山东大学云计算实验(生成语音对抗样本)
Posted Burger_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了山东大学云计算实验(生成语音对抗样本)相关的知识,希望对你有一定的参考价值。
软件环境:
华为云弹性服务器
最好选择西南-贵阳一、华东-上海一等有GPU加速型服务器的地区的GPU加速型服务器,这样在之后可以用英伟达的显卡加速;否则之后创建镜像再迁移很麻烦。
实验步骤与内容:
1.按照README.md,第一步安装docker没有问题。
2.从第二步运行setup.sh开始会报很多错(没有报类似错的请忽略),比如:
执行setup.sh中的docker build时没有权限,所以在前面加了sudo
pip install超时,在docker文件夹中的aae_deepspeech_041_gpu.dockerfile里面的第25行pip3之后加上--default-timeout=1000
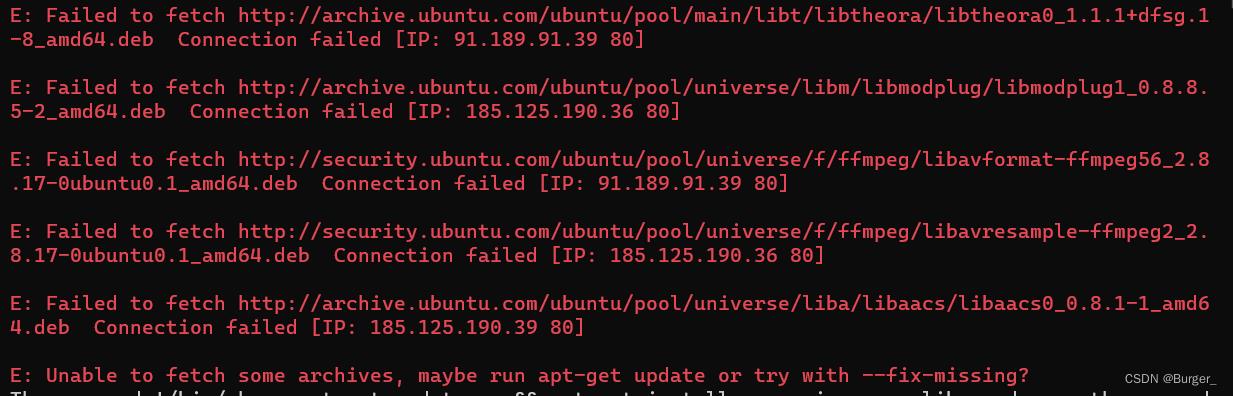
failed to fetch:
在执行它提示的apt-get update –fix-missing之后仍然报错,只不过少一些:
他说在/etc/resolv.conf里添加nameserver 8.8.8.8,照做,终于不报这个错了。

git clone(aae_deepspeech_041_gpu.dockerfile里的)又出现问题:
以下这几种方法都试过,也不知道是哪种导致最后成功了:
apt-get install curl git config --global --unset http.proxy git config --global --unset https.proxyhttps://zhuanlan.zhihu.com/p/378894743
https://zhuanlan.zhihu.com/p/378894743将“https://github.com/tom-doerr/DeepSpeech”的https改成http(应该是这个起作用了)

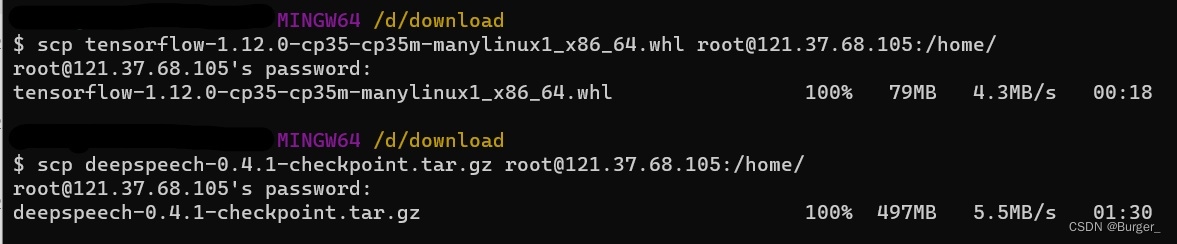
安装cpu版本的tensorflow的时候又出错了,timeout:
对于这样的大包,我们先把它下载到本地,再上传到云服务器(tensorflow-1.12.0-cp35-cp35m-manylinux1_x86_64.whl移动到项目的docker文件夹下,deepspeech-0.4.1-checkpoint.tar.gz移动到项目文件夹下):
#scp 本地文件路径 远程用户名@ip地址:远程路径 scp tensorflow-1.12.0-cp35-cp35m-manylinux1_x86_64.whl root@121.37.68.105:/home/ scp deepspeech-0.4.1-checkpoint.tar.gz root@121.37.68.105:/home/
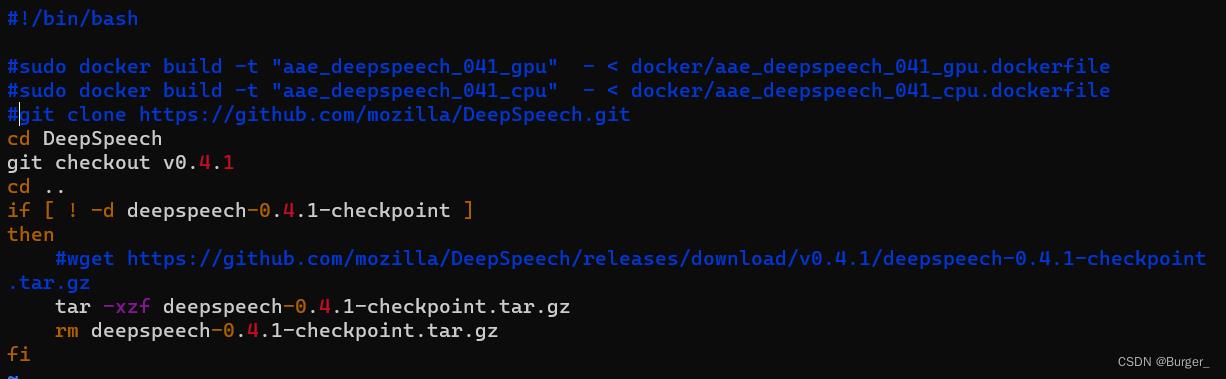
然后cd到docker文件夹下,修改aae_deepspeech_041_cpu.dockerfile的内容为:
FROM aae_deepspeech_041_gpu COPY tensorflow-1.12.0-cp35-cp35m-manylinux1_x86_64.whl /home RUN pip3 install /home/tensorflow-1.12.0-cp35-cp35m-manylinux1_x86_64.whl执行命令:
docker build -f aae_deepspeech_041_cpu.dockerfile -t "aae_deepspeech_041_cpu" .这样就解决了timeout的问题,成功安装tensorflow1.12的cpu版本。

成功构建gpu和cpu镜像之后应该是这样的(none应该是临时镜像不用管它):
cd到项目目录,修改setup.sh,根据自己的情况注释掉已经成功运行的命令:
最后setup.sh成功执行应该是这样:
查看项目文件夹发现deepspeech-0.4.1-checkpoint.tar.gz已经被解压且被删除:



3.华北-乌兰察布一的服务器没有装英伟达的驱动,所以我推测它没有英伟达显卡:
所以我们采用CPU的命令启动容器:
docker run -it --mount src=$(pwd),target=/audio_adversarial_examples,type=bind -w /audio_adversarial_examples aae_deepspeech_041_cpu


4.检查是否可以正确分离正常音频:
python3 classify.py --in sample-000000.wav --restore_path deepspeech-0.4.1-checkpoint/model.v0.4.1
(PS:最后一个单词应该是两个词is useless)

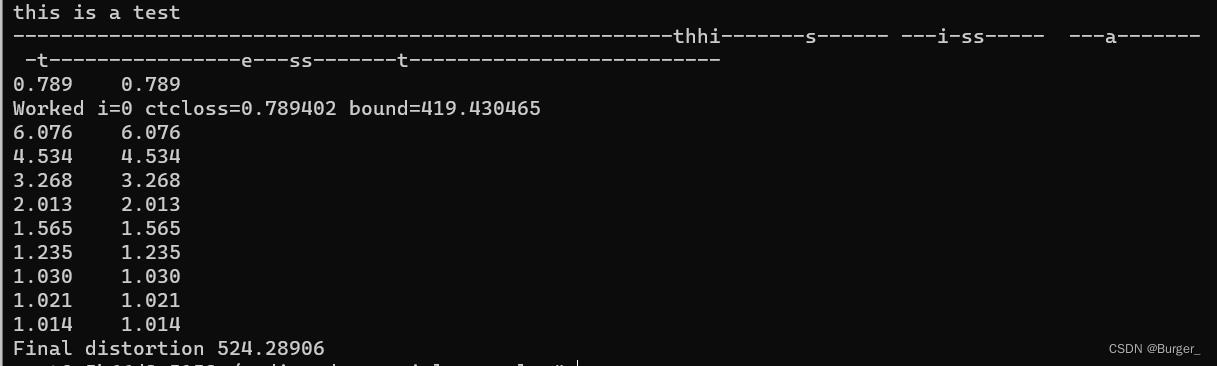
5. 生成对抗样本(CPU太慢了,可以将迭代数改少一点比如100):
python3 attack.py --in sample-000000.wav --target "this is a test" --out adv.wav --iterations 100 --restore_path deepspeech-0.4.1-checkpoint/model.v0.4.1
(PS:多核的CPU貌似可以使过程快一些)
6. 验证攻击成功:
python3 classify.py --in adv.wav --restore_path deepspeech-0.4.1-checkpoint/model.v0.4.1

7. 尝试一下GPU版本,报错:

就这样吧,累了,毁灭吧。
结论分析与体会:
1.单纯的把这个实验跑出来的话难度不算大,照着readme做就行。关键是运行setup.sh的时候出的错误真的让人心力憔悴。
2.为了解决clone GitHub失败的问题还去Gitee创建了仓库,但是改变成开源还需要等很长时间,Gitee不和Github学点好的,尽瞎整。这里给出DeepSpeech(https://github.com/mozilla/DeepSpeech.git)的Gitee仓库地址:https://gitee.com/liuburger/DeepSpeech
3.解决了报错之后没有必要删掉容器或镜像重新来过,再次运行setup.sh就可以,docker会自动采用之前的cache,但前提是你的docker必须一直处于运行状态、没有stop存有cache的容器。
4. 这里附上一些实用的docker命令:
#启动所有容器:
docker start $(docker ps -a | awk ' print $1 ' | tail -n +2)
#停止所有容器:
docker stop $(docker ps -a -q)写在最后
有问题欢迎在评论区探讨。
以上是关于山东大学云计算实验(生成语音对抗样本)的主要内容,如果未能解决你的问题,请参考以下文章