Flink学习之容错机制和状态一致性
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink学习之容错机制和状态一致性相关的知识,希望对你有一定的参考价值。
☀️在前天的学习中,我们学习了flink中的几个重要概念:时间、水位线和状态,今天我们继续学习flink中的两个重要机制:容错机制和状态一致性保证。对往期内容感兴趣的同学可以参考👇:
- 链接: Flink学习中之time、watermark、state.
- 链接: Flink实战之电商用户行为实时分析.
- 链接: Flink学习之flink sql.
- 链接: Flink学习之Table API(python版本).
- 链接: Flink学习之DataStream API(python版本).
🌰flink的容错机制是指出现故障后,如何恢复数据?状态一致性保证是指出现故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比,前者到底有多正确?接下来,接下来我们将对这两个部分进行详细了解。
目录
1. flink的容错机制
1.1 checkpoint
checkpoint是flink故障恢复的核心,所谓的checkpoint,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候
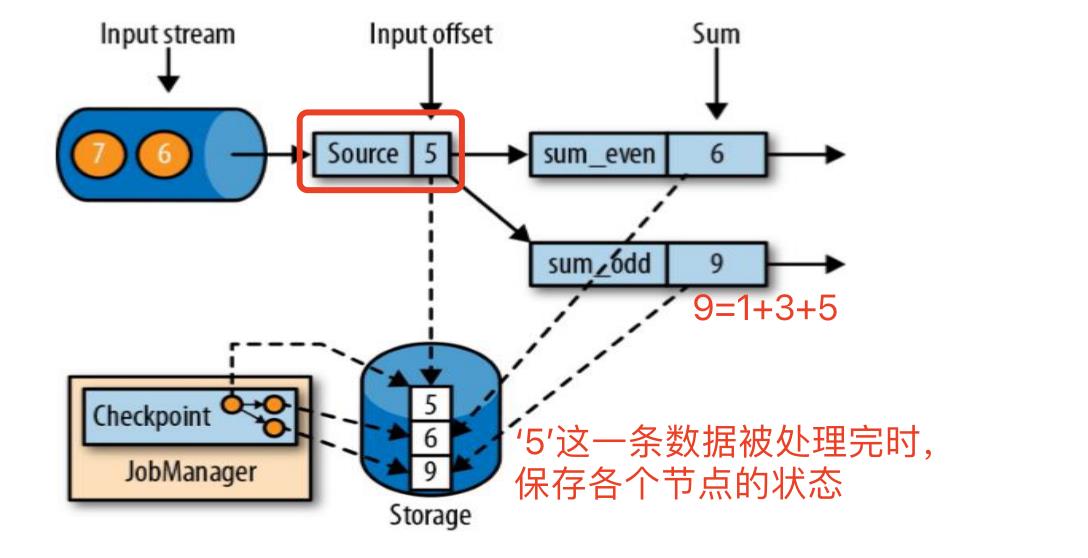
如图所示,我们的消息偏移量是5,所以当前处理的是‘5’这个数字,我们需要保存的checkpoint,就是指奇数求和sum_odd处理完5之后,所有节点的状态,比如我们这里需要保存的状态有:source=5,奇数求和sum_odd=9,偶数求和sum_even=6这些信息进行存盘,而jobmanage只保存checkpoint的元数据。
1.2 从checkpoint恢复状态
在执行流应用程序期间,Flink 会定期保存状态的一致检查点;如果发生故障, Flink 将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程,恢复的过程如下:
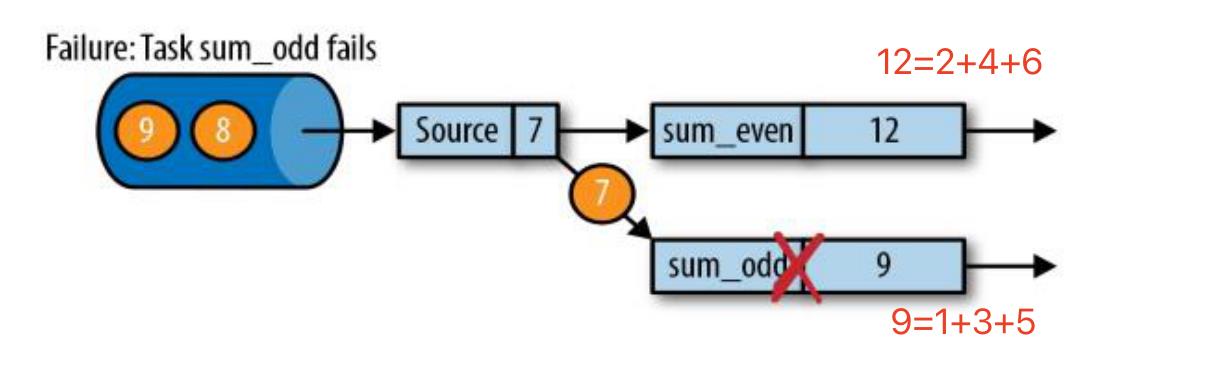
当前有一个流式处理的任务,统计数据的奇数和偶数之后,当‘7’这条数据传入sum_odd的过程中发生了错误,我们需要从最近的检查点恢复。
-
第一步就是重启应用(重启任务后,任务中无数据无状态。)

-
第二步:从 checkpoint 中读取状态,将状态重置
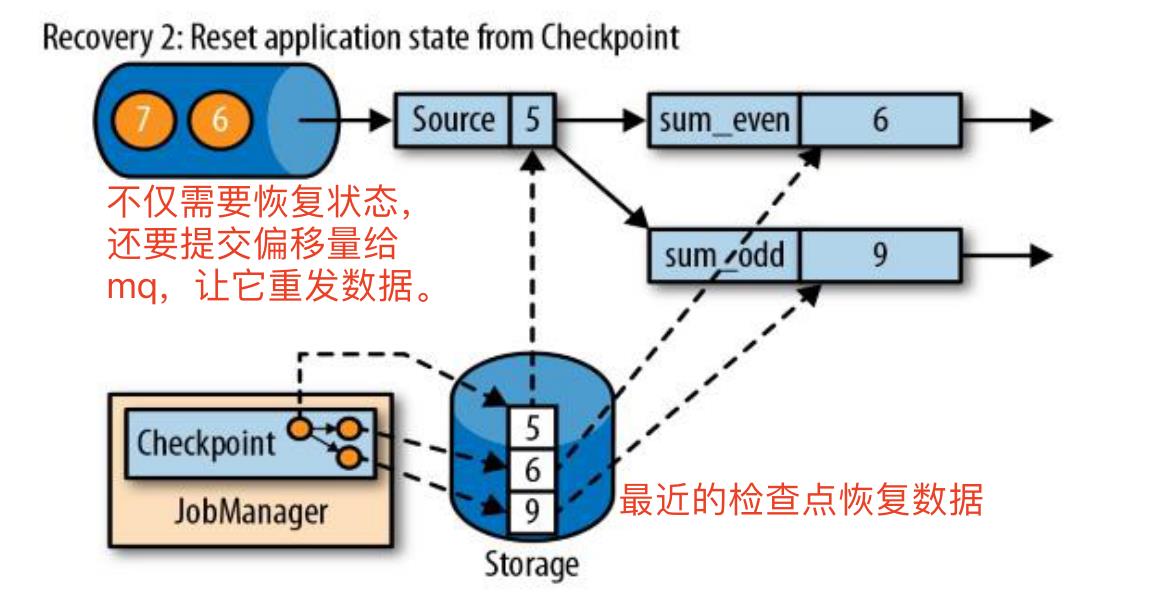 从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同,这里需要注意的是source任务的恢复不仅需要恢复当前状态,还要重新提交偏移量给消息队列,让mq重发数据。
从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同,这里需要注意的是source任务的恢复不仅需要恢复当前状态,还要重新提交偏移量给消息队列,让mq重发数据。 -
第三步:开始消费并处理检查点到发生故障之间的所有数据

这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置。
1.3 checkpoint的恢复算法
在spark中的checkpoint是根据stage划分阶段,等该stage运行完毕后,保存当前stage的数据。而在flink中将检查点的保存和数据处理分离开,不暂停整个应用。
- 检查点分界线(Checkpoint Barrier)
flink的检查点算法用到了一种称为**分界线(barrier)**的特殊数据形式,用来把一条流上数据按照不同的检查点分开;分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中。
flink涉及的是分布式任务的checkpoint,如何在并行执行的情况下保证各个任务的状态一致?我们举例说明。 - 现在是一个有两个输入流的应用程序,用并行的两个 Source 任务来读取。
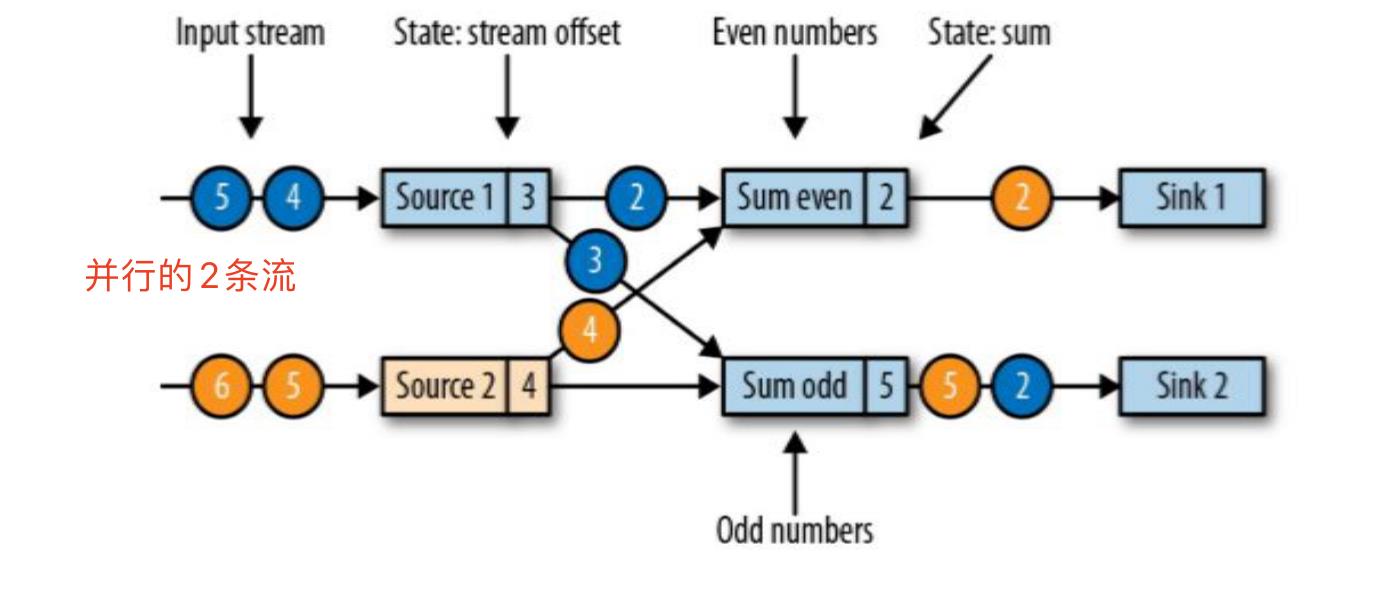
- JobManager 会向每个 source 任务发送一条带有新检查点 ID 的消息,通过这种方式来启动检查点(记住是每个任务都发一个检查点)
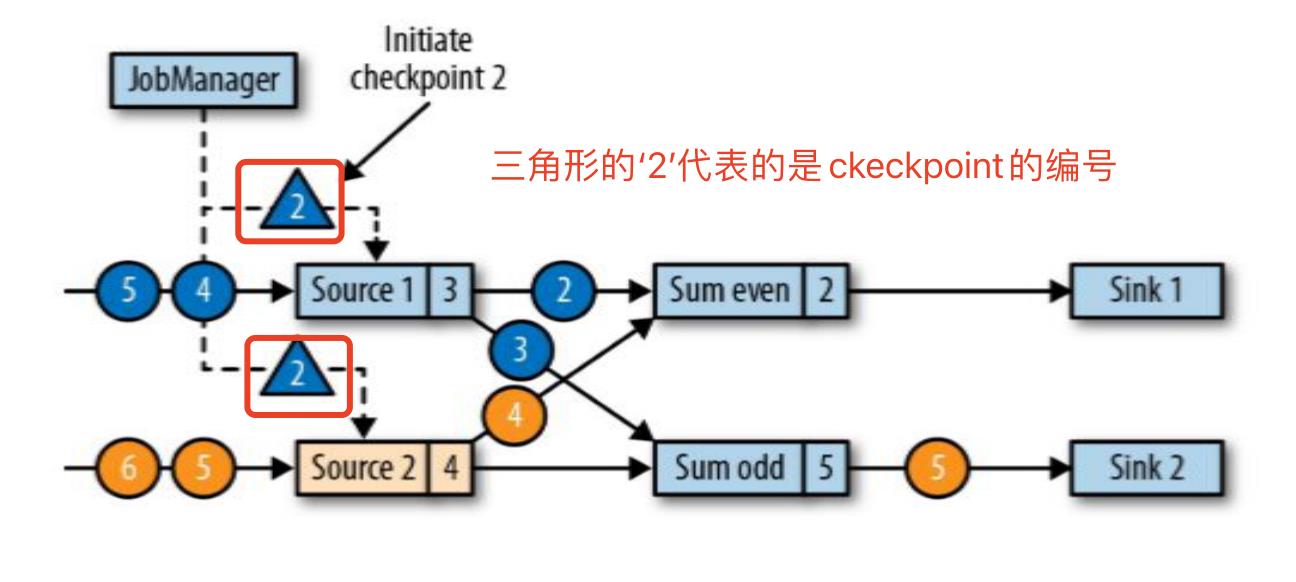
- 数据源将它们的状态写入检查点,并发出一个检查点 barrier,状态后端在状态存入检查点之后,会返回通知给 source 任务,source 任务就会 向 JobManager 确认检查点完成。
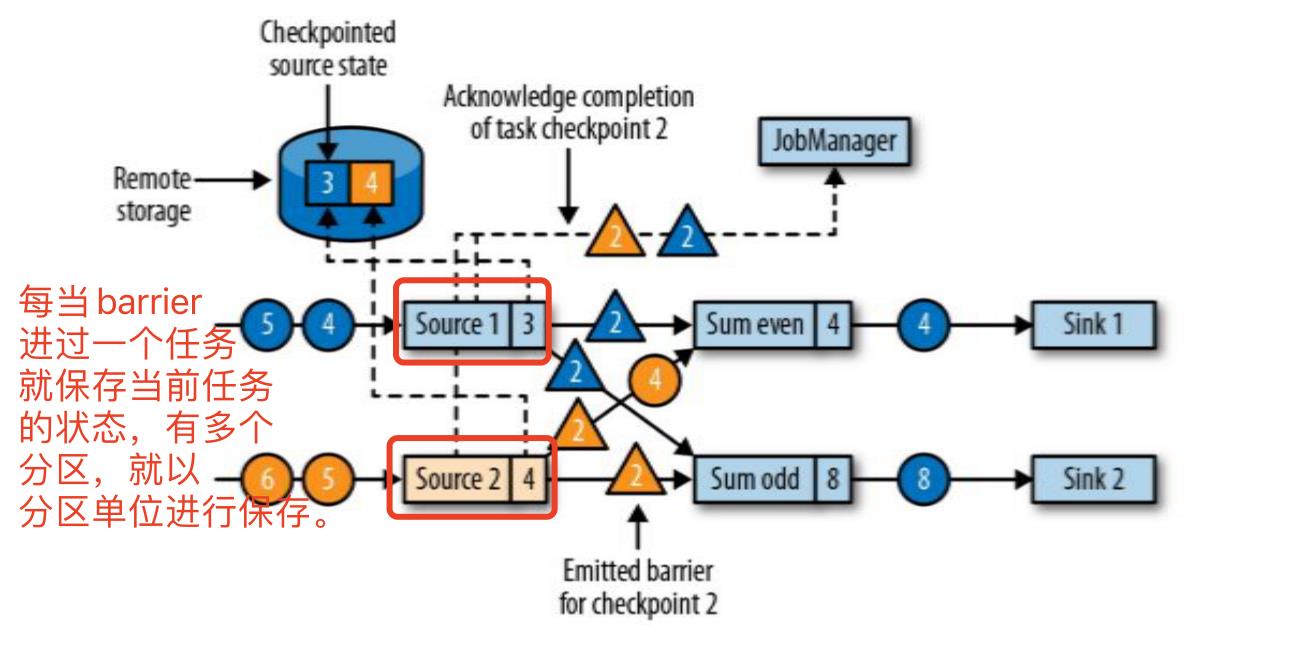
- 分界线对齐:barrier 向下游传递,sum 任务会等待所有输入分区的 barrier 到达 ; 对于barrier已经到达的分区,继续到达的数据会被缓存;而barrier尚未到达的分区,数据会被正常处理。

- 当收到所有输入分区的 barrier 时,任务就将其状态保存到状态后端的检查点中,然后将 barrier 继续向下游转发
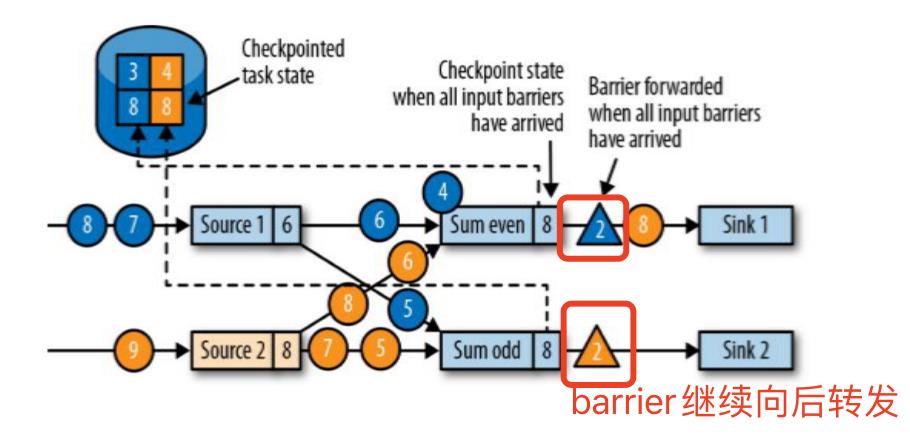
- 向下游转发检查点 barrier 后,任务继续正常的数据处理,Sink 任务向 JobManager 确认状态保存到 checkpoint 完毕,当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了
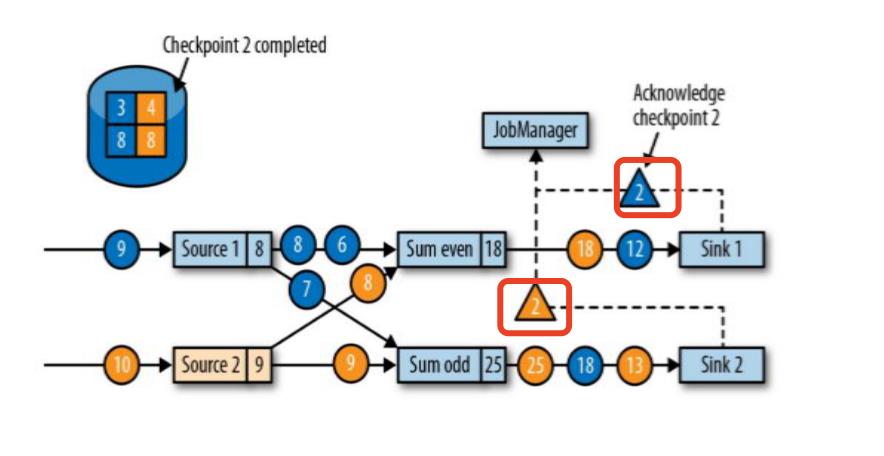
1.4 save points
这里介绍一个和checkpoint差不多的概念——保存点:
- 可以自定义的镜像保存功能,就是保存点(savepoints)。
- 原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点。
- Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地触发创建操作。
- 保存点是一个强大的功能。除了故障恢复外,保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停和重启应用,等等。
2.flink的状态一致性
2.1 状态一致性定义
- 有状态的流处理,内部每个算子任务都可以有自己的状态。
- 对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确。
- 一条数据不应该丢失,也不应该重复计算。
- 在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
状态一致性分为以下几类:
- AT-MOST-ONCE(最多一次):当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重播丢失的数据。At-most-once 语义的含义是最多处理一次事件。
- AT-LEAST-ONCE(至少一次):在大多数的真实应用场景,我们希望不丢失事件。这种类型的保障称为 atleast-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次。
- EXACTLY-ONCE(精确一次):恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。
2.2 一致性检查点
- Flink 使用了一种轻量级快照机制(检查点checkpoint)来保证 exactly-once 语义(这里的checkpoint就是第一部分的检查点)
- 有状态流应用的一致检查点,其实就是:所有任务的状态,在某个时间点的一份拷贝(一份快照)。而这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
- 应用状态的一致检查点,是 Flink 故障恢复机制的核心
2.3 端到端(end-to-end)状态一致性
这里所谓的端到端的一致性是指,我们不仅需要保证flink运行机制的一致性,还需要保证数据源(例如 Kafka)和输出到持久化系统一致性。
- 意味着结果的正确性流处理框架的全部过程,每一个组件都保证了它自己的一致性。
- 整个端到端的一致性级别取决于所有组件中一致性最弱的组件。
- flink内部: checkpoint保证
- source端(数据源):可重设数据的读取位置(重设偏移量)
- sink 端(输出端):从故障恢复时,数据不会重复写入外部系统
2.4 端到端的精确一次(exactly-once)保证
在上面我们说到,端到端的一致性保证中,flink内部有checkpoint,source端可以重新设置偏移,sink端不会重复写。那如何保证sink端端一致性呢?
- 幂写入( e x e^x ex)
幂写入是指一个操作,可以允许重复执行很多次,,但是只有一次导致结果更改,后面再重复执行就不起作用了。
- 事务写入
这里的事务和关系型数据的事务很像(ACID),一个事务中的一系列的操作要么全部成功,要么一个都不做。实现的方法:构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。
-
- 预写日志
把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统,简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么sink 系统,都能用这种方式一批搞定。(缺点就是,在流式框架中,出现了类似批的操作,容易影响速率)
- 预写日志
-
- 两阶段提交(一般采用这种形式)
对于每个 checkpoint,sink 任务会启动一个事务,并将接下来所有接收的数据添加到事务里,然后将这些数据写入外部 sink 系统,但不提交它们(这时只是“预提交”),当它收到 checkpoint 完成的通知时,它才正式提交事务,实现结果的真正写入。
- 两阶段提交(一般采用这种形式)
2.5 Flink+Kafka 端到端状态一致性的保证
这里我们看一下实际生产过程中,Kafka-Flink-Kafka 怎么实现端到端的状态一致性保证。
- 内部 —— 利用 checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性。
- source —— kafka consumer 作为 source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink —— kafka producer 作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction(2阶段提交)
- JobManager 协调各个 TaskManager 进行 checkpoint 存储,checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存。

- 当 checkpoint 启动时,JobManager 会将检查点barrier注入数据流,barrier会在算子间传递下去,每个算子会对当前的状态做个快照,保存到状态后端。

- 每个内部的 transform 任务遇到 barrier 时,都会把状态存到checkpoint 里 ;sink 任务首先把数据写入外部 kafka,这些数据都属于预提交的事务;遇到barrier 时,把状态保存到状态后端,并开启新的预提交事务。

- 当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 checkpoint 完成,sink 任务收到确认通知,正式提交之前的事务,kafka 中未确认数据改为“已确认”

我们来总结一下:
- 第一条数据来了之后(进入sink的时间),开启一个 kafka 的事务(transaction),正常写入 kafka 分 区日志但标记为未提交,这就是“预提交”。
- jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到barrier 的算子将状态存入状态后端,并通知 jobmanager。
- sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager, 并开启下一阶段的事务,用于提交下个检查点的数据(事务可以同时开启)。
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成。
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据。(事务的完成只和它关联的checkpoint有关)
- 外部kafka关闭事务,提交的数据可以正常消费了。
3. 总结
本片博客主要讲述了flink的容错机制,以及流处理框架如何实现状态一致性,主要需要记住source、flink内部、sink这三部分通过什么机制,如何实现错误恢复的。 我在文章里记录的都很详细。
4. 参考资料
《尚硅谷Java版Flink》
《Flink入门与实战》
《Kafka权威指南》
《Apache Flink 必知必会》
《Apache Flink 零基础入门》
《Flink 基础教程》
以上是关于Flink学习之容错机制和状态一致性的主要内容,如果未能解决你的问题,请参考以下文章