自动驾驶 Apollo 源码分析系列,感知篇:感知融合中的数据关联细节
Posted frank909
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶 Apollo 源码分析系列,感知篇:感知融合中的数据关联细节相关的知识,希望对你有一定的参考价值。
前一篇文章讲了,Apollo 6.0 中融合的代码逻辑流程,但那是基于软件的角度进行梳理和分析的,这一篇文章基于上篇的成果进一步对算法进行更详细的分析,因为代码量奇大,所以本文重点讨论数据关联的一些细节。
目标跟踪的基础知识概念
为保持文章内容由浅入深,先做一些基础的概念介绍。
卡尔曼滤波如何工作?
数据融合最常见的算法是卡尔曼滤波及其变种。
卡尔曼滤波是一个多次迭代的算法,一个周期内的工作如图所示:
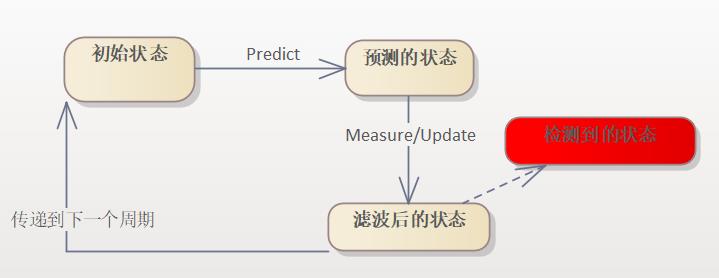
一个目标初始状态,经过 T 时间后,调用 Predict() 方法,初始状态会移植到预测状态,一般 Predict() 方法都是基于特定运动公式进行计算的,比如手机上的 GPS,5s 更新一次 GPS 位置,但 5s 颗粒度太粗了,就将 1s 切分成 10 段,每一段 100ms 自己调用公式推断一次位置,这就是 Predict 过程。
大家会发现问题,这样的结果虽然凑合着可用,但毕竟是理论上推断出来的,不会怎么靠谱。
那就需要一个靠谱的东西,将结果及时纠偏。
比如,你每隔 100ms 自行推断的位置,我每隔 5s 收到 GPS 数据时,用这个数据来更新数据。
这就涉及到融合的过程了,这一过程称为 Update 或者是 Measure,融合可以简单理解为加权,就是一个比例,相信历史数据多一些还是相信检测到的数据多一些。
然后,融合得到的值传递给下一周期的状态值,这样一轮一轮进行下去。
单目标跟踪和多目标跟踪区别?
讲完滤波算法,讲讲单目标跟踪和多目标跟踪的区别。
多目标比单目标难。
假设,车辆前方只有一个目标需要跟踪,比如 ACC 功能。

蓝色正方形是融合系统每次推断的结果值。
橙色三角形是每次传感器检测到的结果。
绿色圆形则是融合的数据。
这是单个目标跟踪,基本上是 1 对 1 的关系,也就是一个目标状态值对应一个观测值。
当然,也许传感器有杂波可能产生多个观测值,但我们同样可以通过算法进行筛选或者做加权融合最终得到一个观测值,总之在单目标跟踪中观测值和状态值一般是 1 对 1 的。
再来看多目标跟踪问题。
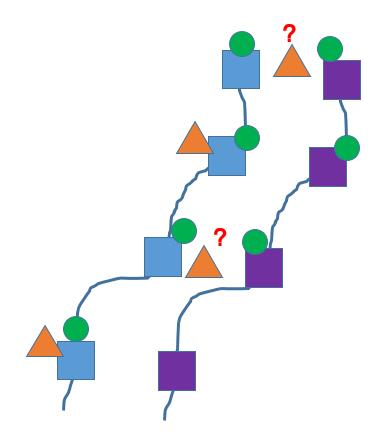
紫色正方形是另外一个目标的状态值,大家很容易发现问题。
上图标记红色问题的地方会存在一个困惑,那个橙色三角形代表的观测数据究竟属于哪个目标真实的检测信号呢?
因为传感器本身也存在抖动,所以,你不能简单说左边,因为左边更近吧?
这涉及到一个多目标匹配的问题,需要靠谱的数据关联(data associate)技术解决。
Apollo 中的目标融合
目标跟踪领域,一般用 Track 来代表一个被稳定跟踪的对象,
但 Track 是有生命周期状态变换的。
生命周期和状态
- initial
- tracking
- temporary lost
- destroyed

上面这张图已经跟踪清晰了,对应到代码中其实就是 3 个:
- 新建 Track
- 维护 Track
- 销毁过时 Track
讲了目标的状态后,我们需要解决一个问题:
将检测信号和正确的 Track 进行匹配。
数据关联中的关联矩阵?
在代码中如何表示新检测的目标和历史 Track 的关系呢?

比如,上图中左侧代表 Tracks,右侧代表新检测到的 Objects。
两个节点之间有连线,说明这个object 和对应的 Track 可能是同一个对象,线段上可以保存距离值,如果没有连接,距离值就为 -1。
但大家可以看到,会出现一些多对多的情况,这个时候就需要我们用一个矩阵将objects和tracks之间的距离值保存下来。
比如,上图的关系完全可以用一个 4x5 的数组来表示,我们称为关联矩阵。
5,6,-1,-1,-1;
3,-1,4,-1,-1;
1,-1,-1,-1,-1;
-1,-1,2,-1,3
然后,就需要通过数据关联的算法去寻找最佳匹配,这个过程会迭代很多次,最终迭代到最佳状态,就是我们匹配的结果。
比如这样:

上图所示,找到了一个好的匹配结果。
节点 I 是 unassign obj,需要为它单独创建新的 Track。
另外,还会出现一种情况,就是可能某些历史节点 Track,没有新的 obj 和它匹配,这个时候就需要看情况,是不是删掉这个 Track,还是继续跟踪一段时间。
Apollo 6.0 中会有这样的关联矩阵计算过程。

先不管实现代码,单单从函数参数中我们就知道,这个函数要通过 fusion tracks 和 sensor objs 计算一个距离矩阵,并且还要详细记录未匹配上的 tracks 和 objs。
因为代表很多,我们要克服好奇心,先不探索这个函数怎么实现的,我们关心它被谁调用。
其实它是 hm_tracks_objects_match.cc 内部的方法,在 Associate() 方法中被调用。

Associate() 方法的代码实在是长,我简单概括了一下,它内部调用了好几个方法。
我们很容易看到,ComputeAssociationDistanceMat() 之前有个很重要的方法 IDAssign。
并且,我们也需要知道 ComputeAssociationDistanceMat 里面的参数变量如何得到的。

IDAssign

目标融合有几种情况需要处理:
第 1 种情况,系统第 1 次融合时,FusionTracks 数量为 0.
这个时候会发生什么呢?
根据上面的代码,它会将 unassigned_measurements 的数量置为 objs 的数量.

就是一个 vector,用来保存未分配的 obj 的信息。
如果 fusion_tracks 为空,调用 std::itoa 方法给 unassigned_measurements 赋值,从 0 开始。
第2种情况,某次融合时,sensor objs 数量为 0
这和第 1 种情况相反,会将 unassigned_tracks 结果更新。
第 3 种情况,fusion_tracks,objs 数量都正常
这个时候会根据 sensor id 和时间戳去重置位置相关的信息,然后就进入到 IDAssign 方法。
当然,如果是前向毫米波雷达,代码是有区别对待的,它将不参与 ID 分配.
我们需要关注的是正常情况下,ID 是怎么分配的?这个 ID 代表什么?

在 IDAssign() 方法中,有上面这么一段。
我们需要思考 sensor_id_2_track_ind 这个 map 有什么作用,从字面意思上看应该是要标记一个 track 来自于哪个 sensor。
可事实上不是这样的,里面保存的是track_id 和 track 在 fusion_tracks 中的索引位置一一对应关系。
假设 fusion_tracks 里面有 3 个 Track。

那么,可以推出:

当然,前面还有一个细节,那就是前视摄像头的对象要区别对待。

这一段代码干嘛呢?
从 sensor_objs 中提取一个 obj 的 trackid,然后去 fusion_tracks中找相同的 trackid 的 track,如果找到了就给 sensor_used 和 fusion_used 赋值,并且将这种简单的 fusion_tracks 和 sensor_objs 的匹配关系的数组索引保存到 assignment。
然后分别检测未在 IDAssign 阶段得到 trackid 匹配的 fusion_tracks 和 sensor_objects 保存到 unassigned_fusion_tracks 和 unassigned_sensor_objects 中。
其实 IDAssign 的目的很简单,无非就是从 sensor objs 中去查找已经存在于 fusion tracks 中的 track。
绕回ComputeAssociationDistanceMat

了解了 IDAssign 做了什么之后,再看 ComputeAssociationDistanceMat 就会比较容易了。

association_mat 是针对 trackid 未匹配上的 track 和 sensor objs 的二维矩阵,这样避免了已经匹配上的 track 进行重复计算。
在这里默认距离是 s_match_distance_thresh_。
要计算的是两者中心位置的欧式距离。
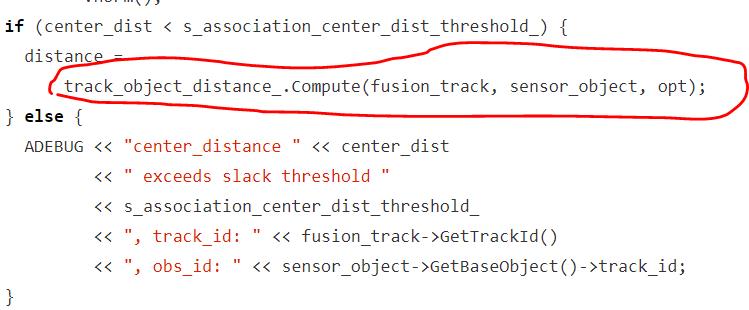
如果 center_dist 小于 s_association_center_dist_threshold_,
那么将调用 track_object_distance_.Compute() 做精细化计算。

代码注释中讲到,因为 2D 到 3D 转换误差太大,所以数据关联的时候,阈值设置的很宽松,在这里是 30m,为了防止 camera 检测到的目标和 Lidar 的目标匹配不上。
这一行解释其实也透露出了在实际数据关联时常见的无奈。
重头戏在这里。
这个函数的逻辑很复杂,值得独立一小节来介绍它。
TrackObjectDistance.compute()
之前说过 Apollo 6.0 感知融合的传感器有 Lidar、Radar、Camera。
所以,在某个时刻一个 Track 其实有对应 LidarObject、RadarObject、CameraObject。
而做数据关联的时候,需要计算 sensor obj 和 track 中的哪个 object 距离最近。

这个是一一比较的过程。
我们先看 computeLidarLidar 的实现。
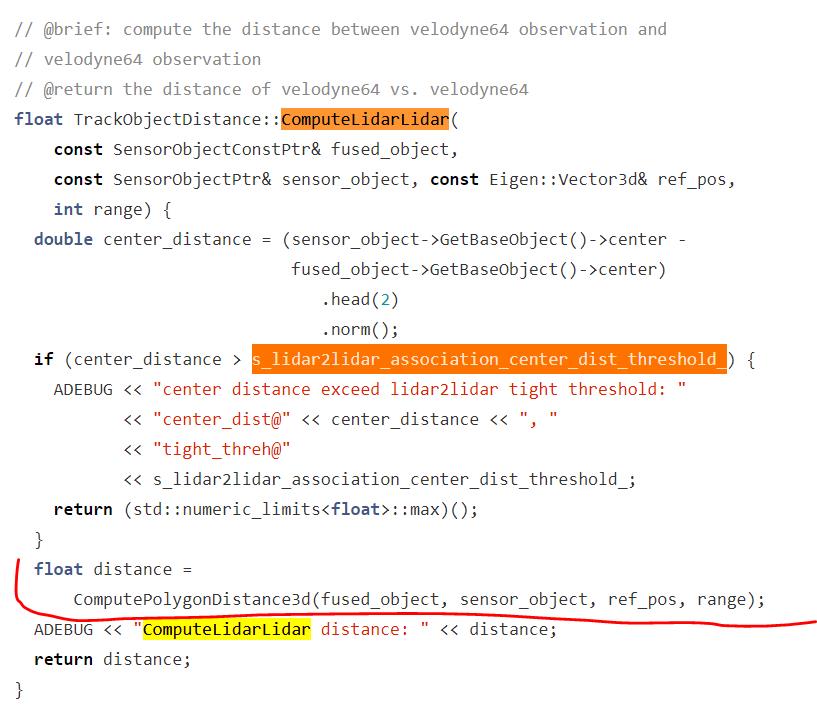

如果两个 Lidar 对象的中心距离大于 10 米,那么它们的距离就被重置为 max,也就是一个最大数,表示不是一个对象。
如果在 10 米范围内,那就调用 ComputePolygonDistance3d()方法。

求 track 和 sensor 之间的距离时,并不是直接求距离。
需要计算 track 在 sensor obj 同样时间戳下的距离,有一个航迹推断的过程,上图红线圈了出来。
其实也就是我在文章前面部分讲到的
measure() 前要经过 predict()
比如 track 是在 0 s 时的位置为 p0,sensor obj 有数据参与融合时是在 1.5s,那么这个时候 track 的位置为p1= p0 + track 的速度乘以 1.5s,才是当前 track 的位置,而与 sensor obj 进行距离计算是 p1 不是 p0。
ComputeLidarRadar 和 ComputeLidarLidar 逻辑是一样的,ComputeLidarCamera 逻辑有点不同。
ComputeLidarCamera
这个方法初看不起眼,没想到跟踪代码时简直让我感受到陷入泥坑当中,代码量太多了。
这个方法是计算 Lidar 目标和 Camera 目标的距离。

首先是判断 lidar 检测到的 object 和 camera 检测到的 object id 是不是一致。
如果不一致的话,需要判断两者的距离是不是超过了一个动态的距离阈值。
调用的是 LidarCameraCenterDistanceExceedDynamicThreshold 方法。
判断的依据是两个obj的中心点的差值,是否大于 5 + 0.15 * local_distance,默认情况下 local_distance 为 60,如果存在点云数据则取最近的点云距离,总体阈值应该是 9 米的样子。
如果超过了,直接返回 distance_thresh_ 
计算 Lidar 和 Camera object 的 distance 有两种情况。
一种是当前有点云数据,另外一种是无点云数据。
有点云数据的情况需要计算一个相似度,这个相似度取值范围是 0 ~ 1,1 代表完全一致,0 代表不一致。
相似度怎么计算呢?
- 计算点云数据和camera数据的距离相似度和形状相似度;
- 融合距离相似度和形状相似度。
ComputePtsBoxSimilarity。

求距离的相似度时,基本思路是算一个点云到 camera bbox 的平均距离,然后再以 box 的尺寸进行归一化操作。

在这里假设 mean_pixel_dist 是服从高斯分布,然后计算卡方分布。
这里运用了统计学中的卡方检验工具。
卡方检验是要假设 H0 和 H1 的。
在这里 H0 假设应该是:Lidar 和 camera 是一致的。
然后通过计算两者在 x,y 维度的卡方值,来验证假设。
ChiSquaredCdf2TableFun 求的是累积的概率。

这个是需要查询卡方分布表的。

提前将卡方值和对应的 p 值存储起来,dist_int 代表的是卡方分布表中的卡方值,在上面这个 table 中通过 dist_int 能够查找到对应的 p 值。
原始的卡方检验中,卡方值越大,p 值越小,如果 p 值小于显著性水平比如 0.05,那么原假设就可以算不成立。
但我观察 Apllo 上方的分布表,dist_int 越小,p 值也越小。那么这个 p 代表什么呢?
代表 H0 假设不成立的概率?
而后面相似度的计算是
double location_similarity =
1 - ChiSquaredCdf2TableFun(square_norm_mean_pixel_dist);
需要 1 减去这个概率,得到 H0 假设成立的概率,似乎也符合我的推断,但说实话,我这边还没有怎么整明白,只是根据代码去推断它的算法思想,在这一块比较了解的同学可以留言交流。
上面计算的是距离相似度,还有个形状相似度,最终两个相似度要进行融合,产生一个新的相似度。

注释写的很明白,输入的概率值如果 sum 大于 1,那么最终的结果会大于 0.5,反之小于 0.5.
有了相似度后,终于可以得到最终的 distance 了。

相似度越高,distance 越小。
以上就是 Lidar 和 Camera 目标间的距离计算。
ComputeRadarCamera
计算 Radar 和 Camera 之间的距离和 LidarCamera 类似,但又有一些不同。
Radar 返回来的是一个点,需要通过一个点生成 8 个顶点,其实就是一个长方体的 8 个顶点。

代码很容易编写。

需要注意到的细节是,因为 Radar 探测到的目标是有方向信息的,所以生成长方体的时候要考虑到 xy 平面的旋转。
radar 的中心点需要投影到相机坐标系,形成 local_pt。
最终通过求 X、Y、Loc、Velocity 的相似度,得到最终融合后的相似度 fused_similarity。
通过 fused_similarity 求得最终的 distance,这个和之前的 LidarCamera 基本思路一致。

X 相似度主要通过一个 WelshVarLossFunc 确定的。

说实话,我不大懂它的用意,但看代码可以粗略估计到,如果 dist 非常小,小于阈值,那么说明两者相似度非常高,给一个权重值。
如果 dist 很大,那么就需要缩放,将 p 最终的结果限制在(0,1] 区间。
我比较关心的是 Radar 的速度和 Camera 的速度如何求相似度。

ComputeCameraCamera

这里直接返回最大的数了,意思肯定就是计算 Ojbect 和 track 的时候优先考虑 Liar、Radar 与 Camera 的距离关系。
MinimizeAssignment
计算了 Object 和 track 之间的距离后,用矩阵保存下来。
然后就需要执行匈牙利匹配算法了。

optimizer 声明如下:

就把它当成一个黑盒子吧,下一篇文章讲解 Apollo 6.0 中的匈牙利算法实现。
所以,MinimizeAssignment 进行了实际的目标匹配。
postIdAssign
数据关联之后,还需要进行一些后处理。
主要是要提取一些有效的 track.

如果一个 track 没有匹配上,但它只有上一次的 camera 数据,没有 lidar 数据,那么还是认为它有效。
ComputeDistance
数据关联的最后,需要计算距离,距离指得是一个距离分数。
总结
数据关联还挺难的,代码很多,很多细节都还来不及展开。
总之,要做好数据融合要注意下面几个点:
- 目标的生命周期管理
- 目标的 ID 匹配
- ID 匹配需要注意计算 Object 和 Measurement 的距离
- 距离不等同于欧式距离,它是为了计算相似度,相似度越大,距离越小。
- 匈牙利算法比较复杂,但好在有成熟的现成的代码可以实现。
- 数据关联之后,还需要进行一些后期处理。
- 数据关联做好之后,后面的卡尔曼滤波算法才能正确的运行起来。
以上是关于自动驾驶 Apollo 源码分析系列,感知篇:感知融合中的数据关联细节的主要内容,如果未能解决你的问题,请参考以下文章
自动驾驶 Apollo 源码分析系列,感知篇:感知融合代码的基本流程
自动驾驶 Apollo 源码分析系列,感知篇:感知融合代码的基本流程
自动驾驶 Apollo 源码分析系列,感知篇:Perception 如何启动?
自动驾驶 Apollo 源码分析系列,感知篇:车道线检测基本流程