文献阅读:Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks
Posted Espresso Macchiato
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读:Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks相关的知识,希望对你有一定的参考价值。
文献链接:https://arxiv.org/pdf/1908.10084.pdf
1. 文章简介
这篇文章目前来说也算是一篇比较老的文章了,算是紧跟着bert之后的一篇基于bert的后续考察。
众所周知,bert之后的一种标准范式就是用[CLS]的embedding来进行后续sentence level任务(例如分类问题)的输入进行finetune。因此,一种直接的想法就是,如果我直接用[CLS]的embedding作为sentence的embedding是否能够得到一个比较好的效果,如果不行的话,那么我是否可以通过其他的一些方式来获得一个较好的sentence embedding的表达。
2. 主要方法介绍
这篇文章首先考察了一下直接使用bert的[CLS]的embedding作为sentence embedding进行了一下效果评估,发现效果不好,然后在此基础上考察如何优化其效果。
其得出的结论也挺简单的,就是在bert的基础上在下游任务中进行finetune,然后把sentence embedding的部分进行截取作为sentence的embedding即可。
模型结构具体如下图所示:
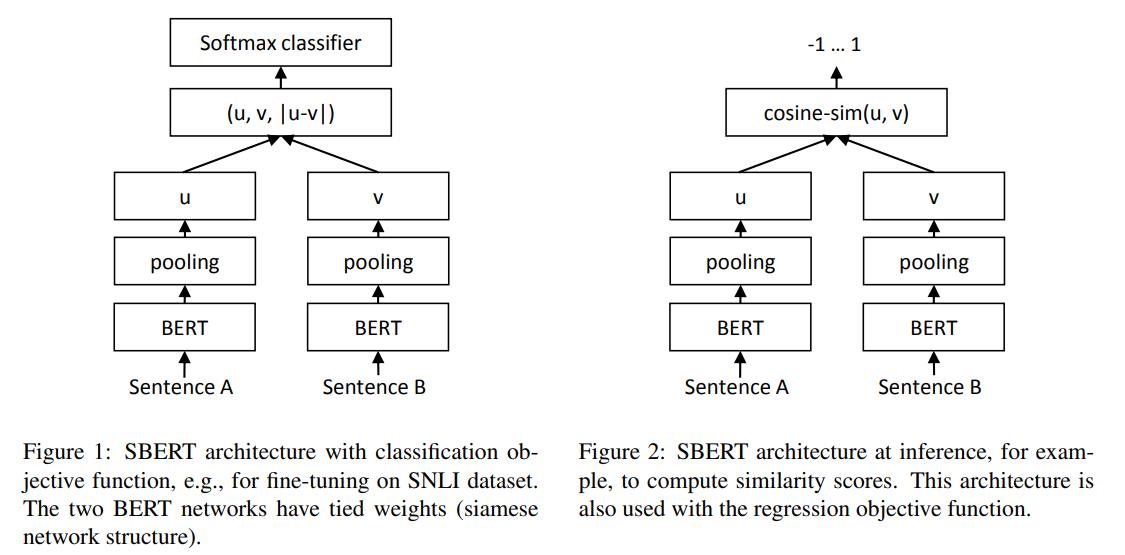
其中,下游的finetune任务这篇文献中选用的是SNLI以及NLI任务,而初始化的模型则是使用的bert以及Roberta只能说整体的思路还是非常的直接的。
3. 主要实验内容
文献中一共给出了6个实验的实验结果,这里给出个人觉得比较重要的4个实验结果进行一下展示。
1. Unsupervised STS
首先我们看一下只使用SNLI以及NLI数据集进行finetune之后的模型直接在STS当中的效果,给出实验结果如下:

可以看到,除了在SICK-R数据集上SentenceBert基本上是碾压了之前其他的sentence embedding的方法,而SICK-R数据上面的落后作者认为是训练数据集的gap导致的,这个也没有足够的证据,不过整体上这个结果基本没有啥太大的问题,还是可以认为SentenceBert效果上确实可以超越之前所有的方法。
2. Supervised STS
上述实验证明了SentenceBert方式确实利用了bert本身的参数信息,拥有很好的性能表现,而这里则是通过监督学习的方式证明上述模型架构在监督学习的情况下能够获得更好地性能表达。

3. Downsteam SentEval Evaluation
而除了在sentence embedding本身的Spearman correlation之外,这里主要是看其训练得到的embedding信号是否有助于下游的NLP任务。
这里采用的测试数据集为SentEval,其结果如下表所示:
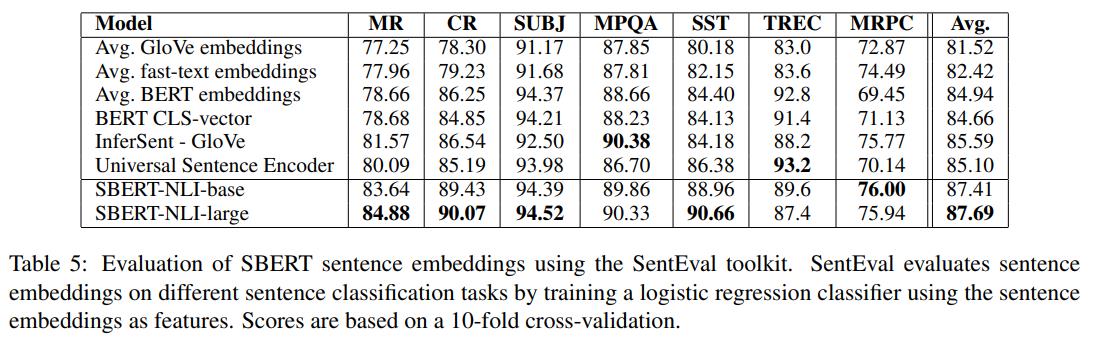
可以看到,其训练得到的sentence embedding也的确能够辅助下游任务,其效果是可适配的。
4. Ablation Study
最后,文献中做了一些消解实验来考察了一下embedding的使用方式以及训练过程中embedding的使用方式。
得到结果如下表所示:

可以看到,整体上来说,要从bert这边获得sentence的embedding,pooling的方式还是比直接拿cls效果更好,而且sentence embedding在训练过程中的使用方式上面,文中的方式似乎还是有明显的优势的。
4. 结论 & 思考
整体而言,这篇文章在我看来最大的意义在于说是对Bert的模型的复用,大模型预训练的结果是真的香,不过时至今日基本这也是共识了。
另外就是这篇文章还指出了bert的直接的[CLS]token的embedding直接用来作为sentence embedding效果并不好,必须要经过下游任务的finetune才能够达到一个好的效果,这个虽然不是文章的核心内容,不过于我而言倒算是一个比较有用的结论,也算是侧面印证了Roberta关于Bert对于NSP任务较弱的观点,毕竟在Bert当中,[CLS]token的embedding信息完全是通过NSP任务来进行有效学习的。
以上是关于文献阅读:Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks的主要内容,如果未能解决你的问题,请参考以下文章