本文基于《Spark 高级数据分析》第3章 用音乐推荐和Audioscrobbler数据
完整代码见 https://github.com/libaoquan95/aasPractice/tree/master/c3/recommend
1.获取数据集
本 章 示 例 使 用 Audioscrobbler 公 开 发 布 的 一 个 数 据 集。 Audioscrobbler 是 last.fm 的 第一个音乐推荐系统。 last.fm 创建于 2002 年,是最早的互联网流媒体广播站点之一。
Audioscrobbler 数据集有些特别, 因为它只记录了播放数据,主要的数据集在文件 user_artist_data.txt 中,它包含 141 000 个用户和 160 万个艺术家,记录了约 2420 万条用户播放艺术家歌曲的信息,其中包括播放次
数信息。数据集在 artist_data.txt 文件中给出了每个艺术家的 ID 和对应的名字。请注意,记录播放信息时,客户端应用提交的是艺术家的名字。名字如果有拼写错误,或使用了非标准的名称, 事后才能被发现。 比如,“The Smiths”“Smiths, The”和“the smiths”看似代表不同艺术家的 ID,但它们其实明显是指同一个艺术家。因此,为了将拼写错误的艺术家 ID 或ID 变体对应到该艺术家的规范 ID,数据集提供了 artist_alias.txt 文件。
下载地址:
- http://www-etud.iro.umontreal.ca/~bergstrj/audioscrobbler_data.html (原书地址,已失效)
- https://github.com/libaoquan95/aasPractice/tree/master/c3/profiledata_06-May-2005(数据集大于git上传限制,分卷压缩)
2.数据处理
加载数据集
val dataDirBase = "profiledata_06-May-2005/"
val rawUserArtistData = sc.read.textFile(dataDirBase + "user_artist_data.txt")
val rawArtistData = sc.read.textFile(dataDirBase + "artist_data.txt")
val rawArtistAlias = sc.read.textFile(dataDirBase + "artist_alias.txt")
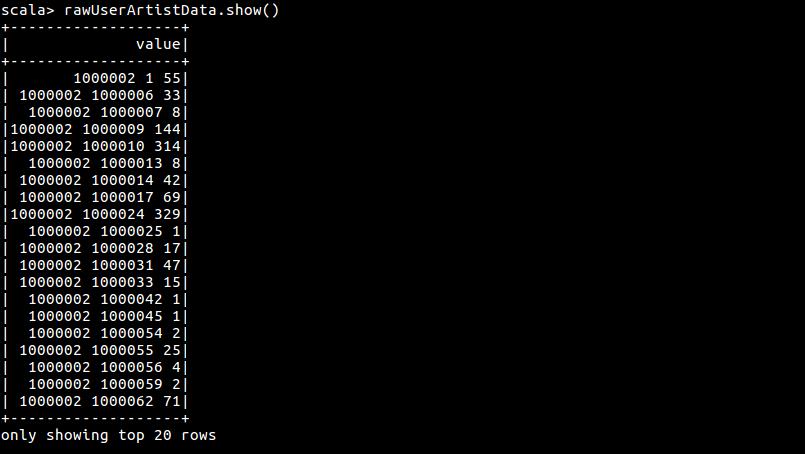
rawUserArtistData.show()
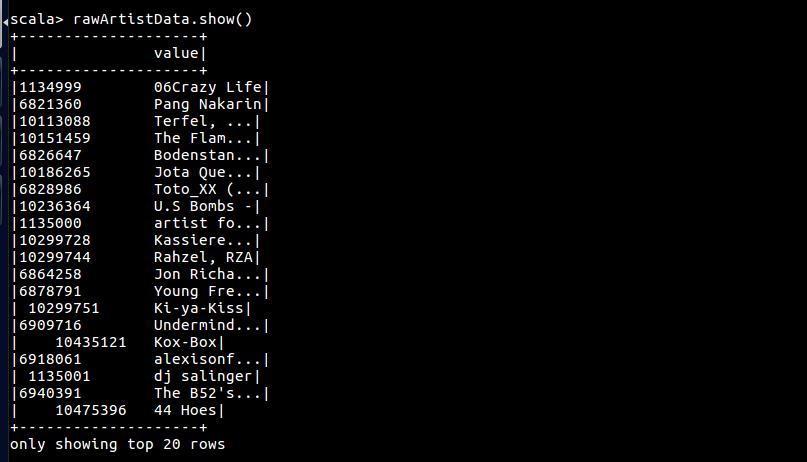
rawArtistData.show()
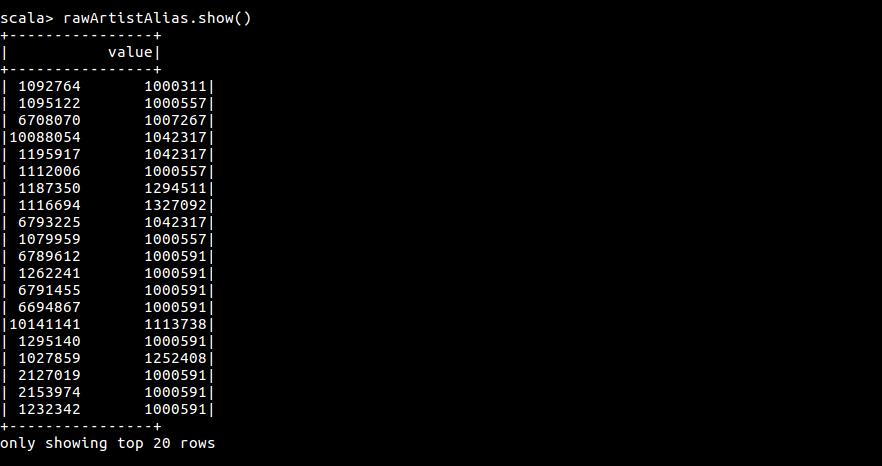
rawArtistAlias.show()
格式化数据集,转换成 DataFrame
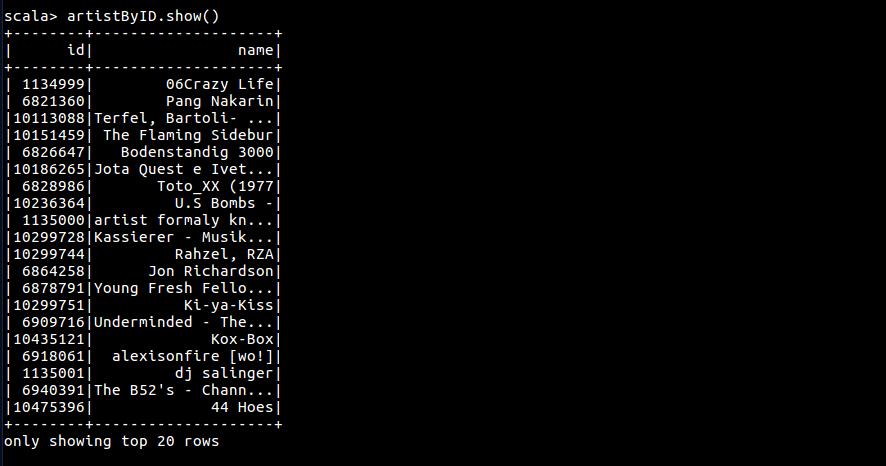
val artistByID = rawArtistData.flatMap { line =>
val (id, name) = line.span(_ != \'\\t\')
if (name.isEmpty()){
None
} else {
try {
Some((id.toInt, name.trim))
} catch{
case _: NumberFormatException => None
}
}
}.toDF("id", "name").cache()
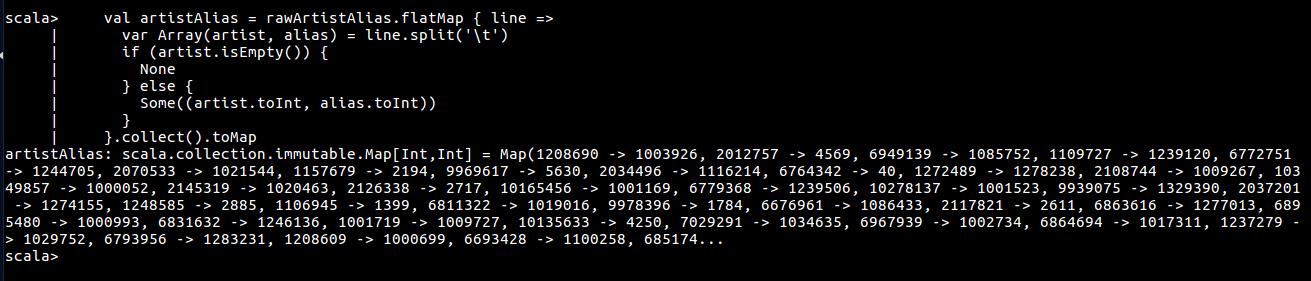
val artistAlias = rawArtistAlias.flatMap { line =>
var Array(artist, alias) = line.split(\'\\t\')
if (artist.isEmpty()) {
None
} else {
Some((artist.toInt, alias.toInt))
}
}.collect().toMap
val bArtistAlias = sc.sparkContext.broadcast(artistAlias)
val userArtistDF = rawUserArtistData.map { line =>
val Array(userId, artistID, count) = line.split(\' \').map(_.toInt)
val finalArtistID = bArtistAlias.value.getOrElse(artistID, artistID)
(userId, artistID, count)
}.toDF("user", "artist", "count").cache()

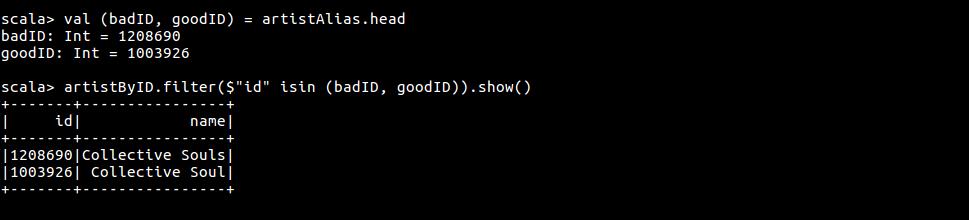
查看 artist 别名与实名
val (badID, goodID) = artistAlias.head
artistByID.filter($"id" isin (badID, goodID)).show()
3.利用 Spark MLlib 进行推荐
Spark MLlib 使用 ALS (交替最小二乘) 来实现协同过滤算法,该模型只需传入三元组 (用户ID, 物品ID, 评分) 就可以进行计算,需要注意,用户ID 和 物品ID必须是整型数据。
val Array(trainData, cvData) = userArtistDF.randomSplit(Array(0.9, 0.1))
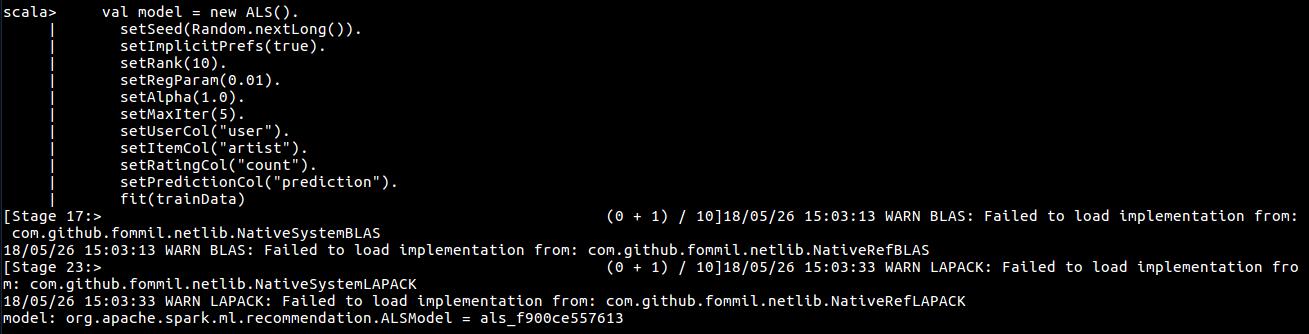
val model = new ALS().
setSeed(Random.nextLong()).
setImplicitPrefs(true).
setRank(10).
setRegParam(0.01).
setAlpha(1.0).
setMaxIter(5).
setUserCol("user").
setItemCol("artist").
setRatingCol("count").
setPredictionCol("prediction").
fit(trainData)
推荐模型已经搭建完成,不过 Spark MLlib 每次只能对单个用户进行推荐,无法进行单次的全局推荐。
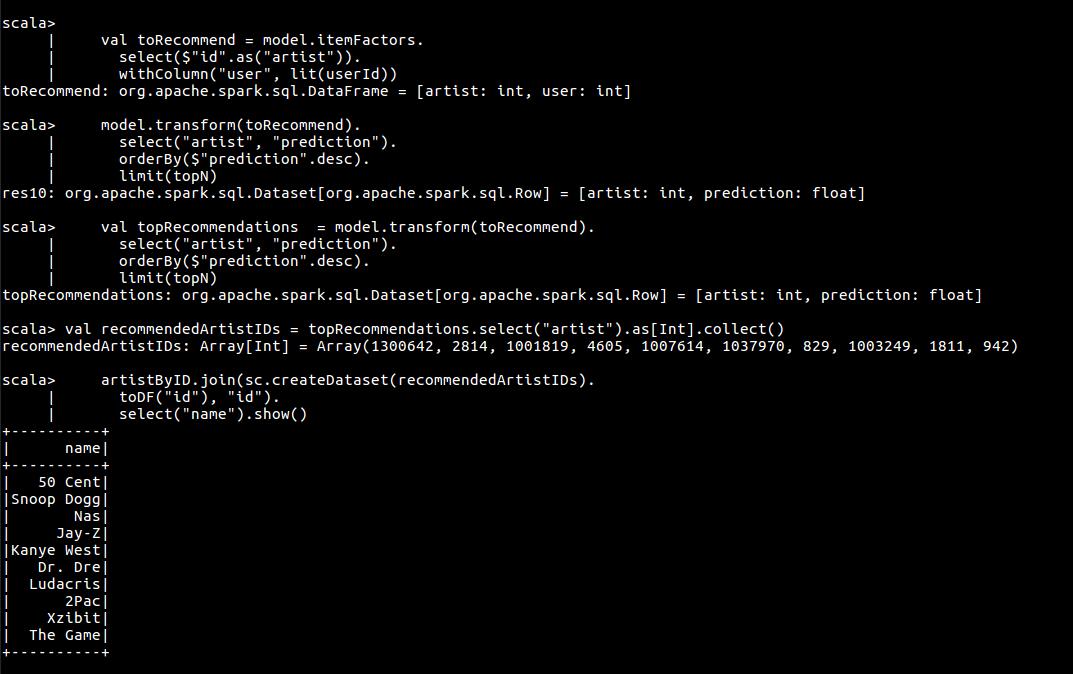
val userId = 2093760
val topN = 10
val toRecommend = model.itemFactors.
select($"id".as("artist")).
withColumn("user", lit(userId))
val topRecommendations = model.transform(toRecommend).
select("artist", "prediction").
orderBy($"prediction".desc).
limit(topN)
// 查看推荐结果
val recommendedArtistIDs = topRecommendations.select("artist").as[Int].collect()
artistByID.join(sc.createDataset(recommendedArtistIDs).
toDF("id"), "id").
select("name").show()