排查HBase内存泄漏导致RegionServer挂掉问题
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了排查HBase内存泄漏导致RegionServer挂掉问题相关的知识,希望对你有一定的参考价值。
问题描述
在测试Phoenix稳定性时,发现HBase集群其中一台RegionServer节点FullGC严重,隔一段时间就会挂掉。
HBase集群规格
| 选项 | Master | RegionServer |
|---|---|---|
| 节点数 | 2台,一主一备 | 3台 |
| CPU核数 | 2core | 4core |
| 存储 | SSD云盘,单节点440G |
初步分析
使用jstat监控RegionServer的Heap Size和垃圾回收情况:
[root@iZbp18zqovyu9djsjb05dzZ ~]# jstat -gcutil 454 5000
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
100.00 0.00 55.68 90.19 98.75 97.30 2244 57.381 149 3.411 360.792
100.00 0.00 55.84 91.32 98.75 97.30 2244 57.381 150 4.724 365.516
100.00 0.00 56.30 92.22 98.75 97.30 2244 57.381 150 4.724 365.516
100.00 0.00 56.88 91.55 98.75 97.30 2244 57.381 151 3.411 368.927
100.00 0.00 57.09 92.37 98.75 97.30 2244 57.381 152 4.057 372.984
Old区内存一直在90%多,且FullGC次数一直在增多。
通过ganglia查看集群的FullGC情况,也可以看出003节点持续在FullGC,并最终挂掉。
怀疑存在内存泄漏导致FullGC可回收的内存越来越小,回收的时间也越来越长,最终导致RegionServer心跳超时,被Master干掉。
问题定位
排查内存泄漏问题,可借助jmap分析java堆内存的占用情况,jmap使用参考:https://blog.csdn.net/xidiancoder/article/details/70948569
使用jmap将RegionServer堆内存dump下来:
[root@iZbp16ku9i9clejitib6dzZ opt]# jmap -dump:format=b,file=regionserver.bin 30590
Dumping heap to /opt/regionserver.bin ...
Heap dump file created
然后借助MAT内存分析工具分析RegionServer的堆内存占用情况
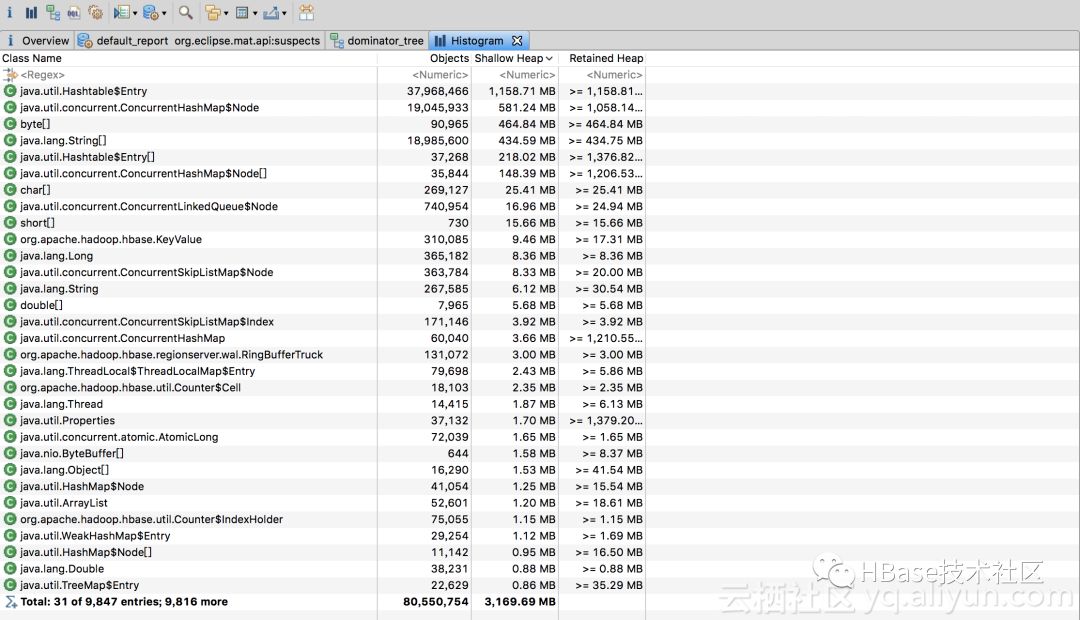
MAT提供Memory Leak Suspect Report分析功能,可帮助我们找到可能存在泄漏的对象:
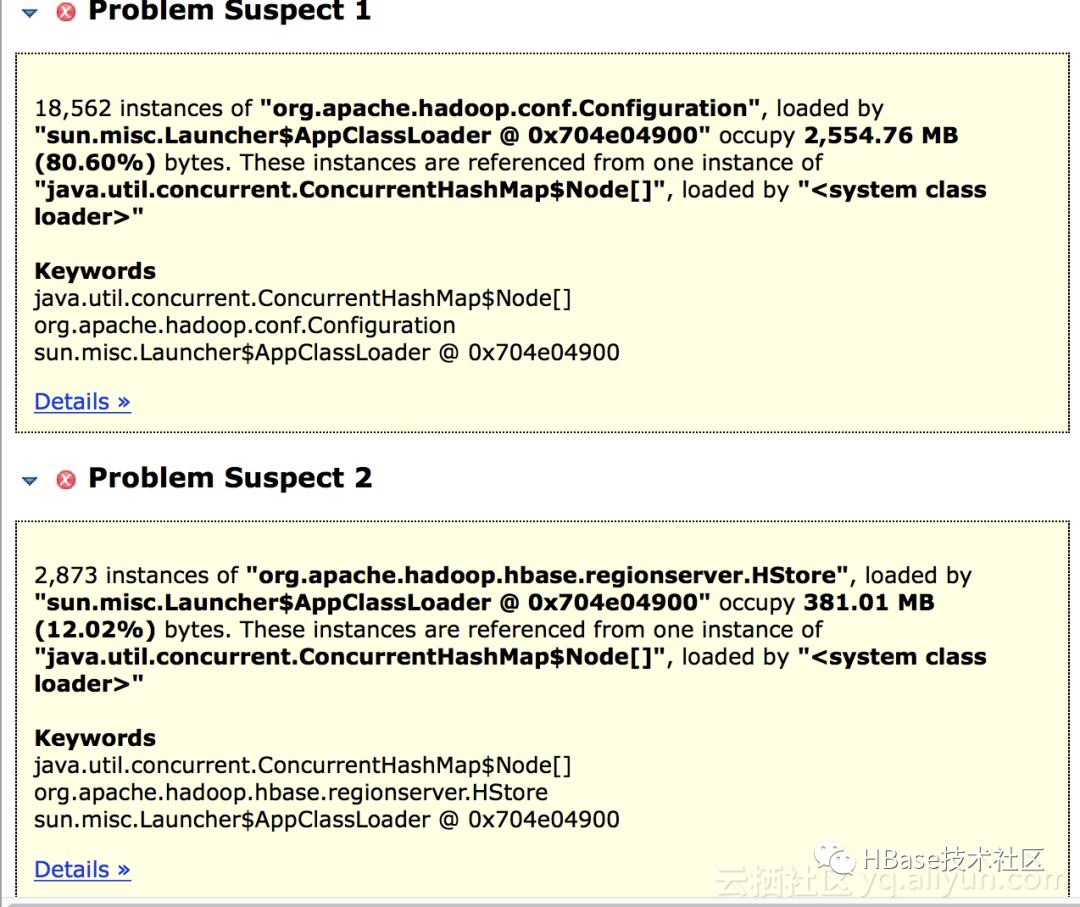
可以看到Configuration对象已经占用到80%堆内存,Configuration底层使用HashTable存配置的键值对,与上图内存分配相符,但是还不确定这么多对象是哪里来的以及为什么没有被回收。
查看内存泄漏详细信息:
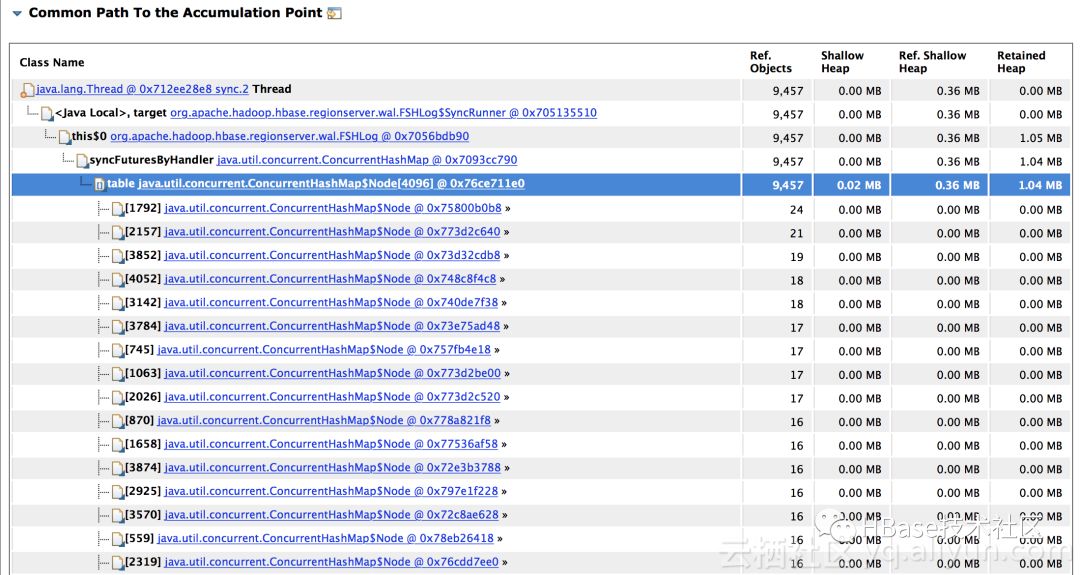
看到这有点懵,Configuration与FSHLog有啥关系呢,这时就要结合Configuration的引用链和HBase的源码来看了。
在堆内存Histogram中,过滤到Configuration对象,然后Merge Shortest path to GC Roots:
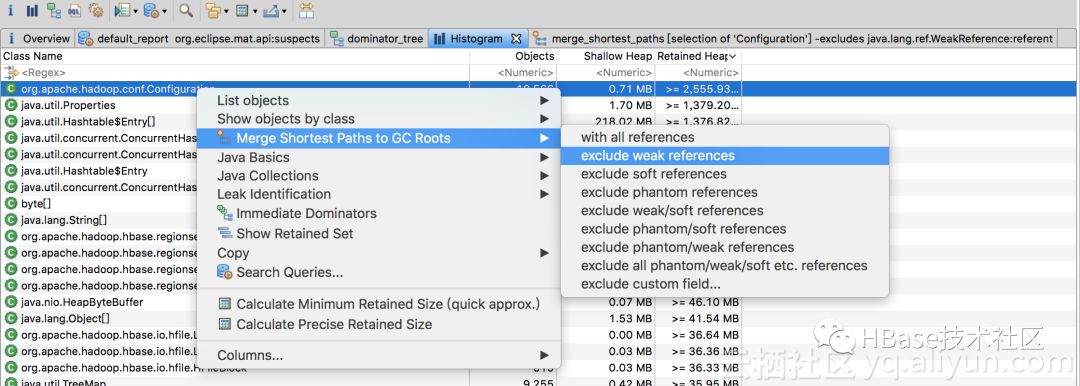
观察到GCRoot最多的就是FSHLog,查看引用链:
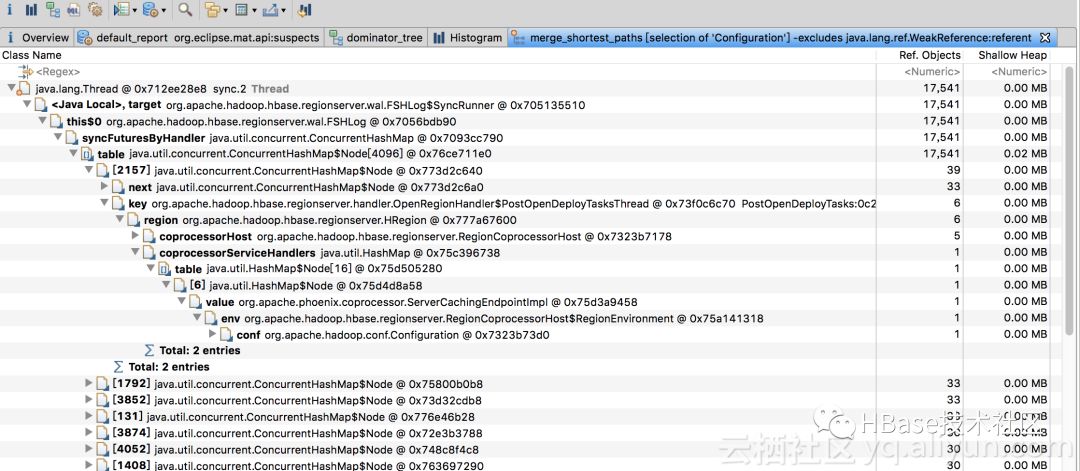
FSHLOG引用OpenRegionHandler$PostOpenDeployTasksThread线程对象,进一步引用HRegion,HRegion引用Coprocessor,然后引用Configuration对象,导致内存泄露。
结合FSHLog源码:
/**
* Map of {@link SyncFuture}s keyed by Handler objects. Used so we reuse SyncFutures.
* TODO: Reus FSWALEntry's rather than create them anew each time as we do SyncFutures here.
* TODO: Add a FSWalEntry and SyncFuture as thread locals on handlers rather than have them
* get them from this Map?
*/
private final Map<Thread, SyncFuture> syncFuturesByHandler;
...
protected AbstractFSWAL(final FileSystem fs, final Path rootDir, final String logDir,
final String archiveDir, final Configuration conf, final List<WALActionsListener> listeners,
final boolean failIfWALExists, final String prefix, final String suffix)
throws FailedLogCloseException, IOException {
...
int maxHandlersCount = conf.getInt(HConstants.REGION_SERVER_HANDLER_COUNT, 200);
// Presize our map of SyncFutures by handler objects.
this.syncFuturesByHandler = new ConcurrentHashMap<>(maxHandlersCount);
}
...
private SyncFuture getSyncFuture(final long sequence, Span span) {
SyncFuture syncFuture = this.syncFuturesByHandler.get(Thread.currentThread());
if (syncFuture == null) {
syncFuture = new SyncFuture();
this.syncFuturesByHandler.put(Thread.currentThread(), syncFuture);
}
return syncFuture.reset(sequence, span);
}
syncFuturesByHandler缓存写WAL的每个线程,但是在线程结束时并不会清除Map中缓存的线程,导致引用的Configuration对象不会被释放。
问题修复
目前该问题已有阿里云HBase社区commiter正研修复并贡献给社区:
https://issues.apache.org/jira/browse/HBASE-21228
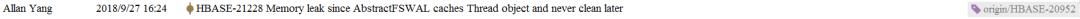
In AbstractFSWAL(FSHLog in branch-1), we have a map caches thread and SyncFutures.
/**
* Map of {@link SyncFuture}s keyed by Handler objects. Used so we reuse SyncFutures.
* <p>
* TODO: Reuse FSWALEntry's rather than create them anew each time as we do SyncFutures here.
* <p>
* TODO: Add a FSWalEntry and SyncFuture as thread locals on handlers rather than have them get
* them from this Map?
*/
private final ConcurrentMap<Thread, SyncFuture> syncFuturesByHandler;
A colleague of mine find a memory leak case caused by this map.
Every thread who writes WAL will be cached in this map, And no one will clean the threads in the map even after the thread is dead.
In one of our customer's cluster, we noticed that even though there is no requests, the heap of the RS is almost full and CMS GC was triggered every second.
We dumped the heap and then found out there were more than 30 thousands threads with Terminated state. which are all cached in this map above. Everything referenced in these threads were leaked. Most of the threads are:
1.PostOpenDeployTasksThread, which will write Open Region mark in WAL
2. hconnection-0x1f838e31-shared--pool, which are used to write index short circuit(Phoenix), and WAL will be write and sync in these threads.
3. Index writer thread(Phoenix), which referenced by RegionCoprocessorHost$RegionEnvironment then by HRegion and finally been referenced by PostOpenDeployTasksThread.
We should turn this map into a thread local one, let JVM GC the terminated thread for us.
AbstractFSWAL源码通过ThreadLocal替换ConcurrentHashMap修复此问题:
/**
* Map of {@link SyncFuture}s owned by Thread objects. Used so we reuse SyncFutures.
* Thread local is used so JVM can GC the terminated thread for us. See HBASE-21228
* <p>
*/
private final ThreadLocal<SyncFuture> cachedSyncFutures;
...
protected AbstractFSWAL(final FileSystem fs, final Path rootDir, final String logDir,
final String archiveDir, final Configuration conf, final List<WALActionsListener> listeners,
final boolean failIfWALExists, final String prefix, final String suffix)
throws FailedLogCloseException, IOException {
...
this.cachedSyncFutures = new ThreadLocal<SyncFuture>() {
@Override
protected SyncFuture initialValue() {
return new SyncFuture();
}
};
}
...
protected final SyncFuture getSyncFuture(long sequence) {
return cachedSyncFutures.get().reset(sequence);
}


阿飞的博客,主要分享JVM/redis/Kafka/Dubbo/Sharding-JDBC以及Linux相关技术,最全的Sharding-JDBC源码分析,喜欢研究分布式,分库分表,缓存分布式技术。
以上是关于排查HBase内存泄漏导致RegionServer挂掉问题的主要内容,如果未能解决你的问题,请参考以下文章