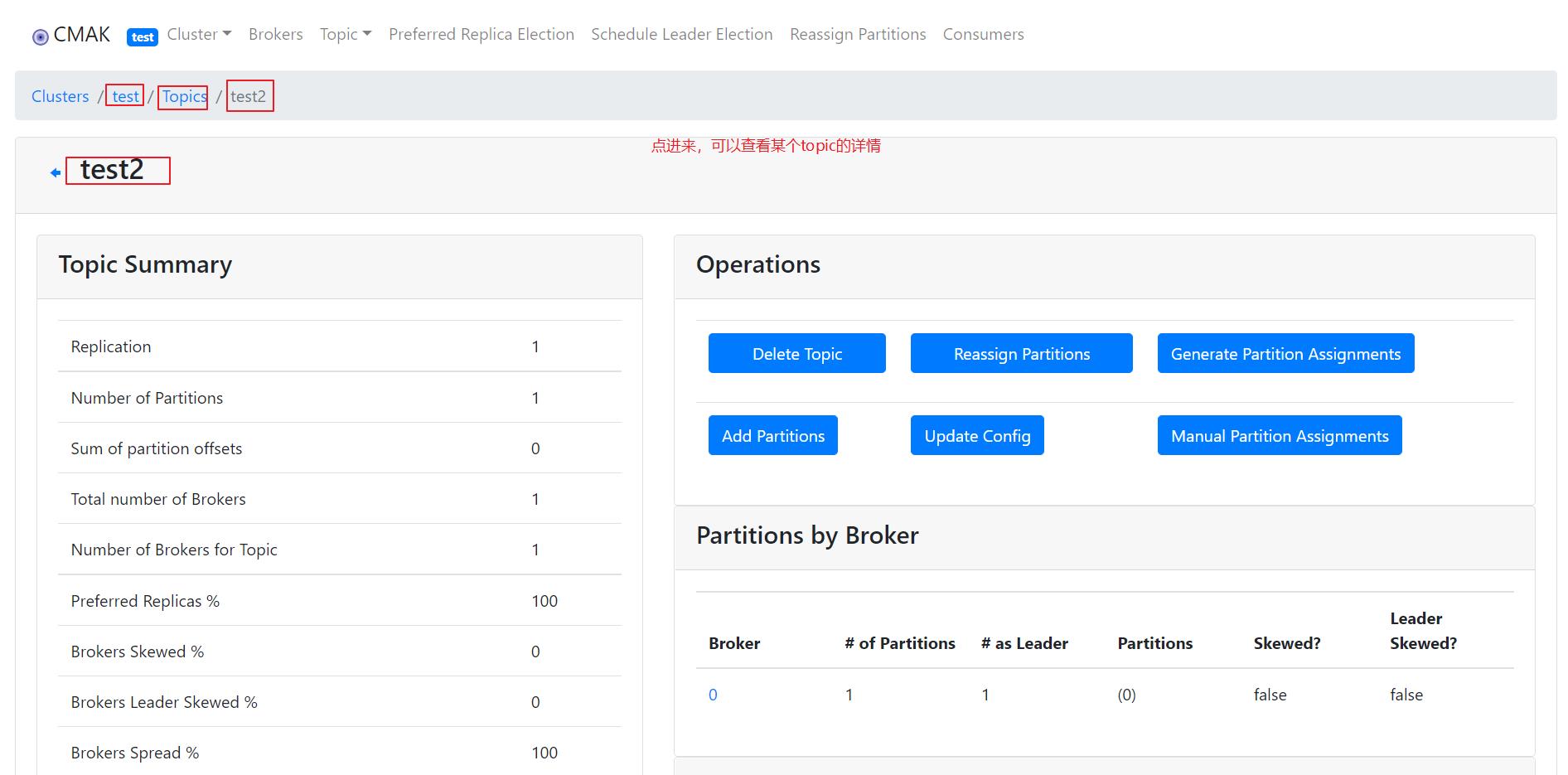
继续点进去,可以查看每个topic的详情,如下:
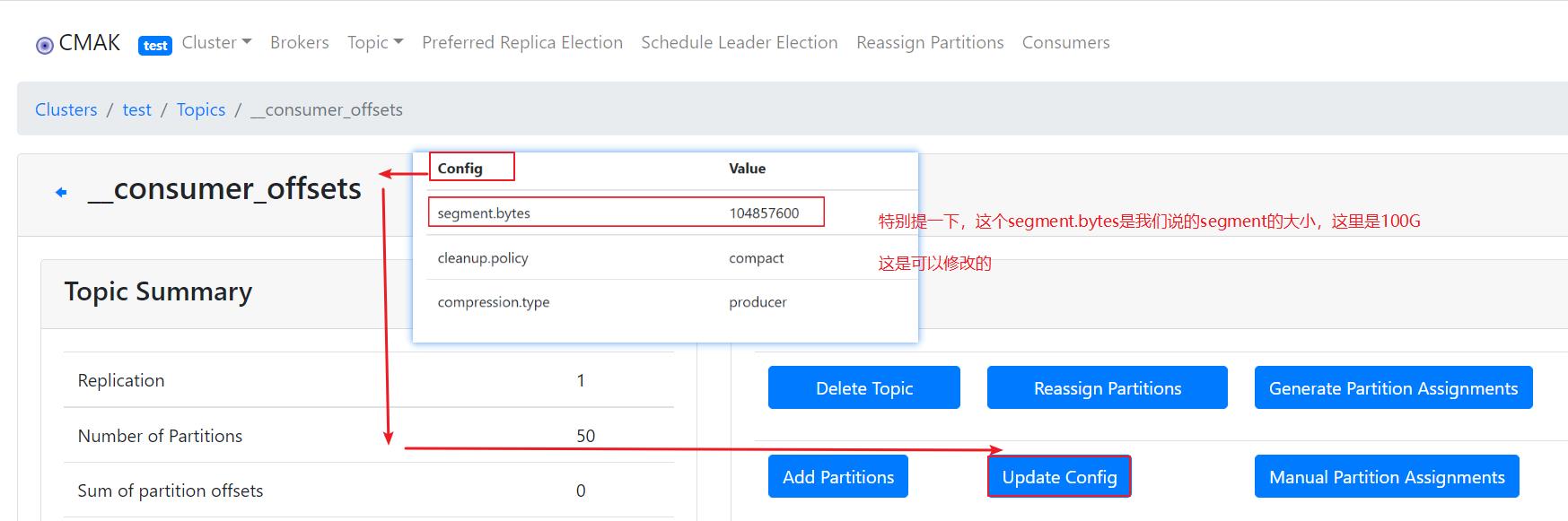
特殊地,segment_types是可以修改的,如下:
上图中有一个 delete topic 的蓝色的按钮,其实页面上默认无法删除topic,需要配置kafka的conf/server.properties 文件
# 删除topic
delete.topic.enable=true


注意:kafka如果生产消息的时候不会自动创建topic,所以如果topic不存在会报错,建议在server.properties文件中配置上
# 自动创建不存在的topic
auto.create.topics.enable=true
六、尾声
本文主要介绍了kafka的offset存储演变、kafka的持久化、kafka集群topic和partition数量设置、kafka可视化监控。
天天打码,天天进步!!
以上是关于解开Kafka神秘的面纱:kafka优雅应用的主要内容,如果未能解决你的问题,请参考以下文章