19推荐系统17MMoE: 多任务学习
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了19推荐系统17MMoE: 多任务学习相关的知识,希望对你有一定的参考价值。
文章目录
1、前言
基于神经⽹络的多任务学习已经过成功应⽤内许多现实应⽤中,⽐如说之前我们介绍的阿⾥巴巴基于多任务联合学习的 ESMM 算法,其利⽤多任务学习解决了 CVR 中样本选择偏差和样本稀疏这两⼤问题,并在实际应⽤场景中取得了不错的成绩。
多任务学习的⽬的在于⽤⼀个模型来同时学习多个⽬标和任务,但常⽤的任务模型的预测质量通常对任务之间的关系很敏感(数据分布不同,ESMM 解决的也是这个问题),因此,google 提出多⻔混合专家算法(Multi-gate Mixture-of-Experts,以下简称 MMoE)旨在学习如何从数据中权衡任务⽬标(task-specifific objectives)和任务之间(inter-task relationships)的关系。所有任务之间共享混合专家结构(MoE)的⼦模型来适应多任务学习,同时还拥有可训练的⻔控⽹路(Gating Network)以优化每⼀个任务。
MMoE 算法在任务相关性较低时能够具有更好的性能,同时也可以提⾼模型的可训练性。作者也将 MMoE 应⽤于真实场景中,包括⼆分类和推荐系统,并取得了不错的成绩。
2、相关知识
这⼀节主要介绍⼀些基础知识和背景,包括多什么是任务学习和多任务学习的挑战。
MTL
MTL(Multi-Task Learning)有很多形式:联合学习(joint learning)、⾃主学习(learning to learn)和带有辅助任务的学习(learning with auxiliary task)等都可以指 MTL。⼀般来说,优化多个损失函数就等同于进⾏多任务学习(与单任务学习相反)。
本篇⽂章,包括之前的 ESMM 都是属于带有辅助任务的多任务学习。
MTL 的⽬标在于通过利⽤包含在相关任务训练信号中特定领域的信息来提⾼泛化能⼒。
那么,什么是相关任务呢?我们有以下⼏个不严谨的解释:
-
使⽤相同特征做判断的任务;
-
任务的分类边界接近;
-
预测同个个体属性的不同⽅⾯⽐预测不同个体属性的不同⽅⾯更相关;
-
共同训练时能够提供帮助并不⼀定相关,因为加⼊噪声有时也可以增加泛化能⼒。
任务是否相似不是⾮ 0 即 1 的。越相似的任务收益越⼤。但即使相关性不佳的任务也会有所收益。
结构
MLT 主要有两种形式,⼀种是基于参数的共享,另⼀种是联合模型 。
参数共享
参数共享的形式在基于神经⽹络的 MLT 中⾮常常⻅,其在所有任务中共享隐藏层并同时保留⼏个特定任务的输出层。这种⽅式有助于降低过拟合⻛险,因为同时学习的任务越多,模型找到⼀个含有所有任务的表征就越困难,从⽽过拟合某个特定任务的可能性就越⼩。ESMM 就属于这种类型的 MLT。
联合模型
每个任务都有⾃⼰的参数和模型,最后通过对不同任务的参数之间的差异施加约束。⽐如可以使⽤L2进⾏正则,迹范数(trace norm)等。
为什么 MLT 有效呢?
那么,为什么 MLT 有效呢?主要有以下⼏点原因:
-
多任务⼀起学习时,会互相增加噪声,从⽽提⾼模型的泛化能⼒;
-
多任务相关作⽤,逃离局部最优解;
-
多任务共同作⽤模型的更新,增加错误反馈;
-
降低了过拟合的⻛险;
-
类似 ESMM,解决了样本偏差和数据稀疏问题,未来也可以⽤来解决冷启动问题。
MTL的挑战
在多任务学习中,假设有这样两个相似的任务:猫分类和狗分类。他们通常会有⽐较接近的底层特征,⽐如⽪⽑、颜⾊等等。如下图所示:

多任务的学习的本质在于共享表示层,并使得任务之间相互影响:

如果我们现在有⼀个与猫分类和狗分类相关性不是太⾼的任务,如汽⻋分类:
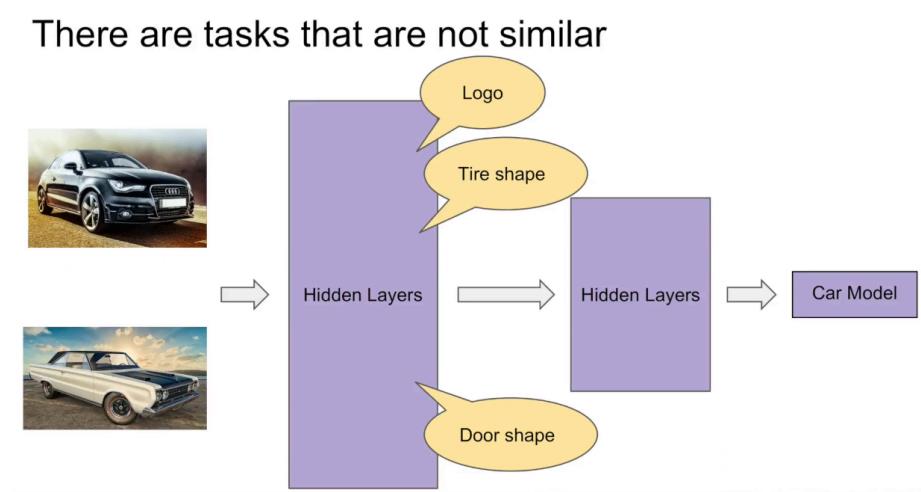
那么我们在⽤多任务学习时,由于底层表示诧异很⼤,所以共享表示层的效果也就没有那么明显,⽽且更有可能会出现冲突或者噪声:

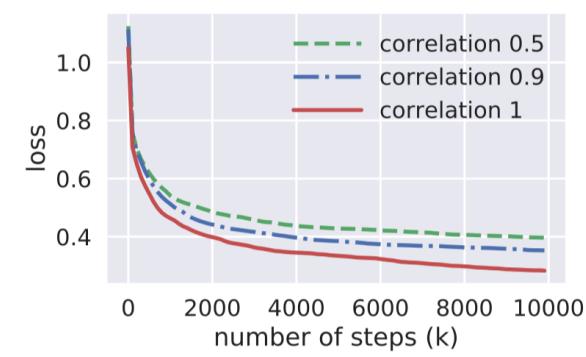
作者给出相关性不同的数据集上多任务的表现,其也阐述了,相关性越低,多任务学习的效果越差:
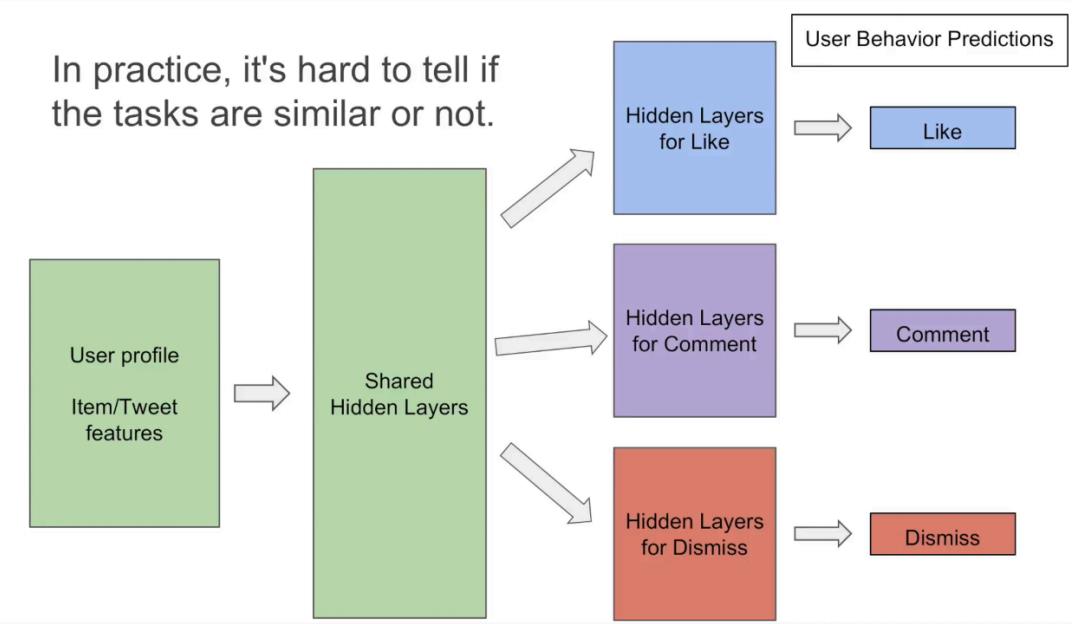
其实,在实际过程中,如何去识别不同任务之间的相关性也是⾮常难的:
基于以上原因,作者提出了 MMoE 框架,旨在构建⼀个兼容性更强的多任务学习框架。
3、模型结构
本节我们详细介绍下 MMoE 框架。
Shared-Bottom model
先简单结下 shared-bottom 模型,ESMM 模型就是基于 shared-bottom 的多任务模型。这篇⽂章把该框架作为多任务模型的 baseline,其结构如下图所示:

给出公式定义:
y
k
=
h
k
(
f
(
x
)
)
y_{k}=h^{k}(f(x))
yk=hk(f(x))
其中,
f
\\mathrm{f}
f 为表征函数,
h
k
\\boldsymbol{h}^{\\boldsymbol{k}}
hk 为第
k
\\mathrm{k}
k 个子网络(tower 网络)。
One-gate MoE Layer
⽽ One-gate MoE layer 则是将隐藏层划分为三个专家(expert)⼦⽹,同时接⼊⼀个 Gate ⽹络将各个⼦⽹的输出和输⼊信息进⾏组合,并将得到的结果进⾏相加。

公式如下:
y
=
∑
i
=
1
n
g
(
x
)
i
f
i
(
x
)
y=\\sum_{i=1}^{n} g(x)_{i} f_{i}(x)
y=i=1∑ng(x)ifi(x)
其中,
f
i
(
x
)
f_{i}(x)
fi(x) 为第
i
\\mathrm{i}
i 个专家子网的输出;
∑
i
=
1
n
g
(
x
)
i
=
1
,
g
(
x
)
i
\\sum_{i=1}^{n} g(x)_{i}=1, g(x)_{i}
∑i=1ng(x)i=1,g(x)i 为第
i
\\mathrm{i}
i 个
logit
\\operatorname{logit}
logit 输出, 表示专家子网
f
i
f_{i}
fi 的权重, 其由 gate 网络计算得出。
MoE 的主要目标是实现条件计算,对于每个数据而言,只有部分网络是活跃的,该模型可以通过限制输入的门控网络来选择专家网络的子集。
Multi-gate MoE model
MoE 能够实现不同数据多样化使用共享层, 但针对不同任务而言,其使用的共享层是一致的。这种情况下, 如果任务相关性较低,则会导致模型性能下降。
所以,作者在 MoE 的基础上提出了 MMoE 模型,为每个任务都设置了一个 Gate 网路,旨在使得不同任务和不同数据可以多样化的使用共享层,其模型结构如下:

给出公式定义:
y
k
=
h
k
(
f
k
(
x
)
)
where
f
k
(
x
)
=
∑
i
=
1
n
g
k
(
x
)
i
f
i
(
x
)
g
k
(
x
)
=
softmax
(
W
g
k
x
)
\\begin{aligned} y_{k} &=h^{k}\\left(f^{k}(x)\\right) \\\\ \\text { where } f^{k}(x) &=\\sum_{i=1}^{n} g^{k}(x)_{i} f_{i}(x) \\\\ g^{k}(x) &=\\operatorname{softmax}\\left(W_{g k} x\\right) \\end{aligned}
yk where fk(x)gk(x)=hk(fk(x))=i=1∑ngk(x)ifi(x)=softmax(Wgkx)
这种情况下,每个 Gate 网络都可以根据不同任务来选择专家网络的子集,所以即使两个任务并不是十分相关, 那么经过 Gate 后也可以得到不同的权重系数, 此时,
M
M
o
E
\\mathrm{MMoE}
MMoE 可以充分利用部分 expert 网络的信息, 近似于单个任务; 而如果两个任务相关性高,那么 Gate 的权重分布相差会不大,会类似于一般的多任务学习。
参考
阿泽的学习笔记
Modeling task relationships in multi-task learning with multi-gate mixture-of experts
以上是关于19推荐系统17MMoE: 多任务学习的主要内容,如果未能解决你的问题,请参考以下文章
推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )
推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )