图解 Google V8 # 16:V8是怎么通过内联缓存来提升函数执行效率的?
Posted 凯小默
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解 Google V8 # 16:V8是怎么通过内联缓存来提升函数执行效率的?相关的知识,希望对你有一定的参考价值。
说明
图解 Google V8 学习笔记
什么是内联缓存?
内联缓存(Inline caching)是部分编程语言的运行时系统采用的优化技术,最早为Smalltalk开发。内联缓存的目标是通过记住以前直接在调用点上方法查询的结果来加快运行时方法绑定的速度。内联缓存对动态类型语言尤为有用,其中大多数(如非全部)方法绑定发生在运行时,因此虚方法表通常无法使用。
例子:
function loadX(o)
return o.x
var o =
x: 1,
y: 3
var o1 =
x: 3,
y: 6
for (var i = 0; i < 90000; i++)
loadX(o)
loadX(o1)
V8 获取 o.x 的流程:查找对象 o 的隐藏类,再通过隐藏类查找 x 属性偏移量,然后根据偏移量获取属性值。
上面这段代码中 loadX 函数会被反复执行,那么获取 o.x 流程也需要反复被执行。V8 为了加速函数执行采取的策略就是内联缓存 (Inline Cache),简称为 IC。
IC 的工作原理
V8 执行函数的过程中,会观察函数中一些调用点 (CallSite) 上的关键的中间数据,然后将这些数据缓存起来,当下次再次执行该函数的时候,V8 就可以直接利用这些中间数据,节省了再次获取这些数据的过程。
IC 过程
IC 会为每个函数维护一个反馈向量 (FeedBack Vector),反馈向量记录了函数在执行过程中的一些关键的中间数据。
函数和反馈向量的关系:
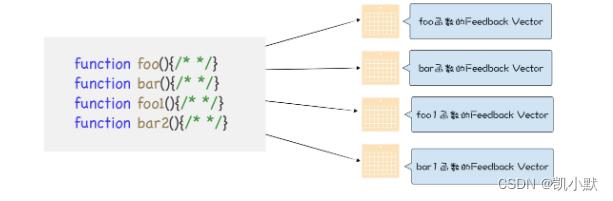
什么是反馈向量?
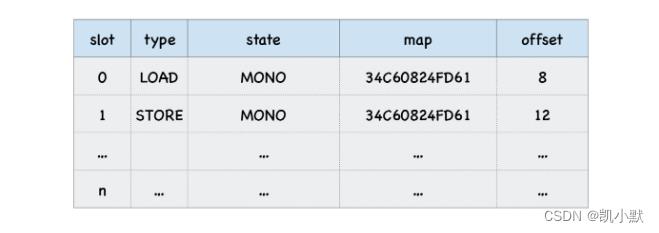
反馈向量其实就是一个表结构,它由很多项组成的,每一项称为一个插槽 (Slot),V8 会依次将执行 loadX 函数的中间数据写入到反馈向量的插槽中。
每个插槽中包括了插槽的索引 (slot index)、插槽的类型 (type)、插槽的状态 (state)、隐藏类 (map) 的地址、还有属性的偏移量。
例子:
function loadX(o)
o.y = 4
return o.x
比如上面代码,当 V8 执行这段函数的时候,它会判断 o.y = 4 和 return o.x 这两段是调用点 (CallSite),因为它们使用了对象和属性,那么 V8 会在 loadX 函数的反馈向量中为每个调用点分配一个插槽。
数据是如何被写入到反馈向量的?
例子:
function loadX(o)
return o.x
loadX(x:1)
我这里的字节码是:
[generated bytecode for function: loadX (0x023600253611 <SharedFunctionInfo loadX>)]
Bytecode length: 5
Parameter count 2
Register count 0
Frame size 0
Bytecode age: 0
00000236002537BE @ 0 : 2d 03 00 00 GetNamedProperty a0, [0], [0]
00000236002537C2 @ 4 : a9 Return
Constant pool (size = 1)
0000023600253791: [FixedArray] in OldSpace
- map: 0x023600002239 <Map(FIXED_ARRAY_TYPE)>
- length: 1
0: 0x023600253599 <String[1]: #x>
Handler Table (size = 0)
Source Position Table (size = 0)
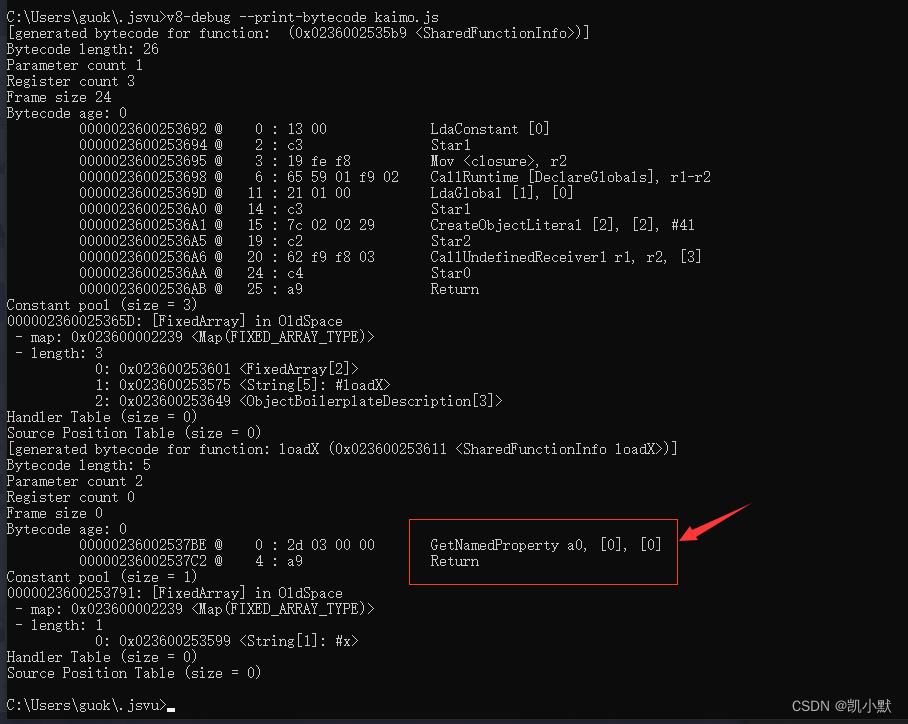
这里先保持跟李兵大佬的一样:
StackCheck
LdaNamedProperty a0, [0], [0]
Return
LdaNamedProperty:它的作用是取出参数 a0 的第一个属性值,并将属性值放到累加器中。
- a0 就是 loadX 的第一个参数;
- 第二个参数
[0]表示取出对象 a0 的第一个属性值。 - 第三个参数和反馈向量有关,它表示将
LdaNamedProperty操作的中间数据写入到反馈向量中,方括号中间的 0 表示写入反馈向量的第一个插槽中。
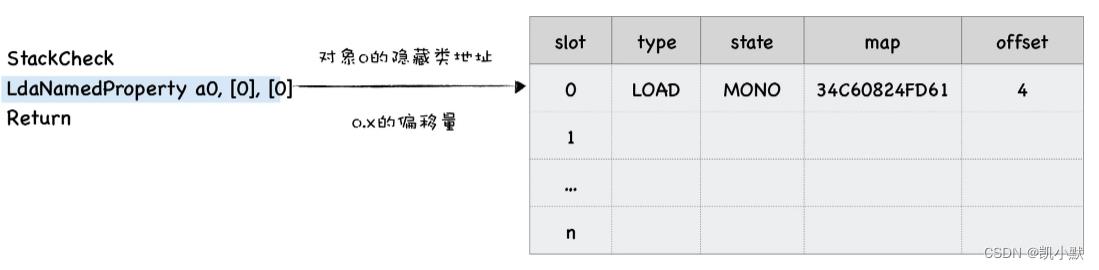
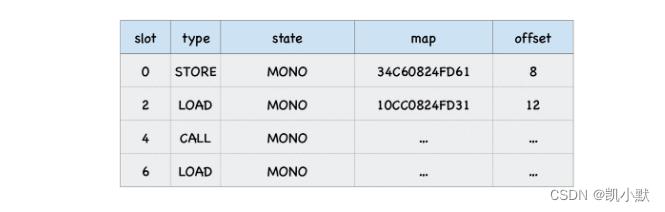
在函数 loadX 的反馈向量中,已经缓存了数据:
- 在 type 栏:缓存了操作类型,这里是 LOAD 类型。在反馈向量中,把这种通过
o.x来访问对象属性值的操作称为 LOAD 类型。 - 在 state 栏:缓存了插槽的状态 ,这里的 MONO (是单态 (monomorphic) 的缩写);
- 在 map 栏:缓存了 o 的隐藏类的地址;
- 在 offset 栏:缓存了属性 x 的偏移量;
存储 (STORE) 类型和函数调用 (CALL) 类型
function foo()
function loadX(o)
o.y = 4
foo()
return o.x
loadX(x:1,y:4)
字节码:
StackCheck
LdaSmi [4]
StaNamedProperty a0, [0], [0]
LdaGlobal [1], [2]
Star r0
CallUndefinedReceiver0 r0, [4]
LdaNamedProperty a0, [2], [6]
Return
字节码的执行流程:
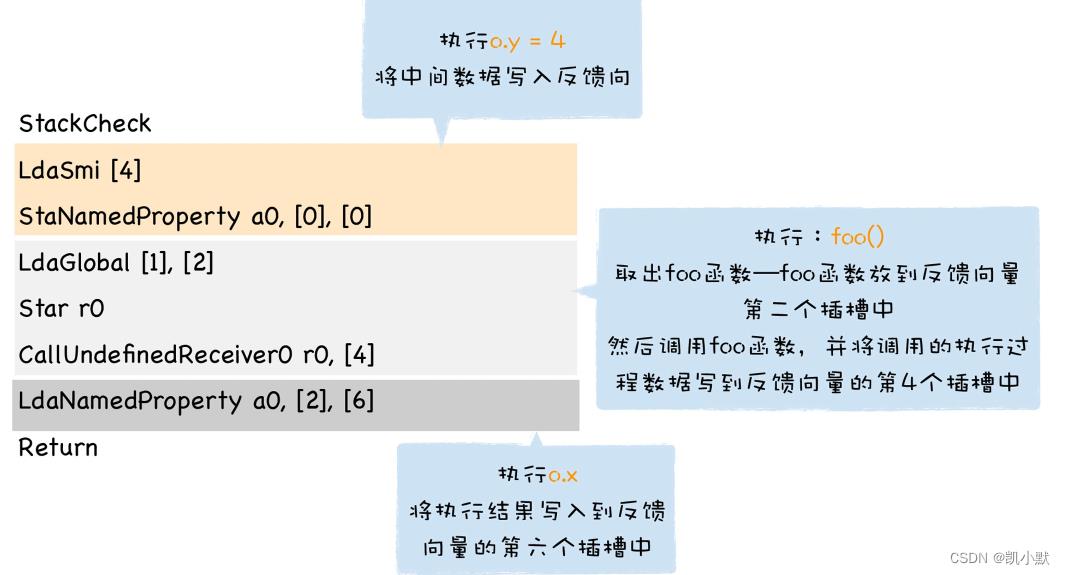
LdaSmi [4]:将常数 4 加载到累加器中StaNamedProperty:将累加器中的 4 赋给o.yLdaGlobal:加载 foo 函数对象的地址到累加器中CallUndefinedReceiver0:实现 foo 函数的调用
最终生成的反馈向量:
多态和超态
一个反馈向量的一个插槽中可以包含多个隐藏类的信息:
- 如果一个插槽中只包含 1 个隐藏类,那么我们称这种状态为单态 (monomorphic);
- 如果一个插槽中包含了 2~4 个隐藏类,那我们称这种状态为多态 (polymorphic);
- 如果一个插槽中超过 4 个隐藏类,那我们称这种状态为超态 (magamorphic)。
执行效率:

如果对象的形状不是固定的,意味着 V8 为它们创建的隐藏类也是不同的。V8 就无法使用反馈向量中记录的偏移量信息。
例子:
function loadX(o)
return o.x
var o =
x: 1,
y: 3
var o1 =
x: 3,
y: 6,
z: 4
for (var i = 0; i < 90000; i++)
loadX(o)
loadX(o1)
o 的隐藏类跟 o1 的隐藏类不是一个隐藏类,V8 会选择将新的隐藏类也记录在反馈向量中。

当 V8 再次执行 loadX 函数中的 o.x 语句时,同样会查找反馈向量表,进行比较。
利用 IC 性能优化
单态的性能优于多态和超态,尽量避免多态和超态的情况。
例子:下面两段代码,哪段的执行效率高,为什么?
let data = [1, 2, 3, 4]
data.forEach((item) => console.log(item.toString()))
let data = ['1', 2, '3', 4]
data.forEach((item) => console.log(item.toString()))
第一种方式效率更高。
- 第一种方式中,每一个item类型一样,后续几次调用toString可以直接命中,是单态。
- 第二种方式中,由于item类型间错不同,经常变换,就要同时缓存多个类型,是多态。
拓展资料
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于图解 Google V8 # 16:V8是怎么通过内联缓存来提升函数执行效率的?的主要内容,如果未能解决你的问题,请参考以下文章
图解 Google V8 # 17:消息队列:V8是怎么实现回调函数的?
图解 Google V8 # 08:类型转换:V8是怎么实现 1 + “2” 的?
图解 Google V8 # 06:原型链:V8是如何实现对象继承的?
图解 Google V8 # 03:快属性和慢属性:V8是怎样提升对象属性访问速度的?