数据处理可视化
Posted 不想写bug第n天
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据处理可视化相关的知识,希望对你有一定的参考价值。
目录
1.采集数据: 【yarn api 采集yarn信息 : 】
2.对应添加各种包 编辑编辑 ContextUtils.scala
-
项目思路
-
项目流程:
-
1.数据采集:采集yarn指标数据 =》 yarn api => 用户自己开发代码 jar
-
2.数据处理:实时处理 =》sparkstreaming
-
3.数据输出:mysql、olap =》 clickhouse
-
4.数据可视化:superset、dataease
olap vs oltp 毫秒级别
olap:clickhouse、doris、tidb、phoenix
oltp:事务 mysql、
-
-
链路:
yarn:
app.jar [采集yarn数据] =》 kafka =》sparkstreaming =》 clickhouse =》superset -
数据格式:
-
1.一行一行发送数据: 文本数据【分割符即可】
1 2 3 4 5 空格
1,2,3,4,5 , -
2.json数据
"applicationid":1,"meme":4G,“name”:"xxx asd x"
性能问题:
json 占用io 、好处:解析方便
-
-
1.采集数据: 【yarn api 采集yarn信息 : 】
-
1.采集yarn 作业运行状态:
-
1.ACCEPTED
-
2.RUNNING
-
-
2.yarn api如何使用?
-
1.YarnClient
-
2.YarnApplicationState
-
3.ApplicationReport:
包含yarn上每个作业的详细信息:
程序id、执行引擎、开始时间、结束时间、mem、cpu、队列、名字
-
流程
-
1.创建idea
-
0.选择

-
1.添加依赖
<!--添加yarn依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-common</artifactId> <version>3.3.4</version> </dependency>版本:2.12.14

-
-
2.添加resources
-
1.添加yarn-site.xml
-
下载路径:/home/hadoop/app/hadoop/etc/hadoop
-
-
-
3.启动spark-sql
-
spark-shell --master yarn --jars /home/hadoop/software mysql-connector-java-5.1.28.jar --driver-class-path /home/hadoop/software mysql-connector-java-5.1.28.jar --name spark-sql
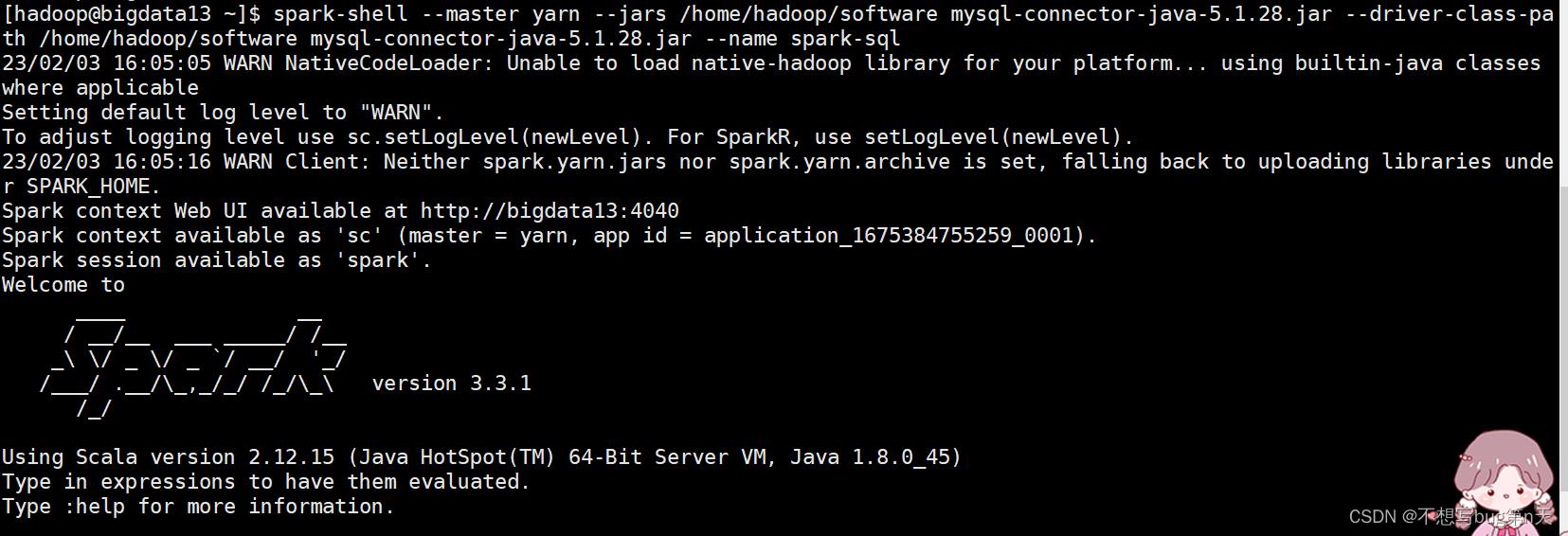
-
//启动第二个(暂时不用)
spark-shell --master yarn --jars /home/hadoop/software mysql-connector-java-5.1.28.jar --driver-class-path /home/hadoop/software mysql-connector-java-5.1.28.jar --name spark-sql01 -
查看bigdata:8088
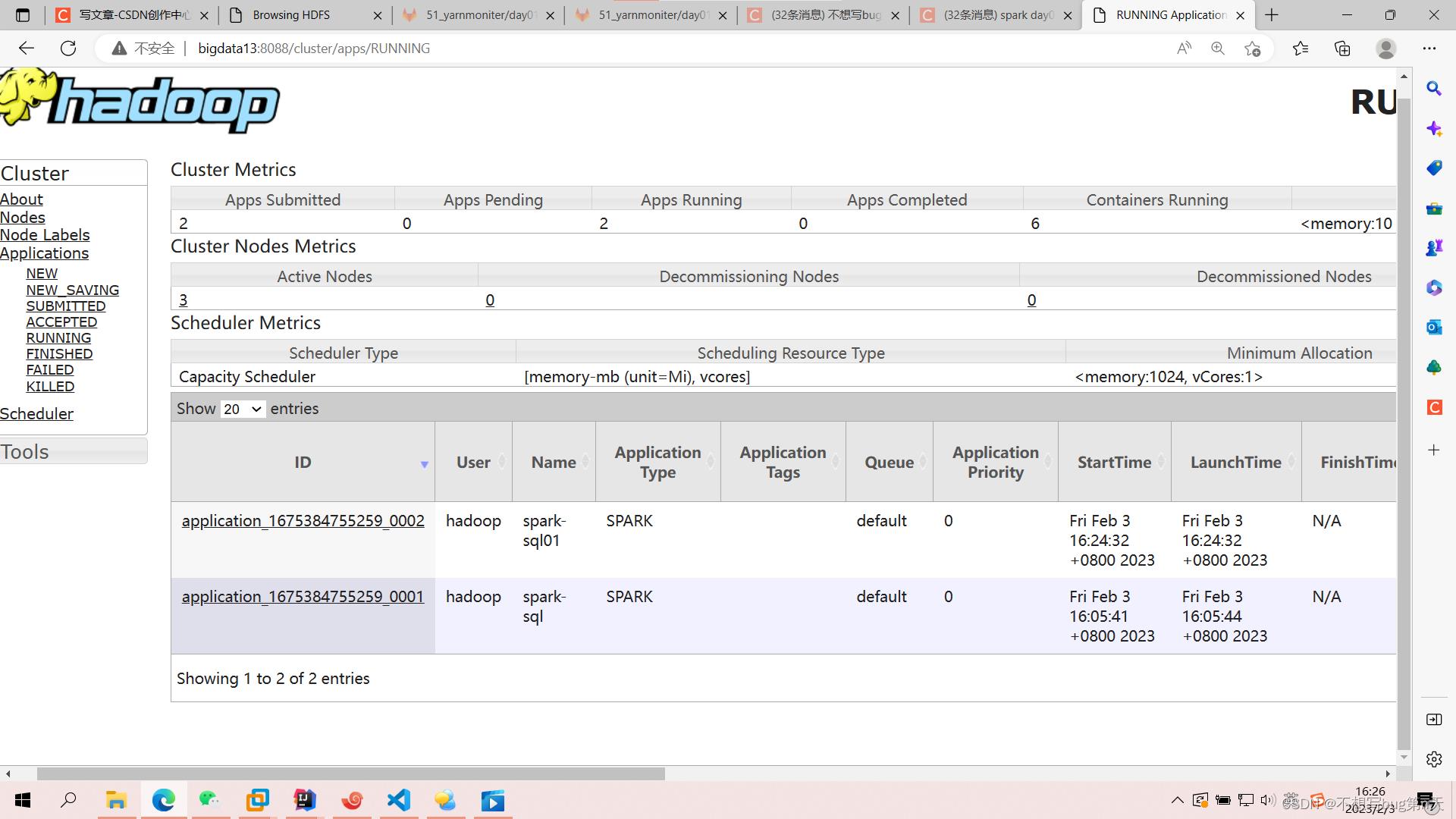
-
-
4.代码
-
YarnInfo 【接口】
package com.bigdata.task import java.util import java.util.Date import org.apache.commons.lang3.time.FastDateFormat import org.apache.hadoop.yarn.api.records.YarnApplicationState import org.apache.hadoop.yarn.client.api.YarnClient import org.apache.hadoop.yarn.conf.YarnConfiguration trait YarnInfo //获取yarn作业的信息 def getYarnInfo = /** * 1.YarnClient * 2.YarnApplicationState * 3.ApplicationReport: */ val yarnClient = YarnClient.createYarnClient() /** * 启动客户端 */ val YarnConfiguration = new YarnConfiguration() yarnClient.init(YarnConfiguration) //初始化 yarnClient.start() //获取作业信息 val appStates = util.EnumSet.noneOf(classOf[YarnApplicationState]) appStates.add(YarnApplicationState.ACCEPTED) appStates.add(YarnApplicationState.RUNNING) val applicationReports = yarnClient.getApplications(appStates).iterator() val data = StringBuilder.newBuilder //拼接 //遍历 while (applicationReports.hasNext) val applicationReport = applicationReports.next() val applicationId = applicationReport.getApplicationId //程序id val applicationType = applicationReport.getApplicationType //执行引擎 val user = applicationReport.getUser val startTime = applicationReport.getStartTime val finishTime = applicationReport.getFinishTime val memorySize = applicationReport.getApplicationResourceUsageReport.getUsedResources.getMemorySize //内存信息 val virtualCores = applicationReport.getApplicationResourceUsageReport.getUsedResources.getVirtualCores //cpu信息 val containers = applicationReport.getApplicationResourceUsageReport.getNumUsedContainers //最终申请资源 val state = applicationReport.getYarnApplicationState val url = applicationReport.getTrackingUrl val name = applicationReport.getName val queue = applicationReport.getQueue val todayTime = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss").format(new Date().getTime) data.append(applicationId).append("&&") .append(name).append("&&") .append(applicationType).append("&&") .append(user).append("&&") .append(startTime).append("&&") .append(finishTime).append("&&") .append(memorySize).append("&&") .append(virtualCores).append("&&") .append(containers).append("&&") .append(state).append("&&") .append(queue).append("&&") .append(todayTime).append("&&") .append(url).append("\\r\\n") data.toString() //println(data.toString()) -
YarnLogTask
package com.bigdata.task object YarnLogTask extends YarnInfo def main(args: Array[String]): Unit = getYarnInfo运行结果

当启动两个spark-sql时

//后添加的时间截图
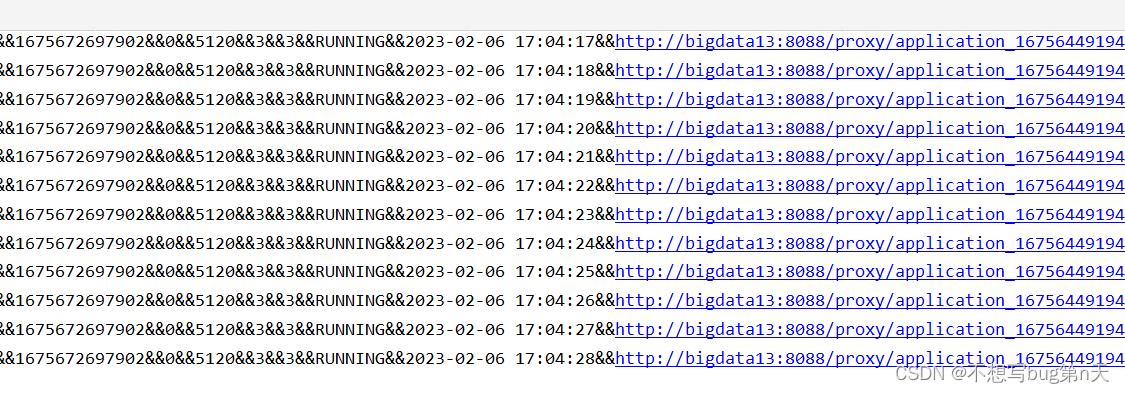
-
-
5.数据发送到kafka
-
1.启动zookeeper
-
路径:/home/hadoop/shell
-
[hadoop@bigdata13 shell]$ zkServer.sh start
-
-
2.启动kafka
-
路径:/home/hadoop/app/kafka/bin
-
[hadoop@bigdata13 bin]$
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties -
1.查看当前topic
kafka-topics.sh \\ --list \\ --zookeeper bigdata13:2181,bigdata14:2181,bigdata15:2181/kafka -
2.创建一个topic
kafka-topics.sh \\ --create \\ --zookeeper bigdata13:2181,bigdata14:2181,bigdata15:2181/kafka \\ --topic yarn-info \\ --partitions 3 \\ --replication-factor 1 -
3.控制台监控
kafka-console-consumer.sh \\ --bootstrap-server bigdata13:9092,bigdata14:9092,bigdata15:9092 \\ --topic yarn-info
-
-
3.代码 YarnLogTask
package com.bigdata.task import java.util.Properties import org.apache.kafka.clients.producer.KafkaProducer, ProducerRecord import scala.util.Random object YarnLogTask extends YarnInfo def main(args: Array[String]): Unit = /** * 采集yarn log 数据 sink kafka : * 1.producer * 2.发送数据 : * 1.采集 * 2.发送 */ val props = new Properties() props.put("bootstrap.servers", "bigdata13:9092,bigdata14:9092,bigdata15:9092") props.put("acks", "all") props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer") props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer") val producer = new KafkaProducer[String,String](props) val topic="kafka-console-consumer.sh \\\\\\n--bootstrap-server bigdata13:9092,bigdata14:9092,bigdata15:9092 \\\\\\n--topic yarn-info" while (true) val data = getYarnInfo Thread.sleep(1000) val applicationinfos = data.split("\\r\\n") for(applicationinfo <- applicationinfos) val partitionId = new Random().nextInt(10)%3 println(applicationinfo) producer.send(new ProducerRecord[String,String](topic,partitionId,"",applicationinfo))开始打印

控制台监控
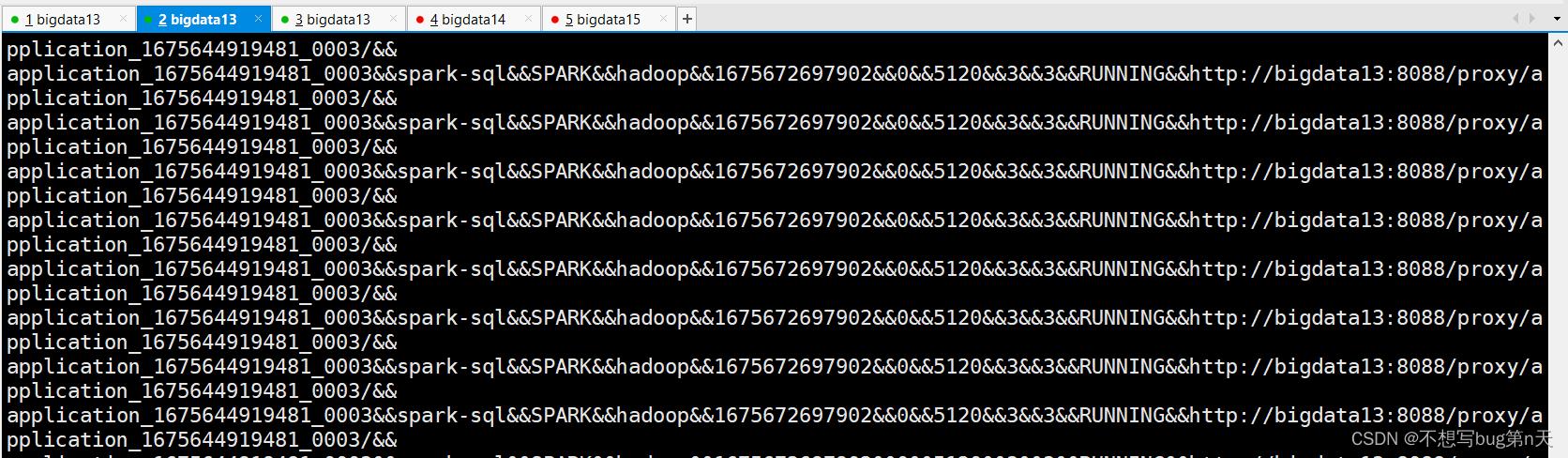
-
2.实时数据处理
重新开一个项目(用原来的也可以)
-
代码流程
-
1.添加依赖
<!--hadoop依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.4</version> </dependency> <!--添加spark-core依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.2.1</version> </dependency> <!--sparksql依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.2.1</version> </dependency> <!--spark-hive依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>3.2.1</version> </dependency> <!--添加mysql驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.49</version> </dependency> <!--sparkstreaming 依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>3.2.1</version> </dependency> <!--spark整合为kafka依赖 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.12</artifactId> <version>3.2.1</version> </dependency> -
2.对应添加各种包
ContextUtils.scalapackage com.bigdata.util import org.apache.spark.sql.SparkSession import org.apache.spark.streaming.Seconds, StreamingContext import org.apache.spark.SparkConf, SparkContext object ContextUtils /** * 获取sc * @param appName * @param master * @return */ def getSparkContext(appName:String,master:String="local[2]")= val conf: SparkConf = new SparkConf() // .setAppName(appName).setMaster(master) // conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer") // conf.registerKryoClasses(Array(classOf[Info])) new SparkContext(conf) /** * 获取 sparksession * @param appName * @param master */ def getSparkSession(appName:String,master:String="local[2]")= SparkSession.builder() .appName(appName).master(master) .config("hive.exec.dynamic.partition.mode","nonstrict") .enableHiveSupport().getOrCreate() def getStreamingContext(appName:String,batch:Int,master:String="local[2]") = val conf = new SparkConf().setMaster(master).setAppName(appName) new StreamingContext(conf,Seconds(batch)) -
3.App初步代码
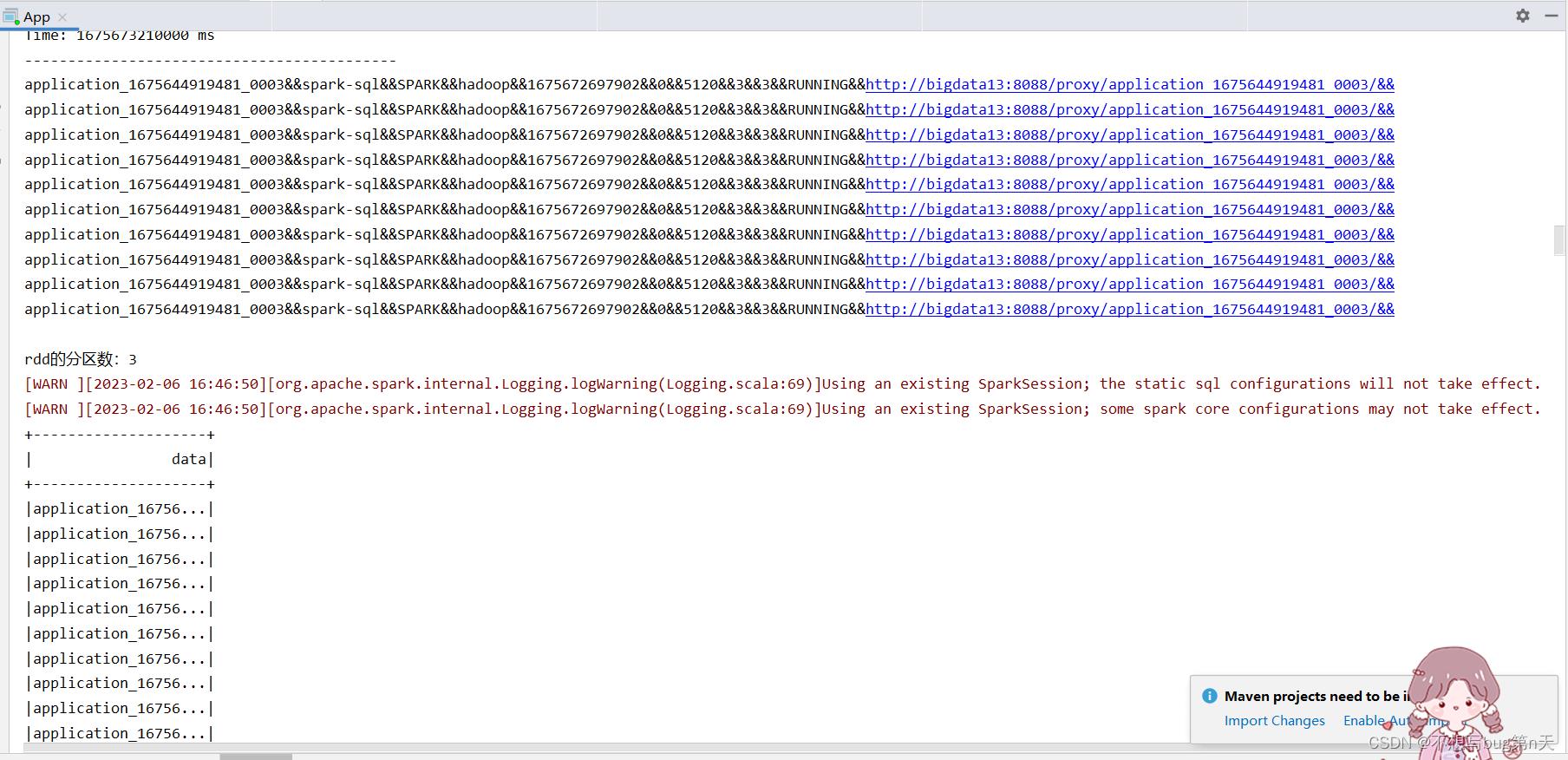
package com.bigdata import com.bigdata.util.ContextUtils import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.rdd import org.apache.spark.sql.SaveMode, SparkSession import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import org.apache.spark.streaming.kafka010.CanCommitOffsets, HasOffsetRanges, KafkaUtils import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent object App def main(args: Array[String]): Unit = val ssc = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10) val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "bigdata13:9092,bigdata14:9092,bigdata15:9092", // kafka地址 "key.deserializer" -> classOf[StringDeserializer], // 反序列化 "value.deserializer" -> classOf[StringDeserializer],//反序列化 "group.id" -> "yarn01", // 指定一个 消费者组 "auto.offset.reset" -> "latest", // 从那个地方 开始消费数据 偏移量 "enable.auto.commit" -> (false: java.lang.Boolean) // offset 提交 选择 不自动提交 手动管理的 ) val topics = Array("yarn-info") val stream = KafkaUtils.createDirectStream[String, String]( ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams) ) stream.map(_.value()).print() stream.foreachRDD(rdd => /** * 获取offset * 业务逻辑 no * sink: clickhouse * sparksql jdbc api * jdbc代码 =》了解 * 提交offset */ println(s"rdd的分区数:$rdd.partitions.size") val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges /** * 业务逻辑处理: * sparksql */ val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate() import spark.implicits._ val df = rdd.map(_.value()).toDF("data") df.show() // 提交offset stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) ) ssc.start() ssc.awaitTermination()单独运行结果

和yarn-log中YarnLogTask共同运行结果
-
4.
保证代码健壮性package com.bigdata import java.util.Properties import com.bigdata.util.ContextUtils import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.rdd import org.apache.spark.sql.SaveMode, SparkSession import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import org.apache.spark.streaming.kafka010.CanCommitOffsets, HasOffsetRanges, KafkaUtils import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent object App def main(args: Array[String]): Unit = val ssc = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10) val url = "jdbc:clickhouse://bigdata15:8123/bigdata" val table = "yarn_info02" val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "bigdata13:9092,bigdata14:9092,bigdata15:9092", // kafka地址 "key.deserializer" -> classOf[StringDeserializer], // 反序列化 "value.deserializer" -> classOf[StringDeserializer],//反序列化 "group.id" -> "yarn02", // 指定一个 消费者组 "auto.offset.reset" -> "latest", // 从那个地方 开始消费数据 偏移量 "enable.auto.commit" -> (false: java.lang.Boolean) // offset 提交 选择 不自动提交 手动管理的 ) val topics = Array("yarn-info02") val stream = KafkaUtils.createDirectStream[String, String]( ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams) ) stream.map(_.value()).print() stream.foreachRDD(rdd => /** * 获取offset * 业务逻辑 no * sink: clickhouse * sparksql jdbc api * jdbc代码 =》了解 * 提交offset */ println(s"rdd的分区数:$rdd.partitions.size") val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges /** * 业务逻辑处理: * sparksql */ val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate() import spark.implicits._ //保证代码健壮性 val df = rdd.map(_.value()).filter(_.nonEmpty) .map(line => val columns = line.split("&&") //反射方式来做 java scala // 反射:array =》case class (columns(0), columns(1), columns(2), columns(3), columns(4), columns(5), columns(6), columns(7), columns(8), columns(9), columns(10), columns(11), columns(12)) ).toDF("applicationid" ,"name" ,"applicationtype" ,"user" ,"starttime" ,"finishtime" ,"memorysize" ,"virtualcores" ,"containers" ,"state" ,"queue" ,"todaytime" ,"url") df.show() df.printSchema() val properties = new Properties() properties.setProperty("user", "default") df.write.mode(SaveMode.Append) .option("driver","ru.yandex.clickhouse.ClickHouseDriver") .jdbc(url,table,properties) // 提交offset stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) ) ssc.start() ssc.awaitTermination()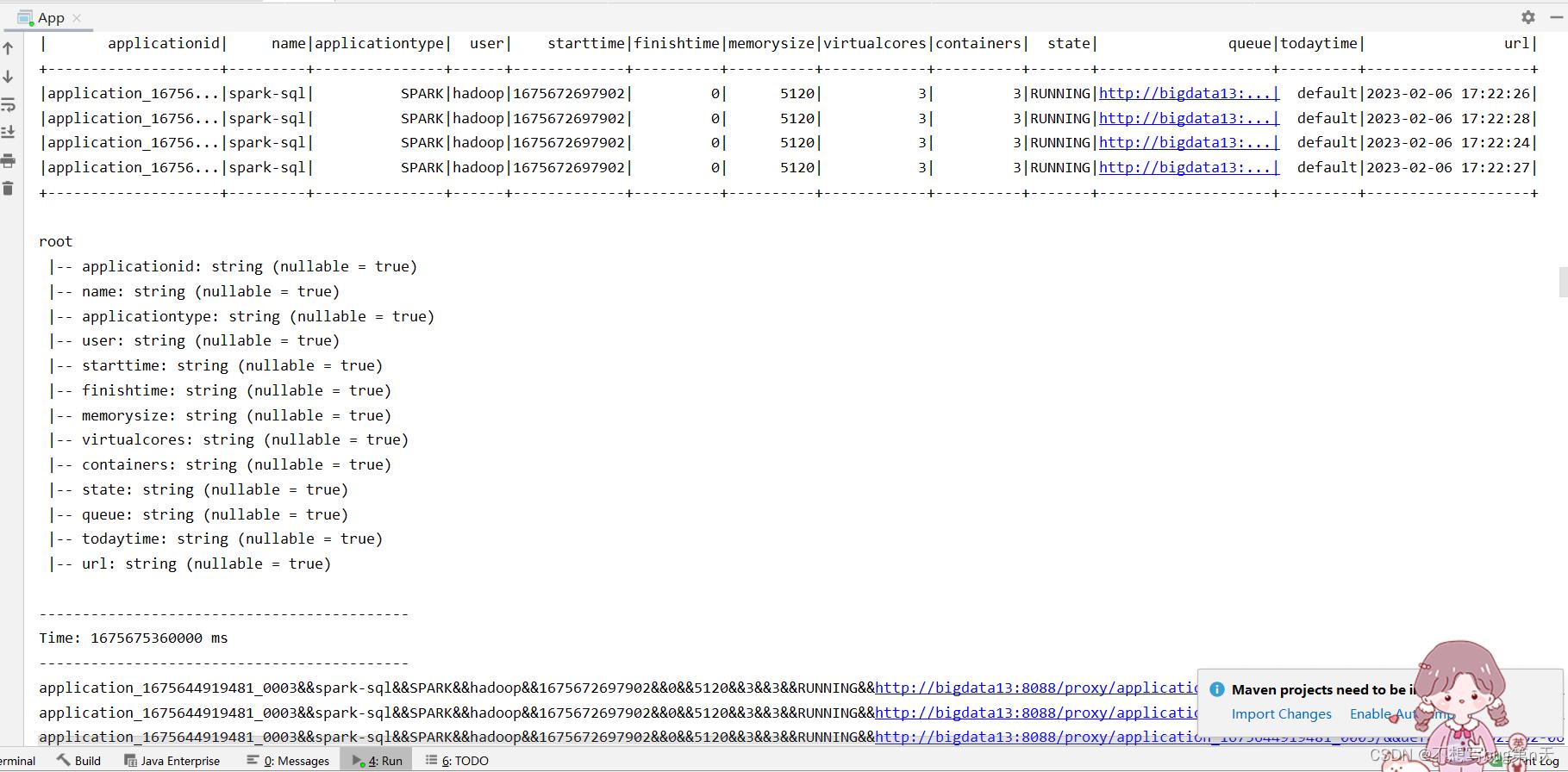
-
clickhouse
-
1.安装部署
- 1.官网:https://clickhouse.com/docs/en/install/#from-rpm-packages
- 2.选择了rpm方式下载
- 下载到bigdata15的home目录下
sudo yum install -y yum-utils sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo sudo yum install -y clickhouse-server clickhouse-client sudo /etc/init.d/clickhouse-server start clickhouse-client # or "clickhouse-client --password" if you set up a password.
登录命令:clickhouse-client
重启命令:
clickhouse stop
clickhouse start
- 下载到bigdata15的home目录下
-
2.使用
- 1.创建数据库: create database bigdata;
- 2.切换数据库: use bigdata
- 3.创建表
CREATE TABLE bigdata.user_info ( id String , name String, age String, dt String ) ENGINE = MergeTree() PARTITION BY dt PRIMARY KEY (dt,id,name,age) ORDER BY (dt,id,name,age) SETTINGS index_granularity = 8192 - 4.插入表
insert into bigdata.user_info values('1','zhangsan','30','20230206'),('2','lisi','30','20230206');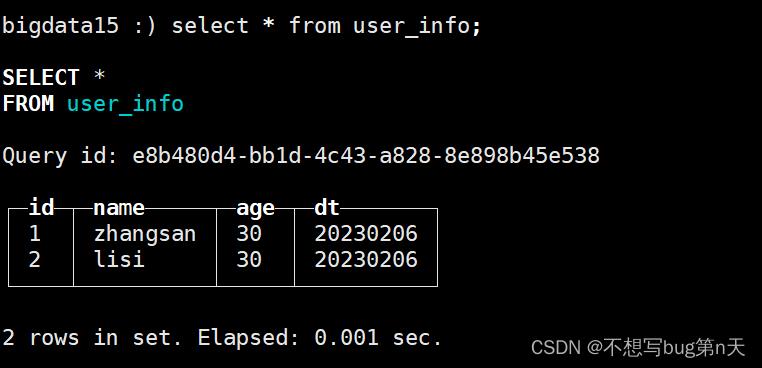
-
3.dbeaver 进行远程连接
-
方法一【不使用】
- 创建新连接(未开启权限)
① ssh
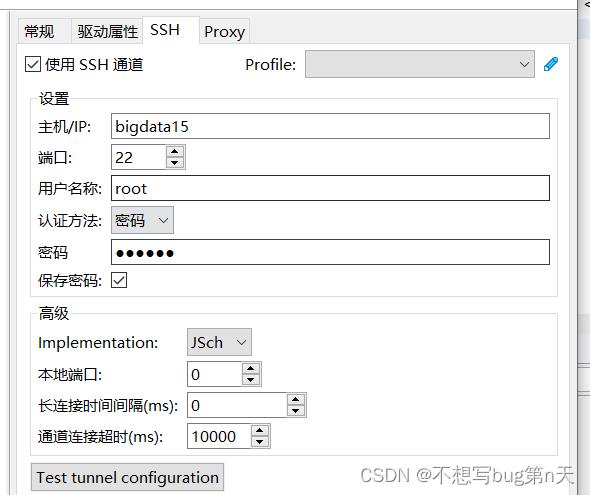
②常规

- 查看8123端口号:[root@bigdata15 ~]# netstat -nlp | grep 8123

未被其他占用 - 查看

- 查看8123端口号:[root@bigdata15 ~]# netstat -nlp | grep 8123
-
方法二【使用】
- 修改配置文件
- 进入配置温江:vim /etc/clickhouse-server/config.xml
- 尾行模式查找:/listen

- 插入
<listen_host>::</listen_host> - 重启clickhouse
- 直接创建连接

-
-
4.idea中使用
- 1.添加clickhouse依赖
spark运行过程中需要 xml依赖<!--添加clickhouse驱动--> <dependency> <groupId>ru.yandex.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <version>0.2.4</version> </dependency> <!--添加 xml问题的依赖--> <dependency> <groupId>com.fasterxml.jackson.module</groupId> <artifactId>jackson-module-scala_2.12</artifactId> <version>2.12.4</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.module</groupId> <artifactId>jackson-module-jaxb-annotations</artifactId> <version>2.12.4</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.12.4</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-annotations</artifactId> <version>2.12.4</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>2.12.4</version> </dependency> - 2.添加代码
val url = "jdbc:clickhouse://bigdata15:8123/bigdata" val table = "yarn_info" val properties = new Properties() properties.setProperty("user", "default") df.write.mode(SaveMode.Append) .option("driver","ru.yandex.clickhouse.ClickHouseDriver") .jdbc(url,table,properties) - 3.创建表
CREATE TABLE bigdata.yarn_info ( applicationid String, name String, applicationtype String, user String, starttime String, finishtime String, memorysize String, virtualcores String, containers String, state String, queue String, todaytime String, url String ) ENGINE = MergeTree() PARTITION BY queue PRIMARY KEY (applicationid,name,applicationtype,user,starttime,finishtime,memorysize,virtualcores,containers,state,queue,todaytime,url) ORDER BY (applicationid,name,applicationtype,user,starttime,finishtime,memorysize,virtualcores,containers,state,queue,todaytime,url) SETTINGS index_granularity = 8192
运行结果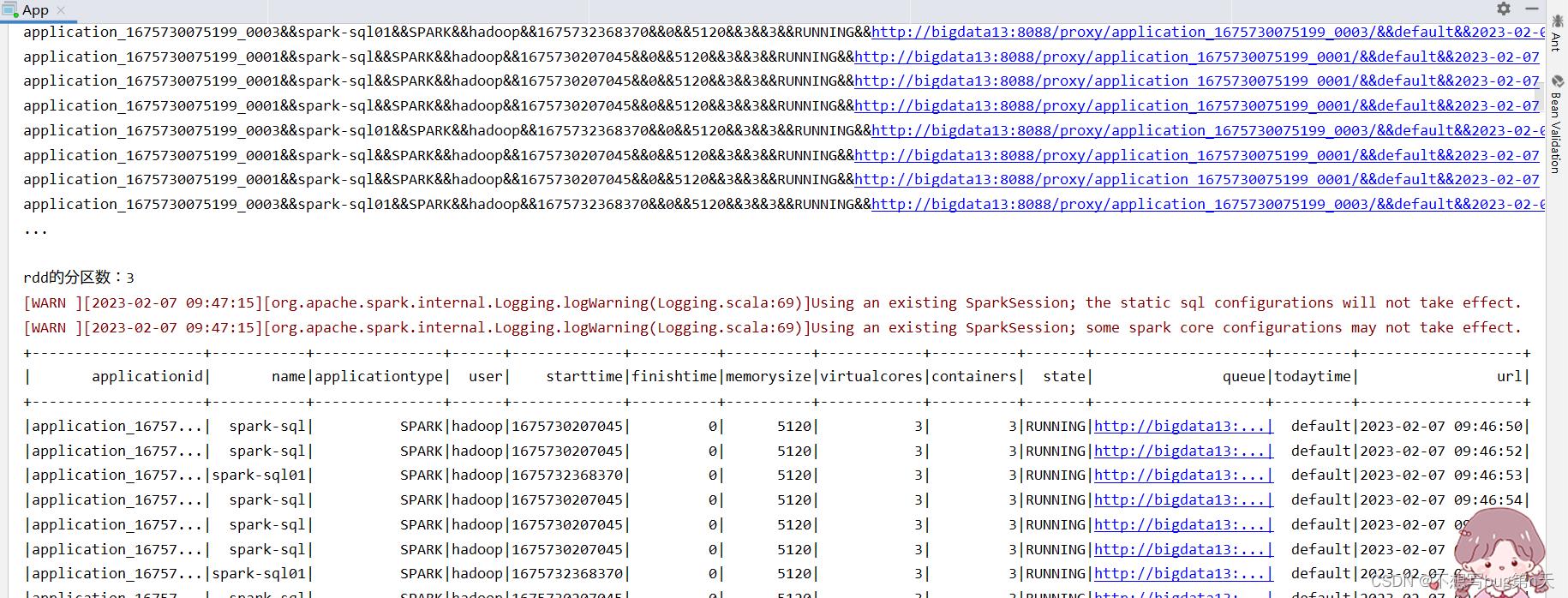

- 1.添加clickhouse依赖
-
3.数据可视化
-
1.原生方式
-
1.superset启动
- 1.[root@bigdata15 hadoop]# cd /usr/local/src
- 2.[root@bigdata15 src]# source superset-py3/bin/activate #激活superset的venv
- 3.(superset-py3) [root@bigdata15 src]# superset run -h bigdata15 -p 8889
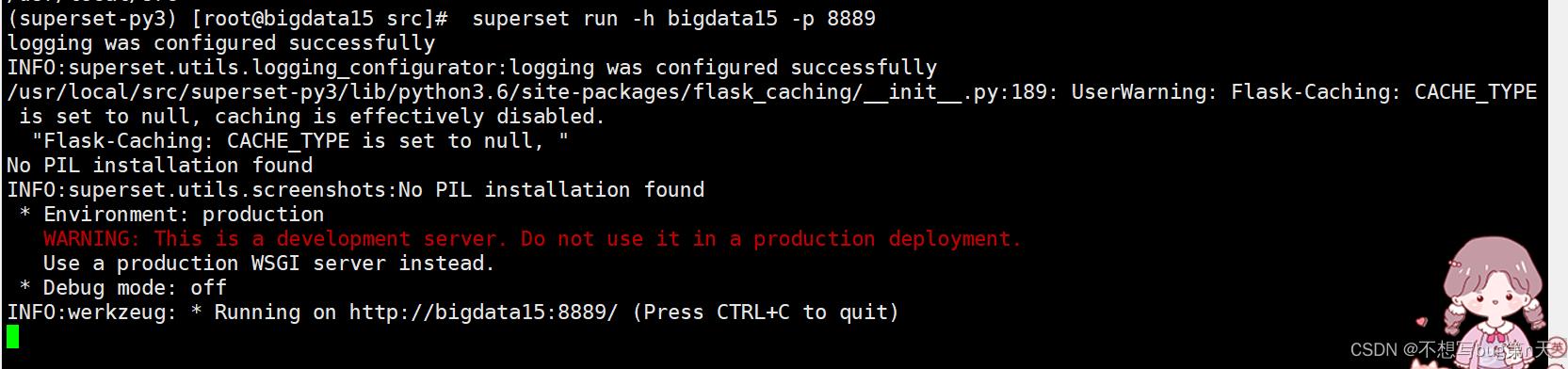
- 4.进入http://bigdata15:8889/
用户:admin
密码:admin

-
2.superset连接clickhouse
- 1.先关闭superset,再安装clickhouse驱动
pip3 install sqlalchemy-clickhouse -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com - 2.启动superset:
(superset-py3) [root@bigdata15 src]# superset run -h bigdata15 -p 8889 - 3.在clickhouse中创建用户
- 修改clickhouse中users权限
- [root@bigdata15 clickhouse-client]# vim /etc/clickhouse-server/users.xml
- 取消注释:<access_management>1</access_management>
- 进入clickhouse创建用户
bigdata15 :) create user root identified by '123456'; - 赋予用户权限:
bigdata15 :) GRANT ALTER on *.* TO root;
- 修改clickhouse中users权限
- 4.在superset网页中添加新的Database


clickhouse://root:123456@bigdata15/bigdata - 5.测试连接
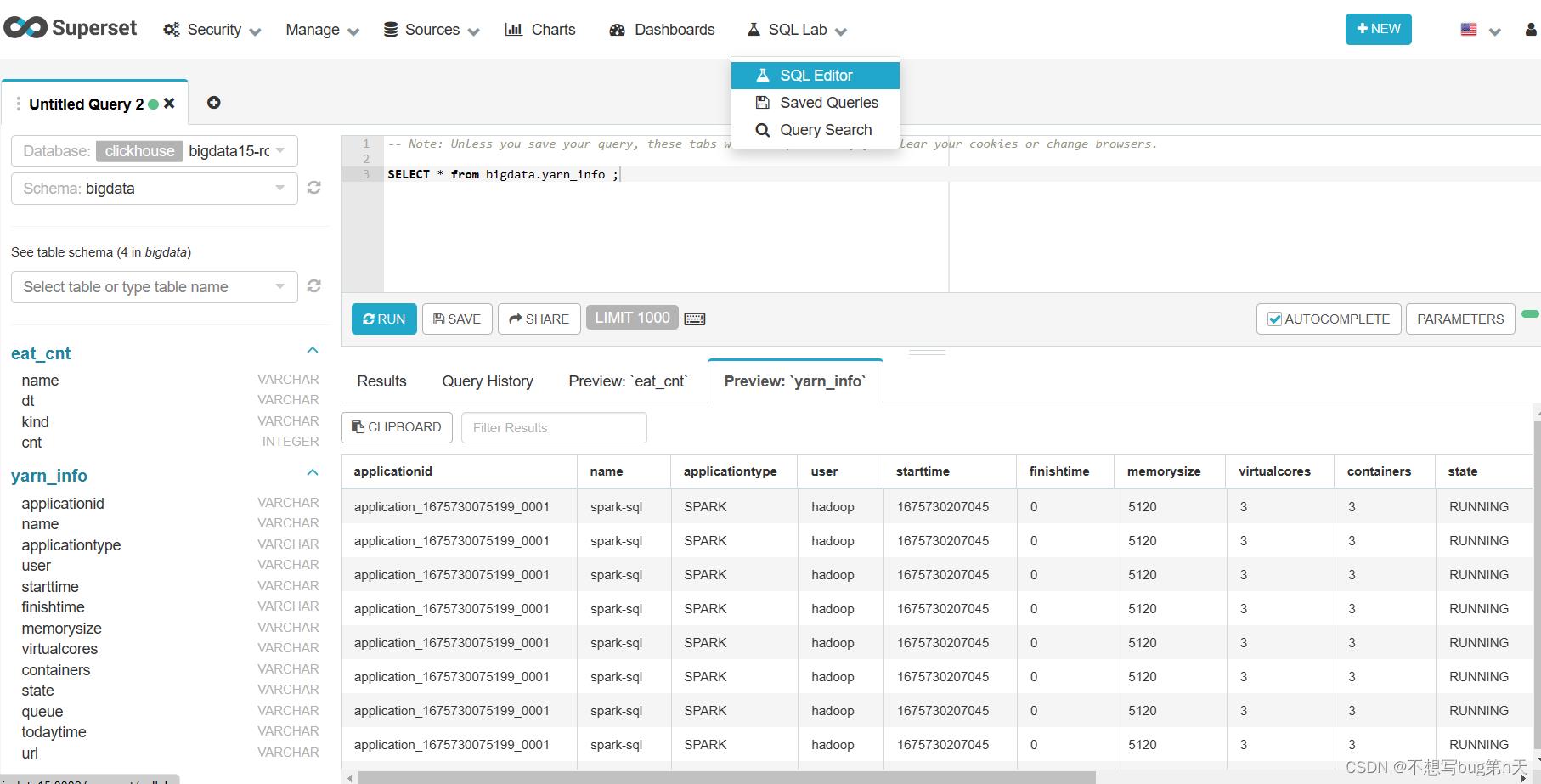
- 1.先关闭superset,再安装clickhouse驱动
-
2.doctor方式部署
- 视频:E:\\视频\\yarnmonitor\\day02\\14
4.制作可视化
- 要求
-
1.yarn正在运行作业的明细表
-
2.yarn正在运行作业内存使用情况
-
3.yarn正在运行作业任务数
-
4.yarn正在申请作业任务数
-
5.yarn正在运行作业内存使用top10、运行时长top10
-
过程
由于前面的一些错误,在此重新建表yarn-info02 【yarn-info = yarn-info02】
-
1.yarn正在运行作业的明细表
-
1.sql查询语句
select applicationid, name, applicationtype, user, toDateTime(intDivOrZero(toInt64OrZero(starttime),1000)) as s_time, dateDiff('minute', toDateTime(intDivOrZero(toInt64OrZero(starttime),1000)),toDateTime(todaytime) ) as diff, intDivOrZero(toInt64OrZero(memorysize),1024) as user_mem, virtualcores, containers, state, queue, todaytime, url from bigdata.yarn_info02 where state='RUNNING' and todaytime =( select max(todaytime) as t from bigdata.yarn_info02 where formatDateTime(toDateTime(todaytime),'%Y-%m-%d')=formatDateTime(now(),'%Y-%m-%d') )-
在dbeaver测试
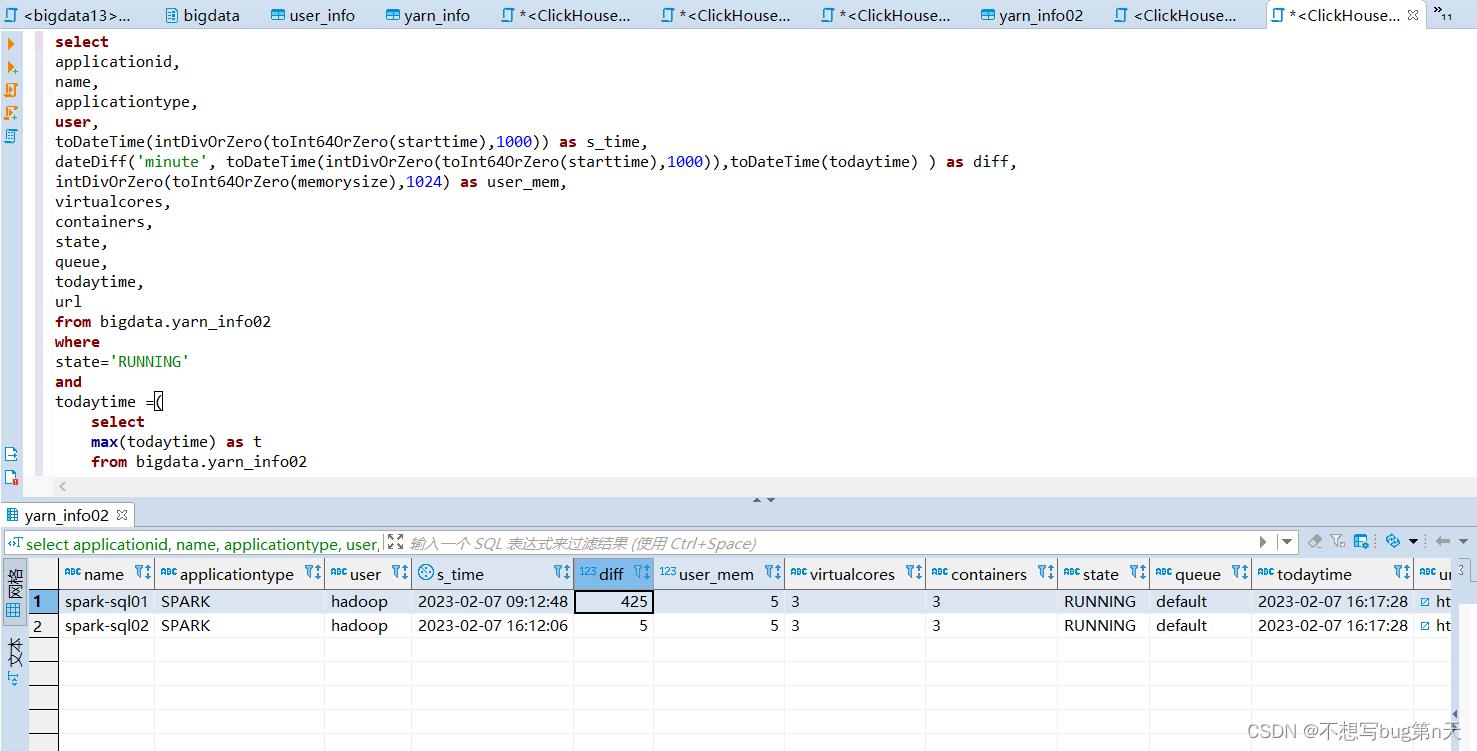
-
-
2.在superset制作
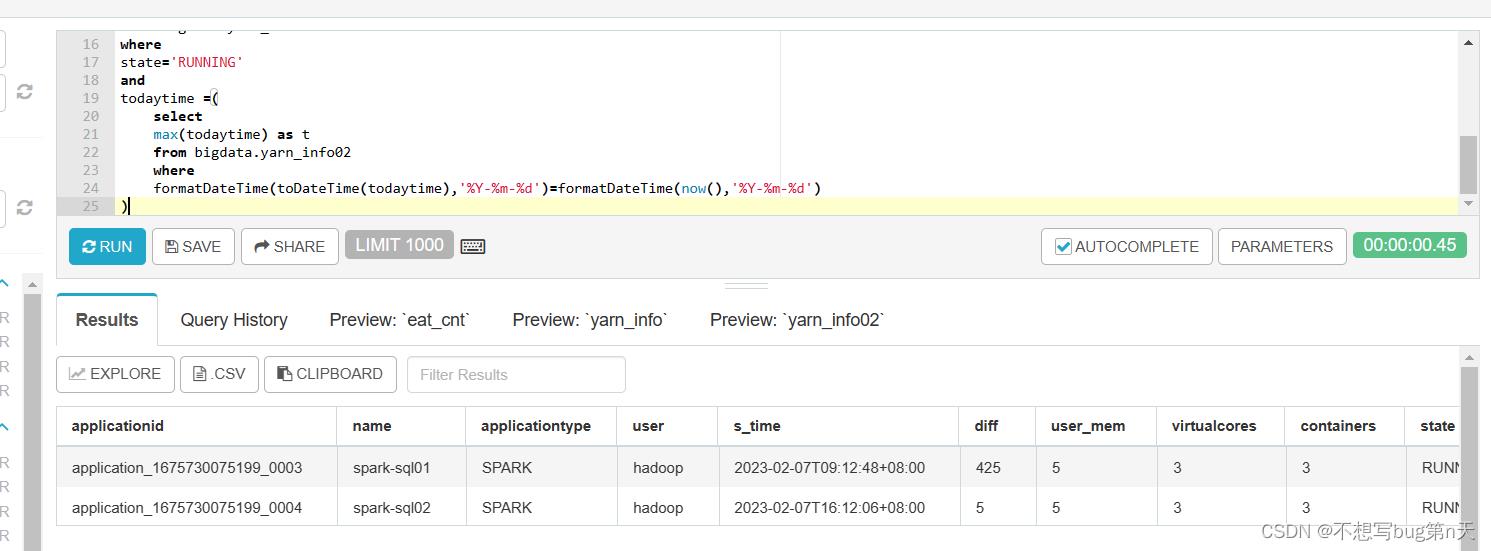
-
-
2.yarn正在运行作业内存使用情况
-
1.sql语句查询
select cast(todaytime_alias,'String') as dt, sum(user_mem) as all_g from ( select toDateTime(todaytime) as todaytime_alias, intDivOrZero(toInt64OrZero(memorysize),1024) as user_mem, name from bigdata.yarn_info02 where state='RUNNING' group by todaytime_alias, user_mem, name ) as a group by dt; -
2.superset
-
1.选择图标

-
2.选择时间字段
-
3.修改内容
-
x轴时间
-
表格的数据
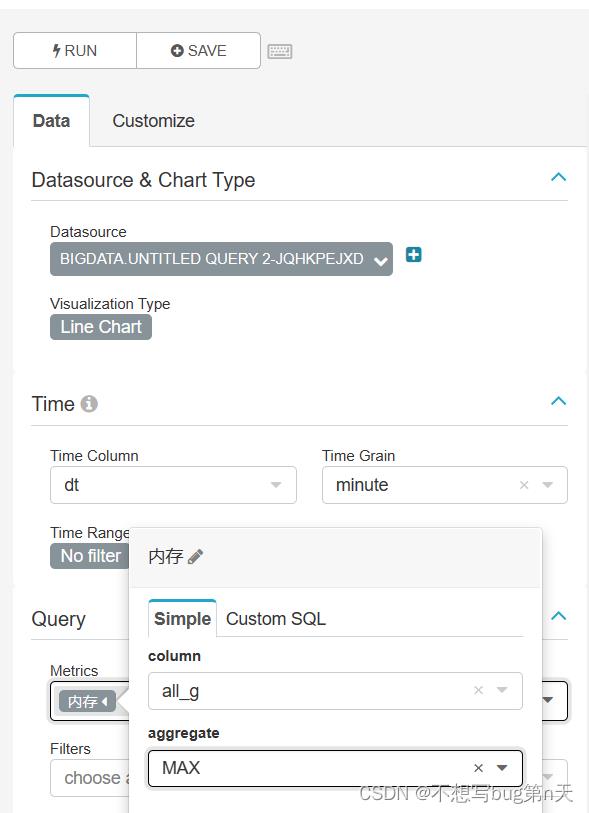
-
-
运行YarnLogTask的结果
-
-
以上是关于数据处理可视化的主要内容,如果未能解决你的问题,请参考以下文章