Flink学习之flink sql
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink学习之flink sql相关的知识,希望对你有一定的参考价值。
🌰 昨天我们学习完Table API后,今天我们继续学SQL,Table API和SQL可以处理SQL语言编写的查询语句,但是这些查询需要嵌入用Java、Scala和python编写的程序中。
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
🌱flink sql只需要具备 SQL 的基础知识即可,不需要其他编程经验。我的SQL 客户端选择的是docker安装的Flink SQL Click,大家根据自己的需求安装即可。
目录
1. SQL客户端
SQL客户端内置在Flink的版本中,大家只要启动即可,我使用的是docker环境中配置的Flink SQL Click,让我们测试一下:

输入’helloworld’ 看看输出的结果。
SELECT ‘hello world’;
结果如下:说明运行成功!

2. SQL语句
2.1 create
CREATE 语句用于向当前或指定的 Catalog 中注册表、视图或函数。注册后的表、视图和函数可以在 SQL 查询中使用。
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
<physical_column_definition> | <metadata_column_definition> | <computed_column_definition> [ , ...n]
[ <watermark_definition> ]
[ <table_constraint> ][ , ...n]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( <like_options> )] ]
-- 例如
CREATE TABLE Orders_with_watermark (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'scan.startup.mode' = 'latest-offset'
);
2.2 drop
DROP 语句可用于删除指定的 catalog,也可用于从当前或指定的 Catalog 中删除一个已经注册的表、视图或函数。
--删除表
DROP TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
--删除数据库
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
--删除视图
DROP [TEMPORARY] VIEW [IF EXISTS] [catalog_name.][db_name.]view_name
--删除函数
DROP [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF EXISTS] [catalog_name.][db_name.]function_name;
2.3 alter
ALTER 语句用于修改一个已经在 Catalog 中注册的表、视图或函数定义。
--修改表名
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
--设置或修改表属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
--修改视图名
ALTER VIEW [catalog_name.][db_name.]view_name RENAME TO new_view_name
--在数据库中设置一个或多个属性。若个别属性已经在数据库中设定,将会使用新值覆盖旧值。
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
2.4 insert
INSERT 语句用来向表中添加行(INTO是追加,OVERWRITE是覆盖)
-- 1. 插入别的表的数据
INSERT INTO | OVERWRITE [catalog_name.][db_name.]table_name [PARTITION part_spec] select_statement
-- 2. 将值插入表中
INSERT INTO | OVERWRITE [catalog_name.][db_name.]table_name VALUES [values_row , values_row ...]
-- 追加行到该静态分区中 (date='2019-8-30', country='China')
INSERT INTO country_page_view PARTITION (date='2019-8-30', country='China')
SELECT user, cnt FROM page_view_source;
-- 追加行到分区 (date, country) 中,其中 date 是静态分区 '2019-8-30';country 是动态分区,其值由每一行动态决定
INSERT INTO country_page_view PARTITION (date='2019-8-30')
SELECT user, cnt, country FROM page_view_source;
-- 覆盖行到静态分区 (date='2019-8-30', country='China')
INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30', country='China')
SELECT user, cnt FROM page_view_source;
-- 覆盖行到分区 (date, country) 中,其中 date 是静态分区 '2019-8-30';country 是动态分区,其值由每一行动态决定
INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30')
SELECT user, cnt, country FROM page_view_source;
2.5 show
show用于列出所有的catalog、database、function等
-- 列出catalog
SHOW CATALOGS;
-- 列出数据库
SHOW DATABASES;
--列出表
SHOW TABLES;
-- 列出视图
SHOW VIEWS;
--列出函数
SHOW FUNCTIONS;
-- 列出所有激活的 module
SHOW MODULES;
3. Window Functions
这里的Window Functions不是指我们sql中的窗口函数,是指处理流数据中特有的窗口操作。
3.1 滚动窗口 TUMBLE
TUMBLE函数把行分配到有固定间隔时间且不重叠的窗口上,滚动窗口在批处理和流处理可以定义在事件时间上,但只有流处理可以定义在处理时间上。

--1. TUMBLE函数的参数
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
-- TABLE:代表数据源
-- DESCRIPTOR(timecol):指时间列
-- size:指窗口大小
-- offset:可增加其他参数,会有特别的意义
-- 2.实例
SELECT window_start, window_end, SUM(price)
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
3.2 滑动窗口 HOP
滑动窗口在批处理和流处理中可以定义在事件时间上,但只有流处理可以定义在处理时间上。(数据会有重复)
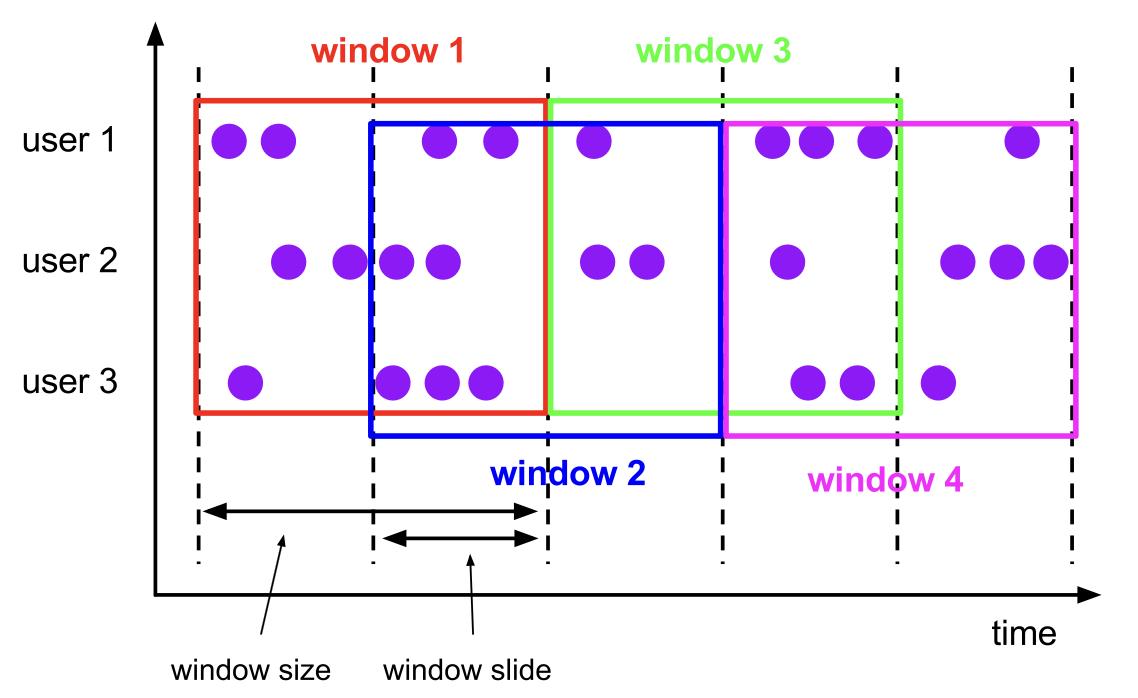
-- 1. HOP函数的参数
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
-- TABLE:代表数据源
-- DESCRIPTOR(timecol):指时间列
-- slide:指窗口滑动的大小
-- size:指窗口大小
-- offset:可增加其他参数,会有特别的意义
-- 2.实例
SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
3.3 累计窗口 CUMULATE
累计窗口是指在固定窗口内,每隔一段时间触发操作。类似于滚动窗口内定时进行累计操作。
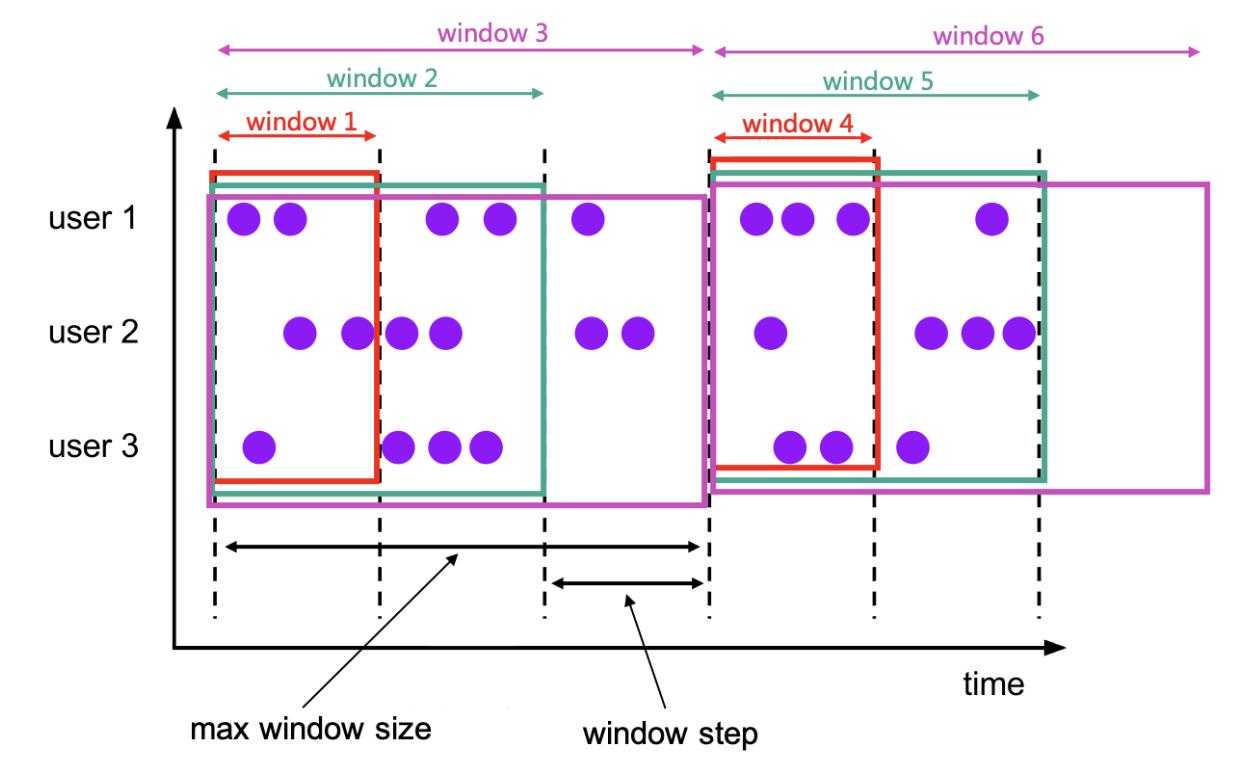
--1. 累计窗口的参数
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
--data: 和时间有关的数据源
--timecol: 时间列,数据的哪些时间属性列应该映射到滚动窗口。
--step: 是指定顺序累积窗口结束之间增加的窗口大小的持续时间。
--size: 是指定累积窗口最大宽度的持续时间。size 必须是 step 的整数倍。
-- offset:可增加其他参数,会有特别的意义
-- 实例
SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
4. 其他函数
处理上述这些,剩下还有的操作都是和我们的SQL语法差不多,就不再阐述:
- 窗口聚合函数:group by、…
- 分组聚合函数:count、having、count(distinct xxx)、…
- over聚合函数:over(partition by xxx order by xxx)、…
- 内外连接函数:join、left join 、outer join、…
- limit 函数
- TOP-N函数: rank()、dense_rank()、row_number()
对以上内容感兴趣的小伙伴可以参考如下链接:
- SQL教程: SQL专题-各部分函数讲解.
5. 总结
今天学习的sql,和往常不一样的地方在于,以往的sql都是处理的是批数据,而今天学习的flink sql可以处理流数据,流数据随着时间的变化而变化,flink sql可以对流数据进行类似表一样的处理,可以实现大部分DataStream API和DataSet API的功能。
😂还有就是,flink sql中的窗口函数和我们传统的窗口函数不一样,按理来说,我们正常的窗口函数应该叫over聚合函数。
6. 参考资料
《Flink入门与实战》
《PyDocs》(pyflink官方文档)
《Kafka权威指南》
《Apache Flink 必知必会》
《Apache Flink 零基础入门》
《Flink 基础教程》
以上是关于Flink学习之flink sql的主要内容,如果未能解决你的问题,请参考以下文章