基于飞桨PARL实践PPO算法,让“猎豹”学会奔跑!
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于飞桨PARL实践PPO算法,让“猎豹”学会奔跑!相关的知识,希望对你有一定的参考价值。
点击左上方蓝字关注我们

【飞桨开发者说】陈懿,西交利物浦大学计算机研一,研究方向为:强化学习在游戏领域的应用。

项目背景
20世纪90年代以来,随着计算机技术和数据量的爆发式增长,算力和神经网络得到了极大的发展,但是距离人们想象中的人工智能还需要不断的实践和创新。
而在神经网络的基础上出现的强化学习分支,将机器的智能进行了大幅提升,这种提升来源于强化学习可以让机器(算法)自己和环境交互,不断试错,从而提升自己的能力。是不是感觉和人类成长的方式很像了?

在强化学习发展的过程中,PPO可以算是最经典的算法之一,这主要得益于其非常明显的 3 个优势:算法简洁易理解、适应性强、效果优异。
本次项目中的 Mujoco Half-Cheetah 环境,是在模拟环境中让一个(事实上是半个)虚拟猎豹学会奔跑。而奔跑这件事,难点在于:动作是连续的,环境的反馈也是连续的。所以要应对这些难点,本次选取了“万能算法”——PPO作为尝试。
我们可以先来看看 PPO 算法是如何发展而来的。
最早出现的策略优化算法是PG算法(Policy Gradient)。该算法由于采样和优化用的是同一套策略(on-policy),所以采样的效率比较低。PG算法训练过程不稳定,容易崩溃(可能由于样本的关联度太高造成),比如随机采集到了差的动作,和环境交互后更差,得到的也是一堆差的反馈数据,恶性循环,导致很难从错误中恢复,最终算法崩溃。
如何使PG算法训练更稳定呢?
引入 Trust region 机制,使产生的 gradient 总是在一个安全的范围里(平缓更新),或者用二阶的 natural policy gradient 的方法(增加了Fisher Information Matrix的逆矩阵)取代此前用的一阶的 SGD,这样更准确稳定,但是计算复杂度很高。
对 TRPO 进一步改进,得到ACKTR算法。把 Fisher Information Matrix 求逆的过程,用 Kronecker-factored approximation curvature (K-FAC) 替代,训练速度大幅加快,从而提升 TRPO 的计算效率
PPO对复杂的 TRPO 算法进行了简化。把 Natural gradient 和 TRPO 的 loss function 结合起来,不需要使用复杂的二阶优化方法,可以在保证效果的前提下,速度更快。
最后得到PPO with clipping算法,有如下两点优势:
使用 clip 的方式,限制 ratio 的更新,让 policy output 不会有太激进的变化,让更新变得稳定,所以大部分的 PPO 算法都采用了这种形式。
仅几行代码即可把经典 PG 算法改写成 PPO 的形式,所以很容易实现。
PPO训练效果展示
(Mujoco HalfCheetah-v2)
视频展示:
运行 300,000 步达到 1000 分
运行 600,000 步达到 1500 分
运行 2,000,000 步达到 2500 分以上
最终可以达到 4000-5000 分

PPO 算法论文阅读
PPO是ArXiv 2017的一篇论文,Proximal Policy Optimization Algorithms,论文网址:
https://arxiv.org/abs/1707.06347

下面我们对论文的关键内容进行解读。
1. 回顾各种强化学习算法
论文开篇先是回顾了各种强化学习算法的瓶颈,以及PPO的改进和创新点。
Q-learning:对于很多简单的问题无法解决,而且算法难以理解。
Vanilla Policy Gradient:数据利用率差;鲁棒性(普适性)差;不稳定的问题来源于使用了同一条轨迹进行多步优化。
TRPO:算法太过于太复杂;引入噪声以后,和参数共享的结构不兼容。
PPO:数据利用率高;模型可靠度高(适用范围广),类似 TRPO;模型简洁易懂;创新地引入了 clipped probability ratio。
2. 截断方式
解释了 PPO 如何通过截断 probability ratio 达到 TRPO 同样的效果,同时保持了算法的简易性和可理解性。
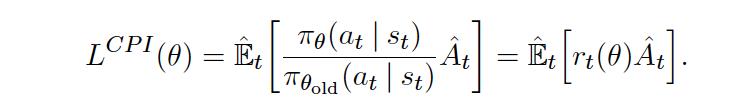
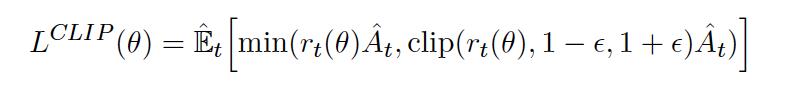
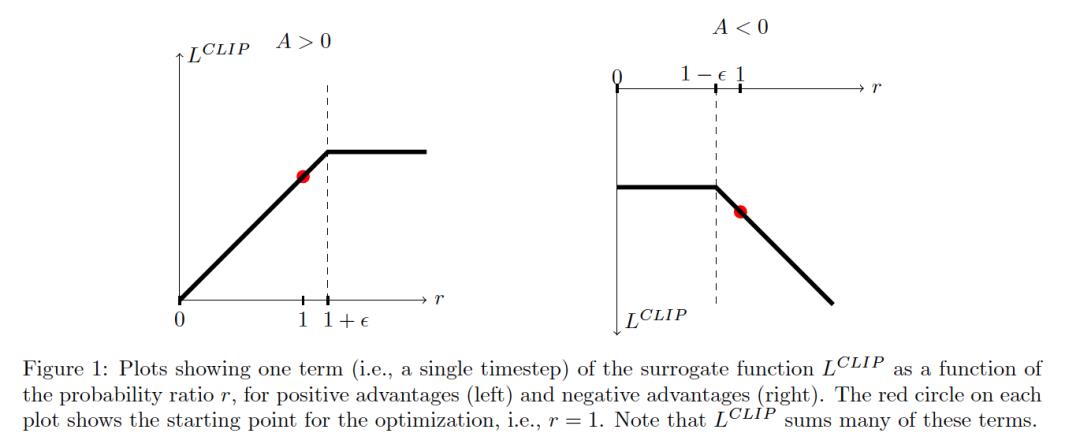
另外一种方法是用 KL 惩罚因子来代替截断的方法:

3. 算法
算法非常简洁。同时这里需要注意:PPO是一个 on-policy 算法!

4. 效果展示
4.1 对比两种更新方法
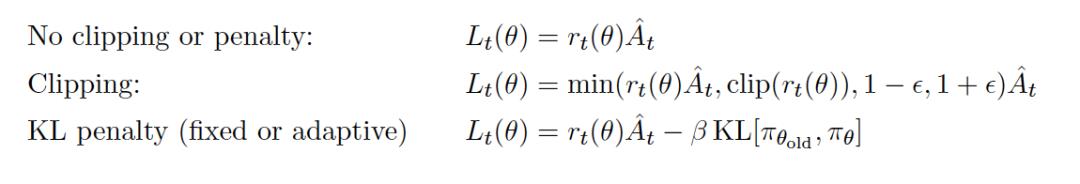
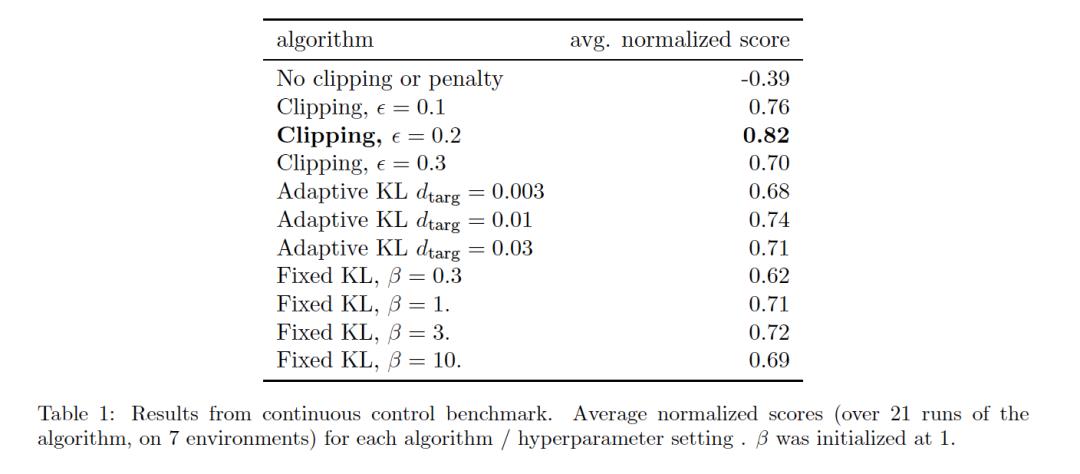
原论文对比了 no clipping or penalty ,Clipping,KL penalty 三种更新方式之间的区别。结果是后面两个表现更好,另外 Clipping 比 KL 表现更好。
4.2 在连续控制环境中与其他算法对比
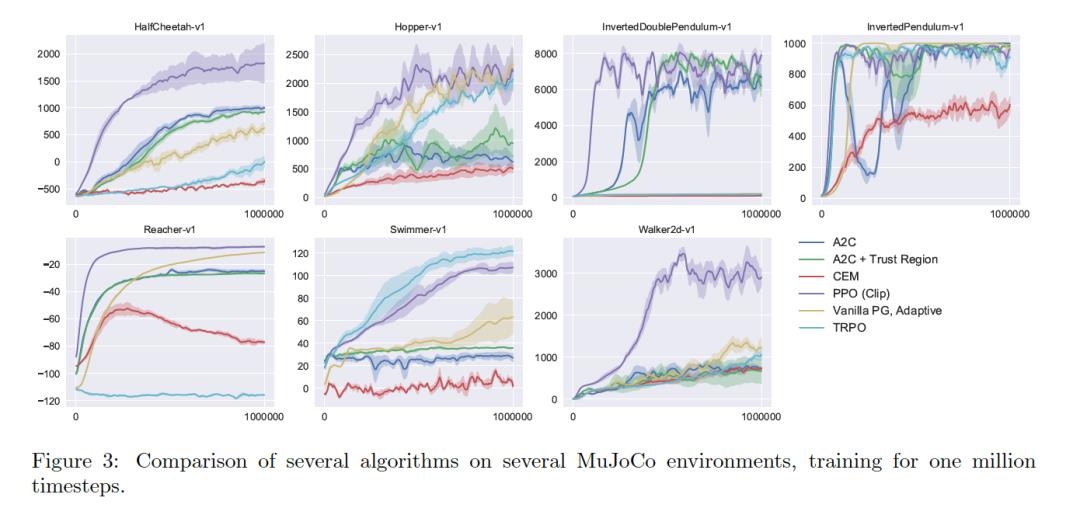
可以看得出,在前1000000步过程中,PPO 明显大多数其他算法收敛更快;
而且适应范围更广,在多种任务中皆表现出色。
4.3 复杂的连续控制环境:模拟人类奔跑
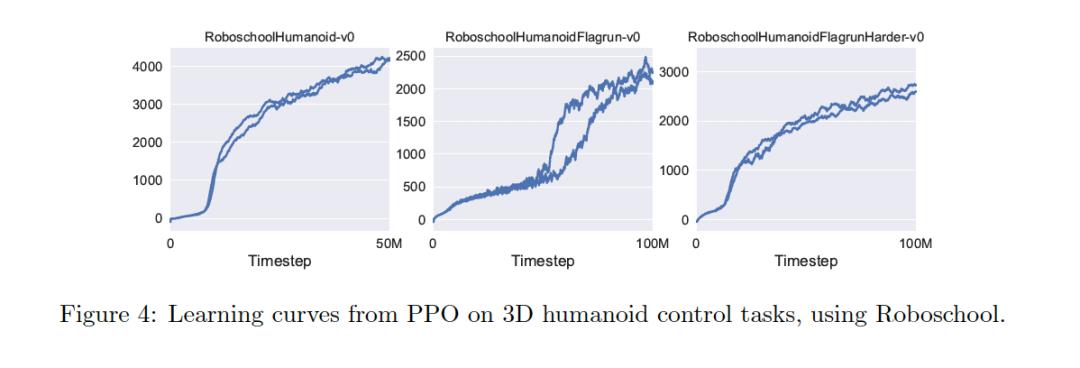
可以看到,在复杂的连续控制环境下,PPO取得的效果也非常不错。
4.4 Atari环境中与其他算法对比

在 Atari 游戏上面进行测试,证明了 PPO 在确保效果的前提下,速度更快。
基于飞桨PARL 的
PPO 算法程序实现
1 . 相关依赖库
python3.5+
paddlepaddle>=1.6.1
PARL
gym
tqdm
mujoco-py>=1.50.1.0
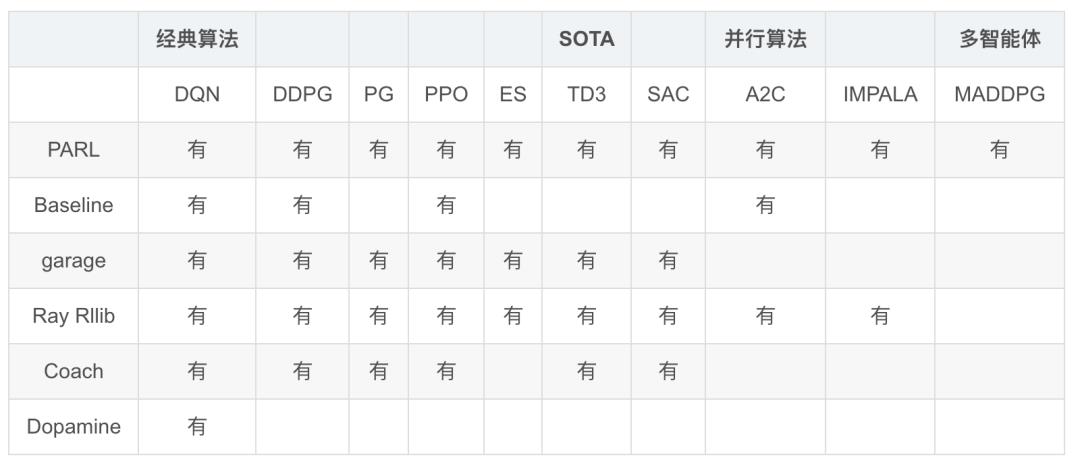
1.1 Gym 和 PARL 的介绍
Gym 是个仿真平台,python 的开源库,RL 的测试平台:
离散控制场景(动作为确定值):一般使用 atari 环境评估
连续控制场景(动作为浮动连续值):一般使用 mujoco 环境游戏评估
Gym 的核心接口是 enviroment,核心方法:
observation (object):对环境的一次观察
reward (float):奖励
done (boolean):代表是否要重置环境(是否达成最终结果/游戏结束)
info (dict):用于调试的诊断信息
reset():重置环境的状态,回到初始环境,以便开始下一次训练。
step(action):推进一个时间步长,返回 4 个值:
render():渲染,刷新环境新一帧的图形
PARL 是对 Agent 的框架抽象,适用范围:
入门:快速学习和对比不同常用算法
科研:快速复现论文结果,迁移算法到不同环境调研
工业:大规模分布式能力,单机到多机仅需2行代码,快速迭代上线
PARL 的实现,基于 3 个类:
Model(模版+用户定制):构建前向网络,用户可以自由的定制自己的网络结构。
Algorithm:定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。
Agent(模版+用户定制): 负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型(Model),数据的预处理流程也一般定义在这里。
1.2 Mujoco 及 mujoco-py 的安装
MuJoCo 是目前机器人强化学习中最流行的仿真器之一

安装 MuJoCo:
获取许可证:
https://www.roboti.us/license.html,可以使用30 天试用版本。
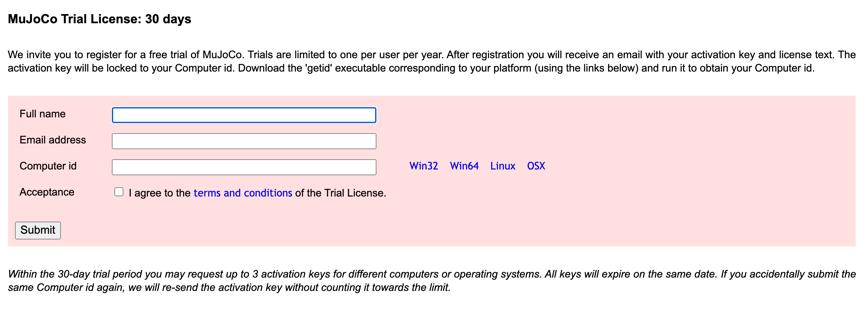
例如:Mac电脑,点击 OSX 下载文件 getid_osx;
获取电脑 id;
在网站上输入,立刻就收到了邮件,里面有两个附件:LICENSE.txt和mjkey.txt。
您也可以选择安装个人版。
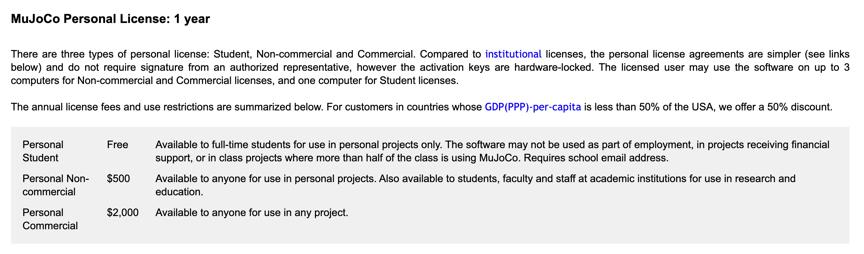
官网上有一段提示,意思就是慎重选择要安装的电脑,它是绑定电脑的。尤其是学生党要注意,虽然有 1 年的免费使用,但是千万别装错电脑!
下载源文件:
Linux 请选择:
https://www.roboti.us/download/mujoco200_linux.zip
OS 系统请选择:
https://www.roboti.us/download/mujoco200_macos.zip
注意:这里的目录设置很重要!如果搞不清楚的话,请选择默认安装路径,以免出错!
在终端中mkdir ~/.mujoco 创建安装目录;
然后把下载的程序文件解压,移动到该目录下
mv mujoco200_macos ~/.mujoco/mujoco200;
将邮件里面得到的 key 放到目录下
mv mjkey.txt ~/.mujoco/mjkey.txt。
安装 mujoco-py:
官方文档介绍直接使用 pip3 install -U 'mujoco-py<2.1,>=2.0' 即可
安装过程如果出现各种报错,可以参考:
强化学习环境:MuJoCo 安装踩坑记录(2020年7月18日)
2 . 程序实现
主程序包含 4 个主要的函数:
run_train_episode:用于训练的交互程序;
run_evaluate_episode:评估和测试的交互程序;
collect_trajectories:通过交互程序,收集轨迹数据,包含了环境状态,采取的动作,对应的奖励等;
build_train_data:把轨迹数据转化为可以用作训练的数据。
mujoco_agent:算法核心:
这里一共创建了 5 个网络:policy_sample_program,policy_predict_program,policy_learn_program,value_predict_program。
policy_learn:用于同步新的策略模型的参数到旧的策略模型,固定策略模型,然后学习多次后再同步。
value_learn:数据训练,更新参数。
def policy_learn(self, obs, actions, advantages):
""" Learn policy:
1. Sync parameters of policy model to old policy model
2. Fix old policy model, and learn policy model multi times
3. if use KLPEN loss, Adjust kl loss coefficient: beta
"""
self.alg.sync_old_policy()
all_loss, all_kl = [], []
for _ in range(self.policy_learn_times):
loss, kl = self._batch_policy_learn(obs, actions, advantages)
all_loss.append(loss)
all_kl.append(kl)
if self.loss_type == 'KLPEN':
# Adative KL penalty coefficient
if kl > self.kl_targ * 2: # 如果 KL 过大
self.beta = 1.5 * self.beta # 则将惩罚系数增大
elif kl < self.kl_targ / 2: # 如果 KL 过小
self.beta = self.beta / 1.5 # 则惩罚系数也对应减小
return np.mean(all_loss), np.mean(all_kl)
def value_learn(self, obs, value):
""" Fit model to current data batch + previous data batch
"""
data_size = obs.shape[0]
if self.value_learn_buffer is None: # 缓存为空的时候
obs_train, value_train = obs, value # 读取状态值和价值到缓存
else:# 如果缓存中有数据,则把新数据和旧的数据进行拼接
obs_train = np.concatenate([obs, self.value_learn_buffer[0]])
value_train = np.concatenate([value, self.value_learn_buffer[1]])
self.value_learn_buffer = (obs, value) # 更新缓存为新数据
all_loss = []
for _ in range(self.value_learn_times):
random_ids = np.arange(obs_train.shape[0]) # 获取 id 列表
np.random.shuffle(random_ids) # 随机打乱训练数据
shuffle_obs_train = obs_train[random_ids]
shuffle_value_train = value_train[random_ids]
start = 0
while start < data_size:
end = start + self.value_batch_size
# 更新价值网络(新数据+旧数据)
value_loss = self._batch_value_learn(
shuffle_obs_train[start:end, :],
shuffle_value_train[start:end])
all_loss.append(value_loss)
start += self.value_batch_size
return np.mean(all_loss)
搭建网络结构:
搭建策略网络 policy model 和价值网络 value model,都用了 4 个全连接层。基于飞桨的架构,搭建的神经网络模型非常简单清晰。
class PolicyModel(PARL.Model):
def __init__(self, obs_dim, act_dim, init_logvar):
self.obs_dim = obs_dim
self.act_dim = act_dim
hid1_size = obs_dim * 10
hid3_size = act_dim * 10
hid2_size = int(np.sqrt(hid1_size * hid3_size))
self.lr = 9e-4 / np.sqrt(hid2_size)
self.fc1 = layers.fc(size=hid1_size, act='tanh')
self.fc2 = layers.fc(size=hid2_size, act='tanh')
self.fc3 = layers.fc(size=hid3_size, act='tanh')
self.fc4 = layers.fc(size=act_dim, act='tanh')
self.logvars = layers.create_parameter(
shape=[act_dim],
dtype='float32',
default_initializer=fluid.initializer.ConstantInitializer(
init_logvar))
def policy(self, obs):
hid1 = self.fc1(obs)
hid2 = self.fc2(hid1)
hid3 = self.fc3(hid2)
means = self.fc4(hid3)
logvars = self.logvars()
return means, logvars
def sample(self, obs):
means, logvars = self.policy(obs)
sampled_act = means + (
layers.exp(logvars / 2.0) * # stddev
layers.gaussian_random(shape=(self.act_dim, ), dtype='float32'))
return sampled_act
完整代码可见 AI Studio 公开项目:
https://aistudio.baidu.com/aistudio/projectdetail/644829
文章小结
1. 关于模型
PPO模型确实非常强大,稳定性很好,最重要的是鲁棒性强,适用性广。所以该算法被 OpenAI 推出后,受到了业界的极大关注,后面强化学习的进一步研究工作,也通常都会把 PPO 作为参照对象和对比基准。
PPO提出的创新点,比如截断等操作,其实衍生性很好,不仅限于强化学习领域,其他深度学习方向也可以借鉴受益。
最后不得不提的是百度的 PaddlePaddle 和 PARL,这是一套完整的深度学习和强化学习框架。从初期学习,到中期实践,到后期落地,这套框架给开发者和研究者带来了极大的便利。PARL 作为专精于强化学习的框架,免除了我们重复造轮子的痛苦,可以专注于不同算法的核心优劣对比和研究,确实节约了我们大量的时间。就我自己而言,以后做相关的研究和论文撰写,PaddlePaddle 和 PARL 一定会是我的首选!
2.关于学习过程
入门强化学习时,发现最难搞的是理解核心的理念,比如关于奖励的概念,如何让奖励可以不断促使算法自我学习和进化,需要反复去琢磨和思考。
学习过程中,相信最经典的理解障碍就是 On-policy 和 Off-policy 的理念对比了,初次接触的人可不容易搞明白,所幸当时科老师的课讲得细致清晰,生动形象,让这些常理来说很困难的部分可以迎刃而解。
有了基础的强化学习理念,往后就是对比和学习主流的强化学习算法,这个时候网上的教程其实就稍显匮乏了,对于想要深入研究的同学,可以考虑从论文研读和代码实践两个板块同时入手,由此可对各种算法有深入的理解。
3.关于PPO训练过程
个人认为,强化学习的代码实践,包含以下几个重要的组成部分,每个部分都有其难点。
实验环境搭建
初期我们会直接用 Gym 库里面提供的一些环境,几乎不费力气去搭建和调用,只要把 Gym 安装完成即可轻松实现。可越往后,当你想尝试各种高难度的环境时,比如一些机器人模拟环境,飞行器模拟环境,交通控制环境,甚至还有一些股票交易环境的时候,光是安装一个环境达到成功运行都是非常费时费力的。
这里实践 PPO,没有选用简单的 Gym 环境,挑战了一下安装 Mujoco,真的是一把辛酸泪,弄了整整一天才勉强跑通,期间无数次在 github 上查询各种 issue,然后进行各种尝试,各种重装。我只想说,那些可以一次安装成功的朋友真的是人品爆发才行!而且大家要有心理准备,以后安装别的环境只会更难~~。
算法代码构建
如果是从 0 开始手动搭建代码,在现代社会几乎是无法想象的事情,所以站在巨人的肩膀上才是最重要的。而有了 PARL 这样的成熟框架,可以让我们有了搭建的基础,让算法代码构建稍稍轻松一点点!
把环境的交互,算法部分,学习部分,都分别做了基础框架,这不但让调用更加简单,其实也是让我们学习过程中对于整个深度学习的过程有了分块的清晰认知。
训练调试
由于 PPO 算法的特性,决定了其稳定性比较好,所以不像 PG 这样的强化学习算法,常常遇到无法收敛的情况,很多时候又需要拼人品~~。PPO 就好多了,在训练前,设置好定期保存模型,然后就开始走起。另外要记得保存训练数据,用于后面绘图以看清楚整个训练过程。
开始训练 100,000 步左右,看看之前有没有收敛的趋势,没有的话就停掉重新调试程序,如果基本的算法和架构没有问题,可以尝试降低学习率来调试。
如果收敛趋势明显,那就可以放着让电脑训练,睡一觉以后看最后训练效果。可以看到最终的收敛曲线,也就是获得奖励上涨的趋势如本文开头的图示。调取训练过程中保存的中间模型,放到测试代码中开启渲染运行,就可以看到我们的小猎豹成长的过程喜人,从呆着不动,到乱七八糟地晃动,再到逐渐可以移动,最后可以比较顺畅地完成奔跑,整个过程还是让人很有成就感的!
飞桨PaddlePaddle课程链接:
百度架构师手把手教深度学习:
https://aistudio.baidu.com/aistudio/course/introduce/888
强化学习7日打卡营:
https://aistudio.baidu.com/aistudio/course/introduce/1335
如果您加入官方 QQ 群,您将遇上大批志同道合的深度学习同学。官方 QQ 群:
1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·官网地址·
https://www.paddlepaddle.org.cn/
·飞桨PARL开源项目地址·
GitHub:
https://github.com/PaddlePaddle/PARL
Gitee:
https://gitee.com/paddlepaddle/ PARL




以上是关于基于飞桨PARL实践PPO算法,让“猎豹”学会奔跑!的主要内容,如果未能解决你的问题,请参考以下文章
强化学习从PG到PPO(基于百度飞桨PaddlePaddle+PARL)
PPO姿态控制基于强化学习(Proximal Policy Optimization)PPO训练的无人机姿态控制simulink仿真