Regionserver频繁挂掉故障处理实践
Posted 格格巫 MMQ!!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Regionserver频繁挂掉故障处理实践相关的知识,希望对你有一定的参考价值。
近期腾讯云的一家大客户频繁出现HBase regionserver 挂掉,影响业务正常使用。通过调整堆栈大小、gc优化、超时时间等都无法解决该问题。经过细致并综合分析hbase regionserver、hbase master以及 zookeeper的日志,发现了问题所在:tickTime设置导致hbase超时时间错误。
一、故障现象
1、 首先regionserver频繁爆出两类错误:
wal.FSHLog: Error syncing, request close of WAL:
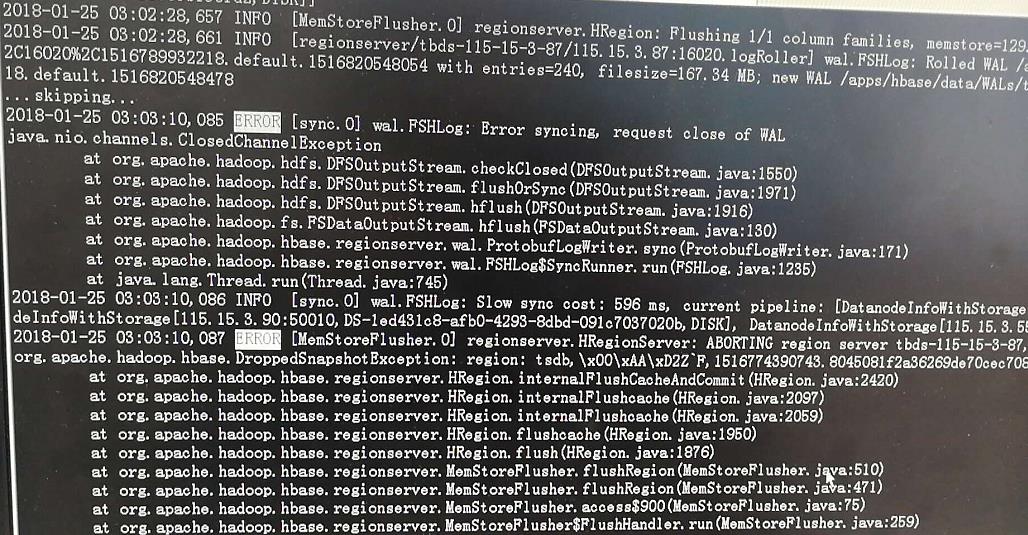
以及出现错误:
regionserver.MemStoreFlusher:Cache flush failed for region XXX …
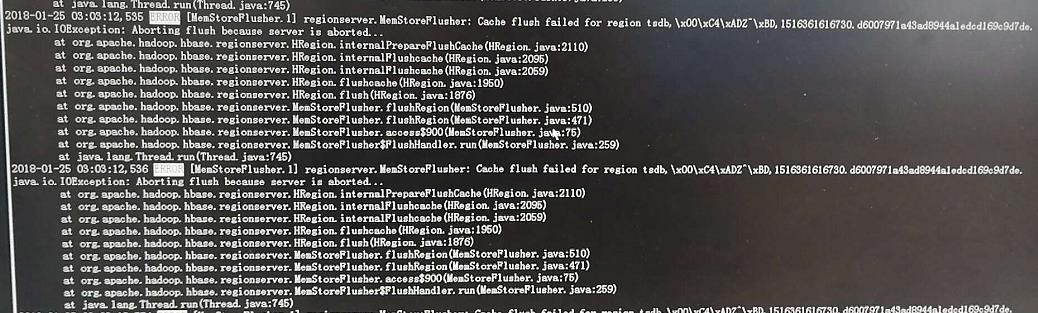
2、然后出现regionserver死亡错误:
HBase error : Memstore size is xxxxxx

以及出现regionserver dead 故障:
Region server exiting
java.lang.RuntimeException: HRegionServer Aborted

二、故障分析与解决
从上述报错可以看出,引起regionserver 故障的主要原因集中在memstore,因此首先想到是regionserver 的堆栈设置不合理或者是gc优化不合理。因此,我们将hbase以及regionserver 的堆栈都设置为16G,然后对gc进行优化。最终,HBase具体优化参数如下所示:
export HBASE_HEAPSIZE=16384
export master_heapsize=8192
export regionserver_heapsize=16384
export HBASE_OPTS=“
H
B
A
S
E
O
P
T
S
−
X
s
s
512
k
−
X
X
:
P
e
r
m
S
i
z
e
=
256
m
−
X
X
:
+
U
n
l
o
c
k
E
x
p
e
r
i
m
e
n
t
a
l
V
M
O
p
t
i
o
n
s
−
X
X
:
+
U
s
e
G
1
G
C
−
X
X
:
M
a
x
G
C
P
a
u
s
e
M
i
l
l
i
s
=
50
−
X
X
:
G
C
P
a
u
s
e
I
n
t
e
r
v
a
l
M
i
l
l
i
s
=
100
−
X
X
:
−
O
m
i
t
S
t
a
c
k
T
r
a
c
e
I
n
F
a
s
t
T
h
r
o
w
−
X
X
:
M
a
x
T
e
n
u
r
i
n
g
T
h
r
e
s
h
o
l
d
=
1
−
X
X
:
C
o
n
c
G
C
T
h
r
e
a
d
s
=
12
−
X
X
:
G
1
O
l
d
C
S
e
t
R
e
g
i
o
n
T
h
r
e
s
h
o
l
d
P
e
r
c
e
n
t
=
3
−
X
X
:
P
a
r
a
l
l
e
l
G
C
T
h
r
e
a
d
s
=
18
−
X
X
:
+
U
s
e
G
C
L
o
g
F
i
l
e
R
o
t
a
t
i
o
n
−
X
X
:
N
u
m
b
e
r
O
f
G
C
L
o
g
F
i
l
e
s
=
5
−
X
X
:
G
C
L
o
g
F
i
l
e
S
i
z
e
=
20
M
−
X
X
:
+
P
a
r
a
l
l
e
l
R
e
f
P
r
o
c
E
n
a
b
l
e
d
−
X
X
:
−
R
e
s
i
z
e
P
L
A
B
−
X
X
:
G
1
M
i
x
e
d
G
C
C
o
u
n
t
T
a
r
g
e
t
=
16
−
X
X
:
I
n
i
t
i
a
t
i
n
g
H
e
a
p
O
c
c
u
p
a
n
c
y
P
e
r
c
e
n
t
=
75
−
X
X
:
G
1
R
e
s
e
r
v
e
P
e
r
c
e
n
t
=
5
−
X
X
:
G
1
N
e
w
S
i
z
e
P
e
r
c
e
n
t
=
8
−
X
X
:
G
1
H
e
a
p
R
e
g
i
o
n
S
i
z
e
=
16
m
−
X
X
:
E
r
r
o
r
F
i
l
e
=
l
o
g
d
i
r
/
h
s
e
r
r
p
i
d
e
x
p
o
r
t
H
B
A
S
E
M
A
S
T
E
R
O
P
T
S
=
"
HBASE_OPTS -Xss512k -XX:PermSize=256m -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:GCPauseIntervalMillis=100 -XX:-OmitStackTraceInFastThrow -XX:MaxTenuringThreshold=1 -XX:ConcGCThreads=12 -XX:G1OldCSetRegionThresholdPercent=3 -XX:ParallelGCThreads=18 -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M -XX:+ParallelRefProcEnabled -XX:-ResizePLAB -XX:G1MixedGCCountTarget=16 -XX:InitiatingHeapOccupancyPercent=75 -XX:G1ReservePercent=5 -XX:G1NewSizePercent=8 -XX:G1HeapRegionSize=16m -XX:ErrorFile=log_dir/hs_err_pid%p.log" export HBASE_MASTER_OPTS="
HBASEOPTS−Xss512k−XX:PermSize=256m−XX:+UnlockExperimentalVMOptions−XX:+UseG1GC−XX:MaxGCPauseMillis=50−XX:GCPauseIntervalMillis=100−XX:−OmitStackTraceInFastThrow−XX:MaxTenuringThreshold=1−XX:ConcGCThreads=12−XX:G1OldCSetRegionThresholdPercent=3−XX:ParallelGCThreads=18−XX:+UseGCLogFileRotation−XX:NumberOfGCLogFiles=5−XX:GCLogFileSize=20M−XX:+ParallelRefProcEnabled−XX:−ResizePLAB−XX:G1MixedGCCountTarget=16−XX:InitiatingHeapOccupancyPercent=75−XX:G1ReservePercent=5−XX:G1NewSizePercent=8−XX:G1HeapRegionSize=16m−XX:ErrorFile=logdir/hserrpidexportHBASEMASTEROPTS="HBASE_MASTER_OPTS -Xmxmaster_heapsize -XX:PermSize=256m -XX:MaxPermSize=256m”
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:CMSInitiatingOccupancyFraction=70 -Xmsregionserver_heapsize -Xmxregionserver_heapsize"
经过参数优化之后,regionserver 频繁挂掉的情况有所改善。
但是,regionserver 还是出现了挂掉的情况,只是比之前有改善。因此通过优化堆栈以及gc,并不能完全解决该问题。
三、分析故障原因
既然通过优化hbase本身无法解决regionserver频繁挂掉的原因,那就必须将分析扩大到hbase相关的进程。与hbase密切相关的是zookeeper。我们详细分析看zk的日志,比如之前regionserver在03:03:17时间出现了regionserver dead 报错信息,因此我们分析zk在这个时间段前后的日志。从日志看到regionserver与zk的超时时间是40秒,“the sessions negotiated with zookeeper from dead regionserver were of 40s”。然后再查看regionserver的gc时长,确实超过了40秒。
总结原因:
(1)gc时间过长,超过40秒的maxSessionTimeout时间,使得zk认为regionserver已经挂掉dead;
(2)zk返回dead region到master,master就让其他regionserver负责dead regionserver的regions;
(3)其他regionserver会读取wal进行恢复regions,处理完的wal,会把wal文件删除;
(4)dead regionserver的gc完成,并且恢复服务之后,找不到wal,已经产生上面截图中的报错(wal.FSHLog: Error syncing, request close of WAL);
(5)dead regionserver从zk得知自己dead,就关闭自己(Region server exiting,java.lang.RuntimeException: HRegionServer Aborted)
四、最终原因:tickTime超时
经过上面的分析,是gc时间超过40秒的maxSessionTimeout导致的regionserver挂掉。但是,我们就很纳闷了,因为我们设置的zookeeper.session.timeout超时时间为240秒,远远超过40秒时间。非常奇怪呀!
经过hbase社区求助,以及google类似的问题,最终找到原因(详细链接,请参考:https://superuser.blog/hbase-dead-regionserver/):
原来我们的HBase 并没有设置tickTime,最终hbase与zk的会话最大超时时间并不是zookeeper.session.timeout参数决定的,而是有zk的maxSessionTimeout决定。zk会根据minSessionTimeout与maxSessionTimeout两个参数重新调整最后的超时值,minSessionTimeout=2*tickTime, maxSessionTimeout=20*tickTime。我们的大数据集群,zk的tickTime设置为默认值(2000ms)2秒,因此,最终hbase 与 zk的超时时间就为40秒。
经过调整zk的tickTime为6秒,相应的zookeeper.session.timeout为120秒,最终解决regionserver 频繁挂掉的故障。
以上是关于Regionserver频繁挂掉故障处理实践的主要内容,如果未能解决你的问题,请参考以下文章