基于特征全埋点的精排ODL实践总结
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于特征全埋点的精排ODL实践总结相关的知识,希望对你有一定的参考价值。

本系列文章包含每平每屋过去一年在召回、排序和冷启动等模块中的一些探索和实践经验,本文为该专题的第三篇。
第一篇指路:冷启动系统优化与内容潜力预估实践
第二篇指路:GNN在轻应用内容推荐中的召回实践
前言背景
淘宝内的每平每屋频道是每平每屋业务获取C端流量并进行内容分发从而建立用户家居、生活方式心智场的主要阵地。在每平每屋频道中,内容主要以场景搭配为主,内容内挂载了多个商品锚点,点击商品锚点可以跳转到商品的详情页。

一直以来,我们结合业务特点利用算法技术提升用户浏览体验、流量分发效率和整体的系统生态。其中排序环节的迭代优化对于提升系统的分发效率至关重要,如下图展示在模型结构和样本特征两方面我们进行了大量的尝试和优化工作,但在模型训练方式的升级上进展缓慢。

在电商搜推等用户行为和环境不断变化的场景中,在线学习能够显著提高模型对于线上流量分布变化响应速度,但整个流程相比于离线学习会复杂很多,这其中包括实时曝光点击数据的收集,实时特征采集,流式样本生成,模型实时训练和更新等流程,这些流程环环相扣,既需要保证逻辑正确性还需要保证时效性。
在20年底我们曾探索过模型的实时在线学习,由于当时对Porsche和AOP等流式训练平台和组件的了解还不充分,只是初步走通了ODL模型训练的链路,并未在线上取得收益。在21年通过调研发现AMC特征中心的特征全埋点功能和porsche开发团队打造PyPorsche可以极大的简化ODL链路中的实时特征采集和样本生成流程,所以决定对原数据链路进行改造,并基于新的数据链路进行精排模型的ODL训练。
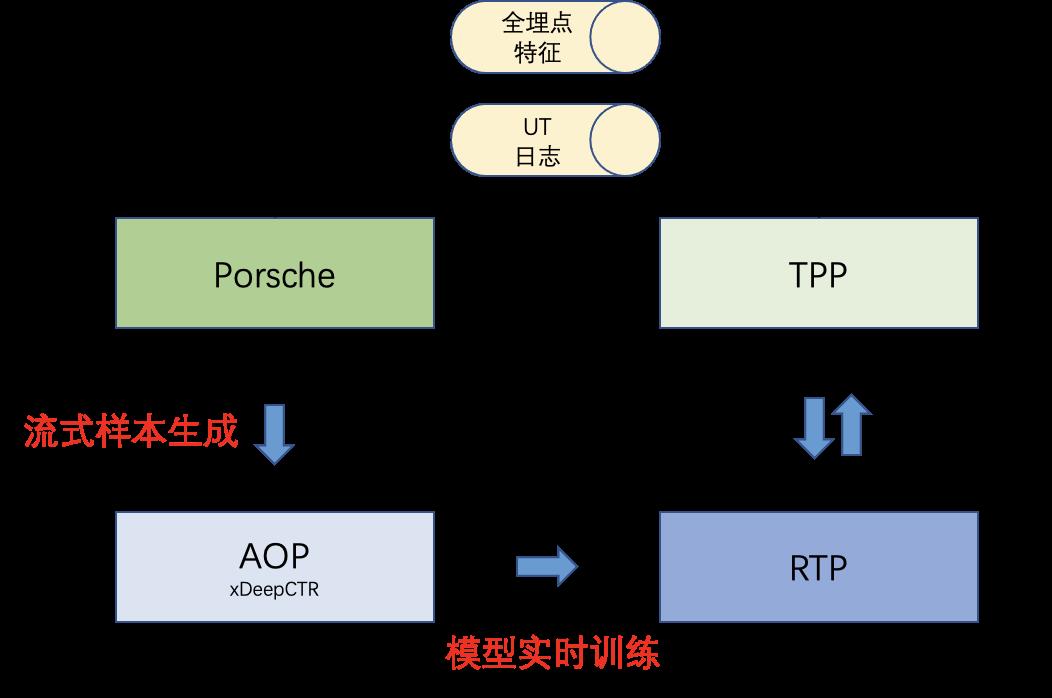
本文将从流式样本生成和模型实时训练两大块介绍每平每屋轻应用ODL链路搭建的实践经验,其中涉及到的AMC特征中心、PyPorsche、AOP和xDeepCTR等平台框架的使用方法请参考对应的文档,不再赘述。
流式样本生成
▐ 数据流架构
在每平每屋频道中,流式样本生成环节主要涉及到了:
UT行为日志解析
全埋点特征解析
ODL 训练样本生成

▐ UT行为日志解析
首先根据event_id,args,arg1以及trackkey,trackinfo等字段从UT日志流中过滤出业务所需的曝光和点击日志,并按一定格式写入TT用于在PyPorsche构建event。
以下是解析得到曝光日志并写入TT流的Blink代码片段,table中的字段可以根据实际需要更改:
create table r_ihome_lapp_content_expo
(
pvid VARCHAR,
user_id VARCHAR,
item_id VARCHAR,
server_timestamp VARCHAR
) with (
type='tt',
topic='dwd_ihome_lapp_content_expo_sample',
accessKey=''
);
INSERT INTO r_ihome_lapp_content_expo
select * FROM XXX WHERE YYY;▐ 特征全埋点
在上一环节可以获取到业务场景内产生的曝光TT流和点击TT流,但ODL模型的训练除了需要userid,itemid,label等基本信息外,还需要对应user侧,item侧以及context侧特征。利用AMC特征中心的特征全埋点功能可以对线上参与打分的现场特征进行完整记录并落盘到TT中。
▐ ODL 训练样本生成
上述两个环节完成后可以得到业务内的曝光点击以及全埋点特征TT流,接下来还需要将这些流数据按一定的规则进行关联,并产生最终可供ODL模型训练使用的流样本。
PyPorsche将ODL样本构建拆分为3个主要流程,分别为:
1. event流程构建
2. 流式样本骨架构建
3. ODL swift 样本构建
每一个流程环节只需要编写若干行Python代码即可完成开发。
event流程构建
首先对曝光/点击和全埋点特征TT流进行日志解析生成对应的event,在 PyPorsche 中,实时特征被称为 Event。
每个event表具有自己的schema和主键,注意event_ids为业务的唯一主键,index_fields中需填入后续会用于和其他表进行join操作的字段。
以下是将曝光的TT流解析并转换为对应event的代码片段:
tt_source = TTSource(TT(topic='dwd_ihome_lapp_content_expo_sample',
access_id='',
access_key=''),
parser_clazz='com.alibaba.pyporsche.ihome.IhomeLappLogParser',
schema=ihome_tt_schema)#schema
tt_source = session.register_table(tt_source)
ihomelapp_sink = session.register_table(
EventSink(Event(event_name=EVENT_NAME_EXPO, event_ids=['pv_id', 'item_id'],
index_fields=['pv_id', 'user_id', 'item_id'])))
tt_source.insert(ihomelapp_sink)在上面的片段中,曝光event具有5个字段,其中pv_id,item_id,user_id,record_timestamp 这4个属性是通过ihome_tt_schema定义得到,而event_id是通过event_ids指定根据pv_id和item_id拼接得到。表的schema如下:

注意,由于xDeepCTR 3.0中将label放置在了features字段中,需要在xfc_event构建时将label特征从fg.json中移除,否则可能会导致最终产出的流式样本label为空。
流式样本骨架构建
在backbone的构建中,需指定一个主event,并从主event出发关联起若干event。在每平每屋场景中,曝光event被作为主event并以keyed_join的形式关联起一跳点击event和详情页的二跳点击event以及对应的全埋点特征event。
以下是将曝光event,一跳点击和二跳点击以及全埋点特征event进行关联并产生backbone的代码片段:
pv_event = session.get_table('event.' + EVENT_NAME_EXPO) # 主event
full_tracking_event = session.get_table('event.' + EVENT_NAME_FULL_TRACK)
click_event = session.get_table('event.' + EVENT_NAME_CLICK)
detail_click_event = session.get_table('event.' + EVENT_NAME_DETAIL_CLICK)
wide_table = pv_event.keyed_join(click_event, condition='pv_id=pv_id,item_id=item_id',
join_type='ONE_TO_MANY', left_wait_second=630,tps=100)
wide_table = wide_table.keyed_join(detail_click_event, condition='pv_id=pv_id,item_id=item_id',
join_type='ONE_TO_MANY', left_wait_second=1,tps=100)
output_table = wide_table.keyed_join(full_tracking_event, 'pv_id=pv_id,item_id=item_id', join_type='ONE_TO_ONE',
left_wait_second=-630,tps=3000)
output_table.insert(session.register_table(BackboneSink(Backbone(BACKBONE_NAME))))通过prosche任务页面的监控可以看到在当前等待时间下各event中数据被join上的的比例,pos表示join上的记录,neg表示没有被join上的记录,根据丢弃比例可以调整等待时间left_wait_second。
ODL swift 样本构建
ODL模型训练样本构建环节需要将backbone中的相关字段进行提取并转化为模型训练要求的格式。另外,为了方便复用原来的批模型(基于xDeepCTR的单source多label形式),我们采取的是在单数据源中包含多目标样本的方式,所以还需要在这个环节将多个目标的label字段拼接到features字段中,使得模型能够识别。
在最后的sink环节定义的swift name就是ODL模型训练任务中数据源的swift_topic。为了便于验证样本的正确性,可以将一定比例的样本写入TT回流到ODPS中进行离线数据分析。
下面是对backbone进行LG并产生swift样本的代码片段:
backbone = session.get_table(BACKBONE_NAME)
# lg
wide_table = backbone.select('*, event_'+EVENT_NAME_FULL_TRACK+'_features as features')
wide_table = wide_table.join_lateral(Lg('*', lgClass='com.alibaba.pyporsche.ihome.IhomeLappClickLG'))
wide_table = wide_table.filter("features IS NOT NULL")
wide_table = wide_table.with_column(AddLabelToFeatures('features,label', label_name="click_label").as_('features'))
# fg
wide_table = wide_table.select('event_id as uniqueId, features, label, type')
# sink tt
tt_sink = TTSink(TT(topic='ihome_lapp_rank_sample_tt', access_key=''),
line_separator='\\n', field_separator='\\t')
tt_sink = session.register_table(tt_sink)
wide_table.filter('rand() < 0.1').insert(tt_sink)
# swift sink
swift_sink = session.register_table(SwiftSink(Swift('ihome_lapp_rank_sample_event')))
wide_table.insert(swift_sink)▐ 样本质量监控
AMC算法质量监控中心提供了流样本的监控功能,在这里可以观测到样本的产出延迟,消费延迟和样本比例以及特征的取值统计等信息。

模型实时训练
模型的训练环节使用xDeepCTR框架在AOP平台上进行。
对比使用批样本训练模型,使用流样本训练模型在配置文件上需要做以下两处改动:
在主入口类文件main_op_aop.py中指定ODL模型从哪个全量训练的模型版本进行参数初始化
在训练配置user_params.json中指定使用流样本数据源,并配置实时参数推送的hook
下面以xDeepCTR中内置的MMOE模型为例说明从离线学习切换为在线学习的主要改动:
▐ 模型参数初始化
实时训练的模型数据源为swift样本,在入口文件中将source配置为空串即可,AOP会加载user_params.json中指定的数据源进行训练。
通过train_from_model和train_from_version参数可以指定ODL模型初始化时的参数来自于哪个模型和对应的版本。
from aop import odps_table, tf_train, AOPClient
if __name__ == '__main__':
fg_path = './ihome_rank_model_fg.json'
user_params_path = "./user_params.json"
algo_conf_path = './algo_conf.json'
running_config_path = "./running_config.json"
repo_name = 'xDeepCTR'
zip_name = './' + repo_name + '.zip'
model_path = repo_name + '/xdeepctr/models/multitask/mmoe.py'
model_name = "ihome_rank_demo_mmoe_odl"
ACCESS_ID = 'XXXX'
ACCESS_KEY = 'YYYY'
source = ""#source为空串即可
train = tf_train(source,
fg_config=fg_path,
model_path=model_path,
model_name=model_name,
user_params=user_params_path,
train_from_model='ihome_rank_demo_mmoe',#使用ihome_rank_demo_mmoe模型的最新版本来初始化
train_from_version='NEWEST', # NEW NEWEST
ps_num=2,
worker_num=3,
)
with AOPClient(model_name) as client:
client.add_code(zip_name)
client.add_resource(algo_conf_path)
client.add_debug_version("aop_version_tf112")
client.add_runconf(running_config_path)
client.run(train)▐ 实时数据源和参数更新
需要user_params.json修改数据源配置,并添加一个发送参数至RTP的hook。相比于批模型的训练方式read_mode从odps_single变更为了swift_single,含义为从一份swift 样本中读取训练数据,若为多份样本可以使用swift。
在source配置中,swift_topic为PyPorsche的ODL样本生成节点中配置的swift名称,通常sample_name和swift_topic保持一致即可。
最后需要在customized_functions中添加一个odl_model_updatehook,我们使用PS直发的方式将实时训练的模型参数定期发送至RTP,其中dense参数以5分钟的间隔发送,sparse参数以15分钟的间隔发送。除了添加hook外,还需要在代码中打开optimizer 的open_auto_record开关,并对RTP进行设置调整,详细步骤可参阅AOP和RTP相关文档。
下面是一个ODL模型的配置例子:
"customized_functions":
"odl_model_update":
"open": true,
"is_sync": true,
"rtp_table_name": "ihome_rank_demo_mmoe_odl",
"rtp_table_topic": "ihome_rank_demo_mmoe_odl_swift_$today",
"swift_partition_count": 32,
"swift_partition_max_buffer_size": 5120,
"reuse_topic" : false,
"interval_time": 300,
"dense_send_interval_time": 300,
"sparse_send_interval_time": 900,
"first_trigger_time": 600,
"global_auc_threshold": "0.68",
"current_auc_threshold": "0.68",
"part_strategy": "div",
"check_numerics": false
▐ 流程调度
在实验阶段以7天为周期对ODL模型进行重新加载批模型参数初始化和在线学习。一个完整的ODL任务涉及到了
批模型训练并产出模型版本
ODL模型从批模型加载参数初始化并创建新版本
ODL模型新版本和参数更新的topic配置推送到rtp,等待RTP进行模型索引构建和切换
ODL训练任务启动,定期推送更新的参数至RTP
整个流程涉及到了不同任务的调度和对RTP索引构建和业务切换状态的监控,AOP pipeline对上述业务逻辑进行了抽象并提供了一套api供算法同学串联起全流程并定期调度。
▐ 在线参数生效监控
当一切流程正常运行后,可以通过AOP-模型管理中的增量版本菜单查看线上参数是否生效以及生效的时间。
参数更新的状态包括3种:
FINISHED:已发送且确认上线完成,该状态下会产出生效时间
PUSH_ONLINE:已发送待确认
SWITCH_TIMEOUT:超过6个小时没切换完成

注意如果修改过odl_model_update的emb_size_thd可能导致该功能无法正常产生结果。这是因为模型部署时RTP会按一定规则产生sparse和dense两种索引,修改该参数会导致对一些变量检测时查了另外的索引,从而无法获取的对应变量的更新状态。
业务效果
在淘宝每平每屋频道首页推荐tab场景中,我们分别在日常和大促期间进行了线上AB实验,结果表明ODL模型相较于天级更新的模型具有明显的效果提升。在日常期间CTR+7.83%/人均曝光+2.15%/人均点击+10.15%/人均详情页点击+9.56%。在双11当天ODL模型在浏览深度和二跳转化目标的提升上更加显著,CTR+7.04%/人均曝光+3.94%/人均点击+11.26%/人均详情页点击+13.03%,说明ODL模型在流量分布发生剧烈变化的情况下的快速适应能力。
ODL流样本中使用到了全埋点特征,我们在离线批模型中单独验证了全埋点特征的收益,在日常期间CTR+6.83%/人均曝光+0.82%/人均点击+7.70%/人均详情页点击+7.11%,ODL在此基础上进一步提升了人均浏览篇数和点击效率。

总结
实时化对于推荐系统捕捉用户的兴趣和流量分布变化非常关键,本文介绍了每平每屋频道精排模型向ODL升级的实践总结,深度模型的在线学习对整个系统具有极大的挑战,充分利用集团内部的平台和工具可以大幅缩短ODL链路搭建所需的时间,推动在线学习的落地并取得收益。
未来我们会在模型的在线学习方面进行持续的迭代和优化,包括将其扩展至重排/粗排以及冷启动等环节,探索流式训练场景下的数据Non-IID问题/label延迟问题以及参数更新梯度衰减等问题,并进一步提升实时链路的稳定性和正确性,以期获得更大的业务效果。
团队介绍
大淘宝技术-淘宝智能团队
淘宝智能团队是一支数据和算法一体的团队,服务于淘宝、天猫、聚划算、闲鱼和每平每屋等业务线的二十余个业务场景,提供线上零售、内容社区、3D智能设计和端上智能等数据和算法服务。我们通过机器学习、强化学习、数据挖掘、机器视觉、NLP、运筹学、3D算法、搜索和推荐算法,为千万商家寻找商机,为平台运营提供智能化方案,为用户提高使用体验,为设计师提供自动搭配和布局,从而促进平台和生态的供给繁荣和用户增长,不断拓展商业边界。
这是一支快速成长中的学习型团队。在创造业务价值的同时,我们不断输出学术成果,在KDD、ICCV、Management Science等国际会议和杂志上发表数篇学术论文。团队学习氛围浓厚,每年组织上百场技术分享交流,互相学习和启发。真诚邀请海内外相关方向的优秀人才加入我们,在这里成长并贡献才智。
如果您有兴趣可将简历发至weichen.swc@alibaba-inc.com,期待您的加入!
✿ 拓展阅读

作者|阅谦
编辑|橙子君
出品|阿里巴巴新零售淘系技术


以上是关于基于特征全埋点的精排ODL实践总结的主要内容,如果未能解决你的问题,请参考以下文章
Gradient Normalization在多任务学习中的优化实践
推荐系统[八]算法实践总结V2:排序学习框架(特征提取标签获取方式)以及京东推荐算法精排技术实战