(2021-03-11)大数据学习之Flink基础概念以及简单Demo
Posted Mr. Dreamer Z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(2021-03-11)大数据学习之Flink基础概念以及简单Demo相关的知识,希望对你有一定的参考价值。
Flink的简介
由于公司要求下周可能会要分享一下Flink。所以这周抽了一些时间学习了一点Flink的知识。也是为了自己总结吧,所以接下来会写一点关于Flink的知识。
OK,话不多说。开始我们今天的唠嗑。
1. 什么是Flink
Apache Flink是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink能在所有常见的集群环境中运行,并能以内存速度和任意规模进行计算。
以上这句话是Flink官网的描述:https://flink.apache.org/zh/flink-architecture.html
大家看到这可能会懵逼,什么是有边界和无边界数据流呢?
1.1 有边界数据流和无边界数据流
数据流被分为有边界数据流和无边界数据流。
简单来说的话
有边界数据流:定义了流的起始,也定义了流的结束。可以等待摄取了所有的数据之后进行计算。比如:离线数据。
无边界数据流:只定义流的起始,无休止的产生数据。必须持续处理,当摄取数据之后需要立即处理。不能等到所有的数据都达到才处理,因为输入是无限的。比如:实时告警展示,双11大屏展示等。
1.2 有状态计算
每一个具有一定复杂度的流处理都应该是有状态的,除非它是一个单独的事件。否则它一定会提供状态让下一个事件进行后续处理。
说了这么多,大家应该有一些基础的了解。至于为什么是有状态的计算,Flink作为一个大数据的分布式处处理引擎,大数据处理是有联动性的,比如阿里双11大屏显示交易额或者某个商品的交易数量等。它都不会使一个单独的事件。
当然了,面试的时候大家可能不会想的那么多。那就一句话来概括:Flink就是一个支持批流一体的分布式处理引擎。
2. Flink的起源
Flink 诞生于欧洲的一个大数据研究项目 StratoSphere。该项目是柏林工业大学的一个研究性项目。早期, Flink 是做 Batch 计算的,但是在 2014 年, StratoSphere 里面的核心成员孵化出 Flink,同年将 Flink 捐赠 Apache,并在后来成为 Apache 的顶级大数据项目,同时 Flink 计算的主流方向被定位为 Streaming, 即用流式计算来做所有大数据的计算,这就是 Flink 技术诞生的背景。
2014 年 Flink 作为主攻流计算的大数据引擎开始在开源大数据行业内崭露头角。区别于 Storm、Spark Streaming 以及其他流式计算引擎的是:它不仅是一个高吞吐、低延迟的计算引擎,同时还提供很多高级的功能。比如它提供了有状态的计算,支持状态管理,支持强一致性的数据语义以及支持 基于Event Time的WaterMark对延迟或乱序的数据进行处理等。
2019年1月8日,阿里巴巴以 9000 万欧元(7亿元人民币)收购了创业公司 Data Artisans。从此Flink开始了新一轮的乘风破浪!

由于Flink被阿里收购,Flink也有了中文网站。
Apache Flink 中文官网
3. 为什么要用Flink

主要原因
1.Flink 具备统一的框架处理有界和无界两种数据流的能力
2.部署灵活,Flink 底层支持多种资源调度器。
3.极高的可伸缩性,可伸缩性对于分布式系统十分重要,阿里巴巴双11大屏采用Flink 处理海量数据,使用过程中测得Flink 峰值可达17 亿条/秒。
4.极致的流式处理性能。Flink 相对于Storm 最大的特点是将状态语义完全抽象到框架中,支持本地状态读取,避免了大量网络IO,可以极大提升状态存取的性能。
Flink 是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架。
Spark 只能兼顾高吞吐和高性能特性,无法做到低延迟保障,因为Spark是用批处理来做流处理
Storm 只能支持低延时和高性能特性,无法满足高吞吐的要求
4. 什么是流处理和批处理
在日常工作中,我们通常都会把数据存到DB中,然后将相应的数据取出进行加工和分析。这就涉及到一个时效性的问题。
如果以年、月为单位的进行统计,那么对实时性没有什么要求。但是如果以天、小时或者更小的粒度的数据进行数据,那么要求数据的时效性就很高了。
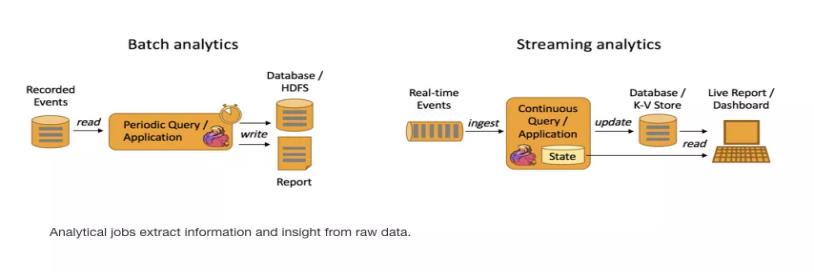
Batch Analytics。传统意义上的统计、分析方式:收集数据->放入DB->对数据进行批量处理。
Streaming Analytics 流式计算,顾名思义,就是对数据流进行处理,如使用流式分析引擎如 Storm,Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表。
简单来说,流处理就是数据来一条处理一条。批处理就是先收集一部分数据然后进行处理。区别就在于:流处理的实时性更强。
5. Flink的应用场景
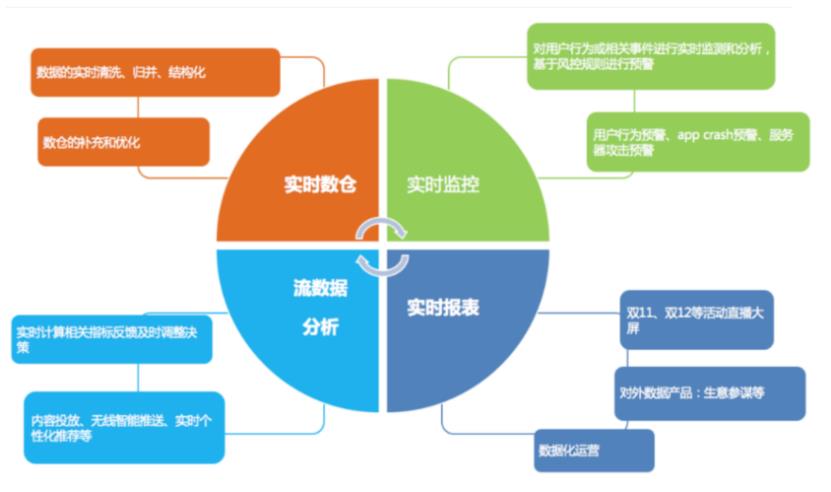
从上图可以看出,Flink的应用场景几乎都是针对实时的统计或者数据分析上。
6. Flink的简单Demo
引入pom
<properties>
<java.version>1.8</java.version>
<flink.version>1.10.1</flink.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
这里说明一下 Tuple2的对应包是org.apache.flink.api.java.tuple.Tuple2
6.1 批处理
public static void main(String[] args) throws Exception
//创建执行环境 批处理
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
//从文件中读取数据
DataSource<String> dataSource = executionEnvironment.readTextFile("D:\\\\操作项目列表\\\\flink\\\\flink-test\\\\src\\\\main\\\\resources\\\\hello.txt");
//对数据集进行处理,按照空格分词展开,转换成(word,1)二元组进行统计
DataSet<Tuple2<String,Integer>> dataSet = dataSource.flatMap(new MyFlatMapper())
.groupBy(0) //按照第一个位置的word分组
.sum(1);//将第二个位置上的数据求和
dataSet.print();
//自定义类,实现FlatMapFunction接口
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String,Integer>>
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception
//按照空格分词
String[] words = value.split(" ");
//遍历所有的word,组成成为二元组输出
for (String word : words)
out.collect(new Tuple2<>(word,1));
在resource下面创建一个文本文件
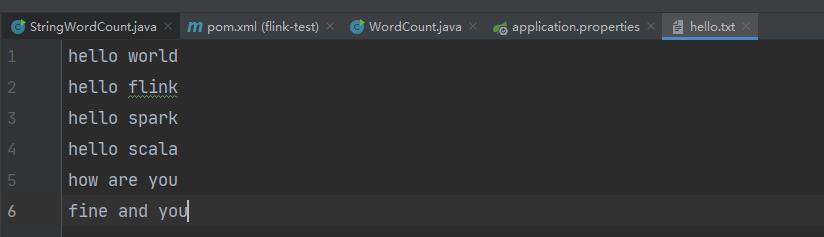
以空格作为分隔
然后执行main方法,可以看到对应的结果
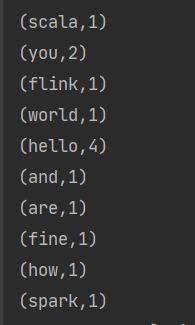
Flink提供了对应的方式,进行数据的统计。
6.2 流处理
public static void main(String[] args) throws Exception
//创建执行环境 流处理
StreamExecutionEnvironment environment = StreamExecutionEnvironment.createLocalEnvironment();
//environment.setParallelism(4);//设置并行度
//读取文件
DataStream<String> dataStream = environment.socketTextStream("127.0.0.1", 9999);
//基于数据流进行转换计算
SingleOutputStreamOperator<Tuple2<String, Integer>> operator = dataStream.flatMap(new MyFlatMapper())
.keyBy(0) //指定key进行不同的划分
.sum(1);
operator.print();
//执行任务 注意了:流处理和批处理不一样。流处理是需要先将操作逻辑规定,再去捞数据进行操作
environment.execute();
//自定义类,实现FlatMapFunction接口
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String,Integer>>
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception
//按照空格分词
String[] words = value.split(" ");
//遍历所有的word,组成成为二元组输出
for (String word : words)
out.collect(new Tuple2<>(word,1));
然后我们在window或者linux系统上面安装一个网络工具 netcat。
nc是netcat的简写,有着网络界的瑞士军刀美誉。因为它短小精悍、功能实用,被设计为一个简单、可靠的网络工具
nc的作用
(1)实现任意TCP/UDP端口的侦听,nc可以作为server以TCP或UDP方式侦听指定端口
(2)端口的扫描,nc可以作为client发起TCP或UDP连接
(3)机器之间传输文件
(4)机器之间网络测速
安装了之后,启动代码。然后
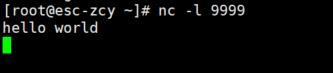
可以看到控制台的输出:

再来一句
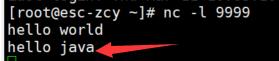
显示
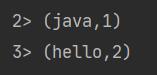
解释一下:数字> 这是代表对应的线程数。然后不信,你可以在创建执行环境之后,设置对应的并行度
environment.setParallelism(4);//设置并行度
以上是关于(2021-03-11)大数据学习之Flink基础概念以及简单Demo的主要内容,如果未能解决你的问题,请参考以下文章