推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )
Posted 天泽28
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )相关的知识,希望对你有一定的参考价值。
推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )
推荐系统系列博客:
- 推荐系统(一)推荐系统整体概览
- 推荐系统(二)GBDT+LR模型
- 推荐系统(三)Factorization Machines(FM)
- 推荐系统(四)Field-aware Factorization Machines(FFM)
- 推荐系统(五)wide&deep
- 推荐系统(六)Deep & Cross Network(DCN)
- 推荐系统(七)xDeepFM模型
- 推荐系统(八)FNN模型(FM+MLP=FNN)
- 推荐系统(九)PNN模型(Product-based Neural Networks)
- 推荐系统(十)DeepFM模型
- 推荐系统(十一)阿里深度兴趣网络(一):DIN模型(Deep Interest Network)
- 推荐系统(十二)阿里深度兴趣网络(二):DIEN模型(Deep Interest Evolution Network)
- 推荐系统(十三)阿里深度兴趣网络(三):DSIN模型(Deep Session Interest Network)
- 推荐系统(十四)多任务学习:阿里ESMM(完整空间多任务模型)
阿里的ESMM模型似乎是为广告ctr和cvr专门量身打造的,在ESMM模型结构中,两个塔具有明确的依赖关系。再早之前的MTL模型中,基本都是N个塔共享底座embedding,然后不同的任务分不同的塔,这种模式需要这些塔之间具有比较强的相关性,不然性能就很差,甚至会发生 『跷跷板』现象,即一个task性能的提升是通过损害另一个task性能作为代价换来的。因此,如果两个task都有足够的数据量,这种共享底座embedding的多塔设计的性能并没有分开单独建模效果来得好,原因是几乎必然出现负迁移(negative transfer)和“跷跷板”现象。因此在实际应用中,并不要盲目的为了MTL而MTL,这样只会弄巧成拙。(以上加黑部分为个人见解,欢迎讨论)
但如果又有多个目标,多个tower之间的相关性并不是很强,比如,CTR、点赞、时长、完播、分享等,并且有的目标的数据量并不是很足够,甚至无法单独训练一个DNN(当然,你如果说我单独建模用xgb,那我无话可说),在这种情况下,我们可能就要考虑MTL了,这时候MMoE就可以派上用场了。值得一提的是,MMoE是谷歌发表在KDD’18上的,和阿里的ESMM同年发表,所以相互之间应该独立的两个工作。
这篇博客将会从以下几个方面介绍MMoe(Multi-gate Mixture-of-Experts):
- 动机
- MMoe模型结构
- MMoe代码实现
- 总结
一、动机
说到动机,自然就要先说当前现状存在的问题。目前在MTL领域存在的问题:
- 工业界真实场景下,多个任务之间的相关性并不是很强,这个时候如果再用过去那种共享底座embedding的结构,往往会导致『跷跷板』现象。
- 当前学术界已经有很多工作意识到1中描述的问题并且尝试去解决,但大多数工作的套路都是『大力出奇迹』的路子,即加很多可学的参数去学习多个任务之间的difference,这在学术界跑跑数据,写写论文倒是没什么,但是在工业界场景下,增加这些参数会导致线上做infer时耗时增加,导致模型服务可用性大大下降,这是无法接受的。
二、MMoe模型结构
关于MMoe的模型结构,先上个论文中的原图:
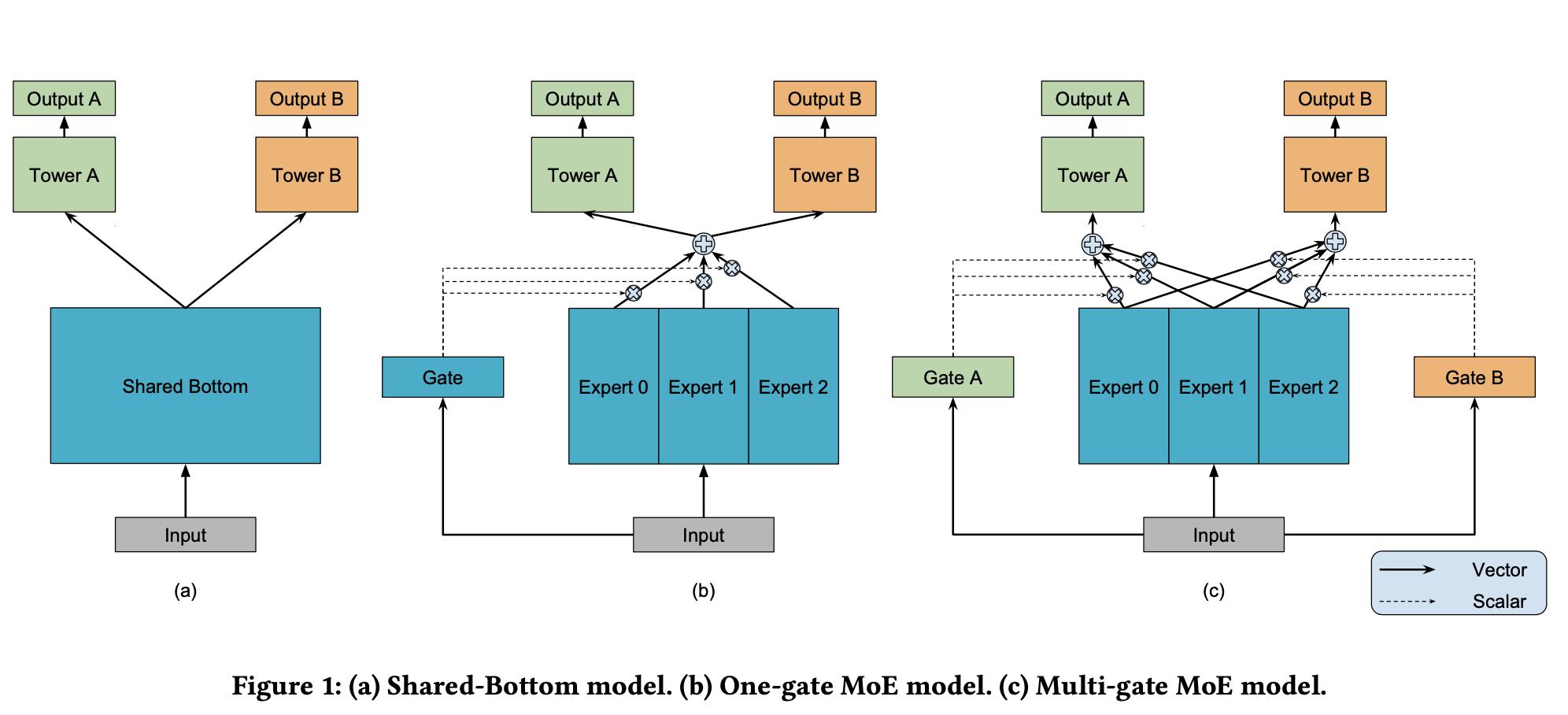
图1中(a)展示了传统的MTL模型结构,即多个task共享底座(一般都是embedding向量),(b)则是论文中提到的一个gate的Mixture-of-Experts模型结构,(c)则是论文中的MMoE模型结构。
我们重点来看下MMoE结构,也就是图1 ( c ),这里每一个expert和gate都是一个全连接网络(MLP),层数由在实际的场景下自己决定。下面上一个我画的详细版本的MMoE模型结构图,有了这个图,公式都不用了,直接对着图代码实现就可以了。
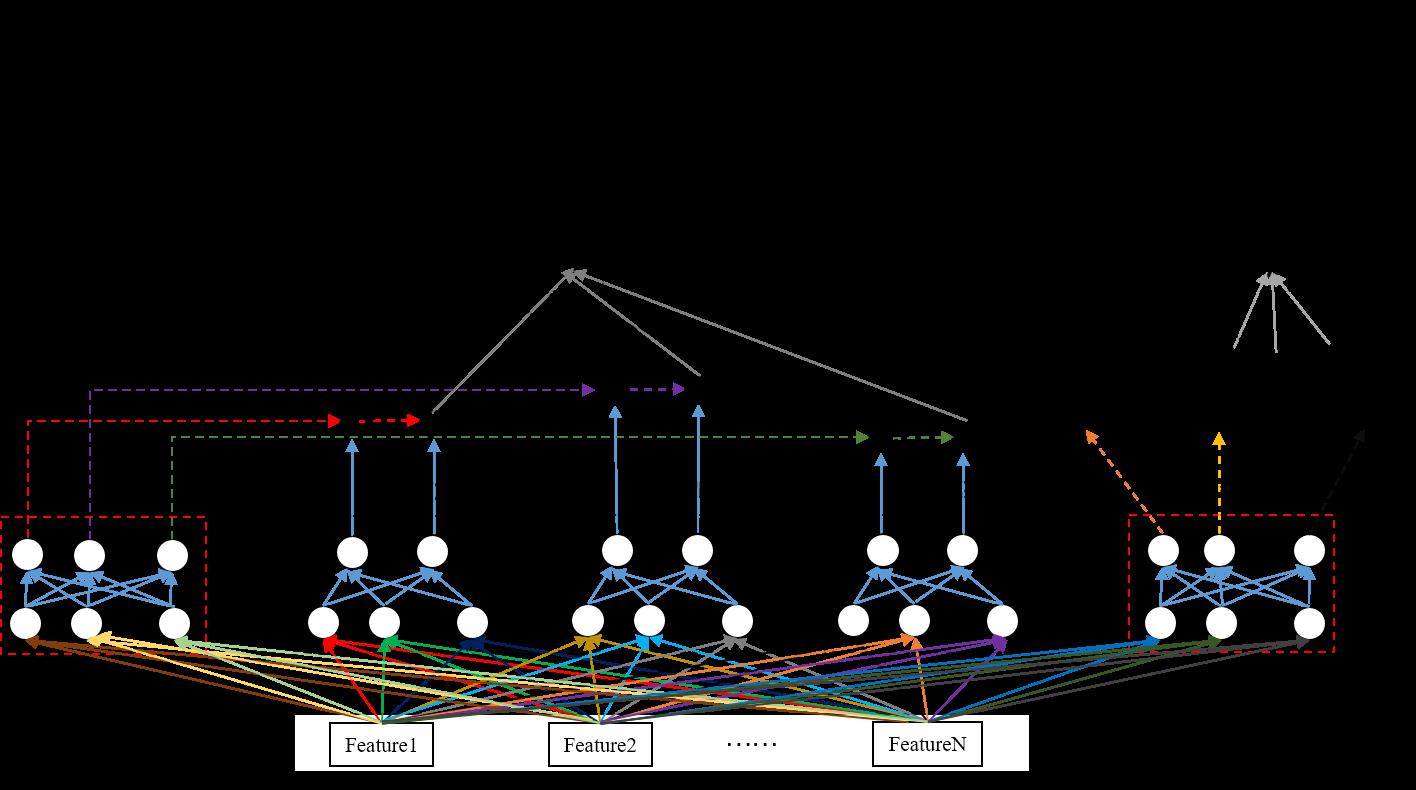
注:GateB那部分没画出来,因为画出来会显得很乱,参考GateA即可。
从上图2中,我们可以出来几个细节(一定要仔细看,非常重要!!!):
- Gate网络最后一层全连接层的隐藏单元(即输出)size必须等于expert个数。另外,Gate网络最后的输出会经过softmax进行归一化。
- Gate网络最后一层全连接层经过softmax归一化后的输出,对应作用到每一个expert上(图2中GateA输出的红、紫、绿三条线分别作用与expert0,expert1,expert2),注意是通过广播机制作用到expert中的每一个隐藏单元,比如红线作用于expert0的2个隐藏单元。这里gate网络的作用非常类似于attention机制,提供了权重。
- 假设GateA的输出为 [ G A 1 , G A 2 , G A 3 ] [GA_1, GA_2, GA_3] [GA1,GA2,GA3],expert0的输出为 [ E 0 1 , E 0 2 ] [E0_1, E0_2] [E01,E02],expert1的输出为 [ E 1 1 , E 1 2 ] [E1_1, E1_2] [E11,E12],expert2的输出为 [ E 2 1 , E 2 2 ] [E2_1, E2_2] [E21,E22]。GateA分别与expert0、expert1、expert2作用,得到 [ G A 1 ∗ E 0 1 , G A 1 ∗ E 0 2 ] , [ G A 2 ∗ E 1 1 , G A 2 ∗ E 1 2 ] , [ G A 3 ∗ E 2 1 , G A 3 ∗ E 2 2 ] [GA_1*E0_1, GA_1*E0_2], [GA_2*E1_1, GA_2*E1_2], [GA_3*E2_1, GA_3*E2_2] [GA1∗E01,GA1∗E02],[GA2∗E11,GA2∗E12],[GA3∗E21,GA3∗E22],然后对应位置求和得到towerA的输入,即towerA的输入size等于expert输出隐藏单元个数(在这个例子中,expert最后一层全连接层隐藏单元个数为2,因此towerA的输入维度也为2),所以towerA的输入为 [ G A 1 ∗ E 0 1 + G A 2 ∗ E 1 1 + G A 3 ∗ E 2 1 , G A 1 ∗ E 0 2 + G A 2 ∗ E 1 2 + G A 3 ∗ E 2 2 ] [GA_1*E0_1+GA_2*E1_1+GA_3*E2_1, GA_1*E0_2+GA_2*E1_2+GA_3*E2_2] [GA1∗E01+GA2∗E11+GA3∗E21,GA1∗E02+GA2∗E12+GA3∗E22]。
- expert每个网络的输入特征都是一样的,其网络结构也是一致的。
- 两个gate网络的输入也是一样的,gate网络结构也是一样的。
一直觉得举例子画图胜过任何繁琐复杂的解释,有了上面那个例子,相信大家基本上看完一遍就理解整个MMoE的精髓了。
三、MMoe代码实现
在实现的时候,expert网络和gate网络的全连接层数依据自己的实际场景设置,个人建议不要设置太深,通常2层就足够。
paddle给出了代码实现(但paddle这里犯了一个致命错误,详情参见我提的issue:关于MMoe网络一些疑问),paddle代码参见:
paddle MMoE
我这里给加了详细的注释,方便大家理解:
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class MMoELayer(nn.Layer):
def __init__(self, feature_size, expert_num, expert_size, tower_size,
gate_num):
super(MMoELayer, self).__init__()
"""
feature_size: 499
"""
self.expert_num = expert_num # 8
self.expert_size = expert_size # 16
self.tower_size = tower_size # 8
self.gate_num = gate_num # 2
self._param_expert = []
for i in range(0, self.expert_num):
# shape(499, 16)
linear = self.add_sublayer(
name='expert_' + str(i),
sublayer=nn.Linear(
feature_size,
expert_size,
weight_attr=nn.initializer.Constant(value=0.1),
bias_attr=nn.initializer.Constant(value=0.1),
#bias_attr=paddle.ParamAttr(learning_rate=1.0),
name='expert_' + str(i)))
# print("linear: ", linear.weight)
self._param_expert.append(linear)
self._param_gate = []
self._param_tower = []
self._param_tower_out = []
# gate_num=2
for i in range(0, self.gate_num):
# shape(499, 8)
linear = self.add_sublayer(
name='gate_' + str(i),
sublayer=nn.Linear(
feature_size,
expert_num,
weight_attr=nn.initializer.Constant(value=0.1),
bias_attr=nn.initializer.Constant(value=0.1),
#bias_attr=paddle.ParamAttr(learning_rate=1.0),
name='gate_' + str(i)))
self._param_gate.append(linear)
# shape(16, 8)
linear = self.add_sublayer(
name='tower_' + str(i),
sublayer=nn.Linear(
expert_size,
tower_size,
weight_attr=nn.initializer.Constant(value=0.1),
bias_attr=nn.initializer.Constant(value=0.1),
#bias_attr=paddle.ParamAttr(learning_rate=1.0),
name='tower_' + str(i)))
self._param_tower.append(linear)
# shape(8, 2)
linear = self.add_sublayer(
name='tower_out_' + str(i),
sublayer=nn.Linear(
tower_size,
2,
weight_attr=nn.initializer.Constant(value=0.1),
bias_attr=nn.initializer.Constant(value=0.1),
name='tower_out_' + str(i)))
self._param_tower_out.append(linear)
def forward(self, input_data):
"""
input_data: Tensor(shape=[2, 499], 2--> batchsize
"""
expert_outputs = []
# expert_num=8
for i in range(0, self.expert_num):
# Tensor(shape=[2, 16])
linear_out = self._param_expert[i](input_data)
expert_output = F.relu(linear_out)
expert_outputs.append(expert_output)
# Tensor(shape=[2, 128]) 128=16*8
expert_concat = paddle.concat(x=expert_outputs, axis=1)
# Tensor(shape=[2, 8, 16]), 2-->batch_size
expert_concat = paddle.reshape(
expert_concat, [-1, self.expert_num, self.expert_size])
output_layers = []
for i in range(0, self.gate_num):
# Tensor(shape=[2, 8])
cur_gate_linear = self._param_gate[i](input_data)
# Tensor(shape=[2, 8]
cur_gate = F.softmax(cur_gate_linear)
# Tensor(shape=[2, 8, 1]
cur_gate = paddle.reshape(cur_gate, [-1, self.expert_num, 1])
# Tensor(shape=[2, 8, 16]) x Tensor(shape=[2, 8, 1]
# = Tensor(shape=[2, 8, 16])
cur_gate_expert = paddle.multiply(x=expert_concat, y=cur_gate)
# Tensor(shape=[2, 16])
cur_gate_expert = paddle.sum(x=cur_gate_expert, axis=1)
# Tensor(shape=[2, 8])
cur_tower = self._param_tower[i](cur_gate_expert)
cur_tower = F.relu(cur_tower)
# Tensor(shape=[2, 2])
out = self._param_tower_out[i](cur_tower)
out = F.softmax(out)
out = paddle.clip(out, min=1e-15, max=1.0 - 1e-15)
output_layers.append(out)
return output_layers
四、总结
这里主要列出一些大家深入思考后可能遇到的疑问点及解释。
1. 疑问点1(呼应三中的4.5两个点)
【问】: expert网络结构一样,输入特征一样,是否会导致每个expert学出来的参数趋向于一致,从而失去了ensemble的意义?
【答】: 在网络参数随机初始化的情况下,不会发生问题中提到的问题。核心原因在于数据存在multi-view,只要每一个expert网络参数初始化是不一样的,就会导致每一个expert学到数据中不同的view(paddle官方实现就犯了这个致命错误)。微软的一篇论文中提到因为数据存在multi-view,训练多个DNN时,即使一样的特征,一样的超参数,只要简单的把参数初始化设置不一样, 这多个DNN也会有差异。论文参见:Towards Understanding Ensemble, Knowledge Distillation, and Self-Distillation in Deep Learning
所以大家在实现的时候,一定要注意这一个点,只需要简单的把参数初始化设置为随机即可。
2. 疑问点2
【问】: 是否应该强上MTL?
【答】: 如果task之间的相关性很弱,基本上都会发生negative transfer,所以MTL是绝对打不过single model的,不要盲目的为了显得高大上牛逼哄哄的一股脑MTL。还是那句话,模型不重要,重要的是对数据及场景的理解。
参考文献
以上是关于推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )的主要内容,如果未能解决你的问题,请参考以下文章