内容推荐场景中自监督学习的应用
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内容推荐场景中自监督学习的应用相关的知识,希望对你有一定的参考价值。

本系列文章包含每平每屋过去一年在召回、排序和冷启动等模块中的一些探索和实践经验,本文为该专题的第七篇。
第一篇指路:冷启动系统优化与内容潜力预估实践
第二篇指路:GNN在轻应用内容推荐中的召回实践
第三篇指路:基于特征全埋点的精排ODL实践总结
第四篇指路:Gradient Normalization在多任务学习中的优化实践
第五篇指路:生成式重排在内容推荐中的应用实践
第六篇指路:无尽流场景优化总结
背景介绍
在机器学习学界,无监督学习 (或者自监督学习) 一直被认为是最有价值的领域之一。在ISSCC 2019上,著名的人工智能研究者,图灵奖获得者Yann LeCun给出了他的“蛋糕图”2.0版本,并再次强调了自监督学习的地位,认为自监督学习是通向未来通用人工智能的可能道路。

其实,自监督学习并不是一个新概念,在NLP领域,已经有非常多相关的应用。自监督学习的本质,是通过数据本身来构造训练目标,从而达到不需要人工标注的目的。例如,word2vec,使用skip-gram的训练方式,是通过单词来预测上下文;之后Google提出的Bert,则是通过Masked LM和Next sentence prediction来实现pre-training。本质上都是利用了原有数据来构造训练目标。
自监督的学习方式,与我们的实际场景契合度很高。在现实世界中,海量数据并不存在所谓的标签体系,例如在内容维度,作者们创作的图像、文字,既无法套入一个标准的标签体系,也不可能存在一个标注团队可以处理每天百万级的数据。通过自监督学习的方式来获取这部分信息成为了一条必由之路。
每平每屋轻应用是是淘系大家装垂类中的主要流量入口,以内容导购的形式满足用户在家居领域的购买需求。在去年Visual4Rec的工作(详见https://mp.weixin.qq.com/s/LmON8pQ8TvPTfN2spblzDQ)中,我们主要通过预训练好的图像embedding,对精排、召回以及EE三个环节做了优化取得了不错的线上结果。在去年工作基础之上,我们希望进一步探究自监督学习得到的embedding质量对推荐、分类、搜索的影响。我们尝试了2020年以来部分图像自监督学习模型在图像embedding抽取、达摩院M6预训练模型在多模态embedding抽取中的效果,并在线下线上不同环节做了详实的验证。本文为琢切在每平每屋算法团队实习期间的工作总结。
理论基础
▐ 图像自监督学习
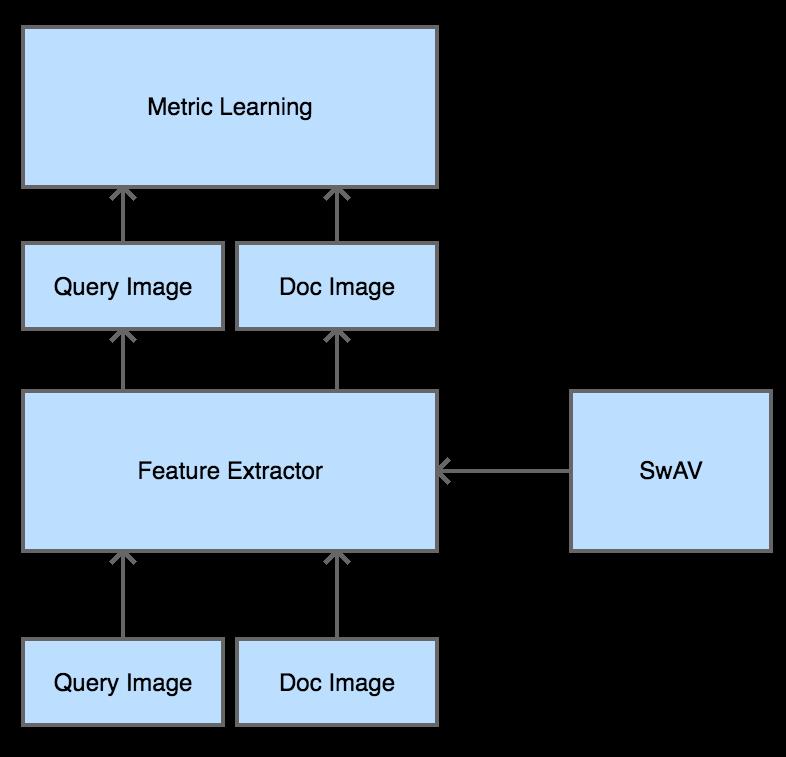
自2020年以来,图像自监督算法在学术界取得了巨大进展,基于图像随机变换 + infoNCE loss 的设计范式,一步步刷新SOTA,基于自监督算法训练得到的无监督图像embedding,在下游使用线性分类器,其分类准确率开始逐步接近甚至超越使用CNN训练的分类准确率。在实际场景中,我们主要使用了EVTorch团队提供的Moco v2 [1] 模型、SwAV [2] 模型做为测试验证。在此简单介绍SwAV的模型原理。Fig1 展示了SwAV和一般的自监督对比学习的核心差异。

Fig1 SwAV与一般自监督对比学习的差异
一般的自监督对比学习,主要通过图像的随机transform(例如随机加入少量噪点、颜色轻微变化、随机裁剪等),如下所示。我们认为,这样的轻微变化,对于图像本身的语义表达是没有影响的。

Fig2 图像随机Transform举例
同一张图的不同transform做为正样本,不同图的不同transform做为负样本,在embedding层面进行对比训练,如下所示

其中 为编码函数(表示学习方程),
为编码函数(表示学习方程), 与
与 为正样本,
为正样本, 与
与 为负样本集合,通过上述公式进行优化。
为负样本集合,通过上述公式进行优化。
从上述式子中我们可以发现,假设在一个百万级的数据集上,做embedding之间的两两比较,其计算开销是非常庞大的。学术界对此提出了一些解决办法,例如Moco系列的memory bank的思想,就是对embedding本身做近似,将历史上计算过的embedding存入一个memory bank中,用于后续的对比学习。而SwAV算法在此基础上提出,或许我们并不需要对两两图片对的embedding都做对比学习,可以将任务做近似,先对embedding做聚类,然后通过聚类来学习两两之间的关系。在Fig1 中, 代表直接由编码函数输出的embedding,
代表直接由编码函数输出的embedding, 表示映射矩阵,将embedding映射到聚类Prototype上,即
表示映射矩阵,将embedding映射到聚类Prototype上,即 ,在一个batch中,通过Swapped Prediction来拉近正样本之间的距离,通过不同图之间引入聚类的均匀间隔限制来保证负样本之间的聚类距离。具体公式如下:
,在一个batch中,通过Swapped Prediction来拉近正样本之间的距离,通过不同图之间引入聚类的均匀间隔限制来保证负样本之间的聚类距离。具体公式如下:
Swapped Prediction, 为
为 的映射向量,作者认为同一张图的不同变化生成的embedding,经过不同映射向量,应该映射到同一个cluster
的映射向量,作者认为同一张图的不同变化生成的embedding,经过不同映射向量,应该映射到同一个cluster
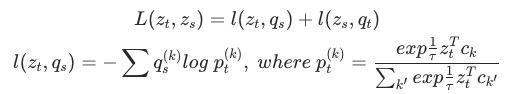
聚类均匀限制,即同一batch中,不同图像对应的cluster会被均匀选择到

SwAV算法,通过将embedding之间的对比学习简化成聚类之间的对比学习,大幅降低了计算开销,同时在在线聚类时引入了均匀限制,使得模型不会陷入到平凡解,从而获得了高质量的图像自监督embedding。
▐ M6多模态预训练
M6(Multi-Modality to Multi- Modality Multitask Mega-transformer)是阿里集团达摩院研发的基于稀疏MoE的多模态预训练模型。在万亿级别参数的预训练模型基础上,使用淘系商品数据进行对比学习,获得我们最终使用的模型。稀疏MoE可以在增加参数量的情况下,保持较低的计算开销,在Whale框架的支持下,可以获得较好的计算效率。稀疏MoE定义如下
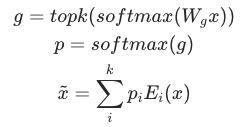
其中 为输入的representation,经过gate函数的参数
为输入的representation,经过gate函数的参数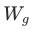 计算后,再经过softmax,得到的weight中取top
计算后,再经过softmax,得到的weight中取top 个。假设总共有
个。假设总共有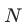 个expert,其中
个expert,其中 ,筛选得到top
,筛选得到top  的gate值之后再经过一次softmax计算,得到最终用于和expert输出值相乘的weight。
的gate值之后再经过一次softmax计算,得到最终用于和expert输出值相乘的weight。 为expert i的输出结果。在实际使用中,模型的每次运算只使用了有限个expert的输出,可以减少一部分计算量。
为expert i的输出结果。在实际使用中,模型的每次运算只使用了有限个expert的输出,可以减少一部分计算量。
在分布式训练场景下,我们可以进一步将不同的experts置于不同的worker,在具体工程实现中需要考虑load balance以保证稀疏设置的合理性。具体实现和算法实现可以参考 [4]
场景实践
▐ 场景、风格KNN召回一致率
在每平每屋轻应用场景,使用轻应用内容封面图训练了Moco v2、SwAV两版自监督图像模型,并分别对图像提取embedding;此外使用M6 预训练模型对轻应用内容的封面标题提取多模态embedding;我们对比的baseline为当前线上使用的预训练图像embedding。对比方式为使用种子内容(seed),基于不同embedding的KNN召回的结果,对比召回内容的场景、风格标签和种子内容的场景、风格标签的一致率,指标越高,表明一致性越好。计算方式为欧式距离。这一对比,主要可以体现出内容embedding在场景、风格方面的语义表达能力,一定程度上可以反映embedding的语义表达能力。+w 代表对embedding做白化处理后的结果。对embedding进行白化操作后再执行KNN召回,主要是参考文献[5]。在Bert模型的输出embedding基础上进行白化处理,可以大幅提升召回的相关性。Table1 为记录的结果
特征 | 召回内容风格一致率 | 召回内容场景一致率 |
Online | 0.63551 | 0.62783 |
Online + w | 0.63704 | 0.63452 |
Moco-v2 | 0.61398 | 0.68160 |
Moco-v2 + w | 0.61538 | 0.68738 |
SwAV | 0.64229 | 0.71147 |
SwAV + w | 0.64566 | 0.71604 |
M6 (32 dim) | 0.70252 | 0.70288 |
M6 + w (32 dim) | 0.71607 | 0.70221 |
Table1 不同embedding在风格、场景召回一致率表现
结果分析
Moco v2在风格一致率上略低于基线,而在场景一致率上优于基线,总体来看,优势并不明显。M6与SwAV输出的embedding在风格、场景的召回一致率上都显著优于Moco v2以及线上使用的embedding基线。
M6的风格召回一致率上显著优于其他embedding,我们在进一步调查后发现这主要来自于标题提供的信息,在标题中会有大量关于风格的描述性语句
白化操作在各个embedding基础上都会带来额外提升,这主要是由于我们使用欧式距离的计算,是基于欧式空间的假设,白化操作可以在embedding原有几何空间基础选择合适的标准正交基,可以拟合欧式空间假设,这也符合文献[5]中提到的假设。
可视化

从可视化结果中也可以发现,线上使用的embedding以及Moco v2产出的embedding,在KNN召回后还是存在一些bad case,而SwAV和M6召回结果则直观得看起来更好一些。此外,我们可视化主要使用了封面主图,SwAV做为纯图像的embedding,在视觉一致性上要优于M6的结果,后者使用了封面图以及内容的标题。
▐ M6&SwAV内容封面特征加入排序
在KNN召回的实验中,我们初步验证了SwAV、M6产出的embedding在某些语义表达维度具有优势,下面我们进一步验证在线上精排模型中加入M6&SwAV的embedding之后的auc指标变化情况(粗体为最优指标,下划线为次优),如下所示。在全部特征中,我们仅对封面图的embedding特征进行增添或者替换。对比基准为不使用内容封面图embedding特征的特征集合,3个实验分别为:1. 只添加了内容封面图预训练embedding特征,2. 只添加了内容封面图SwAV自监督学习获得的图像embedding特征,3. 只添加内容标题 + 封面图的M6预训练embedding特征。其中SwAV和M6的embedding都经过了白化处理。

在内容点击、详情页点击、商详页点击三个任务预测的auc值,其中全量数据测试,我们选取了两个时间段训练测试。此外为了进一步验证效果,我们针对近7天新发布的内容也做了测试。所有实验均3次运行后取平均值以及方差值,具体结果如下所示
特征 | ctr_auc | ctcvr_auc | 商详页行为_auc |
No Image Feature | 0.65426 ± 0.00125 | 0.67302 ± 0.00506 | 0.68214 ± 0.00970 |
Online | 0.65545 ± 0.00035 | 0.67250 ± 0.00408 | 0.67486 ± 0.00812 |
M6 + w | 0.65570 ± 0.00127 | 0.67673 ± 0.00411 | 0.68759 ± 0.00655 |
SwAV + w | 0.65568 ± 0.00144 | 0.67572 ± 0.00651 | 0.68547 ± 0.01055 |
Table2 0611~0617训练0618测试
特征 | ctr_auc | ctcvr_auc | 商详页行为_auc |
No Image Feature | 0.66242±0.00096 | 0.68005±0.00273 | 0.68821±0.00550 |
online | 0.66649±0.00051 | 0.68404±0.00351 | 0.68670±0.00514 |
M6 + w | 0.66509±0.00151 | 0.68450±0.00513 | 0.69332±0.01052 |
SwAV + w | 0.66402±0.00095 | 0.68324±0.00076 | 0.69033±0.00173 |
Table3 0701~0707测试0708测试
模型 | ctr_auc | ctcvr_auc | 商详页行为_auc |
No Image Feature | 0.71587±0.00454 | 0.73770±0.00419 | 0.70397±0.00985 |
online | 0.71907±0.00588 | 0.74005±0.00521 | 0.71821±0.01793 |
M6 + w | 0.72516±0.00113 | 0.74885±0.00574 | 0.71666±0.00317 |
Table4 最近7天新发布内容auc情况对比
结果分析
新增内容的图像embedding特征或者多模态embedding特征,在三个任务的离线auc指标上,对比没有使用这样特征的基线都有一定提升提升,提升相对稳定。
使用不同时期的训练测试数据,加入M6 embedding都对比使用线上embedding略有提升或基本持平。此外我们进一步在近7天发布的新内容测试中发现,M6 embedding的提升会更为明显一些,这表明对于缺乏统计类特征的新发布内容,M6多模态特征会扮演更重要的角色,对离线auc指标的提升也更为明显。
线上我们对加入M6 embedding的模型进行了线上ab,7天观察pctcvr +2.6%,avg_ipv +1.51%
▐ 其他场景
图像分类
大量图像自监督学习的论文都实验验证了,基于预训练的自监督模型在下游任务(分类/检测等)上Finetune的效果要优于end2end的训练方式。这里,我们基于预训练的SwAV模型,在躺平好货场景的图像上进行叶子类目的分类模型实验,总共3519个类目,使用SwAV预训练的模型作为Backbone,效果优于直接使用ResNet50模型的分类器效果。

Type | top1-accuracy | top-5 accuracy |
ResNet50 | 73.72% | 92.85% |
SwAV | 74.67% | 93.22% |
Table5 SwAV预训练对下游分类任务的提升
度量学习
在躺平好货的图搜场景,我们主要使用度量学习的方式来优化图像特征,主要评估指标为召回的商品的Identity Recall@N,即召回的Top-N商品中含有与query图属于相同商品的query数占总query数的比例。由于我们的测试集为目标检测 + 商品锚点信息自动合成的数据集,具有一定的噪声,同时每个query图仅对应一个真实的相同商品(实际上一个query可以对应多个商品),因此得到的指标会偏低。结论是使用预训练的自监督模型作为Backbone,效果会更好。
Identity Recall | R@1 | R@5 | R@10 | R@15 | R@20 |
no-pretrain | 11.56% | 18.55% | 21.47% | 22.62% | 24.26% |
pretrained | 14.23% | 21.85% | 25.28% | 26.68% | 28.97% |
Table6 SwAV预训练对下游度量学习任务的提升
结果分析:使用预训练的自监督模型对下游任务进行Finetune能够带来较为明显的提升。
总结
利用海量无标签数据进行自监督训练,可以极大程度上利用业务中的实际数据,同时解耦了对大规模预训练的标签依赖(例如使用ImageNet的预训练),也更贴近实际业务场景。通过SwAV、M6等方法进行预训练得到的embedding具有良好的语义表达特性,不仅在推荐效果上有所提升,SwAV自监督获取的embedding对实际业务场景的图像分类、图像搜索模型也有稳定的提升。
参考文献
[1] Chen, Xinlei, et al. "Improved baselines with momentum contrastive learning." arXiv preprint arXiv:2003.04297 (2020).
[2] Caron, Mathilde, et al. "Unsupervised learning of visual features by contrasting cluster assignments." arXiv preprint arXiv:2006.09882 (2020).
[3] Lin, Junyang, et al. "M6: Multi-Modality-to-Multi-Modality Multitask Mega-transformer for Unified Pretraining." (2021).
[4] Wang, An, et al. "Exploring Sparse Expert Models and Beyond." (2021).
[5] Sun, Jianlin, et al. "Whitening Sentence Representations for Better Semantics and Faster Retrieval." (2021).
团队介绍
大淘宝技术-淘宝智能团队
淘宝智能团队是一支数据和算法一体的团队,服务于淘宝、天猫、聚划算、闲鱼和每平每屋等业务线的二十余个业务场景,提供线上零售、内容社区、3D智能设计和端上智能等数据和算法服务。我们通过机器学习、强化学习、数据挖掘、机器视觉、NLP、运筹学、3D算法、搜索和推荐算法,为千万商家寻找商机,为平台运营提供智能化方案,为用户提高使用体验,为设计师提供自动搭配和布局,从而促进平台和生态的供给繁荣和用户增长,不断拓展商业边界。
这是一支快速成长中的学习型团队。在创造业务价值的同时,我们不断输出学术成果,在KDD、ICCV、Management Science等国际会议和杂志上发表数篇学术论文。团队学习氛围浓厚,每年组织上百场技术分享交流,互相学习和启发。真诚邀请海内外相关方向的优秀人才加入我们,在这里成长并贡献才智。
如果您有兴趣可将简历发至weichen.swc@alibaba-inc.com,期待您的加入!
✿ 拓展阅读




作者|邦祝
编辑|橙子君


以上是关于内容推荐场景中自监督学习的应用的主要内容,如果未能解决你的问题,请参考以下文章